
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 김승욱의 R을 R려줘 시즌I: 엑셀을 넘어 R 바다로! (4회) : 조건문과 반복문으로 분석 점프업!
작성자
관리자
작성일
2020-10-26 13:14
조회
1714
김승욱의 R을 R려줘 시즌I: 엑셀을 넘어 R 바다로! (4회)
조건문과 반복문으로 분석 점프업!
?| 김승욱 encaionkim@gmail.com 매쓰프리온의 데이터 분석실장으로 있으며 데이터 분석이 직업이자 취미이다. 주로 R과 관련된 활동을 하며 온오프라인 강의, 집필, 스터디, 멘토링 등 벌여놓은 일로 ‘고통’을 받고 있다. |
친구: 자~ 오늘의 고민 동무. 날래날래 노트북을 열어보시게나.
김 대리: 자자. 내가 압축을 한 번 풀어볼게. 심지어 이 압축파일 용량이 1MB도 안되거든?
김 대리: 파일 3000개가 뭐니 진짜… 심지어 폴더 하나에 들어 있는 것도 아니고.
?
보통 파일이나 폴더가 많은 경우는 보통 100줄 200줄을 쓰더라도 직접 손으로 입력하는 분들이 많습니다. 하지만 이렇게 개수가 많은 경우가 되어서야 포기를 하고 도움을 청하는 경우가 있는데 이번 상황이 딱 그러합니다. 데이터를 다루다 보면 각종 기초 서적이나 예제들처럼 파일 개수가 10개 이하인 경우가 대부분이지만, 점점 실력이 늘고 대용량 데이터베이스를 다루게 된다면 우선 맞닥뜨리는 난관이 파일 개수가 많은 경우 입니다. 단순히 파일 개수만 많으면 어떻게 해보면 되겠지만, 폴더 개수까지 많으면 힘들어집니다. 여기서 데이터 처리 시간을 많이 잡아먹는 상황은 파일 확장자가 통일되지 않거나, 내부 데이터 형식이 제각각인 경우입니다. 이 번 시간은 다음과 같은 조건 하에서 데이터 처리를 해보도록 합시다.
① 동일한 파일 확장자(csv)
② 규칙적인 파일명
③ 규칙적인 폴더명
④ 통일된 데이터 서식
위의 경우는 보통 단일 DB에서 파일들을 내려 받은 경우일 가능성이 높습니다.
?
※ 여기서부터 다음의 코드를 실행하여 파일과 폴더를 생성하세요.

파일, 폴더, 데이터의 정보를 전부 아는 경우라고 할지라도 되도록이면 확인 작업을 하는 것이 좋습니다. 물론 그 작업은 귀찮고 시간이 걸릴지라도 여유가 될 때 연습을 한 번이라도 한다면 실전에서는 당황하지 않고 더 빠르게 작업할 수 있겠죠? 그리고 지금은 파일 용량이 작지만 예를 들어 각 파일 용량이 100MB만 되어도 3000개면 약 300GB입니다. 이 경우 제대로 확인을 하지 않으면, 데이터 전처리를 하고 후에 분석을 하다가 문제점을 발견하는 순간 상당히 많은 시간 손실을 감수해야 합니다.
?
? 동작 그만!! 이거 맞아?
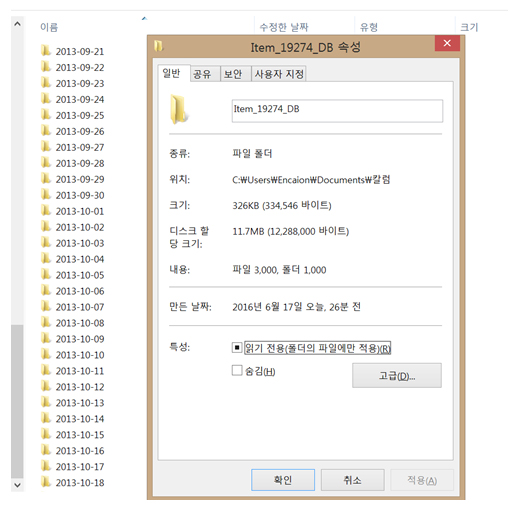
먼저 폴더 형식부터 확인 해봅시다.?

