
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 나성호의 R 부동산 데이터 분석 특강 (2회) : 수집: R로 공공데이터포털의 오픈 API 데이터 수집
작성자
관리자
작성일
2020-10-26 13:43
조회
11158
나성호의 R 부동산 데이터 분석 특강 (2회)
수집: R로 공공데이터포털의 오픈 API 데이터 수집
?? 연재에 들어가며
안녕하세요? 나성호입니다. 지난 연재에서 ‘공공데이터포털 오픈 API로 데이터 수집 준비’ 과정을 알아보았습니다. 이제 데이터를 수집하는 방법에 대해 알아보겠습니다.웹 크롤링을 배우고자 할 때 많은 분들이 파이썬(Python)으로 시작하는 것 같습니다. 저 역시 2014년에 처음으로 웹 크롤링을 배워야겠다고 마음먹었을 때 온라인 검색을 해보니 파이썬 예제가 많이 보였습니다. 파이썬이 아니면 크롤링을 할 수 없을 것 같다는 생각이 들 정도였습니다. 그래서 R을 잘하지 못하는 상태에서 파이썬을 추가로 공부해야 했습니다.
2년 정도 간헐적으로 웹 크롤링 공부를 하고 나니 웬만한 웹 사이트에 있는 글을 스스로 수집할 수 있는 역량을 갖추게 되었는데요. 2016년에 사내 임직원들을 대상으로 R 데이터 분석 강의를 시작하면서, 수강하는 분들이 웹 크롤링도 배우고 싶어한다는 것을 알게 되었습니다. 그래서 처음에는 R로는 데이터 분석을 하고 파이썬으로는 웹 크롤링하는 방법을 알려드렸는데요. 두 가지 언어를 동시에 배우는 것이 비효율적이라는 생각이 들었습니다. 그래서 2017년 초반에 파이썬으로 짠 웹 크롤러를 모두 R 언어로 바꾸어 강의하였고, 그 결과 제 직업도 달라졌습니다.
결론부터 말씀드리면 웹 크롤링에 대해 파이썬으로 할 수 있는 것은 모두 R로도 구현할 수 있다는 것입니다. 따라서 R 프로그래밍을 할 줄 안다면, 파이썬을 몰라도 웹 크롤러를 개발할 수 있습니다(물론 R과 파이썬 둘 다 사용할 줄 아는 것이 훨씬 더 좋습니다. 저도 그렇게 되려고 노력중이구요.).
이번 연재는 ‘R을 활용한 공공데이터 포털 오픈 API 데이터 수집하는 방법’을 소개하는 글이므로 웹 크롤링에 관련된 R 패키지를 소개해드리고자 합니다.
?
? 1. 웹 크롤링 관련 R 패키지
?1) httr 패키지
R 패키지 중에서 HTTP 통신과 관련된 패키지로는 ‘httr’이 있습니다. 우리가 웹 브라우저를 이용하여 인터넷 서핑을 하는 모습을 간단하게 묘사하면 다음과 같습니다. 웹 브라우저 주소창에 웹 페이지의 주소(URI)를 입력하고 엔터를 누르면(HTTP Request, 요청) 해당 주소의 웹 서버에서 정상적인 요청인지 여부를 판단해 그 결과에 해당하는 내용을 컴퓨터로 보내줍니다(HTTP Response, 응답). 웹 서버로부터 받은 내용에는 응답 메시지와 함께 HTML이 포함돼 있는데요. 웹 브라우저는 받은 HTML을 분석(parsing)하여 화면에 보여줍니다.
이와 같은 과정을 R에서 흉내내서 우리가 원하는 HTML을 웹 서버부터 받은 다음, 필요한 내용만 추출·정리하는 것을 웹 크롤링이라고 할 수 있습니다. 웹 크롤링에서 가장 중요한 것은 HTTP Request(요청)를 제대로 해야 한다는 것입니다.
HTTP Request는 여러 가지 방식이 사용되지만 웹 크롤링에서는 GET과 POST 등 두 가지만 알면 됩니다. 그런데 오픈 API에서는 REST 방식이 주로 사용되기 때문에 GET 방식만 알면 된다고 할 수 있습니다.
GET 방식은 요청 메시지로 ‘요청 라인'을 요구하는데요. 쉽게 말씀드리면 주소(URI)만 정확하게 보내면 원하는 내용을 받을 수 있다고 보면 됩니다. 예제 스크립트는 패키지 소개가 모두 끝나고 마지막에 정리해 드리겠습니다.
