
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 파이썬으로 도전하는 데이터 분석
정광윤의 개발자를 위한 파이썬 기반의 데이터 분석(1회)
파이썬으로 도전하는 데이터 분석
파이썬을 이용해 데이터를 분석하고 싶어하는 개발자들은 무엇을 어떻게 해야 할지 막막할 수 있다. 당연하다. 해본 적이 없기 때문에 어떤 질문을 해야 하는지도 모를 것이다. 그래서 이 연재에서는 파이썬을 이용해 데이터를 처리하고 분석하는 데 있어서 핵심적인 작업에 대한 이야기를 먼저 하고자 한다. 항상 무언가 하기 위해서는 환경이 중요하다. 특히 현업에서 개발해본 사람들은 알겠지만 먼저 개발 환경을 만들어야 개발이 가능하다. 데이터를 처리하고 분석하는 일도 마찬가지다. 첫 연재에서는 간단한 문법을 통해 파이썬의 특징을 알아 보고, 데이터 분석을 도와주는 여러 가지 파이썬 패키지를 소개하겠다.?
| [연재 순서] 1회: 파이썬으로 데이터를 분석하자 |
? 데이터 분석
?최근 들어 빅데이터, 그로스 해킹 등 핫한 단어들이 많이 나오고 있다. IoT(사물인터넷)라는 단어가 유비쿼터스라는 용어를 이어받은 것처럼 빅데이터, 그로스 해킹이란 단어도 사실 데이터 웨어하우스 등의 개념들이 더 친숙해진(?) 단어로 바뀐 것이라고 할 수 있다. 그렇다면 이러한 용어들은 어떤 분야에 어떻게 적용되는 것일까?데이터를 의미 있는 정보로 만들기 위해서는 여러 프로세스가 필요하다. 자료 수집과 추출부터 데이터 클리닝, 분석과 리포팅까지 일련의 작업을 하는 사람을 '데이터 과학자'라고 한다. 이런 직업을 가진 사람들은 데이터가 있는 도메인 영역을 잘 알아야 함은 물론, 데이터를 의미 있는 정보로 만들기 위한 처리 작업과 이를 활용하는 과정까지 포괄할 수 있어야 한다. 이렇게 자료를 수집하거나 추출해서 모아진 데이터를 빅데이터라고 한다면, 이 데이터를 근간으로 하여 분석하고 실제로 마케팅 등에 활용할 수 있게 하는 단계에서 바로 그로스 해킹이란 용어가 나온다.
이런 용어들은 데이터가 의미 있는 정보로 만들어지는 과정에서 어느 것 하나 따로 떼어 놓고 생각할 수 없을 정도로 서로 밀접하게 연관되어 있다. 데이터를 분석하는 단계를 간략하게 그려보면 아래와 같다.
| 1. 데이터 수집 또는 추출
2. 데이터 준비(Data Munging) 또는 개조(Wrangling) 3. 탐색적 데이터 분석 4. 시각화 분석 5. 리포팅 |
데이터를 분석하는 일반적 프로세스다. 세부 단계로는 분석 대상 도메인의 문제를 분석하는 과정도 있다. 하지만 여기서는 위의 일반적인 과정을 따라가도록 하겠다.
데이터를 분석한다는 것 자체가 데이터를 기준으로 문제를 정의하고 분석해 해결하는 기법이다. 그런데 여기서는 두번째 데이터 준비 혹은 개조라는 데이터 전처리 작업에 대해 알아볼 계획이다. 이를 외국 문서에서는 Data Munging or Data Wrangling이라는 표현을 쓰는데, 영어 단어 그대로 사용하면 와 닿지 않는 부분이 있어 이를 준비하기 혹은 개조하기라는 용어로 풀이했다. 용어에 대한 자세한 설명은 위키피디아를 참조하면 된다 (https://en.wikipedia.org /wiki/Data_wrangling).
?
? 프로그래밍 언어로 데이터 다루기
?우리는 프로그래밍 언어인 파이썬을 통해 데이터를 다루고 분석할 것이다. 그 전에 데이터를 다루고 분석하는 다양한 툴을 알아보자.
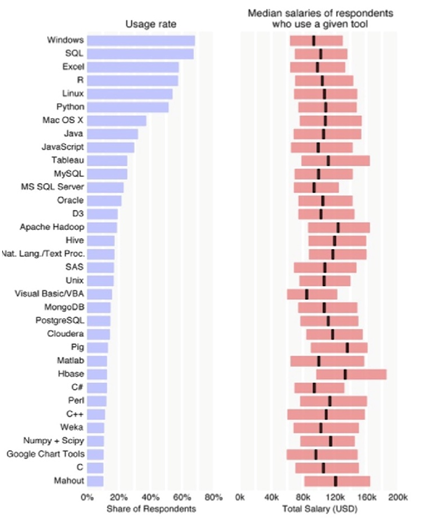
[그림 1] 데이터 분석 도구의 이용률과 급여 평균 (출처: blog.revolutionanalytics.com/2014/12/oreilly-data-scientist-salary-and-tools-survey-november-2014.html)
[그림 1]은 미국의 41개 주와 53개의 나라에서 데이터 영역 분야에 종사하고 있는 800여 명의 응답자가 데이터 분석 시 사용하는 도구와 해당 도구별 급여 평균(Median)을 보여주고 있다(응답자 중 미국의 응답자들이 압도적으로 많다). 해당 내용은 오라일리(O'Reiley)에서 2014 년 11월에 책으로 출간되었으며, eBook을 무료로 다운받을 수 있다(http://www.oreilly.com/data/free/2014-data-science-salary-survey.csp).
