
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 나성호의 R 부동산 데이터 분석 특강 (4회) : 탐색적 분석으로 데이터의 특징과 구조 이해
작성자
관리자
작성일
2020-10-26 14:10
조회
2337
나성호의 R 부동산 데이터 분석 특강 (4회)
탐색적 분석으로 데이터의 특징과 구조 이해
?| 나성호는 금융회사에서 데이터 분석을 직접 수행하는 마케터로 17년 동안 근무했다. 지금은 데이터 마이닝 박사 과정에 재학중이며, 머신러닝을 강의하고 있다. |
안녕하세요. 나성호입니다. 지난 연재에서 ‘아파트 실거래가 데이터를 반복문으로 수집하고 간단한 전처리’ 과정에 대해 설명했습니다. 이번 연재에서는 수집한 데이터에 대해 탐색적 데이터 분석을 실행해 데이터를 이해해보는 내용을 다룰까 합니다.
여러분들은 탐색적 데이터 분석을 실행할 때 어떤 내용들을 주로 확인하시나요? 저는 데이터의 대푯값과 분포 등을 확인하고, 이를 시각화하기 위해 다양한 그래프를 그려보는 정도를 수행합니다.
따라서 이번에서도 다양한 기술통계량을 계산하고 시각화하는 간단한 방법에 대해 소개해드리고자 합니다. 먼저 지난 시간에 저장했던 RDS 파일을 읽고 ‘result’ 객체에 할당하겠습니다.

? 기술통계량 계산하기 - 대푯값
기술통계량(descriptive statistics)은 말 그대로 데이터의 특성을 표현하고자 할 때 사용되는 것으로 이 때 ‘기술'은 ‘묘사하다' 정도로 이해할 수 있습니다. 예를 들어 어떤 중학교의 1반과 2반에는 각각 30명의 학생이 있고, 그 학생들의 수학 성적을 비교하고 싶다고 가정해보겠습니다. 1반과 2반의 수학 성적으로 비교하려면 개별 학생들의 수학성적으로 하나하나 비교하는 것보다 각 반의 수학성적에 대한 대푯값을 계산해 비교하는 편이 더 쉬운 방법이 될 것입니다. 기술통계에서 사용되는 대푯값으로는 ‘(산술)평균’, ‘중위수’ 및 ‘최빈값’ 등이 있습니다. R에서 평균과 중위수를 계산하는 것은 아주 간단합니다. 거래금액의 평균과 중위수를 살펴볼까요?
위 코드를 실행해보면 평균은 172691, 중위수는 165000으로 출력됩니다. 거래금액의 단위가 ‘만원’이므로 각각 17억 2691만원, 16억 5000만원을 의미합니다. ‘평균’은 숫자 벡터의 전체 원소를 모두 더해 길이만큼 나눈 값이며, ‘중위수’는 숫자 벡터의 원소들을 가장 작은 값에서 가장 큰 값 순으로 정렬한 다음 정가운데에 위치한 값을 의미합니다.
거래금액의 길이가 1823로 홀수이므로 912번째 오는 값이 거래금액의 중위수가 됩니다. 만약 거래금액의 길이가 짝수였다면 정가운데에 오는 2개의 숫자 평균을 반환했을 것입니다. 한편 평균은 이상치(outliers)에 민감하다는 특징이 있습니다. 거래금액 중 상당히 큰 값이 여럿 있는 것 같습니다.
평균과 중위수는 R 기본 함수만으로도 쉽게 계산할 수 있지만, 최빈값은 그렇지 않습니다. ‘최빈값’은 벡터의 원소 중 가장 빈도수가 높은 원소가 무엇인지 확인할 때 사용되므로, 연속형 실수 벡터보다는 이산형 정수 또는 명목형 벡터에 대해 확인하는 것이 좋습니다. 이번 예제에서는 건축년도의 최빈값을 확인해보겠습니다.

