
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (4회) : 릴레이션십 구성과 관계 유형별 모델
작성자
관리자
작성일
2020-08-28 18:19
조회
1296
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (4회)
릴레이션십 구성과 관계 유형별 모델
| 필자: 노찬형
빅터플랫폼 CIO. 대학에서 소프트웨어공학을 전공했으며 개발자로 사회 생활을 시작했다. 사회 생활 10년을 넘기고 시작했던 DB 공부가 프로그래머로서 자신을 분명하게 되돌아볼 수 있는 기회를 주었다. 사회 초년생 또는 대학생에게 도움이 되는 데이터 모델링 글을 쓰고 싶은 게 그의 작은 바람이다. pemaker@gmail.com |
|
주경야독하는 이들을 위해 우연한 일이 계기가 돼 필자는 DB와 데이터 모델링을 글로 정리할 수밖에 없는 상황에 맞닥뜨렸다. 필자는 2012년부터 2013년까지 한 대학에서 DB 강의를 했다. 강의를 요청받았을 때, 어떻게 해야 할지 난감했다. 필자가 맡은 반은 낮에는 일하고 저녁에 공부하는 학생들로 구성돼 있었다. 일반 대학생들처럼 많은 시간을 공부에 쓸 수 없는 학생들에 DB를 알려줘야 했다. 어떻게 하면 그들에게 작으나마 도움이 될까 하고 고민하던중 시중 교재 대신, 필자가 직접 강의 자료를 만들어 보면 좋겠다는 생각을 하기에 이르렀다.물론 시중의 책이 부족해서 그런 것은 아니다. 필자가 자료를 직접 만들어 쓰면, 일반 책으로 했을 때보다 더 쉽게 소개할 수 있을 것 같아서 그랬다. 누가 보더라도 이해하기 쉽게 전달하겠다는 목표로 강의 자료를 만들기 시작했다. 2년 넘게 강의 자료를 준비하다 보니, DB의 기초와 데이터 모델링의 기초에 대한 내용을 어느 정도 만들어 낼 수 있었다. 학생들이 강의자료를 요청하면 줬다. 하지만 설명이 없는 프레젠테이션 문서라서 아쉬웠다. 설명이 추가되면 학생들이 예습/복습을 할 때도 훨씬 좋을 텐데…. 배웠거나 배울 학생들을 위해 프레젠테이션 문서를 글로 정리하기 시작했다. 말보다 글로 정리하는 게 더 어렵다는 걸 실감하는 순간의 연속이었다. ‘하늘 아래 새로운 건 없다’는 말처럼 필자의 강의 자료 역시 인식하든 못하든 수많은 자료와 가르침을 받았던 결과물들이다. 물론 보고 들었던 이론을 개발 현장에서 적용?확인하는 과정을 거친, 경험의 산물이다. 앞으로 몇 회에 걸쳐 ‘제로에서 시작하는 데이터 모델링’ 연재를 하겠다고 용기를 내보았다. 독자 여러분과 함께 쓴다는 생각으로 수많은 의견이나 접근 방법을 댓글 또는 이메일로 받을 수 있었으면 좋겠다. |
지난 3회에서 알아본 릴레이션십 구성에 대해 계속하여 알아본다.
? 릴레션이션십 구성
1) ELECTIVITYSELECTIVITY란 선택도를 의미한다. 하나의 데이터에 대해 선택될 수 있는가 없는가를 의미한다. 즉 SELECTIVIY는 상속받은 속성(자식ㆍ하위 엔터티의 속성)이 null일 수 있는지를 말한다.
Null은 대응하는 데이터가 없고, Not NULL은 대응하는 데이터가 있다는 뜻이다. 상속받았다고 해서 꼭 Not NULL은 아니다. 비즈니스에 따라서 null일 수도 있으므로 릴레이션을 설정할 때 null 여부에 따라서 알맞은 릴레이션을 설정해 주어야 한다.
단 식별관계일 경우는 부모ㆍ상위 엔터티의 속성이 자식ㆍ하위 엔터티의 식별자가 되기 때문에 Not NULL이 돼야 한다.
여기서 같이 알아야 할 점은 SELETIVITY에는 null 여부에 따라서 필수(mandatory)와 선택(optional)이 있다는 것이다. Mandatory는 Not Null이라는 뜻이고, Optional은 NULL이 가능하다는 말이다. Mandatory와 Optional은 앞서 소개했듯이 비즈니스에 따라서 결정하는 것이고, 모델링툴에서 지원하는 관계선을 잘 선택?설정해 주면 된다.
