
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 파이썬에서 페이스북 데이터 수집과 분석
정광윤의 개발자를 위한 파이썬 데이터 분석(4회)
파이썬에서 페이스북 데이터 수집과 분석
?| 정광윤 반도체 업체에서 생산 관리 업무를 통해 데이터 분석을 시작했다. 이후 프로그래밍이 즐거워 파이썬을 이용한 데이터 분석에 관심을 갖고 있다. 인문학 전공자 대상의 파이썬 강의를 진행하였으며, 인공지능을 이용한 서비스를 개발중인 스타트업의 대표이자 요즘도 주말마다 스터디 그룹을 운영하고 있다(initialkommit@gmail.com). |
매번 글을 진행하면서 좀 더 쉽고 재미난 것들을 소개해야겠다고 생각을 많이 했다. 그래서 지난 3회는 트위터에서 나오는 데이터를 이용해 전처리 작업과 분석을 살짝 곁들이는 방식으로 진행을 해보았다. 데이터 처리와 분석에 도가 튼 독자라면 시시할 수도 있었겠지만, 소셜 미디어 데이터를 분석하는 트렌드를 따라 해보며 분석이 흥미로운 과정일 수 있음을 알려드리고 싶었다.
이번 회 글을 준비하면서 어떻게 접근할 것인지 많은 생각을 해보았다. 첫 번째 고민은 역시 어디에서 유용한 데이터를 가져올 수 있나였다. 그리고 두 번째 고민은 과연 그 데이터는 재미있을까였다. 필자에게 진지하게 데이터를 분석하는 것은 맞지 않나 보다. 처음부터 정통 데이터 사이언티스트를 걸었던 분들은 통계기법을 활용해 분석하길 원하겠지만, 이번 연재는 무엇보다 데이터 분석의 흥미를 유발하고 싶다는 생각이 매우 컸다.
그래서 많은 사람이 흔히 접하고 재미난 데이터의 원천인 '페이스북'을 생각하게 되었다. 지난 3회 연재와 마찬가지로 소셜 미디어를 주제로 소개하는 것이다. 하지만 지난 회에 소개한 트위터의 경우는 우리나라에선 아직까지 안 하는 사람도 많고 데이터를 확보하기 위해 많은 시간이 필요하다. 실제로 필자도 이틀 동안 데이터를 모아야 했다.
이번 회에는 최근 들어 데이터 레이어로 많이 쓰이는 JSON 형태를 다루게 될 것이다. 이런 형태의 데이터를 분석하는 것은 좋은 경험이 될 것이다. 트위터와 마찬가지로 페이스북도 API를 이용해 데이터를 가져올 것이다. 그런데 페이스북의 API에는 이름이 있다. Social Graph API가 그것이다.
?
1. 페이스북 API 이해하기
페이스북이 어떤 서비스인지는 굳이 설명이 필요 없을지 싶다. 그래서 서비스 관점보다는 데이터 관점에서 살펴보도록 하자. 페이스북의 1억 사용자의 절반 이상이 매일같이 상태 갱신, 사진 게시, 메시지 교환, 실시간 채팅, 실제현장 확인, 게임, 쇼핑 등을 활용하고 있다고 한다. 그 안에서 수없이 많은 데이터의 흐름이 있을 건 분명하다. 물론 우리가 1억 사용자의 데이터를 다 볼 것은 절대 아니다. 여기서는 나와 밀접하게 관련된 사람의 데이터가 궁금할 것이라고 보고 소개한다.?
? 1) Social Graph API
먼저 우리는 페이스북으로부터 데이터를 수집해야 한다. 어떤 문제든지 데이터를 획득하는 과정은 필요하다. 특별히 페이스북의 경우, 페이스북에서 제공하는 API를 통해 데이터를 수집할 것이다. 페이스북은 많은 데이터가 생성되는 거대한 시스템이다. 그리고 많은 API가 있는데 우리는 Social Graph API를 사용하여 데이터를 얻을 것이다.먼저 https://developers.facebook.com/tools/explorer에 들어가 보자.
