
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (7회) : 구체적이고 명확하게 이해하는 ‘속성’
작성자
관리자
작성일
2020-08-28 18:21
조회
719
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (7회)
구체적이고 명확하게 이해하는 ‘속성’
| 필자: 노찬형
빅터플랫폼 CIO. 대학에서 소프트웨어공학을 전공했으며 개발자로 사회 생활을 시작했다. 사회 생활 10년을 넘기고 시작했던 DB 공부가 프로그래머로서 자신을 분명하게 되돌아볼 수 있는 기회를 주었다. 사회 초년생 또는 대학생에게 도움이 되는 데이터 모델링 글을 쓰고 싶은 게 그의 작은 바람이다. pemaker@gmail.com |
|
주경야독하는 이들을 위해 우연한 일이 계기가 돼 필자는 DB와 데이터 모델링을 글로 정리할 수밖에 없는 상황에 맞닥뜨렸다. 필자는 2012년부터 2013년까지 한 대학에서 DB 강의를 했다. 강의를 요청받았을 때, 어떻게 해야 할지 난감했다. 필자가 맡은 반은 낮에는 일하고 저녁에 공부하는 학생들로 구성돼 있었다. 일반 대학생들처럼 많은 시간을 공부에 쓸 수 없는 학생들에 DB를 알려줘야 했다. 어떻게 하면 그들에게 작으나마 도움이 될까 하고 고민하던중 시중 교재 대신, 필자가 직접 강의 자료를 만들어 보면 좋겠다는 생각을 하기에 이르렀다.물론 시중의 책이 부족해서 그런 것은 아니다. 필자가 자료를 직접 만들어 쓰면, 일반 책으로 했을 때보다 더 쉽게 소개할 수 있을 것 같아서 그랬다. 누가 보더라도 이해하기 쉽게 전달하겠다는 목표로 강의 자료를 만들기 시작했다. 2년 넘게 강의 자료를 준비하다 보니, DB의 기초와 데이터 모델링의 기초에 대한 내용을 어느 정도 만들어 낼 수 있었다. 학생들이 강의자료를 요청하면 줬다. 하지만 설명이 없는 프레젠테이션 문서라서 아쉬웠다. 설명이 추가되면 학생들이 예습/복습을 할 때도 훨씬 좋을 텐데…. 배웠거나 배울 학생들을 위해 프레젠테이션 문서를 글로 정리하기 시작했다. 말보다 글로 정리하는 게 더 어렵다는 걸 실감하는 순간의 연속이었다. ‘하늘 아래 새로운 건 없다’는 말처럼 필자의 강의 자료 역시 인식하든 못하든 수많은 자료와 가르침을 받았던 결과물들이다. 물론 보고 들었던 이론을 개발 현장에서 적용?확인하는 과정을 거친, 경험의 산물이다. 앞으로 몇 회에 걸쳐 ‘제로에서 시작하는 데이터 모델링’ 연재를 하겠다고 용기를 내보았다. 독자 여러분과 함께 쓴다는 생각으로 수많은 의견이나 접근 방법을 댓글 또는 이메일로 받을 수 있었으면 좋겠다. |
지난 4~5회 연재에서 릴레이션십(relationship)을 알아보았다. 이제 속성(attribute)을 다룰 차례다.
? 속성은 엔터티와 릴레이션십의 세부사항
엔터티(entity)와 릴레이션십이 데이터 모델의 골격이라면, 속성은 세부적인 부품 또는 구성요소라 할 수 있다. 속성이란 엔터티나 릴레이션십의 특성, 식별, 분류, 수량, 상태를 표현하기 위한 모든 세부사항이다(Any detail that serves to qualify, identify, classify, Quantify or express the state of a relation or an entity.).사람을 놓고 생각해 보자. 아무개라는 사람을 특성, 식별, 분류, 수량, 상태로 나타낸다고 하자. 보통 키, 몸무게, 여성/남성, 두 귀, 두 손 등이 먼저 떠오를 것이다. 이것을 일종의 속성이라 할 수 있다. 엔터티에도 이와 같은 속성들이 존재한다. 이는 곧 속성들이 모여 엔터티를 구성한다는 말이 된다.
