
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] ggplot2를 이용한 R 시각화
작성자
관리자
작성일
2020-10-23 14:15
조회
12486
ggplot2를 이용한 R 시각화
?
?
진짜 이유는 ggplot2의 문법에 기인하는데, 기본 그래픽에서는 데이터 입력 포맷에 대한 함수 내 규정을 상세하게 하고 있어 한번 그려 놓기도 번거로울뿐더러 같은 데이터로 다른 형식의 그래프를 그릴 때 다른 입력 포맷에 대한 적응과 적용이 필요하다. 그러나 ggplot2는 다른 그래프라 하더라도 문법 내에서 간단한 코드 추가/삭제로 플로팅을 할 수 있다. 하나의 데이터를 기반으로 이런저런 그래프를 많이 그려봐야 할 빅데이터 시대에서 가장 필요한 기술 중 하나가 아닐까 하는 생각을 해본다.
ggplot2를 설치하고 사용하기 위한 명령어는 아래와 같이 단 두 줄이다.
?
?
이 밖에 개발 버전을 사용해볼 생각이라면 아래와 같은 명령어를 사용하면 된다.
ggplot2의 매뉴얼은 R help 시스템에서 제공하는 것과 온라인으로 제공하는 것이 있는데, 가독성 측면에서 온라 메뉴얼(http://had.co.nz/ggplot2/)을 보는 것을 추천한다.
이 링크에서는 100여 개의 ggplot2 객체에 대한 소개와 함께 500여 개가 넘는 예제를 제공한다. 이 온라인 페이지는 늘 가까히 두고 익힐 필요가 있다. 그리고 필자가 ggplot2를 공부하면서 참고한 책은?이다. ggplot2에 대한 유일한 책으로 Hadley 교수가 친근한 단어로 쉽게 소개하고 있다. 다양한 시각화 기술을 포함하고 있으므로 ggplot2를 심도 있게 공부하고 싶은 독자께서는 반드시 봐야 될 책이라 할 수 있다. 그리고 이 글 역시 위 두 참고문헌을 기반으로 작성했음을 밝혀둔다.
일단 동기 부여는 이쯤에서 마치고, 실제 이 패키지의 근간이 된 ‘Grammar of Graphics’에 대해 알아보자. Grammar of Graphics는 데이터를 각 기하 객체(geometric object)의 미적 속성(aesthetic attributes)에 매핑하는 방법을 제공한다. 이를 통해 통계적인 시각화를 가능하게 하는 효과적인 방법을 제안한다. 이 와중에 통계적인 데이터 변환이 필요하다면 그 변환까지 수행해 준다. 국소(faceting) 시각화 기법을 사용하면 각 데이터의 부분 데이터만 사용해 여러 개의 그래프를 한꺼번에 그려주기도 한다.
먼저 문법(Grammar of Graphics) 설명 차원에서 데이터 하나를 소개한다.
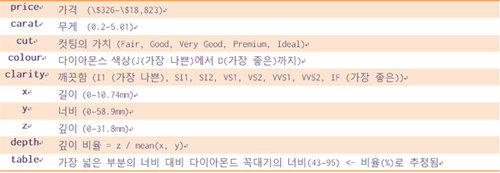
ggplot2를 로딩해 그 안에 포함된 데이터를 사용해 볼 수 있다. diamonds 데이터도 역시 패키지와 함께 배포되는 데이터다. 이 데이터에는 5만 4000여 개의 다이아몬드에 대한 가격을 포함한 10개의 속성 정보가 포함돼 있다. 아마도 다이아몬드의 가치에 대해 궁금한 독자라면 시각화에 관심이 더 갈 것이다.
ggplot2에서는 qplot라는 함수를 제공한다. 이는 R에서 기본적으로 제공하는 plot()과 유사한 인터페이스를 제공하는 데 목적을 둔 함수다. 이를 사용하는 예는 다음과 같다.
?
?
qplot() 함수의 형태는 plot()과 유사하게도 첫 번째 인자에 x축의 변수명이 오며, 이어서 y축의 변수명이 따라온다. 그리고 data라는 인자로 data.frame 형태의 데이터의 객체명을 입력받는 형식이다. 뒤 이어 오는 인자들은 ggplot2에서만 해당되는 특수 인자들이 오게 된다.
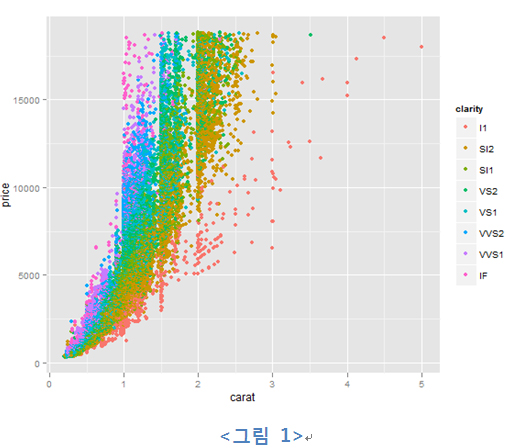
예를 들어 앞 코드 (1)을 실행한 결과는 다음과 같다.