2) rvest 패키지
HTTP Request를 제대로 수행했다면 다음으로 HTTP Response 데이터로부터 원하는 내용을 추출해야 합니다. 오픈 API는 XML 또는 JSON 형태로 데이터를 전송해주는데 만약 XML로 받았다면 rvest 패키지의 함수를 사용해야 합니다(rvest 패키지는 XML과 HTML을 다루는 경우에 사용할 수 있는 함수들을 포함하고 있습니다.). 순서는 다음과 같습니다. 먼저 HTTP Response 객체(object)로부터 XML을 읽고, XML에서 필요한 노드(node)만 선택한 다음, 노드에 담겨 있는 텍스트를 추출합니다.
3) jsonlite 패키지
HTTP Response로 JSON 형태의 데이터를 받았다면 jsonlite 패키지를 이용해 손쉽게 원하는 데이터를 정리할 수 있습니다. HTTP Response 객체를 텍스트로 변환한 다음, JSON 형태의 데이터를 추출하기만 하면 됩니다.
?
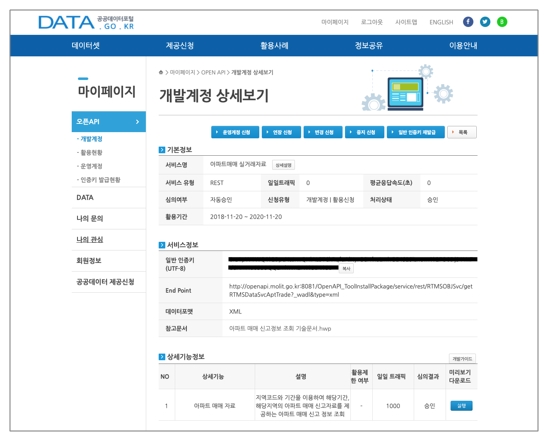
? 2. 2 URI 조립하기
오픈 API는 REST 방식을 주로 사용하기 때문에 주소(URI)만 알고 있으면 GET 방식으로 HTTP 요청을 실행할 수 있다고 설명했습니다. 따라서 오픈 API로 웹 데이터를 수집하려면 주소(URI)를 제대로 조립할 줄 알아야 합니다.URI(Uniform Resource Identifier)는 우리에게 익숙한 URL(Uniform Resource Locator)과 Query String이 ‘?’ 기호로 연결되어 있습니다. URL은 [그림 1]에서 보는 바와 같이 공공데이터 포털의 개발계정 상세보기에서 찾을 수 있습니다. ‘일반 인증키’ 항목 바로 아래 ‘End Point’ 항목이 있는데요. 마지막 부분에 ‘?’ 기호 앞 부분이 URL입니다.
지난 연재에서 수집하고자 하는 오퍼레이션에 대해 상세내용을 확인할 때 참고문서를 내려 받아서 파일 내용을 확인해야 한다고 소개한 바 있습니다(표 1). 파일을 열고 ‘요청 메시지 명세'로 이동하면 3가지 항목이 정리되어 있음을 알 수 있습니다. 이 세 가지 항목이 Query String의 파라미터로 사용됩니다.
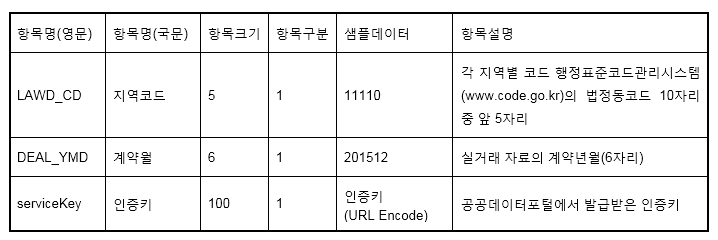
첫 번째 파라미터인 ‘LAWD_CD’는 10자리 법정동코드에서 앞 5자리만 지정해야 합니다. 이는 ‘광역시도(2자리) - 시군구(3자리)’ 단위로 조회할 수 있다는 것을 의미합니다. 예를 들어, 서울특별시는 ‘11’이며, 종로구는 ‘110’이므로, 서울특별시 종로구를 조회 조건으로 설정하려면 ‘11110’을 지정합니다. [표1]의 항목설명을 보면 ‘행정표준코드관리시스템'에서 법정동 코드를 조회하도록 안내하고 있습니다. 조회 방법에 관한 내용은 연재글 끝에 부록으로 소개하도록 하겠습니다.