급여 수준에 눈길이 먼저 가겠지만, 이번 연재에서는 잠시 관심 밖으로 빼도록 하겠다. 위 그래프에서 데이터 과학자들이 흔히 사용하는 도구의 순위를 눈여겨보자. 여기에는 프로그래밍 언어, 데이터베이스, 하둡, 시각화 도구, BI 프로그램, 운영체제, 통계 패키지 등 다른 영역들의 도구가 포함되어 있다.
이를 감안하고 살펴보면 SQL, 엑셀, R, 파이썬이 상위에 있음을 알 수 있다. 데이터베이스로는 MySQL, MS SQL Server, Oracle, MongoDB, PostgreSQL 순으로 많이 사용되고 있다. 최근 빅데이터 분야에서 각광받는 프레임워크나 플랫폼 등을 살펴보면 아파치 하둡, 하이브, 클라우데라, 피그 등이 있다. 이를 통해 다양한 데이터 분석도구가 사용됨을 알 수 있다. 이는 각자 장단점이 있기에 각 도메인에 맞고, 문제 해결에 적합한 도구가 있다는 것으로 볼 수도 있다. 데이터를 다루는 도구들에 대해서도 간단히 살펴보자.
? 스프레드시트
?마이크로소프트 엑셀 같은 스프레드시트 프로그램은 프로그래밍을 모르는 일반인들이 가장 많이 다루는 데이터 핸들링 도구다. 그렇다고 해서 낮은 수준의 데이터 분석 도구라고는 결코 말할 수 없다. 어느 한 데이터 과학자의 말을 따르면, 엑셀은 고객과 데이터 분석을 통해 커뮤니케이션할 때 가장 효과적이라고 한다.필자도 반도체 회사에서 근무할 때 주로 엑셀로 데이터를 다뤘다. 제조업의 가장 근본적인 데이터, 즉 생산 데이터는 MES(Manufacturing Execution System)로부터 나온다. 하지만 이 데이터는 어디까지나 원천 데이터, 즉 처리-가공이 되지 않은 데이터다. 필자는 이를 가공-시각화해 공장장에게 분석 리포팅하는 업무를 많이 했다. 이 때 사용한 도구가 엑셀이었다. 만약 시스템이 갖춰져 있었다면, MES에서 나오는 원천 데이터를 공장장 등 의사결정자들이 바로 볼 수 있는 형태로 리포팅하면 가장 좋았을 것이다. 하지만 아직도 많은 회사에서는 엑셀을 이용해 리포팅하는 경우가 많다.
?
?프로그래밍 언어
?프로그래밍 언어로도 데이터를 다룰 수 있다. 이는 프로그래밍이라는 부분에 좀 더 포커스를 두는 것이라 볼 수 있다. 대용량 데이터를 분석하려면 전처리 작업을 거쳐야 하는데, 이를 엑셀로 한다고 가정해보라. 여러 함수를 이용해 여러 번의 마우스 클릭을 하면서 작업해야 할 것이다. 이때 프로그래밍 도구를 사용하면 어떨까? 시스템 사고법, 즉 여러 번의 클릭을 하지 않고 반복되는 구간과 분기 구간 등 논리적인 사고를 이용해 빠른 시간에 작업을 완료할 수 있다. 뿐만 아니라 프로그래밍으로도 연결시킬 수도 있다. 그뿐이겠는가? 이렇게 만들어진 소스를 계속해서 사용할 수 있고 이 소스를 이용해 다른 사용자들과 공유할 수도 있다.1) R
위 그래프에서도 알 수 있듯이 흔하고 쉽게 사용하는 도구인 엑셀을 급격하게 추격하는 언어가 있다. 바로 R이다. 데이터를 분석하는 데에 보통 컴퓨터와는 상관이 없는 비전공자들, 즉 기획자, 분석가 등이 주로 사용한다. 필자는 R을 써본 적은 없다. 엑셀, 오라클 등을 통해 데이터를 다루다가 파이썬으로 바로 넘어왔기 때R 다음으로 많이 사용하는 것이 바로 파이썬(Python)이다. [그림 1]에서 보았듯이 R과 거의 차이가 없을 정도로 많이 쓰이고 있다. R과 마찬가지로 파이썬은 언어 그 자체만으로 데이터 분석이 가능하다. 이를 퓨어 파이썬(Pure Python)이라고 부르기도 한다. 물론 파이썬으로 데이터 분석을 돕는 패키지도 많다. 특히 파이썬이 각광 받는 여러 이유 중 하나가 R처럼 다양한 패키지가 있다는 점이다. 이런 패키지를 이용하면 어렵게 프로그래밍하지 않아도 바로 데이터 분석을 할 수 있다는 이점이 있다. 이는 파이썬이 오픈소스이기 때문에 가능한 일이다. 또한 파이썬이 데이터 분석에 좋은 도구로 거듭나는 데는 분석용 패키지의 역할이 매우 컸다고 볼 수 있다. 파이썬의 분석용 패키지로는 Numpy, Scipy, Pandas 등이 있다. 위 그래프에서도 확인할 수 있듯이 Numpy와 Scipy는 순위에 랭킹돼 있을 정도로 많이 사용되지만 순위가 높지 않다. Numpy, Scipy는 데이터 준비 작업에 주로 사용되기 때문으로 추측된다. 이 연재를 통해 주로 다루게 될 패키지는 Pandas다.
3) DBMS
Oracle, MS SQL Server, MySQL 등의 관계형 데이터베이스를 관리하는 시스템을 RDBMS라 한다. 최근에는 NoSQL(Not Only SQL) DBMS도 주목을 받고 있다. 이런 도구를 통해 데이터를 저장하고 관리할 수 있다. 또한 최근에는 이런 큰 DBMS뿐만 아니라 PostgreSQL, MariaDB 등 오픈소스도 사랑받고 있다.