속성을 모두 도출하면, 해당 엔터티에서 관리할 데이터가 무엇인지 알게 된다. 속성은 데이터를 저장하는 가장 작은 저장 단위이기 때문이다.
하나하나의 속성이 모여 엔터티를 구성한다고 했는데, 이 말은 곧 ‘속성은 엔터디 개체의 세부 내용을 표현한다’는 뜻이 된다. 아무개의 속성이 아무개를 표현해준다면 그 뜻을 이해할 수 있을 것이다.
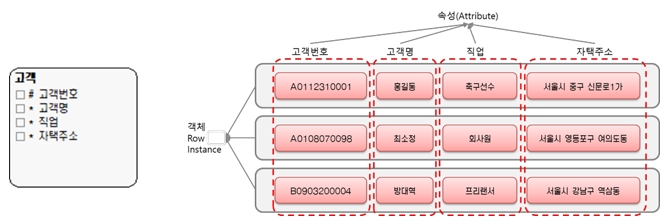
[그림 1] 고객 엔터티 개체와 속성
데이터 모델에서 엔터티와 릴레이션십이 중요하지만, 실제 데이터 값은 속성에서 관리된다.
? 속성의 구성 요소
논리모델에서 속성은 속성명, 데이터타입, 식별속성 여부, 필수속성 여부, 제약조건, 도메인, 속성의 정의요소로 구성된다(바커 표기법 기준).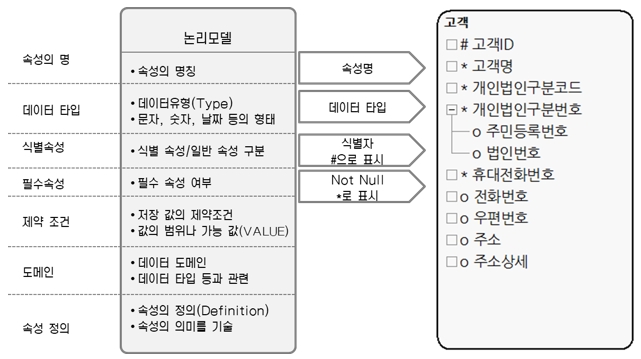
[그림 2] 속성의 구성 요소
1) 속성명
속성명은 속성의 명칭을 말하므로 속성을 가장 잘 표현할 수 있도록 다는 것이 좋다. 예를 들어, 속성명을 ‘1’이나 ‘2’로 달았다면 1이 도대체 무엇인지 알 수 없으므로 고객번호 또는 고객명과 같이 명확한 명칭을 사용해야 한다.
2) 데이터 타입
속성에 들어가는 데이터의 종류와 그 크기를 말한다. 고객명 데이터 타입은 문자형을 주로 사용하며, 돈이나 계산과 관련된 속성은 숫자형을 사용한다.
오라클 DBMS에서 제공하는 데이터 타입은 다음과 같다. 오라클 DBMS도 버전에 따라서 제공하는 데이터 타입이 다를 수 있다.
① 문자형




3) 식별속성
속성은 크게 식별속성과 비식별속성으로 구분할 수 있다. 식별자 역할을 하는 속성이 식별속성이며, 나머지가 비식별속성(일반속성)이 된다.
식별속성, 식별자는 엔터티에 존재하는 인스턴스를 유일하게 구분해 주는 속성이나 속성들을 말한다. 여기서 ‘속성들’이라는 식별자는 한 개의 속성으로 구성될 수 있 개의 속성이 모여서 식별자가 되는 경우를 복합 식별자(composite key attribute 또는 composite identifier)라고 한다.
식별속성은 바커 표기에서는 속성명 앞에 #을 붙여 구분한다. 식별자를 부르는 용어는 여러 가지가 있는데, 이는 식별자 부분에서 소개하겠다.
