
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] 파이썬에서 소셜 데이터 수집과 분석
작성자
관리자
작성일
2020-10-26 10:25
조회
2744
정광윤의 개발자를 위한 파이썬 데이터 분석(3회)
파이썬에서 소셜 데이터 수집과 분석
?지난 회에는 데이터 과학에서 매우 유명한 Kaggle이라는 곳의 타이타닉호의 문제를 분석해보았다. 어느 등급의 승객이 생존할 확률이 높았는지, 나이대는 어떻게 되었는지 등을 분석해 이를 차트로 그려보기까지 하였다.
Kaggle의 타이타닉 문제는 너무 유명해서 이미 풀어봤던 독자도 있을 수 있다. 그럼에도 지난 2회 연재에서 Kaggle의 타이타닉 문제로 분석을 해본 것은 파이썬으로 처음으로 데이터를 분석해본 독자를 대상으로 했기 때문이며, '데이터 분석'이라는 관점에서 쉽게 접근해볼 수 있는 문제였기 때문이다.
다만, 문제가 좀 있었다. 생각해보면 Kaggle이라는 유명한 곳에 타이타닉의 문제를 해결하기 위해 이미 데이터가 잘 준비돼 있었다는 것이다. 물론 Null 데이터 등 프로세싱 과정이 필요했지만 우리는 데이터 컬렉션 과정을 매우 쉽게 넘어갈 수 있었다.
하지만 현실의 세계에서는 어떠한가. 데이터를 획득하는 과정 자체가 쉽지가 않다. 소위 ‘구글신’이라는 구글조차도 유저의 데이터를 확보하기 위해 무료 서비스를 내놓는 걸 보면 데이터를 수집해 유의미한 정보 혹은 서비스를 만들어내는 과정은 쉽지 않다고 볼 수 있다.
또 다른 문제가 있다. 2회차에서는 좀 더 데이터 ‘과학자’스럽게 문제에 접근했다는 것이다. 사실 특별히 문제라고 볼 순 없다. 하지만 이번 회에서는 좀 더 '개발자'스럽게 접근해보고자 한다. 그래서 여러 프로그래밍을 해볼 예정이다. 아래 두 가지 관점에서 글을 시작하고자 한다.
1 실생활에서 데이터 수집하기
2 '개발자'스럽게 데이터 분석하기
실제 생활에서는 여러 가지 문제에 접근할 수 있다. 하지만 이번 회에서는 전 세계적으로 많이 쓰이고 데이터가 흘러 넘치는 트위터의 데이터를 이용해보고자 한다.
트위터에서 트위트되고 있는 데이터에서 파이썬, 자바스크립트, 루비(Ruby)라는 프로그래밍 언어의 인기도를 한번 분석해보겠다.
?
? 준비하기
여기에서 사용하게 될 패키지를 먼저 설치하겠다.1. pandas
2. matplotlib
3. json (이미 내장돼 있음)
4. re (이미 내장돼 있음)
5. tweepy
위 패키지 1, 2번은 이미 1회에서 설치법을 다루었기 때문에 5번 tweepy만 아래에서 설치 방법을 소개하겠다.
?
? 1단계: Twitter API Key 획득하기
우리가 흔히 접할 수 있고 또한 쉽게 데이터를 획득할 수 있다. 그 이유가 바로 API에 있다. API는 Application Programming Interface의 약자이다. 즉 프로그래밍 언어로 어플리케이션에 접근할 수 있는 인터페이스다. 벌써부터 '개발자'스럽다. 지난 회에는 Kaggle.com에서 아주 쉽게 타이타닉 관련 엑셀 파일을 다운받아 바로 분석만 하면 됐지만, 이번에는 넘어야 할 산의 높이가 다르다.우리가 트위터로부터 데이터를 가져오기 위해서는 아래 4가지 정보가 필요하다.
1. API Key
2. API Secret
3. Access Token
4. Access Token Secret
위 네 가지 정보를 얻기 위해서 아래의 과정을 따라 해보도록 하자. 이미 트위터 계정이 있다는 것으로 가정하겠다.
1. https://apps.twitter.com/에 접속한다.
2. 우측 상단의 'Create New App'을 클릭한다.
3. 양식들에 값들을 적당히 채우고(이름, 설명, 웹사이트(아무거나 입력 가능)만 입력해도 된다.) 'Create your Twitter application'을 클릭한다.
4. 'Keys and Access Tokens' 탭으로 이동하면 Consumer Key(API Key), Consumer Secret(API Secret)이 있다.
5. 그 아래를 보면 'Create my access token' 버튼이 있고 이를 클릭한다.
6. 'Access token'과 'Access token secret'이 생성된다.
?
? 2단계: Twitter API에 연결해 데이터 다운로드 받기
우리는 트위터 API에 접근하기 위해 파이썬으로 만들어져 있는 특정 라이브러리를 이용할 것이다. 참 감사한 일이다. 이런 모든 게 오픈소스로 이미 만들어져 있다. 바로 Tweepy가 바로 그것이다.아래와 같이 터미널에서 입력해 설치를 한다.