대기업의 SI 프로젝트에는 오라클이나 SQL Server 등 상용 제품을 주로 사용된다. MySQL이나 MariaDB 등은 대기업 환경에서 사용되지 않는 편이라고 봐야 한다. SI가 보수적인 측면이 없지 않으므로 엔터프라이즈 프로젝트에서 이전에 사용하던 것을 계속 사용하기 때문일 수도 있다. 그래서 대형 SI 프로젝트의 대부분은 자바가 지속적으로 사랑받고 있다.
4) 하둡과 스파크
아파치 하둡(Hadoop)은 빅데이터에서 분산 처리 혹은 분산 스토리지를 위한 오픈소스 프레임워크이다. 대용량 데이터를 수집-처리하려면 고성능을 필요로 하기 때문에 나온 기술이라고 할 수 있다. 빅데이터 기술은 하둡의 등장과 궤를 같이 했다고 해도 과언이 아니다. 그런데 하둡 안에서도 데이터 분석 및 분산 처리 기술을 담당하는 부분(MapReduce)이 있는데 이 부분에 기술적 성능이 뛰어난 것이 바로 스파크(Spark)다.
엑셀은 몇 십 만에서 몇 백만 건을 불러왔을 때 로딩이 급격이 느려지고 불안해지는 현상이 나타난다. 심지어 특정 데이터를 불러오는 데도 제한이 따른다. 뿐만 아니라 RDBMS는 데이터가 많으면 처리 속도가 매우 느려져 관계형 데이터베이스임에도 관계를 다 끊고 개발하는 것을 적잖이 볼 수 있다. 데이터가 쌓이면 쌓일수록 하둡이나 스파크 같은 기술이 각광받게 될 것이다. 필자가 대형 프로젝트에 참여했을 때의 경험으로는, 100만 건의 데이터였는데도 퍼포먼스가 나오지 않은 경우가 많아 신경을 많이 썼던 부분이 바로 SQL 튜닝이었다.
? 프로그래밍 도구들의 포지셔닝
?데이터 과학자라면 다양한 도구 중 어느 것 하나만 고집하고 사용할 필요도 없고 그렇게 할 수도 없다. 각기 장단점이 있으며 문제에 맞게 도구를 선택해 사용하는 것이 중요하다. 데이터 분석 시 특정 단계에 쓰이는 도구가 있다.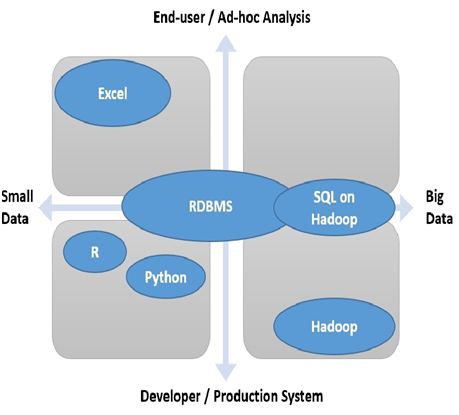
[그림 2] 데이터 분석에 사용되는 도구의 포지셔닝 (출처: http://www.hellodatascience.com)
위 그림은 MIT에서 컴퓨터 사이언스 박사 학위를 받고 MS의 검색엔진 연구자로 일하고 있는 김진영 님의 블로그에 있는 자료다. 위 그림에서 볼 수 있듯이 데이터 크기와 사용자 그리고 일시적으로 사용할 것인지 아니면 운영 시스템에 사용할 것인지 등에 따라 도구들의 포지셔닝이 조금씩 다르다.
? 프로그래밍 언어로 데이터에 접근하기
?데이터를 프로그래밍 언어로 처리하는 방법을 보자. 위 그림에 따르면 프로그래밍 언어는 빅데이터보다는 스몰데이터에, 최종 사용자보다는 개발자에, 일시적 분석 보다는 실제 운영 시스템에서의 분석에 포지셔닝이 되어 있다. 실제로 파이썬이란 프로그래밍 언어로 데이터를 처리하고 다루는 데는 다른 중간 매개체가 필요없다. 바로 실제 운영 서버로부터 데이터를 불러와서 데이터를 처리할 수 있기 때문이다. 다만 이는 프로그래밍 언어이기 때문에 일반 사용자가 접근하기에는 다소 무리가 따른다는 단점이 있다. 그렇기 때문에 일반 사용자의 경우 파이썬보다는 R로 분석하는 경우가 많다.그런데 파이썬의 이점은 응용 능력에 있다. 다양한 패키지를 이용해 해당 데이터를 분석하고 응용할 수 있는 것이다. 예를 들어 데이터를 처리하고 나서 파이썬로 만들어져 있는 무료 웹 애플리케이션 프레임워크인 Django를 이용해 바로 웹 서비스를 만들 수 있다. 이 때문에 데이터를 다루는 개발자들이 R보다는 파이썬을 선호하는 경향이 있다.
앞서 설명한대로 프로그래밍 언어로 데이터에 접근시 프로그래밍 이라는 특수성을 이용해 데이터를 빠르게 처리할 수 있는 이점이 있다. 그렇지 않다면 엑셀처럼 일련의 과정을 거쳐 데이터를 처리하고 준비하는 작업을 거쳐야 한다. 그럼에도 불구하고 프로그래밍 언어는 현업 부서에서 일하는 사람들이 쉽게 다룰 수 있는 도구는 아니다.