데이터의 빈도수를 확인하려면 table() 함수를 사용해야 합니다. 다만 이 함수는 원소의 값을 알파벳과 가나다 순으로 정렬한 결과를 반환하므로, 빈도수를 내림차순 또는 오름차순으로 정렬해야만 최빈값을 알기 쉽습니다. 따라서 table() 함수를 실행한 결과를 sort() 함수에 할당해 정렬하도록 합니다. 이번 예제에서는 건축년도의 빈도수를 내림차순으로 정렬하도록 설정했습니다. Console 창에서 출력된 결과를 확인하면 ‘1983’년과 ‘2006’년에 지어진 아파트가 가장 많이 거래됐다는 것을 알 수 있습니다. 건축년도로 최빈값을 확인해보니 아파트단지명으로 최빈값을 출력해보면 어떤 아파트단지가 가장 많이 거래됐는지 알 수 있을 것 같습니다. 독자 여러분께서 이 정도는 직접 해보시죠!
? 기술통계량 계산하기- 분포
이번에는 데이터가 퍼져 있는 정도를 살펴보는 기술통계량에 대해 알아보겠습니다. 대푯값에 비해서는 여러 가지 통계량이 사용되는데요. 먼저 최솟값과 최댓값, 범위, 사분위수, 백분위수 및 사분범위 등이 있습니다. 그리고 통계를 조금 공부했다면 평균과 함께 가장 많이 들어본 적이 있는 분산과 표준편차도 데이터의 분포와 관련된 기술통계량이 됩니다.앞에서 중위수를 설명할 때 ‘최솟값’과 ‘최댓값’을 언급한 바 있습니다. 최솟값과 최댓값은 R 기본함수인 min()과 max() 함수로 쉽게 확인할 수 있는데요. 아래 코드를 실행해보면 2019년 1~7월 중 서울 강남구에서 거래된 1823건에 대해서 거래금액의 최솟값과 최댓값을 확인할 수 있습니다. 코드를 실행해보니, 최솟값은 18000, 최댓값은 602000으로 출력됐습니다. 놀랍게도 서울 강남구에 2억이 채 안되는 아파트가 있었네요.

최솟값과 최댓값에서 한 단계 더 나아가보겠습니다. 기술통계에는 ‘범위’라는 개념이 있습니다. 바로 최솟값과 최댓값의 간격을 의미하는데요. R에서는 range() 함수를 사용하면 최솟값과 최댓값을 한 번에 출력해줍니다. 따라서 range() 함수의 결과값은 원소의 길이가 2인 숫자 벡터인 셈인데요. 만약 최솟값과 최댓값의 간격을 출력하고 싶다면 range() 함수의 실행 결과를 diff() 함수에 할당하면 됩니다.

위 코드를 실행해보니 최솟값과 최댓값의 간격이 602000임을 알 수 있습니다. 꽤 큰 값입니다. 그러니까 서울 강남구에서 아파트 거래금액의 최솟값과 최댓값의 범위가 60억이 넘는다는 뜻입니다. 만약 서울의 자치구별 아파트 거래 데이터를 수집해 거래금액의 범위를 계산해본다면 어떤 자치구의 거래금액 범위가 가장 좁고, 어떤 자치구의 거래금액 범위가 가장 넓은지 알 수 있을 것입니다. 숫자 벡터의 범위만으로도 데이터가 퍼져 있는 정도를 대략적으로 가늠할 수 있습니다.
이번에는 ‘사분위수’에 대해서 알아보겠습니다. 사분위수는 숫자 벡터를 4등분할 때, 각각의 분리점에 위치한 숫자들을 의미합니다. 가장 작은 값은 최솟값(0%)이 되고, 가장 큰 값은 최댓값(100%)이 됩니다. 앞에서 배운 중위수는 정가운데 숫자(50%)가 되는데, 25%와’라 쉽게 계산할 수 있습니다.