이 그래프를 코드와 매핑해 보면 아주 쉽게 그 의미를 파악할 수 있다. 이 그래프는 x축은 caret를, y축은 price를 의미한다. 그래프의 종류는 각 점마다 point를 찍는 scatter plot을 그려준다. 이와 동시에 다이아몬드의 선명도(clarity)에 따른 컬러도 매핑을 시켜줬다.
?qplot()에 대한 설명은 더 이상 하지 않을 생각이다. 여기엔 이유가 있다. 일단 ggplot2를 다양하게 활용하기 위해서는 레이서(layer)를 잘 활용할 필요가 있다. qplot()으로는 문법을 효과적으로 활용하는 데 한계가 따른다는 점과 이 때문에 그래프를 핸들링하는 데 인터페이스 상의 복잡함이 존재한다는 점이다. 다른 한 가지는 qplot()으로는 문법을 배우고 가르치기가 어렵다는 것이다. 따라서 다음과 같은 플로팅 방식의 문법을 사용할 것이다.
물론 위 코드는 동일한 그래프를 플로팅한다.
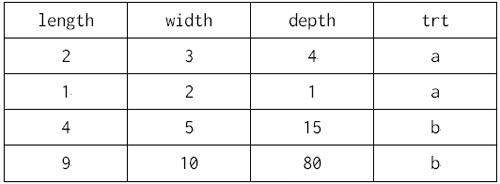
일단 간단한 데이터를 갖고 문법의 각 단계가 어떻게 적용되는지 살펴보자. 이 예제는 Hadley 교수의 발표자료에서 가져왔다. 이유는 내부 데이터가 어떻게 바뀌면서 각 문법이 적용되는지 ggplot2의 내부를 들여다 보기가 여의치 않기 때문이다. 이 점을 이해해주기 바란다.
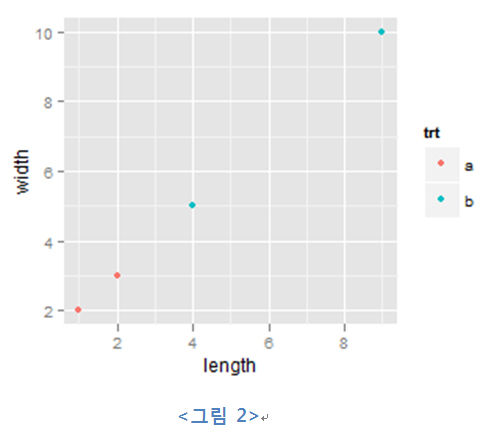
위 데이터의 length, width를 기반으로 아래와 같이 scatter plot을 그린다고 해보자.
일단 scatter plot은 각 축에 숫자형 데이터를 입력받아 좌표계에 점을 찍는 것이다. 점은 ggplot2에서 기하객체(geometric object)라고 불리며, 문법에서는 짧게 geom이라고 한다. 여기에는 점(points), 선(lines), 다각형(polygons) 등 많은 객체가 존재한다.
데이터를 플로팅 하기 위해 데이터의 각 레코드를 갖고 그래픽 요소에 매핑할 필요가 있다. 이를 ‘미적 요소 매핑(aesthetic mapping)’이라고 표현하며, ggplot2의 문법에서는 aes라는 함수가 이 역할을 한다. ‘aes(x=length, y=width)’ 코드가 의미하는 바는 x축에 length 컬럼을 매칭시키고, y축에 width 컬럼을 매칭시키라는 것이다.
미적 요소 매핑은 데이터의 각 속성을 그래프 속성에 매핑을 시킨다. scatter plot의 경우 좌표계 속성에 필요한 x, y, 점의 모양, 점의 크기, 점의 색깔 등이 그에 해당한다. 이를 위해 ggplot2 내부에서는 다음과 같이 데이터를 변환시킨다.
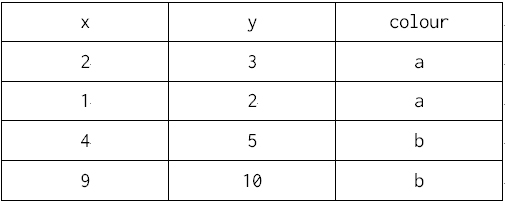
?