필자는 파이썬으로 세무 데이터의 처리 및 준비 작업에서부터 웹 서비스로 보여주기 까지 파이썬과 Django를 이용해 개발한 적이 있다. 이때 세무사라는 직업의 특성 상 주로 엑셀을 통해 세무 데이터를 관리하고 있었고, 엑셀로 업로드 하면 바로 데이터 전처리 작업을 거쳐 저장과 분석 기능까지 구현한 적이 있었다. 데이터가 작고 일시적으로 분석하기 위해 엑셀을 자주 사용하는 경우라면 파이썬을 이용해 데이터를 업로드해 전처리 및 저장, 분석과 서비스까지 할 수 있는 장점을 누릴 수 있다.
?
? 파이썬
?지금까지 오라일리(O'Reiley)에서 설문 조사했던 결과를 바탕으로 데이터를 분석할 수 있는 여러 도구를 살펴보았다. 다양한 분석 도구가 있지만 여기서는 파이썬을 선택할 것이다. 또한 다른 언어를 주로 다루는 개발자를 대상으로 하되, 일반적으로 개발자는 빠르게 학습할 수 있을 것이란 전제 아래 깊이 있게 다루지는 않겠다.?
? 파이썬의 시작
?1991년 네덜란드 국립 연구소의 Guido Van Rossum에 의해 발표되었다. 파이썬의 로고가 뱀을 형상화한 이유는 파이썬이 뱀이라는 뜻을 가지고 있기 때문이며 이는 Guido Van Rossum이 좋아하는 TV 드라마의 제목에서 가져왔다고 한다. 파이썬이 세상에 나온 지 24년이 지난 최근에서야 각광받는 언어가 된 이유는 이 언어가 배우기 매우 쉽기 때문이다. 파이썬은 기본적으로 문법체계를 배우지 않아도 그 뜻을 알 수 있을 정도로 인간 친화적인 언어다. 또한 필자가 큰 장점이라고 생각하는 부분은 바로 다양한 패키지의 활용이 가능하다는 점이다. 파이썬은 앞서 설명한대로 웹 애플리케이션을 개발할 수도 있으며 데이터 분석도 가능하다. 이게 가능한 이유는 무료로 배포되어 있는 패키지들 때문이다. 또한 이들 패키지는 많은 개발자에 의해 현재까지 꾸준히 업데이트되고 있다.1) 파이썬 설치
파이썬은 리눅스, OS X에 기본으로 설치되어 있는데, 가장 많이 사용하는 2.7 버전과 3.4 버전이 모두 설치되어 있다. 다만 윈도우 사용자의 경우엔 http://www.Python.org에서 직접 다운로드를 받아야 한다. 다운로드를 받을 경우 꼭 PIP이 설치된 옵션을 선택해 설치하길 권장한다. PIP은 추후에도 많이 나오는 것으로 파이썬 패키지 매니저이며, 파이썬 패키지를 쉽게 설치할 수 있는 유용한 관리도구이다. 윈도우 사용자는 설치 후에도 파이썬이 설치된 디렉토리와 파이썬이 설치된 디렉토리의 하위 디렉토리인 Scripts 디렉토리까지 시스템 변수의 Path에 설정하는 것도 잊지 말자.
필자는 OS X 기반의 노트북에 가상 환경으로 Ubuntu를 설치해 개발하는 경우가 많은데, 필자의 경우엔 Ubuntu에서 파이썬 3.4를 직접 다운 받아 설치해 사용하곤 한다. 이는 Ubuntu에 이미 설치되어 있는 파이썬 3의 경우 PIP이라고 부르는 파이썬 Package Manager가 지원되지 않기 때문이다. (이 말이 어렵게 느껴지는 독자는 그냥 넘어가도 무방하다. )
이번 연재에서는 파이썬 2.7을 바탕으로 하려고 한다. 이유는 아래에서 설명하겠다.
?
? 파이썬 버전의 선택
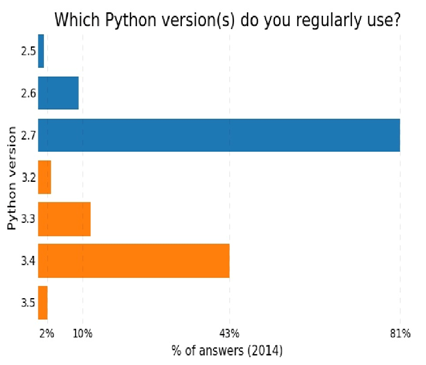
[그림 3] 파이썬 사용 현황 (출처: http://www.randalolson.com/2015/01/30/Python-usage-survey-2014/www.randalolson.com/2015/01/30/Python-usage-survey-2014)
??위 그림에서도 알 수 있듯이 파이썬 2.7 버전은 2008년 12월에 릴리즈되어 7년 정도가 지났음에도 사용 빈도가 매우 높다. 파이썬 2.x 버전에 비해 성능이 향상되고 편리해진 파이썬 3이 출시됐는데도 전 세계적으로 파이썬 2.7의 사용빈도가 높은 이유는 바로 지원하는 패키지 때문이다. 아직까지 파이썬 2.7에 비해 파이썬 3을 지원하는 패키지 수가 많지 않다. 심지어 OS X나 리눅스의 경우 파이썬 2.7과 3.4 모두 기본적으로 설치되어 있지만 alias가 파이썬 2 버전을 가리키고 있어 특정 설정을 해야 파이썬 3을 사용할 수 있는 불편함이 있다.