두 번째 파라미터인 ‘DEAL_YMD’는 조회년월을 의미합니다. 만약 2019년 7월에 거래된 아파트 매매가격을 조회하려면 ‘201907’과 같이 지정하면 됩니다.
마지막 파라미터인 ‘serviceKey’는 인증키를 의미합니다. 지난 연재를 잘 따라하셨다면 [그림1]에서 보이는 것처럼 ‘일반 인증키'를 발급받았을 것입니다. 이 문자열을 추가해주어야 원하는 데이터를 받을 수 있습니다.
? 3. R 환경변수(environ) 사용하기
?지금까지의 설명을 읽었다면 R을 활용하여 오픈 API 데이터를 수집할 때 필요한 내용에 대해 모두 알게 되었습니다. 하지만 한 가지 더 추가로 알려드릴까 합니다.
일반 인증키는 사용자마다 발급되는 것이므로 이것을 다른 사람과 공유하면 안 됩니다. 여러분이 이 글을 읽고 오픈 API를 이용하여 공공데이터를 수집하는 R 스크립트를 완성하였는데, 주변 사람들로부터 그 스크립트를 공유해달라는 요청을 받았다고 가정해보겠습니다. 그 때 어떻게 하겠습니까? 가장 쉬운 방법은 스크립트에서 자신의 인증키를 지우고 주변 사람들에게 공유하는 것일 겁니다. 더불어 인증키를 발급받는 방법을 알려주면 되겠죠. 하지만 사람은 누구나 실수할 수 있습니다. 그래서 자신도 모르게 인증키가 포함된 스크립트를 보내고 뒤늦게 그 사실을 깨닫게 되어 부랴부랴 뒷수습을 하곤 하죠.
이와 같은 일을 미연에 방지할 수 있는 좋은 방법을 소개해드리겠습니다. 바로 R 환경변수에 일반 인증키를 저장해 놓는 것입니다. 환경변수는 사용자의 컴퓨터에 숨김 파일로 저장할 수 있으므로, 관련 스크립트를 다른 사람들에게 공유해도 노출될 위험이 전혀 없습니다(컴퓨터를 훔쳐가지 않는다면 말이죠). 따라서 자신만의 비밀스러운 정보는 모두 환경변수에 저장해 놓고 필요할 때마다 꺼내 쓰는 습관을 기르는 것이 좋습니다.
예제 스크립트를 소개합니다. RStudio를 열고 아래와 같이 실행합니다.
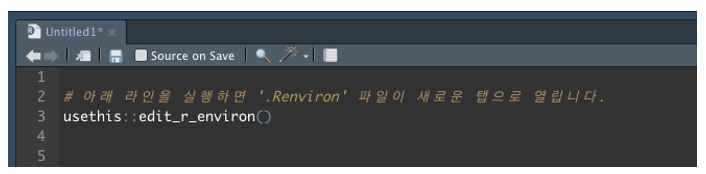
[그림 2] ‘.Renviron’ 파일 열기 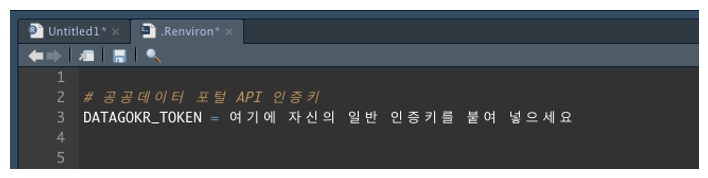
[그림 2]와 같이 usethis 패키지의 edit_r_environ() 함수를 실행하면 ‘.Renvirion’ 파일이 열립니다. 환경변수를 처음 사용하는 경우, 아무런 내용도 없습니다. 이제 [그림 3]과 같이 공공데이터 포털에서 발급받은 일반 인증키를 복사하여 여기에 붙입니다. 그리고 R환경변수 파일을 저장하고 RStudio를 껐다 켜면 인증키를 사용할 수 있게 됩니다.