API를 사용하기 위해서는 액세스 토큰(Access Token)이 필요하다. 그러나 페이스북은 탐색용으로 주어지는 액세스 토큰으로 먼저 몇 가지 테스트를 해볼 수 있는 장치를 마련해놓았다. 위 링크에서 마음껏 실행해볼 수 있다. 그러나 필자는 따로 앱을 만드는 방법을 아래에 소개하겠다.
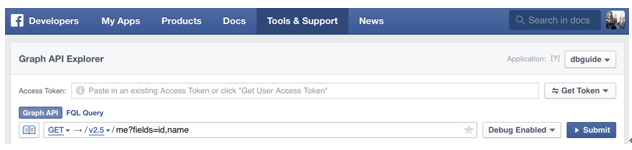
[그림 1] 페이스북의 Social Graph API 페이지에서 ‘dbguide’ 앱 작성
이를 위해서는 먼저 상단 메뉴의 ‘My Apps’에서 새로운 앱 만들기를 통해 App을 만들어줘야 한다. 물론 돈이 드는 것은 아니다^^. 아주 간단하게 ‘Next’ 버튼 몇 번만을 클릭해 앱을 만들 수 있다. 처음에 앱 만들기를 선택하면 안드로이드 앱인지 Web site인지 묻는 질문에서 Web site를 선택한다. URL을 적는 부분은 등록한 도메인이 없으므로 아무거나 적어도 전혀 상관이 없다.
필자는 위 그림에서 우측 상단에도 보이듯이 ‘dbguide’라는 이름으로 앱을 만들었다. 이제 아래에 있는 Get Token 버튼을 눌러 Get User Access Token을 통해 Access Token을 획득할 수 있다.
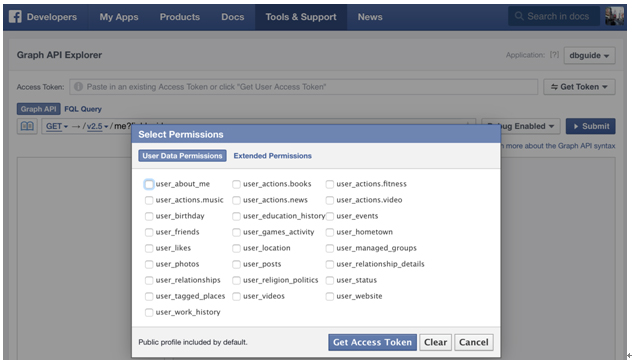
[그림 2] Access Token 획득
[그림 2]와 같은 화면이 나올 것이다. 여기에서 독자가 얻고자 하는 Permission을 체크해 Get Access Token을 클릭하면 된다.
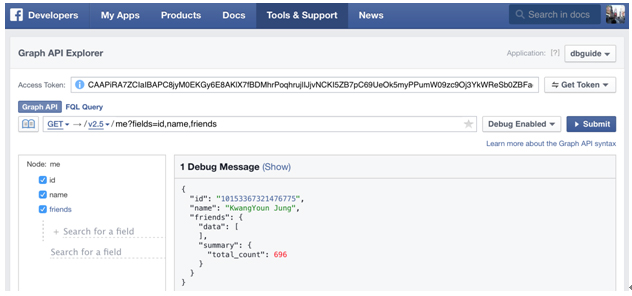
[그림 3] Submit 버튼을 눌러 데이터 확보
필자는 'user_friends' Permission에 체크하여 액세스 토큰을 획득했다. 그리고 위와 같이 id,name,friends를 적고 Submit 버튼을 눌러 데이터를 얻을 수 있었다. 하지만 앞서 만든 앱은 해당 앱을 설치한 사람의 목록만 볼 수 있다. 따라서 페이스북에서 제공하는 기본적인 액세스 토큰을 이용해 내 친구의 목록 모두를 볼 수 있도록 연습해보면 좋을 것이다. 우측상단의 dbguide 앱 대신에 Graph API Explorer를 다시 선택하여 아래와 같이 연습해보자.
GET 부분에 다음과 같이 적고 Submit 버튼을 클릭해보자.
● me?fields=id,name,friends
● me?fields=id,name,friends.limit(10)
● me?fields=id,name,friends.limit(10).fields(likes)
위의 결과물은 매우 재밌을 것이다.
?