최근 들어서는 많은 패키지가 파이썬 3.x 버전을 지원하고 있어 정말 특이한 패키지가 아닌 이상 파이썬 3.x을 사용해도 무방하리라 본다. 다만 이번 연재에서는 그래도 아직까지는 대중적으로 사용되고 있는 파이썬 2.7을 다룰 것이다. 연재에서는 파이썬 3.x과 파이썬 2.x의 차이를 느끼는 못하는 부분이 많은 것 또한 한 이유이다.
?
? 기초 문법
?파이썬의 모든 것을 다룰 순 없다. 그러므로 데이터 처리 및 분석 시 가장 기본적으로 알아야할 내용만 간추려서 보도록 하겠다. 파이썬이 이미 설치가 되었다고 가정하고 아래부터는 Console 창에서 파이썬 Interpreter를 열어 실습해보도록 하자. 맥북에서는 아래와 같이 터미널을 열어 파이썬을 입력하여 실행할 수 있으며 윈도우에서도 마찬가지로 터미널을 열어 확인할 수 있다.
[그림 4] 파이썬 인터프리터 실행 화면
?데이터베이스를 주로 다루던 사람 혹은 자바와 같은 언어를 다루는 사람이라면 익숙하지 않은 문법들이 제법 나온다. 하지만 명확하고 쉬워질 것이다. 아래 이슈를 통해 알아보도록 하자.
?
| # coding: UTF-8
def function_a(request): """ 파이썬 연습 글자 출력 """ # 출력하세요 print "Data Munging, Wrangling, Processing" 1. 들여쓰기 2. 콜론(:) 3. 한글사용 4. 주석처리 5. 0부터 시작 |
?위 그림에 나와있는 함수 소스를 보면 알 수 있지만 첫 번째로 함수를 정의하는 문맥 상의 구분을 들여쓰기(Indentation)으로 하고 있다. 이는 정해져 있는 스페이스의 수는 없지만 관례상 4칸을 띄운다. 또한 함수의 처음 시작과 끝이 없다. 자바처럼 중괄호를 하지 않고 처음 시작 부분에만 콜론(:)을 사용하며 문맥 상 들여쓰기가 끝난 곳이 함수의 마지막이라고 판단한다.
문서 내 한글을 사용하기 위해선 문서의 맨 위에 주석처리로 된 coding :UTF-8을 입력해 줘야 한다. 주석처리의 경우 두 가지 방식이 있는데, 위 그림에서처럼 Multiple line을 구성할 때에는 쌍따옴표 혹은 홑따옴표로 구성하며 Single line일 경우에는 # 한 개만을 붙이고 쓰고 싶은 내용을 쓰면 된다.
위 소스에는 나와 있지 않지만 파이썬의 시작 인덱스 번호는 항상 0으로 시작한다. 따라서 10개를 셀 때는 항상 9부터 시작해야 한다.
Basic data types
다른 언어와 마찬가지로 파이썬에도 데이터에 대한 타입이 존재한다. 다만 파이썬은 변수를 선언할 때 데이터 타입을 선언하지는 않는다. 파이썬에도 크게 Number와 String이 있으며 여기서 Number를 다루진 않겠다. 비교적 간단하고 다른 언어와 다른 점이 없기 때문이다. 다만 String 타입을 잘 살펴볼 필요가 있다. 이는 아래에 나와있는 세 가지 - List, Tuple, Dic를 보도록 하자. 이를 특별히 데이터를 담을 수 있는 그릇이라는 의미로 Container라고 하겠다.
Containers - Lists/Tuples
리스트와 튜플은 아래 두 가지만 빼고 똑같다.
리스트 튜플
[] ()
수정/삭제/추가 가능 수정/삭제/추가 불가능
아래와 같이 리스트/튜플을 만들 수 있다. 자바와 같은 언어를 사용해본 개발자라면 배열을 생각할 수 있을 것이다.
lst = [1, 2, 3, 4]
tpl = (1, 2, 3, 4)
Containers - Dictionaries
두 번째로 살펴볼 것은 Dictionary 즉, 사전 객체이다. 이는 JSON 형태이다. Key와 Value가 결합된 형태이며 순서는 상관없고 Key 값으로 Value 값을 찾는 방식이다. 매우 중요하니 꼭 알아두길 바란다.
dic = {
'key1': 'value1', 'key2': 'value2', 'key3': 'value3'
}
Function
파이썬에서의 함수 정의는 아래와 같이 간단하게 할 수 있다. 다만 유념해야 할 것이 콜론(:)과 띄어쓰기(Indentation)이다. 파이썬을 처음 다뤄보는 개발자가 가장 많이 혼란스러워하며 틀리는 부분이다. 특히 띄어쓰기에 조심하지 않으면 IndentationError와 친해질 수 있다.
def function_a(num1, num2):
n1 = int(num1) n2 = int(num2)
runturn n1+n2
Class?클래스를 선언하고 인스턴스를 만드는 방법은 아래와 같다.
class User(Human):
country = 'South Korea'
def eat(food):
# 중략
korean1 = User()
print korean1.country
위와 같이 class 클래스명(상속받을 클래스명)을 통해 클래스를 선언한다. 다만 파이썬에서는 의무는 아니지만 관례적으로 클래스명의 첫 글자를 대문자로 한다. 또한 korean1 = User() 처럼 아주 간단히 인스턴스를 생성할 수 있다.
본 연재는 파이썬에 대한 연재가 아니기 때문에 파이썬 언어에 대한 부분은 매우 간단하게 언급하고 넘어가는 것을 양해해 주길 바란다. 이를 좀 더 공부하고 싶은 독자는 codeacademy 등 무료 학습 사이트
? 데이터 분석을 위한 파이썬 패키지
?이제 본격적으로 분석을 하기 위해 필요한 패키지를 설치하도록 하겠다. 패키지를 설치하기 위해서는 기본적으로 아래와 같은 개발 환경을 갖추고 있어야 한다.| 1. 파이썬이 설치되어 있어야 한다.