[그림 1] SELECTIVITY/Mandatory, Optional
SELECTIVITY를 구분하는 또 하나의 방법은 관계선이다. 관계선의 점선과 실선으로 필수 여부를 표기한다.
다음 [그림 2]와 [그림 3] 모델을 보면서 관계선을 해석해보자.
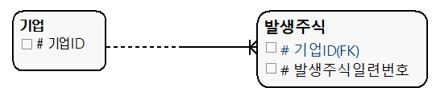
[그림 2] SELECTIVITY 관계선 해석 1
위 모델을 해석해 보면 ‘발생주식’은 부모ㆍ상위 엔터티인 ‘기업’이 필요하다. 하지만 기업 엔터티는 자식ㆍ하위 엔터티인 발생주식 엔터티가 없어도 무방하다. 일반적으로 부모ㆍ상위 측이 점선, 자식ㆍ하위 측이 실선이다.
이는 식별/비식별관계와는 독립적이다. 즉 식별/비식별과 SELECTIVITY는 다르게 또는 독립적인 관점에서 생각해야 한다.
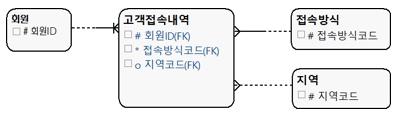
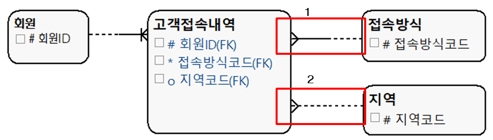
[그림 3] SELECTIVITY 관계선 해석 2
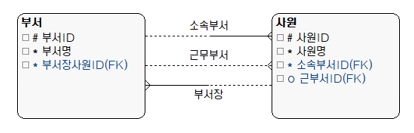
위 모델에서 ‘고객접속내역’은 실전으로 ‘회원’과 ‘접속방식’이 반드시 필요함을 나타내고 있다. 이에 비해 ‘지역’은 점선으로 처리됐으므로 선택적이라는 뜻이다. 회원과 접속방식 입장에서는 고객접속내역과 점선으로 피현했으므로 선택적 관계다. 회원은 고객접속내역이 없더라도 문제가 없음을 의미한다.
?
2) CARDINALITY
CARDINALITY는 관계가 있는 두 엔터티 사이에 데이터 대응 수를 의미한다. 사람마다 취미를 하나 또는 하나 이상을 갖고 있는 것처럼, 사람에 대응하는 취미의 수를 표기하는 것이다.
데이터 모델에서 CADINALITY는 1:M, M:M, 1:1이라는 3가지가 있다. 모델의 관계는 대부분 1:M의 CADINALITY로 표현된다. 3 가지 CADINALITY에 대해 알아보자.
(1) 1:M 관계
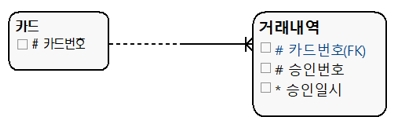
[그림 4] 1:M 관계
이런 관계는 가정 정상적인 릴리이션십이다. 논리모델에서 거론할 바는 아니지만 일반적으로 빈번하게 조인이 일어나며, 빈번한 조인이 발생하면 성능 저하가 발생할 가능성이 있으므로 조인에 대한 조인 방식과 조인 순서 최적화가 필요하다.
1:M 관계에서 SELECTIVITY에 따라 다음과 같이 3 가지 릴레이션이 발생할 수 있다.
?
① 1:M이면서 식별관계
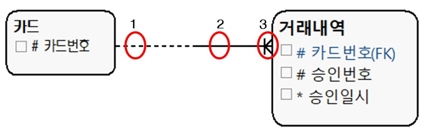
[그림 5] 1:M 식별관계
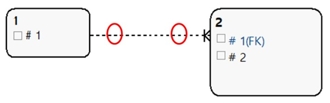
② 1:M이면서 비식별관계
[그림 6] 1:M 비식별관계
③ 부모가 반드시 하나 이상의 자식이 있어야 하는 관계
[그림 7] 1:M 부모가 반드시 하나 이상의 자식을 가져야 하는 관계
?
(2) 1:1 관계
[그림 8] 1:1 관계
모델에서 1:1 관계가 많이 나오면, 하나의 엔터티로 구성해도 무방할 가능성이 높으므로 모델을 재검토해 볼 필요가 있다. 하나의 엔터티로 구성해도 되는 것을 1:1 관계로 두 개의 엔터티로 구성하면, 빈번한 조인 발생으로 성능 저하 가능성이 높고, 데이터 정합성 위험도 따른다. 하지만 1:1 관계를 발견하면 기계적으로 통합 또는 분할하는 경우가 있다. 실제로 1:1 관계는 다른 관계들보다 사용 빈도가 매우 낮고 통합/분할 여부 결정이 어렵다.