아래와 같이 소스를 작성해서 twitter.py로 파일을 저장하도록 하자.
?

?
맨 상단에 앞서 설치한 tweepy의 클래스를 선언하는 부분을 볼 수 있다. 여기서 선언한 각각의 클래스는 아래에서 설명하겠다. 그리고 우리가 트위터에서 생성시킨 API Key와 Access Token도 볼 수 있다. 이 정보는 필히 독자들이 각자 생성한 정보를 입력해야만 한다.
자, 이제 중간 부분인 ①에 선언한 StdOutListener라는 클래스를 보도록 하자. 이 부분은 수없이 많은 트위트를 가져와 print를 하는 역할을 한다. 나중에 우리는 이 print되는 것을 텍스트 파일로 저장할 것이다. 해당 클래스는 tweepy의 StreamListener라는 클래스를 상속받으며 on_data와 on_error라는 함수를 오버라이딩(덮어쓰기)한다.
이후 ② 부분에서 if 조건문이 보이는데 뭔가 이상하게 생겼다. 이것은 파이썬의 특징이다. 위에 작성한 내용을 twitter.py에 저장하고 이를 실행할 것이다. 이 if 조건문이 없으면 실행을 해도 위에 작성한 소스가 실행되지 않는다. 즉 커맨드 라인 인터페이스(CLI)에서 파이썬 파일을 실행할 때 이 조건문이 있으면 이를 먼저 실행하게 되는 것이다. 어렵지 않다.
그 아래를 보자. 우리가 위에서 선언한 StdOutListener 클래스를 통해 l이라는 객체를 하나 만들었, Access Token을 설정한 이후 stream = Stream(auth, l)을 통해 현재 트위터에서 발생되고 있는 트위트의 스트리밍을 객체로 만든 것이다. 객체의 모든 트위트를 다 저장할 순 없으므로 아래에 filter 함수를 통해 우리가 알고자 하는 파이썬, 자바스크립트, 루비만 필터링해 가져오도록 했다.
어떠한가?
파이썬이 익숙하지 않거나 더 나아가 프래그래밍 자체가 익숙하지 않은 독자들에겐 쉽지 않은 작업이다. 그래서 이 부분을 '개발자'스럽다고 할 수 있다. __name__은 무엇이고 객체는 무엇인지 헷갈리는 독자가 있을 수 있다.
코드 하나 하나가 이해가 안 될 수 있겠지만 제일 중요한 건 스트리밍되고 있는 트위트들을 가져오기 위해 트위터의 API 사용 승인 절차를 consumer_key, consumer_secret, access_token, access_token_secret을 통해 '나'를 인증 받아 거치는 것이다.
이렇게 무료 오픈소스인 tweepy 라이브러리의 도움을 받아 현재 트위터 서비스에서 스트리밍되고 있는 트위트에서 'python, javascript, ruby' 세 가지만 가져올 수 있게 됐다. 이제 이것을 아래와 같이 실행해 보자.

이 작업은 현재 트위터의 트위트 스트리밍에서 python, javascript, ruby라는 텍스트가 들어 있는 트위트를 실시간으로 계속해서 수집하는 것이다. 아니, 더 정확히 말하면 twitter_data.txt 파일에 해당 내용을 출력-저장하는 것이다. 따라서 이 작업에는 많은 시간이 걸린다. 좀 더 의미 있는 데이터를 얻기 위해서 많은 양이 필요하다. 이틀 정도 쉬지 않고 돌리면 좀 더 의미 있는 내용으로 분석이 가능하리라 생각한다. 필자도 실제로 이틀에 걸쳐 계속 수집을 해보았다.

? 3단계: 수집된 데이터 확인하기
twitter_data.txt에 저장된 데이터는 JSON 형태다. JSON의 경우 자바스크립트 Object Notation의 약자다. 자바스크립트의 객체 표기법을 그대로 따라가기 때문이다. 그리고 아래와 같이 먼저 사용할 패키지를 선언해보도록 하자.
사용할 패키지를 위와 같이 선언하였으니 이번에는 twitter_data.txt에 있는 데이터를 읽어보도록 하겠다.

자, 여기서 데이터를 좀 더 쉽게 조작하기 위해서 DataFrame 객체를 하나 만들어보겠다.