2. 리눅스나 OS X 사용자는 신경쓰지 않아도 되지만 윈도우 사용자라면 pip이라는 것을 설치해야 한다. 하지만 걱정할 필요는 없다. 파이썬 설치 시 기본 옵션으로 pip도 같이 설치하게 되어 있다. 3. 윈도우 사용자라면 어디에서도 파이썬과 pip을 실행할 수 있도록 시스템 Path 설정에 파이썬이 설치되어 있는 디렉토리와 pip 실행파일이 있는 디렉토리를 Path 설정을 해야 한다(예: c:\ Python27;c:\ Python27\Scripts). |
1) Interpreter: I Python
처음으로 설치할 것은 I Python 이다.
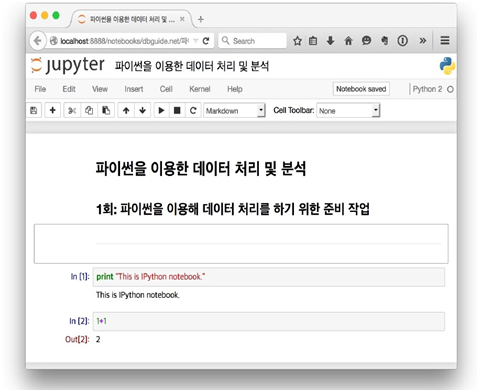
[그림 5] IPython Notebok 실행화면
?IPython은 2 버전까지는 IPython이었으나 3버전 들어오면서부터 이름이 Jupyter로 바뀌었다(하지만 대게는 IPython이라고 부른다.) IPython이란 것은 파이썬 인터프리터의 기능을 개선한 인터프리터라고 생각하면 된다. 다만 여기서는 데이터 분석 시 인터프리터를 사용하지 않고 IPython Notebook을 사용할 것이다. 위의 그림은 이 바로 IPython Notebook으로, 간결하게 문서를 만들 수 있다. 이의 특징은 아래와 같다.
① Markdown 지원
이 글을 연재하고 있는 필자도 IPython을 이용해 작성하고 있다. 특히 IPython에는 CLI 방식의 Interpreter뿐만 아니라 IPython Notebook 이란 것을 제공한다. 이는 In-brower editor라고 생각하면 편하다. 브라우저에서 본인이 파이썬으로 작업한 내용을 계속 기록하면서 작업할 수 있다. 뿐만 아니라 Markdown을 지원하고 있어서 문서로 만드는 것이 가능하다. 이는 개발할 때의 문서화에도 큰 도움이 된다.
필자는 IPython Notebook의 팬이라고 말하고 싶을 정도로 매우 유용하게 사용하고 있다. 본인이 학습한 내용을 정리해서 만드는데 주로 사용한다.
② 다른 언어 지원
IPython Notebook의 또 다른 이점은 파이썬뿐만 아니라 R 프로그래밍 언어도 지원한다는 점이다. 그래서 데이터 분석 시 파이썬 언어를 사용하는 사람 뿐만 아니라 R 프로그래밍 언어를 하는 사람도 IPython Notebook을 자주 사용한다.
③ Github과의 연동으로 간편하게 공유 가능
GIthub이라고 하는 매우 유명한 소스 저장소가 있다. GIthub에서 IPython Notebook 형식을 지원하기 전까지는 nbviewer라고 하는 곳에서 온라인상에서 IPython notebook을 공유할 수 있도록 지원했지만 변환 작업이 다소 귀찮다는 점이 단점이었다. 그런데 Github에서는 저장소에 업로드만 하면 바로 IPython Notebook을 볼 수 있다. 이 기능을 지원한지는 얼마 되지 않았다(Github의 공식 Announcement 참고: 2015.05.07 https://github.com/blog /1995-g ithub-jupyter-notebooks- 3). 이것이 가능한 이유는 IPython Notebook(확장자: ipynb) 파일이 JSON 형태이기 때문이다.
④ IPython 설치
데비안(Debian) 계열 리눅스의 경우 apt-get을, 레드햇(Red Hat) 계열 사용자의 경우 yum을 통해 설치할 수 있다. 하지만 필자는 파이썬 가상 환경 안에서 설치하는 것을 기본으로 다루겠다. 리눅스나 OS X의 경우 파이썬 Packag eManager인 pip가 기본적으로 설치되어 있어 이 것을 통해 IPython을 설치할 수 있다. 하지만 윈도우 사용자의 경우 최초에 파이썬을 설치할 때 PIP이 포함된 버전으로 설치를 해야 파이썬과 함께 설치가 되니 이 점을 꼭 유의하기 바란다. 아래와 같이 pip를 통해 IPython을 설치해보자.
$ sudo pip install ipython[notebook]
단순히 ipython만 적으면 notebook은 설치되지 않으므로 대괄호([]) 속에 notebook을 꼭 입력하도록 하자. 뒤에서 언급하겠지만 Continuum의 Anaconda라는 배포판을 설치하면 앞으로 설치하게 될 패키지와 IPython을 한꺼번에 자동으로 설치할 수도 있다. 이 방법은 뒤에서 다시 언급 하겠다.
⑤ IPython 사용
콘솔창에 아래와 같이 입력해 IPython Notebook을 실행해 보자.