4) 필수속성
필수속성은 널(null)값을 허용하지 않는 Not Null 성격을 갖는다. 엔터티의 속성들 중에는 처음 인스턴스 생성 시 꼭 있어야 하는 속성이 있고, 그렇지 않은 속성이 있을 수 있다. 이때 꼭 데이터가 있어야 하는 속성을 필수속성이라고 하고, 그렇지 않은 속성을 옵션속성이라고 한다.
필수속성은 바커 표기에서는 속성명 앞에 *이 붙으며, 비식별속성은 속성명 앞에 o가 붙는다. 식별자는 당연히 필수속성이다.
데이터 모델링의 속성을 추출해 정의할 때, 필수속성과 옵션속성을 잘 구분한 후 정의해야 한다. 정확하게 구분해 정의하지 않으면, 프로그램 개발 후 꼭 들어와야 하는 데이터가 들어오지 않을 수 있다. 데이터 모델에서 필수속성으로 정의해 놓으면, 개발자가 프로그램 개발 시에 필수속성에 데이터가 꼭 들어 올 수 있도록 개발할 수밖에 없으므로 데이터의 품질을 올릴 수 있다. 반대로 필수속성을 옵션속성으로 정의하면 복잡한 상황이 발생할 수 있다.
5) 제약조건
속성의 제약조건이란 속성에 저장되는 값의 제약조건 또는 값의 범위나 가능 값(value)을 말한다. 예를 들어 금액 속성에는 숫자만 들어가야 한다. 남녀구분에서는 M 또는 F 이외에는 들어갈 수 없다.
6) 도메인
이 부분은 표준화와 관련된 부분이다. 도메인을 쉽게 이야기하면 그룹핑한 것이다. 예를 들어 성명은 문자, 주소는 문자, 성별은 문자라고 하면 성명?주소?성별은 문자형 속성이 된다. 이때 문자를 도메인이라고 할 수 있다. 도메인은 데이터 표준에서 정의하며, 속성은 정의된 도메인 중에 하나여야 한다. 혹 새로운 도메인이 필요하면, 데이터 표준에 정의한 후에 사용해야 한다. 표준에 없는 도메인을 임의로 사용하면 표준에 어긋나므로 지양해야 한다.
7) 속성정의
속성정의를 하는 이유는 자기 자신뿐 아니라 후임자를 위한 배려이기 때문이다. 처음에 속성명을 정할 때는 분명 어떤 데이터를 담을 것이라고 생각했을 텐데, 시간이 지나서 보면 그 의미를 만든 자기 자신도 헷갈릴 경우가 있다.
예를 들어서 고객 엔터티에 주소라는 속성이 있다고 가정하자. 주소 속성에 들어가는 것은 고객의 집 주소인지, 회사 주소인지, 우편물 수령지인지 알 수 없다. 이런 경우는 속성명도 좋지 않지만, 속성정의를 해놓지 않았기 때문에 정확성과 명확성이 떨어진다.
따라서 속성명을 잘 기술하는 것도 중요하지만, 속성정의를 잘 해놓는 것도 중요하다. 속성정의를 하는 방법과 기능은 ER-WIN이나 DA#같은 케이스툴에서 제공한다.
8) 속성과 데이터 모델
논리모델에서는 ‘하나의 속성은 반드시 단 하나만 존재해야 한다’를 이상적인 목표로 한다. 하나의 속성이란 단순히 같은 이름의 속성이 아닌, 그 의미가 같음을 말한다. 논리모델은 또한 속성의 중복을 배제한 No Redundancy한 상태를 목표로 한다. 그런 논리모델의 이상적 목표가 실용적이냐는 다른 문제다.
이번 회에서는 속성에 대한 전반적인 사항들을 알아보았다. 다음 회에는 속성을 도출하는 방법을 본격적으로 알아보겠다. (다음 회에 계속)
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)