? 2) JSON
자 여기서 중요한 것은 요청했을 경우 응답을 어떻게 받는 것인가이다. 응답의 형태는 가운데 화면의 { ... } 형태다. 이것이 바로 JSON으로, Javasscript Object Notation의 약자다. Javascript라는 스크립트 언어 문법에 중괄호({..})로 있는 것을 객체(Object)라고 부른다. 즉 Javascript의 객체 표기법을 그대로 사용해 데이터를 표현하고 있는 방법이 JSON이다. 형식은 다음과 같다.{
key: value,
key: value,
key: value,
.
.,
}
어디서 많이 본 형태 아닌가? 맞다. 이것은 파이썬에도 있는 형태다. 파이썬에서는 사전 객체라고 부르는 것이다. 굉장히 직관적인 데이터 구조의 형태를 갖고 있다. 해당 key에 대한 value(값)로 구성돼 있다. 매우 간단하다. 중첩(nested)되게 사용하면 매우 훌륭한 데이터 구조를 갖게 된다. 이런 형태를 이용하는 것이 바로 NoSQL인 MongoDB다.
?
2. 친구의 ‘좋아요’ 분석하기
어느 정도 페이스북의 API 다루는 연습이 되었으리라 생각한다. 이제는 데이터를 획득할 수 있다. 하지만 분석은 안 된다. 분석을 하기 위해서 설치해야 할 패키지가 있다. 다음을 실행하여 패키지를install requests다만 facebook-sdk는 아직 Python3.5를 지원하고 있지 않다. Python3.4까지 지원하고 있음을 코딩 시 참고하기 바란다.
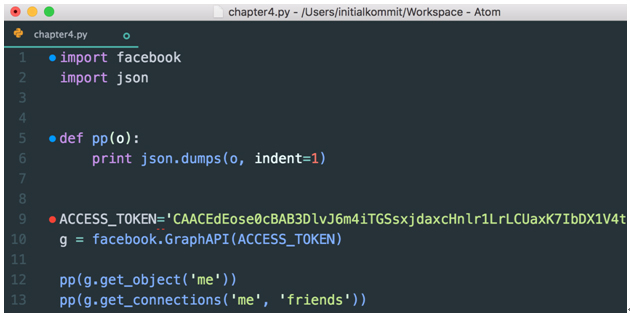
[그림 4] 파이썬에서 facebook-sdk 실행
이어서 [그림 4와]와 같이 작성을 해보자. 단 위 그림의 ACCESS_TOKEN은 앞서 실습했었던 Graph API Explorer에 있던 것으로 적으면 된다. 그리고 아래와 같이 실행해 보자.
> python chapter4.py
그러면 JSON 형태의 데이터를 받을 수 있다. 자, 이제 실제로 친구의 ‘좋아요’ 버튼 목록을 가져와보자.
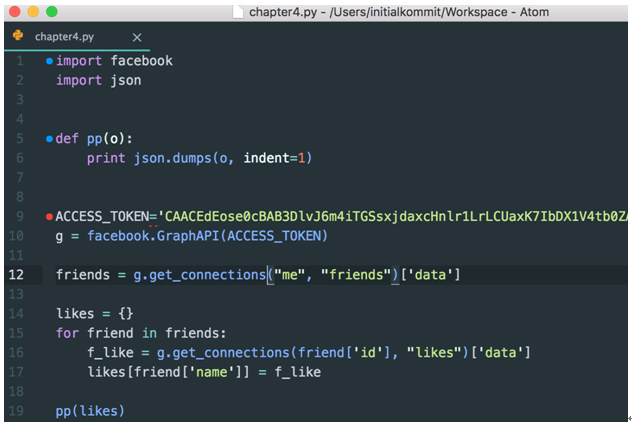
[그림 4] 파이썬에서 친구의 ‘좋아요’ 버튼 목록 가져오기
이번에는 [그림 4]와 같이 작성해 보도록 하자. 친구들의 목록을 ‘friends’라는 변수에 담고 해당 친구의 좋아요 정보를 가져와(g.get_connections(friend['id'], "likes")['data']) likes라는 사전 객체에 저장하였고 이를 출력해본 것이다. 다소 시간이 걸릴 수 있으나 결국 정보가 나오는 것을 확인할 수 있다. 이런 걸 직접 해보면서 느낀 건 참 무서운 세상이라는 거다(?).