$ ipython notebook
우측 상단에 있는 New 버튼을 눌러 나오는 Python 2을 클릭하여 새로운 문서를 만들 수 있다. VI 를 사용해 본 적이 있는 개발자라면 쉽게 다룰 수 있을 것이다. 편집 모드와 커맨드 모드 두 가지 방식이 있으면 편집 모드에서는 편집을 할 수 있고 ESC를 눌러 커맨드 모드로 빠져나올 수 있다. 커맨드 모드의 Shortcut은 커맨드 모드에서 h를 눌러 확인할 수 있다.
2) Package: Beautifulsoup4
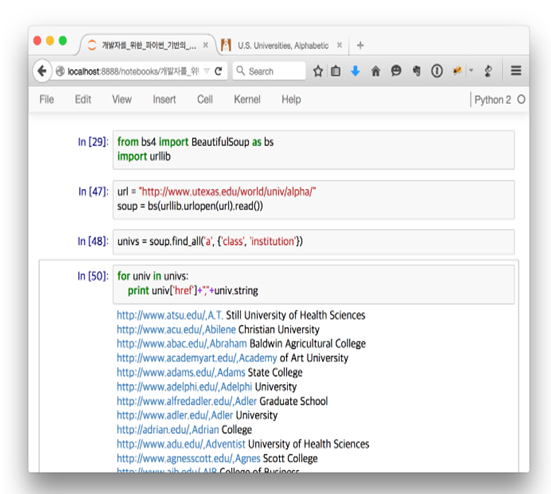
[그림 6] Beautifulsoup4을 이용해 크롤링 테스트
이 패키지는 분석용 패키지는 아니다. 그렇다면 어떤 패키지일까? 요즘에 많이 들어봤을 용어인 '크롤링(Crawling)'을 해주는 패키지이다. 즉 인터넷에 있는 웹 페이지를 긁어(?)오는 도구이다. 조금 더 유식한 표현으로는 크롤링 혹은 데이터 추출(Extraction)이라고 한다. 필요한 자료가 특정 웹 페이지에 있다고 하면 그 데이터를 가져오는데 이 패키지를 사용하게 될 것이다. 아래와 같이 설치를 해보고 테스트를 해보자.
$ sudo pip install beautifulsoup4
지금은 위의 내용을 알 필요는 없다. 어디까지나 테스트니까 말이다. 그래도 간단히 말하자면 위 그림은 http://www.utexas.edu/world/univ/alpha 사이트에 있는 대학교 목록을 긁어오는 방법이다. 위 사이트를 가보면 대학교 목록이 하나의 페이지에 있고 이는 a태그로 되어있으면 class는 institution으로 되어있다. 이를 가져와 전부 출력하려면 위와 같이 하면 된다.
3) Package: NumPy
NumPy 패키지는 파이썬을 이용한 과학 계산을 다룰 때 가장 기본이 되는 패키지이다. 특히 다차원 배열 객체(N-Dimentional Array)를 만드는데 매우 강력하다. 이 패키지는 여기서는 많이 쓰지 않겠지만, 주로 다루게 될 패키지인 pandas의 기본이 되기 때문에 중요하다. 이는 아래와 같이 설치할 수 있다.
$ sudo pip install numpy
설치한 후 IPython Notebook에 들어가 간단한 NumPy 배열을 만들어 아래와 같이 테스트를 해보자.
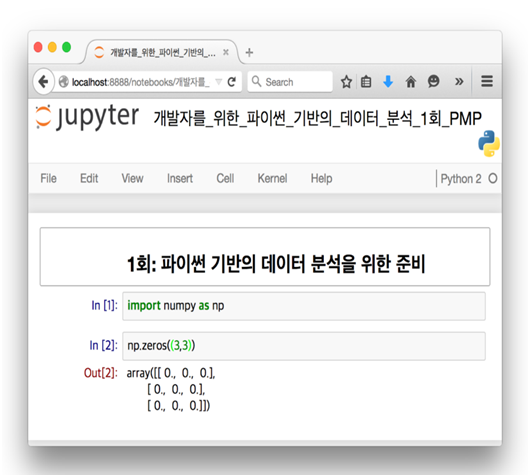
[그림 7] numpy 테스트
im port numpy as np
np.zeros((3,3))
4) Package: pandas
우리가 가장 관심있게 봐야 할 패키지로 가장 중요하다. 금융 분야에서 일하던 Wes Mckinney라는 사람이 자기 분야에서 분석을 하기 위해 만들었다. 개발자 출신이 아닌 사람이 만든 것이다. 정말 대단하다고 생각한다.
여기서는 pandas의 가장 기본적인 데이터 구조인 Series와 DataFrame을 집중적으로 살펴볼 것 이다. 우선 아래와 같이 설치하고 테스트를 해보자.
$ sudo pip install pandas
pandas 내용은 다음 연재부터 자세히 다룰 것이므로 지금은 테스트라 생각하고 그냥 넘어가도 무방하다. 위의 예제는 1차원 배열 객체인 Series를 만드는 예제이며, Series를 만들고 1000 미만을 가져오도록 filtering하는 과정을 보여준다.