연-월-일 형식으로 폴더명이 지정돼 있는 것 같습니다. 앞에서 배운 내용을 활용하여 검사해보겠습니다. 먼저 폴더명 길이를 확인하고 모든 폴더 이름의 길이가 같은지 알아보겠습니다.

table() 함수로 확인을 해보니 각 폴더 이름의 길이가 모두 12라고 나왔습니다. 이렇게 되면 폴더가 전부 같은 서식으로 명명되었다고 생각할 수도 있습니다. 그러나 절대 방심은 금물입니다.
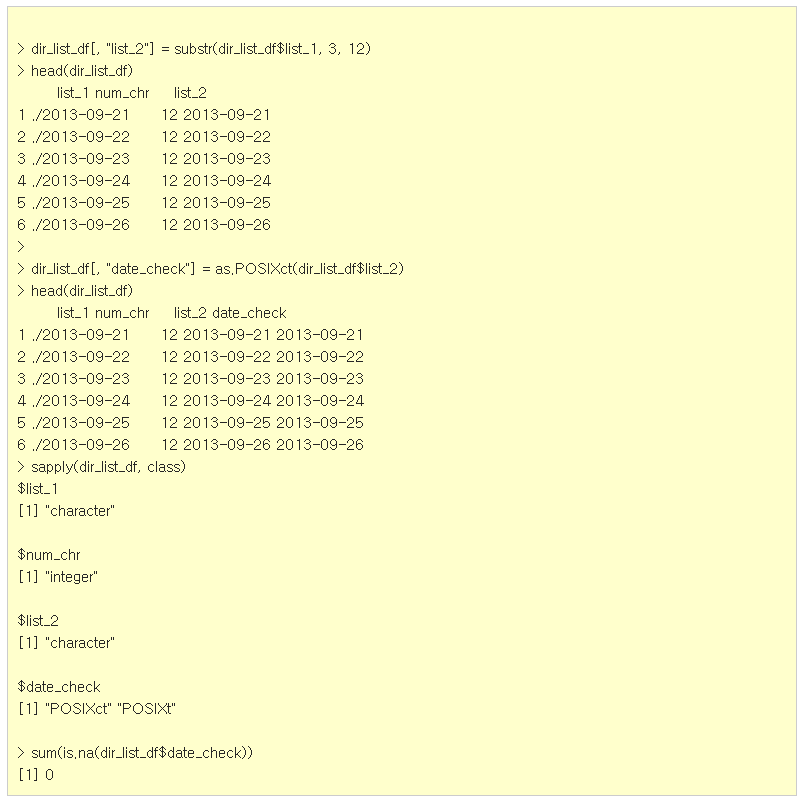
? as.POSIXct() 함수 활용
?
먼저 substr() 함수를 사용하여 온점과 슬래시 특수문자를 제외 한 후 list_2라는 새로운 column을 만들었습니다. 그리고 list_2 column을 시간 속성(POSIXct)으로 변환하고 sapply() 함수로 확인하였습니다. 특히 as.POSIXct() 함수는 R에서 지원하는 표준 날짜 표기 형식을 준수하지 않으면 가차없이 결측값(NA)을 반환합니다. 그렇기 때문에 sum() 함수와 is.na() 함수를 중첩하여 결측값 개수를 확인하였습니다. 결과는 0으로 나왔습니다. 결측치가 존재하지 않고, 모든 폴더명이 표준 날짜 표기 형식을 준수한다는 뜻입니다.
이제 드디어 데이터를 모은다고 생각하실 수 있겠으나 아직 멀었습니다. 얼핏 봐서는 매일매일 생산된 데이터가 각 폴더에 있는 것처럼 보이는데 정말 그렇게 기록되어 있는 것일까요? 중간에 시스템 장애가 있었거나 여러 가지 사유로 데이터가 수집되지 않은 날은 없었을까요? 귀찮겠지만 확인이 필요한 시점입니다.