이번에는 실제로 분석을 해보자. ‘좋아요’를 누른 페이지가 분명 ‘중복될 수 있다’는 가정을 세울 수 있다. 그렇기 때문에 과연 내 친구 사이에서 어떤 페이지가 ‘좋아요’를 많이 눌렀는지 분석해볼 수 있다. 다음과 같이 해보자.
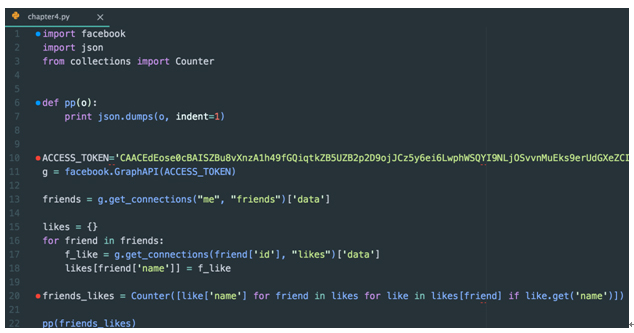
[그림 5] ‘좋아요’를 많이 클릭한 페이지 찾기
[그림 5]의 20번째 줄이 좀 어렵게 보이긴 하다. 이 것은 2개의 반복문에 1개의 조건문을 한 줄로 나타낸 것뿐이다. 이런 방법도 있으니 참고하기 바란다. 그런데 처음 본 것도 있을 것이다. from collections import Counter이 그것으로, 이것은 도수분포를 생성해주는 역할을 한다.
결과물은 어떠한가? 중복된 수가 많지 않지만 도수분포 결과물을 보여주고 있다.
3. 공통된 ‘좋아요’
마지막으로 내가 ‘좋아요’ 버튼을 누른 것과 친구들이 ‘좋아요’ 버튼을 누른 것의 공통 항목을 찾아보도록 하겠다. 이를 통해 나와 비슷한 성향을 가진 친구들을 찾아보는 것도 흥미로울 것이다.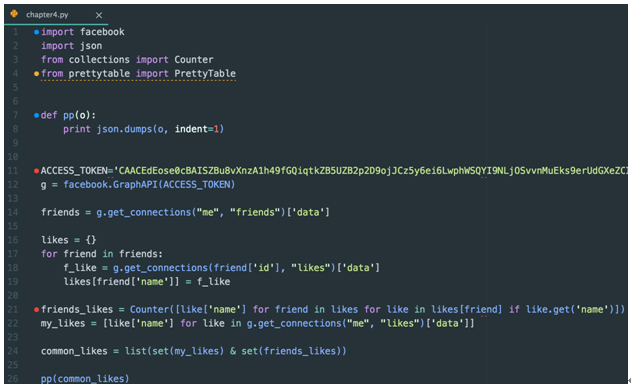
[그림 6] 중복된 값을 common_likes 리스트에 담기
위와 같이 친구들이 ‘좋아요’를 클릭한 목록(friends_likes)과 내가 ‘좋아요’를 클릭한 목록(my_likes)을 set 객체로 만들어서 두 개의 중복된 값을 common_likes라는 리스트에 담아보았다.
(list(set(my_likes) & set(friends_likes)))
이로써 지난 회에는 트위터에서, 이번 회에는 페이스북에서 데이터를 가져와 분석해보는 것을 알아보았다. 복잡하고 어려운 것보다 되도록 흥미를 가질 만한 주제를 다루었다. 어려운 통계 기법을 사용하면서 분석해보는 것을 피했다. 초급자의 눈에 맞춰 데이터 분석은 재밌고 좋은 인사이트를 얻을 수 있음을 말해주고 싶었다. 데이터 분석이 흥미로운 과정이라는 생각이 들면, 그때부터 본격적으로 중급 과정에 도전해볼 수 있기 때문이다. 최근의 경향을 반영해 소셜 미디어의 데이터 분석을 주제로 소개했다. 수없이 많은 데이터가 쏟아져 나오는 시대다. 이런 데이터를 나에게 맞게 유의미하게 사용하는 데이터 과학자, 데이터 분석가가 되길 소망한다. (다음 회에 계속)
?
출처 : 한국데이터베이스진흥원
제공 : 데이터 전문가 지식포털 DBguide.net
?
?