통합하면 일부에서는 조인 감소로 유리하지만, 그렇지 않은 경우도 있으므로 업무 요소를 따져서 통합 여부를 결정해야 한다. 결국 모델링 초기에 1:1 관계가 나오면 서둘러 통합할 필요는 없다. 서둘러 통합하면 분리할 기회를 놓칠 수 있다.
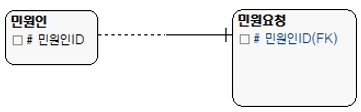
최종 모델에서 1:1 관계는 수직분할 때 나타날 수 있다. 1:1 관계에서 SELECTIVITY에 따라 다음과 같이 3가지 릴레이션이 발생할 수 있다. 다음 모델은 1:1 관계이면서 식별관계다. 식별관계 외의 식별관계가 있을 수 있다.
① 1:1이면서 식별관계
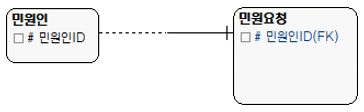
[그림 9] 1:1 식별관계
② 1:1이면서 비식별관계/Mandatory
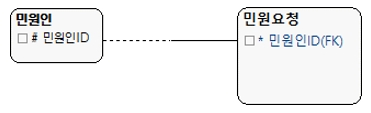
[그림 10] 1:1 비식별관계/Mandatory
③1:1 비식별관계/Optional
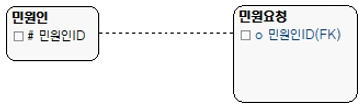
[그림 11] 1:1 비식별관계/Optional
?
(3) M:M 관계
M:M 관계는 논리적으로 존재한다. 현재 존재하는 DBMS에서는 지원하지 않기 때문에 물리로 변환할 때는 M:M 관계를 해소해 줘야 한다. 이 때문에 논리 모델링 시에 M:M이 나오는 경우, 물리변환을 고려해 M:M 관계를 해소하는 경우가 많다.
M:M 관계는 요리와 식재료의 예를 들 수 있다.
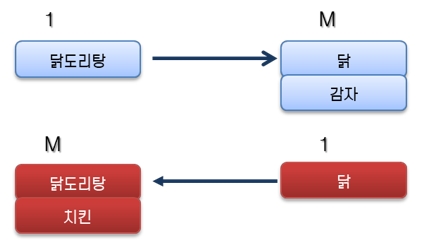
[그림 12] M:M 관계인 요리와 식재료
그런데 닭은 닭도리탕에만 들어가는 것이 아니라 치킨에도 들어간다. 이 때문에 반대로 M:1 관계가 발생하므로 결국 M:M 관계가 발생하게 된다.
이를 모델로 표현하면 [그림 13]과 같다.
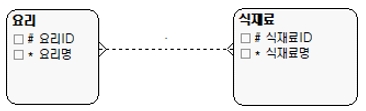
[그림 13] M:M 모델
M:M 관계는 이해?에서는 M:M 관계 도출도 M:M 관계를 풀어내는 것도 힘들다. 분명하게 이해하기 위해 위의 요리, 식재료 데이터를 예를 들어 조금 더 알아보자.
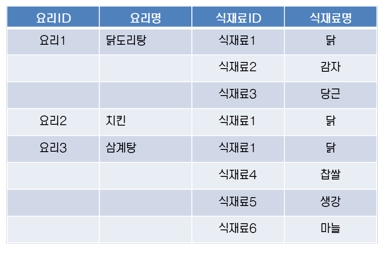
[표 1] 요리별 식재료 표
요리별 식재료를 [표 1]처럼 도출했다고 하자. 닭도리탕에는 닭·감자·당근이 들어가고, 삼계탕에는 닭·찹쌀·생강·마늘이 들어간다고 정리했다. 생각한 것을 익숙한 표로 작성하는 것은 쉽다. [표 1]의 요리와 식재료 표를 모델로 표현한다면 어떻게 할 수 있을까?
표를 자세히 보면 요리와 식재료가 연결됐음을 알 수 있다. 요리를 기준으로 정리했으므로 요리1에 식재료1, 2, 3이 들어간다. 즉 연결됐다고 할 수 있다. 이렇게 연결하기 위해서는 M:M 관계를 해소해야 한다. 관계를 해소하는 방법으로 요리와 식재료 사이에 연결, 릴레이션(교차) 엔터티를 만들어 관계를 설정해 주는 것이 있다.
다음 회에는 릴레이션십 가이드를 알아본다. (다음회에 예속)
?
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)