‘백분위수’는 숫자 벡터의 원소들을 오름차순으로 정렬했을 때 백분율로 표현되는 특정 위치에 해당하는 값을 의미합니다. 그러므로 사분위수를 백분위수로 표현하면 1사분위수는 25분위수, 중위수는 50분위수, 그리고 3사분위수는 75분위수라 할 수 있습니다. 방금 quantile() 함수로 사분위수를 확인한 바 있습니다. 그런데 quantile() 함수에는 숫자 벡터를 할당하는 `x` 인자 외에도 `probs` 인자도 있는데, `probs` 인자의 기본값은 c(0.0, 0.25, 0.50, 0.75, 1.0)입니다. 따라서 `probs`를 생략하면 사분위수를 반환하게 됩니다. 하지만 분석가가 `probs` 인자에 특정 위치를 백분율로 할당하면 해당 위치의 숫자를 반환해줍니다.

‘사분범위'는 사분위수 중 1사분위수와 3사분위수의 간격을 의미합니다. 사분범위는 숫자 벡터에서 이상치를 판단할 때 참고할 수 있는 통계량이 됩니다. 좀 더 자세한 내용은 간단한 시각화 부분에서 ‘상자수염그림'을 설명할 때 말씀드리겠습니다.

‘분산’과 ‘표준편차'를 끝으로 기술통계량에 대한 간단한 설명을 마무리하겠습니다. ‘분산'과 ‘표준편차'는 숫자 벡터의 각 원소들이 평균에서부터 얼마나 넓게 퍼져 있는지 확인할 때 사용하는 대표적인 통계량입니다. ‘분산'은 숫자 벡터의 분포 모양을 결정짓습니다.
예를 들어 정규분포를 따르는 두 숫자 벡터가 있다고 가정해보겠습니다. 정규분포곡선은 평균을 중심으로 좌우대칭하는 모습을 갖는데, 분산이 클수록 가운데 봉우리가 완만한 형태를 띄고 분산이 작을수록 가운데 봉우리가 뾰족한 모양을 갖습니다.
분산을 계산하려면 먼저 편차를 알아야 합니다. ‘편차'는 숫자 벡터의 각 원소에서 평균을 뺀 것인데, 편차는 개별 원소가 평균으로부터 얼마나 멀리 떨어져 있는지를 의미합니다. 원소가 평균보다 작으면 편차는 음의 값을 갖고, 원소가 평균보다 크면 편차는 양의 값을 같습니다. 그러다 보니 편차를 모두 더하면 그 결과는 항상 0이 됩니다. 분산은 편차를 모두 더하는 대신 제곱해 평균함으로써 +/- 부호를 통일할 수 있게 됩니다.
분산은 원래 데이터를 제곱했기 때문에 다시 원래 데이터의 척도에 맞도록 제곱근을 씌운 것을 표준편차라 합니다. 분산보다 표준편차가 좋은 점은 원래 척도와 맞기 때문에 이해하기 좋다는 점입니다. 예를 들어 우리가 아파트 거래금액의 단위가 ‘만원'이라고 할 때, 분산은 제곱한 것이라 단위가 ‘만원x만원'이 되기 때문에 세상에 없는 단위가 되지만 분산을 제곱근해 표준편차를 계산하면 다시 ‘만원'이라는 단위로 환원됩니다.