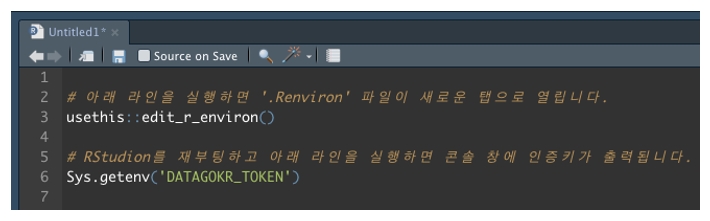
지금까지 R환경변수에 공공데이터포털 오픈 API 인증키를 추가하는 실습을 진행하였습니다. R환경변수에 제대로 저장돼 있는지 확인하려면 [그림 4]와 같이 Sys.getenv() 함수를 실행합니다. 만약 콘솔 창에 자신의 인증키 문자열이 출력되지 않았다면 인증키 추가가 제대로 수행되지 않은 것이므로 ‘.Renviron’ 파일을 다시 열어서 확인하기 바랍니다.
이제 오픈 API로 데이터를 수집할 모든 준비가 끝났습니다. [표 1]에 있는 요청 메시지 명세에 나온 조건으로 데이터를 수집해보도록 하겠습니다. 아래에 예제 스크립트를 나누어 소개합니다.
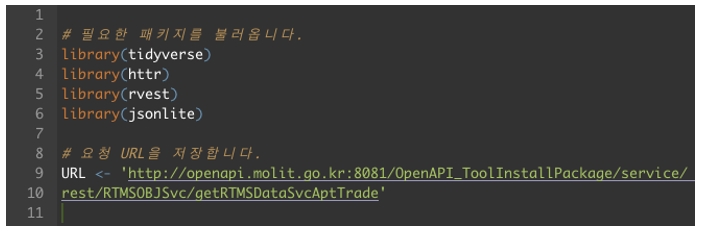
호출하는 패키지 중에서 ‘tidyverse’는 이번 연재에서 소개해드리지 않았습니다만, R 사용자라면 많은 분들이 이미 알고 있을 것이라고 생각합니다. 이번 예제에서는 파이프 연산자(%>%)와 dplyr 및 stringr 패키지를 동시에 호출하기 위해 tidyverse 패키지를 호출하였습니다.

[그림 6]에서 13행을 실행하면 R 환경변수에 저장된 일반 인증키를 불러와서 ‘myKey’에 저장할 수 있습니다. 이렇게 하면 자신의 인증키 문자열을 스크립트에서 빼놓을 수 있으므로 다른 사람들에게 공유해도 전혀 문제가 발생하지 않게 되는 것입니다.
17행부터 20행은 GET 방식으로 HTTP Request(요청)을 실행하는 코드입니다. GET() 함수의 `url` 인자에는 미리 저장해 놓은 ‘URL’을 할당하고, `query` 인자에는 Query String에 해당하는 파라미터들을 리스트 자료형의 원소로 조립하여 할당합니다.
이 때 주의해야 할 점은 ‘serviceKey’ 파라미터입니다. 코드에 보이는 바와 같이 ‘myKey %>% I()’와 같이 표현되어 있는데요. 여기에서 ‘%>%’는 파이프 연산자로 앞에 있는 객체를 뒤에 따라오는 함수의 첫 번째 인자로 할당합니다. 다르게 표현하면 ‘I(x = myKey)’와 같습니다.
그러면 왜 I() 함수를 추가하는지 궁금한 분이 있을 텐데요. 웹 서버로 문자열을 보낼 때 ‘%’의 경우 ‘%25’로 바뀌게 됩니다. 이와 같은 현상을 ‘이중인코딩'이라고 하는데요. 이렇게 되면 우리가 원하는 결과를 얻을 수 없습니다. 따라서 문자열 그대로 입력하기 위해 I() 함수를 씌워주는 것입니다. 이 코드를 실행하면 HTTP Request(요청)가 완료됩니다.

? 5. HTTP Response(응답) 결과 확인하기
?다음으로는 HTTP Response(응답) 결과 객체인 `res`를 출력하여 확인할 차례입니다. 역시 예제 스크립트로 설명하겠습니다.
[그림 7]의 23행을 실행하면 응답 메시지를 콘솔 창에 출력합니다. 응답 메시지에는 요청 URL과 일시(Date), 상태코드(Status), 콘텐트 형식(Content-Type) 및 크기(Size) 등이 출력됩니다.
가장 먼저 확인해야 할 사항은 상태코드입니다. 만약 상태코드가 ‘200’이 아니면, HTTP Response(응답)가 정상이 아니라는 것을 의미하므로 요청 코드를 확인해야 합니다.