그리고 위에서 만든 DataFrmae 객체인 tweets에다 트위트(text), 언어(lang), 국가(country) 정보를 넣어보자. 이 때 각각 text, lang, country라는 컬럼에다 tweets_data의 내용을 입력하게 되는데 사용한 함수가 map이다.

이제 우리가 데이터를 분석해볼 준비는 다 된 것이다! 우리는 지금까지 데이터를 수집했고 수집된 데이터를 DataFrame 객체에 넣어두었다. 이제 이 데이터를 이용해 차트를 만들어보도록 하자. 차트를 만들면 좀 더 쉽게 해당 정보를 파악할 수 있다.
첫 번째로 보게 될 차트는 언어별 트위트 순위이다.
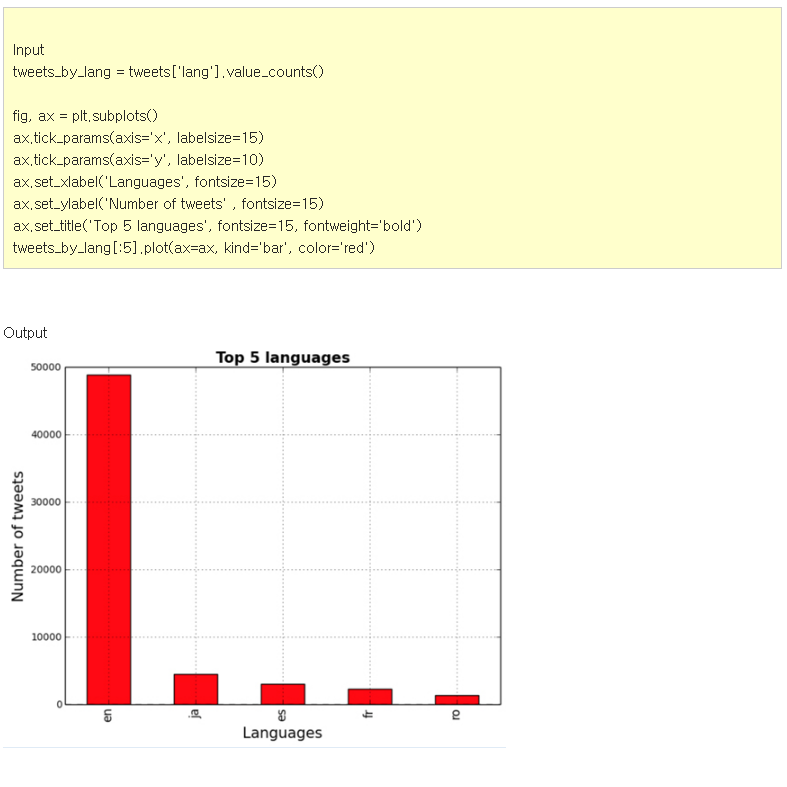
그 다음으로 볼 것은 국가별 트위트 순위이다.
?
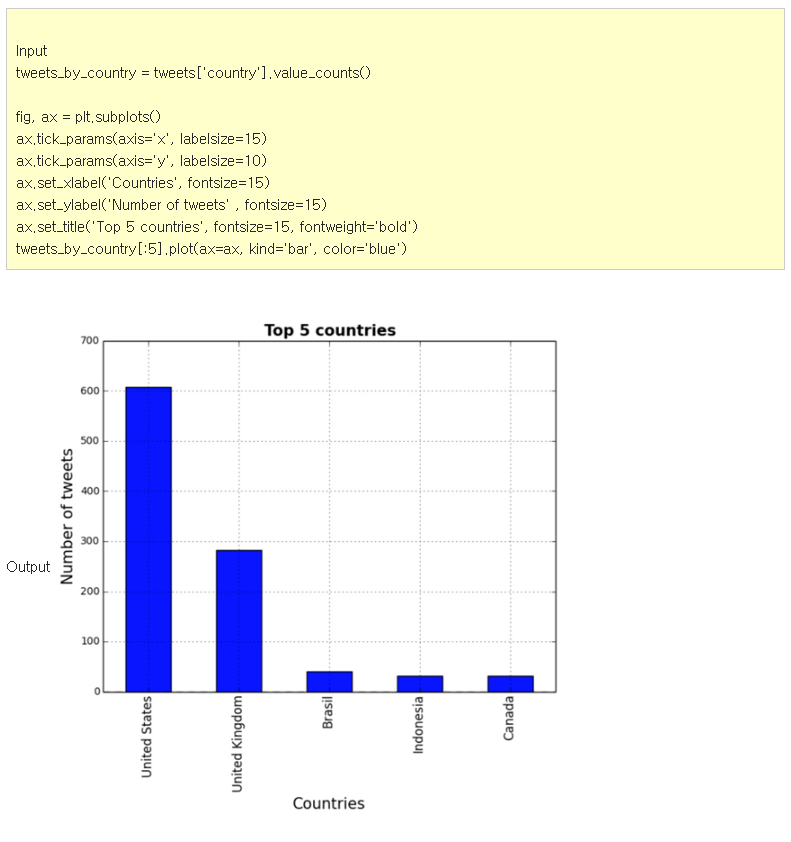
이렇게 위 두 차트를 통해 아주 단순한 통계 정보를 확인할 수 있었다. 물론 데이터는 각 사용자마다 다를 것이다.
?
? 4단계: 트위트 분석하기
단순한 통계 정보만으로는 어떤 언어가 인기가 있는지 확인할 수는 없다. 따라서 트위트 정보를 좀 더 분석해보는 작업을 해보도록 하자. 트위트의 내용에서 해당 언어(파이썬, 자바스크립트, 루비)를 추출해 낼 수 있어야 한다. 그래야 해당 트위트가 어떤? 그리고 나서 해당 언어(파이썬, 자바스크립트, 루비) 태그를 각 트위트에 달아볼 것이다. 꼬리표인 셈이다.어떤 특정 단어 추출을 위해 우리는 re라는 패키지를 사용할 것이다.