? 간단한 시각화
지금까지 기술통계량으로 탐색적 데이터 분석을 실행해봤는데요. 아무래도 사람은 글보다는 그림에 더 시각적으로 반응하기 때문에 기술통계량을 그대로 사용하는 대신 간단한 시각화 이미지로 표현하는 것이 내용 전달 면에서 더 유리하다고 할 수 있습니다. R에서 대표적인 시각화 관련 패키지로는 단연 ggplot2을 들 수 있습니다. 하지만 이번 연재에서는 R 기본함수들을 사용해 시각화 방법을 소개해드리겠습니다.? 데이터 분포 시각화 - 히스토그램과 상자수염그림
데이터의 분포를 이미지로 표현할 때, 히스토그램과 상자수염그림을 우선적으로 그려보는 것을 추천합니다. 먼저 히스토그램은 일정한 간격의 계급을 정하고 계급에 속한 도수를 계산해 막대 그래프와 유사한 모양으로 그린 것입니다. 막대그래프와 달리 히스토그램은 막대끼리 서로 붙여 있도록 그리는데요. 이는 데이터 분포 곡선의 면적이 1이 되도록 하기 위함입니다. 일단 히스토그램을 그려보겠습니다.
[그림 10] 거래금액의 히스토그램을 그리는 코드1
?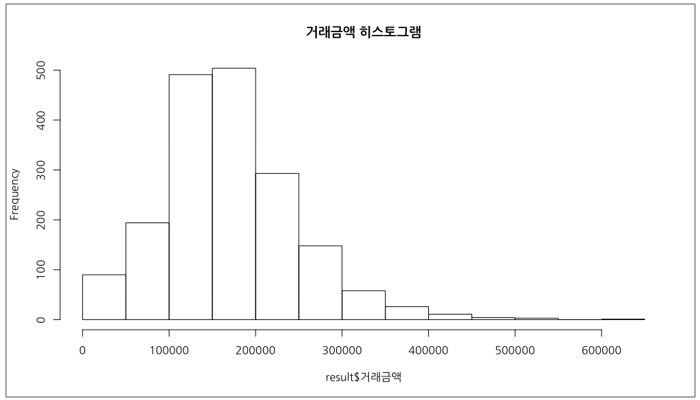
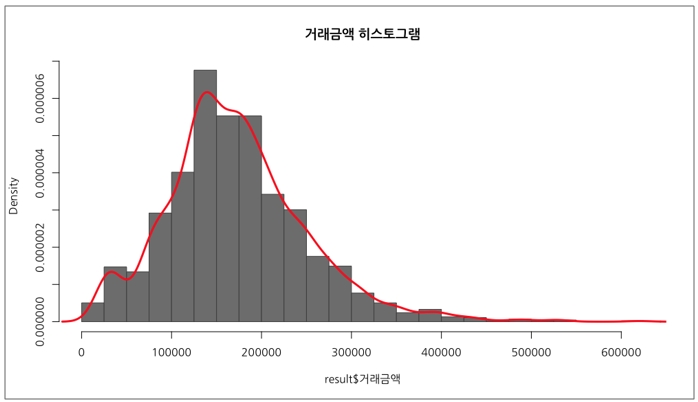
[그림 10]의 코드를 보면, hist() 함수에 별다른 인자를 건드리지 않고 기본적인 히스토그램을 그렸다는 것을 알 수 있습니다. 만약 히스토그램을 그릴 때 원하는 간격을 지정하고 싶다면 `break` 인자에 구간을 설정해 지정하면 됩니다. 예를 들어 [그림 11]은 구간이 5억 단위로 되어 있는데요. 2.5억 단위로 구간을 나눠보도록 하겠습니다. 아울러 Y축을 빈도수(frequency) 대신 밀도(density)로 바꾸고, 막대와 테두리의 색상을 회색 계열로 지정합니다. 마지막으로 확률밀도곡선을 빨간색으로 추가합니다.
?

[그림 12] 거래금액의 히스토그램을 그리는 코드 2
?
다음으로 상자수염그림에 대해서 알아보겠습니다. 일반적으로 상자수염그림은 세로 방향으로 그리기 때문에 히스토그램을 세워서 그린 것이라고 생각하면 좀 더 이해하기 쉽습니다. 일단 상자수염그림을 그려보겠습니다.