두 번째로는 콘텐트 형식을 확인합니다. 앞에서 언급한 바와 같이 오픈 API는 응답 결과로 XML 또는 JSON 형태로 데이터를 제공한다고 했는데요. 이번 예제에서는 JSON 형태로 제공되었음을 확인할 수 있습니다.
마지막으로 크기를 확인합니다. 보통 kB 단위로 데이터를 받는 것이 일반적인데 간혹 응답 메시지가 B 단위일 때가 있습니다. 이 경우, 우리가 원하는 데이터를 제대로 받지 못했을 수도 있습니다. 왜냐하면 웹 서버로부터 받은 데이터가 아주 작다는 의미이기 때문입니다. 정상적으로 데이터를 내려 받았다고 가정하고 이후 과정을 소개해드리겠습니다

HTTP Response(응답) 결과로 JSON 형태의 데이터를 받았으니 해당 데이터를 추출해야 합니다. [그림 8]의 26~28행과 같이 `res`를 텍스트로 변환한 다음 fromJSON() 함수에 넣어 실행한 결과를 `json` 객체에 할당합니다. 그리고 31번 행을 실행하여 콘솔 창에 출력된 `json` 객체의 구조를 파악합니다.
[그림 9]를 보면 `json` 객체는 원소가 1개인 리스트(list) 자료형입니다. 해당 원소명은 `response`입니다. 그리고 `response`는 원소가 2개인 리스트이며, 그 중 첫 번째 원소인 `header`에는 응답 상태코드와 관련된 내용이 포함되어 있습니다. 그리고 두 번째 원소인 `body`에 데이터가 포함되어 있습니다.
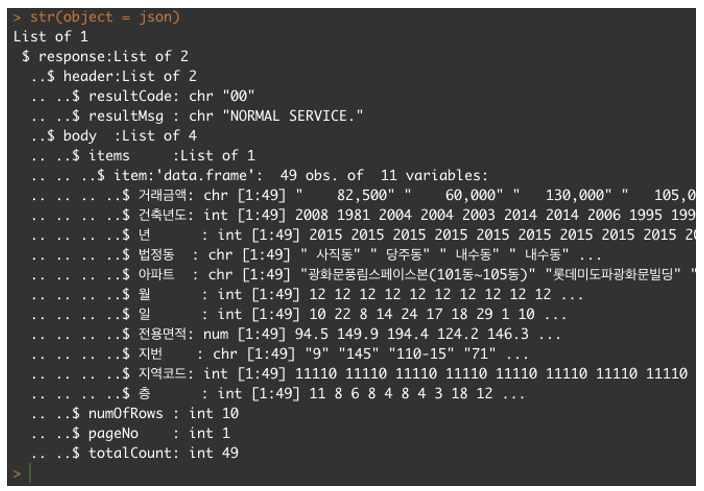
`body`의 첫 번째 원소는 `item`이고, 다시 `item`의 원소인 `items`는 우리가 원하는 데이터가 데이터프레임 형태로 저장되어 있습니다. 따라서 우리는 이 항목을 찾아서 새로운 객체(예를 들어, `df`)에 할당하면 나중에 시각화나 데이터 분석에 사용할 수 있습니다.
`body`의 두 번째 원소는 `numOfRows`로 한 번의 Request(요청)에 최대 10건만 제공한다는 의미이지만, 실제로 이 항목은 유명무실한 것으로 보입니다. 이미 `items`에 49건이 모두 저장되어 있기 때문입니다.
`body`의 세 번째 원소는 현재 페이지수, 네 번째 원소는 조회 조건에 해당하는 건수를 의미합니다. 그러니까 우리가 HTTP Request(요청)할 때 Query String에 ‘서울특별시 종로구'에서 ‘201512’에 거래된 아파트 매매 건을 조회 조건으로 주었던 것으로 떠올리면, 해당 건이 총 49건이라는 것으로 연결할 수 있습니다.
`json` 객체는 리스트이고, 우리가 필요한 데이터프레임까지 원소명이 있으므로 ‘$’ 기호로 연결하면 원하는 원소만 선택할 수 있습니다. [그림 10]의 34번 행을 실행하면 `df` 객체에 2015년 12월에 서울특별시 종로구에서 거래된 아파트 매매 49건이 저장됩니다. 35번 행을 실행하면 `df`에 저장된 내용을 확인합니다.

다음 회에는 데이터 분석 과정에서 가장 많은 시간이 필요하다고 알려진, 데이터 전처리에 대해 알아보겠습니다. (다음 회에 계속)
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 DBguide.net