이 작업은 두 번째 코드 한 줄로 끝나는 것이지만 이해를 돕기 위해서 첫 번째 코드를 추가하였습니다. 앞에서 sapply() 함수를 활용하여 "date check" column이 날짜/시간 형식으로 되어 있는 것을 확인했었습니다. 여기서 단순히 두 시간 값의 차를 구하면 위 코드의 결과와 같이 출력이 됩니다. 여기서는 첫 번째 코드를 통해 정확하게 1일 차이가 있다는 것을 알 수 있습니다. 그리고 두 번째 코드에서 table() 함수를 활용하여 각 폴더 간 날짜가 얼마나 차이가 나는지 확인하였습니다. 1이 999개 있는 것을 보아 전부 1일씩 차이가 나는 것을 알 수 있습니다.
데이터 확인은 여기까지 하도록 하겠습니다. 만약 추가로 더 해야 한다면 폴더 안의 파일까지 검사를 해야겠지만 생략하겠습니다.
?
? 꼼꼼하게, 민첩하게
드디어 수많은 파일을 착착 모으는 작업을 시작해봅시다. 그런데 아직 폴더 안을 안 봤죠? 탐색기로 열지 말고 R에서 처리합시다.
?
먼저 2013년 9월 21일 폴더로 이동해 파일 목록을 확인하였습니다. 파일은 3개가 있는데 여기서 "POS"로 시작되는 파일에 대한 데이터를 취합하게 됩니다. 일단 다른 폴더에도 "POS"로 시작되는 이름을 가진 파일이 있는지 확인해 보았습니다. 참고로 네 번째 코드는 상위 폴더로 이동하는 것을 의미합니다.
이제 코드를 짭니다. 한방에 갑시다!
?

먼저 for() 반복문 앞의 코드는 반복문을 실행하기 전 폴더 목록과 읽어들인 파일 내용을 저장할 데이터 프레임 객체를 생성하는 것입니다. for() 반복문의 첫 번째 코드는 앞에서 만들었던 폴더 목록인 dir_list_T 객체를 활용해 작업 폴더를 지정하는 코드입니다. 변수 n이 1부터 1000까지 바뀜에 따라 작업 폴더도 바뀝니다. 여기서 이동하는 작업 폴더는 기존 작업 폴더에서 한 단계 아래로 내려가는 것이기 때문에 반복문 끝에 setwd("..") 코드를 넣어 이동한 폴더에서 작업이 끝나면 상위 폴더로 이동하도록 하였습니다.
여기에서 이해하기가 난해하면서도 어쩌면 핵심이라고 할 수 있는 코드는 중괄호 안 여섯 번째 줄입니다. POS_data 객체에 data_sub 객체의 내용을 집어넣는데 벡터연산을 사용하고 있습니다. 코드 동작 원리는 반복문이 실행되면서 POS_data 객체에 새로 불러온 데이터(data_dub)를 계속 붙여 나가는 것입니다. 흔히들 쓰는 rbind() 함수를 활용하면 코드 작성자/해독자 입장에서도 편할지 모르지만, rbind() 함수 대신 벡터연산을 사용하면 속도가 빠르기 때문에 작업량이 많은 경우 벡터연산 코딩을 권장합니다. 마지막에 print() 함수로 출력을 하게 하였습니다. 아무래도 작업량이 많은 경우 현재 컴퓨터가 제대로 연산을 수행하고 있는지, 얼마나 진행 되었는지 나타낼 수 있도록 했습니다.
김 대리: 와. 깔끔하게 끝났네!
친구: 그럼. 밥값은 해야지.
김 대리: 그나마 폴더, 파일 이름이 복잡하지 않아서 다행이다.
친구: 맞아. DB 출처가 각각 다르거나 심지어 불규칙하게 특수문자라도 들어가 있으면 정말 힘들어.
김 대리: 그렇게 되면 문자열 처리하느라 꽤 애먹겠다.
친구: 그건 나중에 생각하고. 일단 내 방으로 가서 치킨이나 배달 시켜서 먹자. 마침 쿠폰을 받아서 말이지.
김 대리: 그래그래.

다음 회에서는 ggplot2 패키지를 활용한 데이터 시각화에 대해서 알아보겠습니다. 더 이상 엑셀에서 헤매지 마시고 프로답게 그려봅시다! 예습 하실 분은 http://docs.ggplot2.org/ 또는 google 검색 창에 ggplot이라고 입력하여 여러 가지 다양한 그래프를 확인해 보세요. (다음 회에 계속)
?
출처 : 한국데이터베이스진흥원
제공 : 데이터 전문가 지식포털 DBguide.net
?
?
?