[그림 14] 거래금액의 상자수염그림을 그리는 코드
?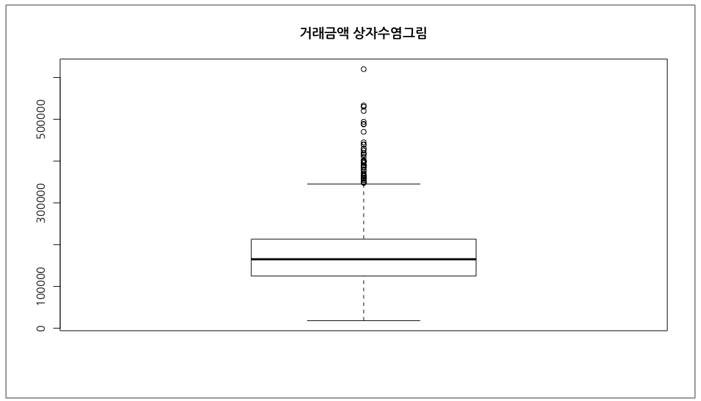
[그림 15]의 상자수염그림을 해석하려면, 상자와 수염이 의미하는 것을 알고 있어야 합니다. 상자에 대해서 말씀??위수가 되며, 가운데 굵은 선은 중위수를 의미합니다. 수염은 상자의 위아래로 그린 점선을 의미합니다.
위아래 수염 끝에는 각각 수평선이 하나씩 있는데, 아래에 위치한 수평선은 최솟값을 의미하고, 위에 위치한 수평선은 상한선을 의미합니다. 두 수평선의 용어가 서로 다른데요. 왜 그런지 지금부터 설명해드리겠습니다.
먼저 사분범위에 대해 다시 언급해야 합니다. 그림에서 사분범위는 상자의 윗선과 아랫선의 간격이 됩니다. 사분범위는 이상치(outlier)를 판단할 때 기준이 되는 값이라고 설명한 바 있는데요. 상자의 아랫선인 1사분위수로부터‘사분범위에 1.5를 곱한 값’만큼 아래쪽으로 내려 수평선을 그릴 위치를 잡습니다. 이 때 수평선의 위치보다 최솟값이 더 위쪽에 있으면 최솟값을 기준으로 수평선을 그립니다. 그래서 아래의 수평선은 최솟값을 의미하게 됩니다.
이제 상자의 윗선인 3사분위수로부터?‘사분범위에 1.5를 곱한 값’만큼 위쪽으로 올려 수평선을 그릴 위치를 잡습니다. 이 때 수평선의 위치보다 최댓값이 더 아래쪽에 있으면 최댓값을 기준으로 수평선을 그리게 되지만 이번 경우에서는 수평선보다 큰 값들이 여러 개 있기 때문에 수평선을 원래 위치에 그린 다음 수평선보다 큰 값들은 동그라미로 표시합니다. [그림 15]에서 동그란 점들은 상한선보다 큰 값들이며, 사분범위 기준으로 이상치가 됩니다. 그리고 최댓값은 맨 위에 있는 동그란 점입니다.
상자수염그림은 히스토그램과 마찬가지로 데이터의 분포를 시각화할 때 사용하지만, 히스토그램보다 유용한 점은 여러 집단의 분포를 한꺼번에 그릴 수 있다는 것입니다. 예를 들어, 서울특별시 강남구 법정동별로 상자수염그림을 그릴 수 있는데요. 이렇게 함으로써 법정동별 거래금액의 분포를 서로 비교할 수 있습니다.