그리고 트위트에 특정 단어가 있는지 없는지를 파악하기 위한 word_in_text라는 함수를 하나 만들도록 하겠다. 만약 특정 단어가 있다면 True를 반환하게 된다.

이제 위에서 만든 함수를 이용해서 각 트위트에 해당 언어가 매칭이 되면 True를 반환시켜 3개의 컬럼에 값을 넣어주도록 하겠다. python, javascript, ruby라는 이 3개의 컬럼이 곧 태그가 된다.

이제 간단히 각 언어의 개수가 얼마나 되는지 출력해보도록 하자.

자 위에서 만든 정보만으로 우리는 비교 차트를 만들어 낼 수 있다! 아래와 같이 작성해보자.
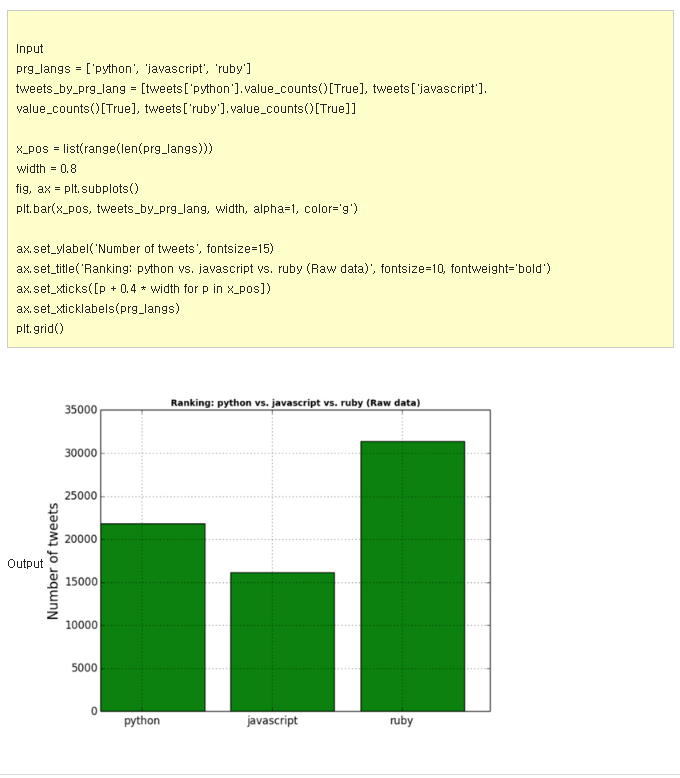
? 도전의 즐거움
이번 3회차에서는 트위터에서 스트리밍되는 트위트들을 실시간으로 모으는 형태로 데이터를 수집하고 텍스트 데이터를 분석해 카테고리화하고 간단한 차트까지 그려보았다. 사실 지난 회에 비해 데이터를 조작한다든가 차트를 만드는 분량은 많이 줄어들었다. 하지만 이 번 회의 초점은 실제 세상에 많은 데이터 중에 특별히 트위터에서 API를 이용해 어떻게 데이터를 수집할 것인지, 해당 트위트의 내용, 즉 텍스트를 분석하는 방법까지 보았다. 이렇게 이번 연재서는 좀 더 파이썬의 기술을 이용할 수 있었다. 다음 회에서는 다시 심화된 분석에 초점을 두려고 한다. (다음 회에 계속)?
출처 : 한국데이터베이스진흥원
제공 : 데이터 전문가 지식포털 DBguide.net
?