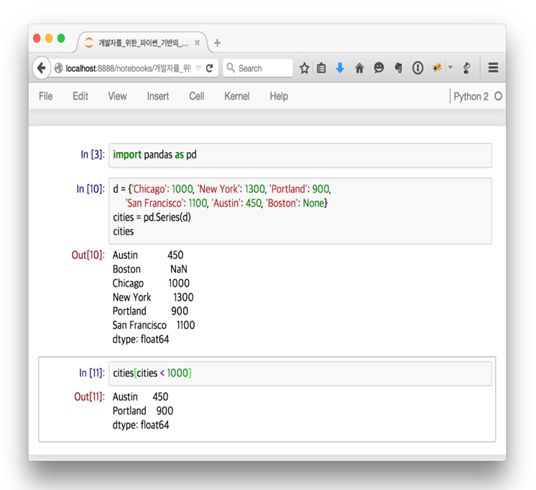
[그림 8] pandas 테스트
5) 시각화 도구: Matplotlib
시각화 도구이다. 이 부분은 연재 주제와는 맞지 않아 자세하게 다루지는 않겠다. 하지만 분석 내용을 시각화해 보여줄 필요성은 꾸준히 증가하고 있기 때문에 이번 연재에서 자세하게 다루지 않겠지만 꾸준히 사용해볼 예정이다. 주로 사용하게 될 패키지인 matplotlib가 있지만, 연재 내용에 따라 다른 패키지(Bokeh)를 설치할 수도 있다. 이럴 경우 다시 설명하겠다.
$ sudo pip install matplotlib
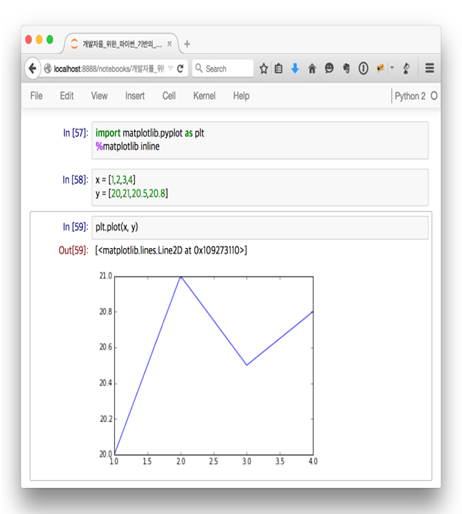
[그림 9] matplotlib 테스트
6) 배포판: Anaconda
Scientific 파이썬 통합 패키지로 무료로 사용할 수 있고 리눅스, OS X, 윈도우 모두 지원한다. 이를 이용하면 파이썬으로 데이터를 처리하고 분석하는데 필요한 수많은 패키지를 간편하게 설치할 수 있다는 장점이 있다. 국내에서도 유명한 '파이썬 라이브러리를 활용한 데이터 분석(원제: 파이썬 for Data Analysis)'의 번역자도 본 책의 저자인 Wes McKinney가 일하는 회사에서도 Anaconda를 사용하고 있다면서 이 배포판을 추천하고 있다.
Anaconda의 제작사인 Continuum Analytics의 홈페이지(https://store.continuum.io/cshop/anaconda/)에 가서 각자의 운영체제 환경에 맞게 바이너리 파일을 다운로드 받아 설치하면 된다. 단, 리눅스나 OS X 사용자는 확장자가 sh인 파일을 다운받은 후 bash 명령어로 설치를 해야한다. (예: bash anaconda.sh )
7) 파이썬에서 엑셀 파일 작업하기
pandas 패키지를 통해서도 가능하지만 가볍고 쉽게 사용할 수 있는 다른 패키지도 있어 소개하고자 한다. 하지만 이 패키지는 이번 연재에서는 다루지 않을 생각이다. 그럼에도 불구하고 소개하는 이유는 다양한 패키지를 눈에 익히는 것만으로도 큰 도움이 된다고 생각하기 때문이다. 나중에 '그때 그 패키지를 사용해야겠다'라고 생각만 할 수 있다면 성공적이다.
xlrd
엑셀 파일을 읽어올 때 사용하는 것이다.
$ sudo pip install xlrd
8) xlwt과 xlutils
xlwt는 엑셀 파일에 저장할 때 사용하는 것이다. xlutils라는 패키지를 설치하는 이유는 xlwt 패키지의 경우 항상 새로운 엑셀 파일을 만들어야 하는 문제가 있기 때문이다. 즉 기존에 있던 엑셀 파일에 내용을 쓰기 위해서는 xlutils라는 패키지가 필요하다.
$ sudo pip install xlwt xlutils
위 패키지에 대한 설명은 자세히 다루지 않겠다. 인터넷에 검색하면 쉽게 나온다. 또한 공식 문서(http://www.파이썬-excel.org/)를 참고하면 금방 따라할 수 있을 것이다.
? 정리
이 연재에서는 '개발자'들이 데이터 분석을 어떻게 하는가에 대한 내용을 다루고자 한다. 왜 하필 '개발자'일까, 그리고 왜 하필 데이터 분석이라는 주제일까?
데이터 분석이 워낙 ‘핫한’ 주제이고 필요성을 느끼고는 있으나 어떻게 다뤄야할지 모르는 사람들이 많다. 데이터는 의사판단 기준의 중심이고 경영의 가장 중요한 지표가 될 것이다. 그렇기 때문에 데이터를 처리하고 분석하는 작업은 매우 중요하다. 이를 체감하는 사람도 점차 많아질 것이다. 경영진 뿐만 아니라 마케팅에 종사하는 사람들도 관심을 두고 있다. 심지어 현대카드의 경우 빅데이터라는 용어를 직접 쓰는 TV 광고까지 내보내고 있을 정도다.
이번 연재는 처음부터 기획을 하고 분석하던 사람이 아니라 개발자들이 보길 권한다. 개발자 중심의 데이터 분석에는 분명 다른 이점이 있을 것이라고 생각한다. 그 중심에는 파이썬이라는 언어가 있다. 어디까지나 도구일 뿐이지만, 이 도구로 황금을 캐는 개발자가 되길 소망한다.
다음 회에는 실제로 파이썬을 이용해 데이터 분석을 어떻게 하는지 튜토리얼 방식으로 따라해 보면서 직접 분석을 해보도록 하겠다. (다음 회에 계속)