[그림 16] 법정동별 거래금액의 상자수염그림을 그리는 코드
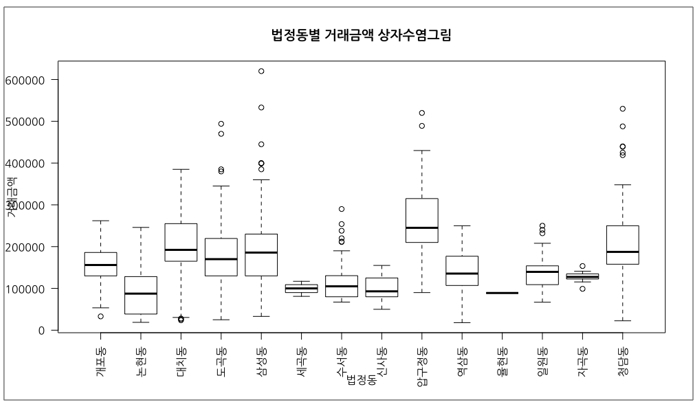
[그림 17]을 보면 논현동의 아파트 거래금액이 가장 낮고, 반대로 압구정동의 아파트 거래금액이 가장 높게 형성되어 있다는 것을 알 수 있습니다. 물론 최고금액으로 거래된 법정동은 삼성동이지만 상자의 위치, 특히 중위수가 높은 지역은 압구정동이므로 그렇게 해석할 수 있습니다.
? 데이터 관계 시각화- 산점도
마지막으로 산점도에 대해 소개해드릴까 합니다. 산점도는 2개의 숫자 벡터 간 관계를 표현하기에 좋습니다. 예를 들어 x축에 입력변수를 놓고, y축에 목표변수가 오도록 산점도를 그리면 자연스럽게 두 변수 간 관계를 시각적으로 표현할 수 있습니다. 아울러 산점도 위에 선형회귀선을 추가하면 더욱 멋진 그래프가 될 것입니다. 이번 예제에서는 전용면적을 x축, 거래금액을 y축에 놓고 산점도를 그려보겠습니다.
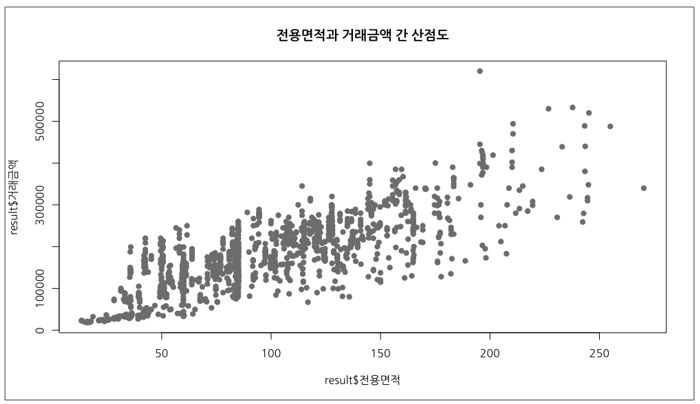
[그림 19]를 보면 전용면적이 커질수록 거래금액이 커지는 것을 알 수 있습니다. 아무래도 전용면적이 큰 집이 더 비싸게 팔리기 때문에 당연한 결과라 할 수 있습니다. 주목해야 할 점은, 전용면적이 커지면서 거래금액의 변동폭이 아주 미세하게 증가하는 경향이 있다는 것입니다. 물론 크게 문제될 것은 없어 보입니다. 아울러 전용면적이 200 근처에서 이상치가 하나 보입니다.
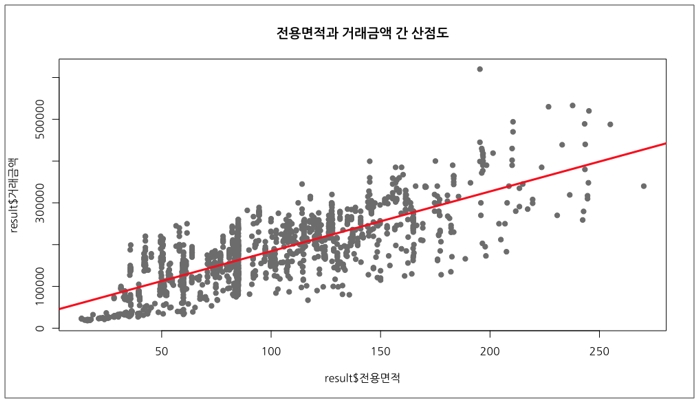
선형회귀모형을 적합할 때, 이 점을 제외해야 할 지 먼저 판단해야 할 것 같습니다. 이제 마지막으로 산점도 위에 선형회귀선을 빨간색으로 추가하고 마무리하겠습니다.

[그림 20] 산점도 위에 선형회귀선을 추가하는 코드
?
이상으로 2019년 1~7월 중 서울특별시 강남구에서 거래된 아파트 거래금액 데이터로 기본적인 기술통계량을 계산하고 간단한 시각화 방법을 소개해드렸습니다. 다음 연재부터는 5회에 걸쳐 다양한 알고리즘을 활용해 회귀모형을 적합하고 성능을 비교하는 내용을 소개해드리겠습니다. 감사합니다. (다음 회에 계속)
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 DBguide.net
?