‘length→ x, width→ y, trt→ colour’로 변환된 것을 확인할 수 있다. 점의 크기나 모양은 매핑 속성에 없으므로 매핑되지 않았으나, 모두 같은 기본 값으로 암묵적으로 생성된다. 모양의 기본값은 속이 꽉찬 점이고, 점의 크기는 1이 기본값이다. 미적 요소 매핑은 어느 데이터가 어떤 곳에 쓰일지를 명시하는 작업이라고 생각하면 된다. 앞의 매핑된 데이터는 line chart에서도 사용될 수 있다. 잘 생각해보면 이들 그래프를 그리기 위해 필요한 것은 x, y축에 따른 값과 색상을 구분하는 변수뿐이다. 그러나 이런 그래프는 이 상황에서는 그다지 의미가 없으니 그냥 참고하기 바란다.
?
미적 매핑을 한 후에 진행되는 작업은 매핑된 데이터를 갖고 컴퓨터가 알아볼 수 있는 데이터로 변환시키는 것이다. 이는 흡사 디지털 카메라 자동 프로세스를 통해 이해하면 쉬울 것이다. 디지털 카메라는 피사체를 CCD에 매핑한 후 디지털 이미지화해 메모리에 저장하는 과정으로 작동한다. 컴퓨터가 이해할 수 있는 이미지 포맷으로 변환하는 작업이 바로 ggplot2의 스케일링(scaling) 작업이다.
x, y축 데이터는 이미지를 출력하는 대상에 맞게 변수 변환이 이뤄진다. ggplot2에서 사용하는 시스템은 grid이기 때문에 [0,1] 사이의 값으로 스케일링된다. 그리고 colour 값은 자동으로 사람의 눈으로 구분하기 쉬운 색상으로 매핑된다. 사람이 구분하기 쉬운 색상을 사용하기 위한 작업도 이뤄지는데 컬러휠(color wheel)을 구분하고 싶은 레벨 개수로 색상과 명암 기준으로 일정하게 분할해 색상을 매칭시킨다. ggplot2는 자동으로 이 작업을 해주기 때문에 다변량에 대한 그래프를 그릴 때 매우 편하다. 물론 사용자가 이 값들을 직접 정해줄 수 있다.
스케일링을 통해 나온 데이터는 다음과 같다.
재미있게도 x, y의 스케일링된 데이터 값은 동일한다. 이것이 앞 <그림 3>에서 어떻게 표현되는지 비교·확인해 보면 이해가 빠를 것이다.
사실 x, y의 변환된 데이터를 일반적인 직교 좌표계를 사용하거나 극 좌표계를 사용하느냐에 따라서 한 번의 변환이 더 일어난다. 기본값은 직교 좌표계이기 때문에 예상대로 출력된 것을 확인할 수 있다.
이들 데이터 말고도 하나의 그래프를 그리기 위해서는 더 많은 것이 필요하다. 예를 들면, 축(axis), 레전드(legend), 레이블(lable), 그리드(grid) 라인 등인다. 이들은 사용자가 직접 설정하지 않으면 기본값으로 출력된다. 이들을 직접 핸들링하기 위해서는 ggplot2의 테마(theme)와 관련된 매뉴얼을 찾아봐야 한다.
이상으로 개략적인 ggplot2의 동작 방식을 살펴봤다. 이 이외에 ggplot2에서 중요한 레이어(layer) 시스템이 있다. 이 레이어 시스템 덕분에 그래프 위에 다양한 정보를 추가해 그래프를 더욱 ‘정보성 있게’ 만들 수 있다.
이 코드에서 볼드 처리된 부분은 좌표계에 레이어를 씌우는 역할을 한다. ggplot2에서는 직관적으로 ‘+’ 연산자를 사용해 이를 연동한다.
이런 레이어를 플롯에 올릴 때 원 데이터는 다음과 같은 변환 과정을 통해 레이어 개별적으로 적용받는다.
1. 미적 매핑
2. 통계적인 변환(stat)
3. 기하객체에 적용(geom)
4. 위치 조정(position adjustment)
1번과 2번 사이에 스케일링이 작업이 들어간다는 것을 명심하자. 4번 위치 조정의 경우 동일 좌표계에 여러 종류의 그래프를 올려놓기 위해 개별 레이어의 위치 정보에 대해 학습(train)을 하는 과정이 포함된다. 만일 이 과정이 없다면 특정 레이어에 특화된 스케일만 적용돼 적절하지 못한 그래프가 출력될 것이다.
아래 두 코드는 같은 그래프를 그린다. 사실 qplot()은 ‘+’ 연산자 없이도 그래프 한장을 그리고 아래 코드의 (2)는 앞 부분만 실행하면 그래프가 생성되지 않는다. 이유는 그래프를 플로팅하기 위해서는 최소 하나 이상의 레이어가 있어야 하기 때문이다. 아래 코드의 (2)의 ggplot(..) 부분은 단지 데이터와 미적 요소 매핑을 하는 메타 데이터만을 생성한다. 실제 볼드 처리된 부분이 비로소 레이어 하나를 추가 하는 코드다.
ggplot2는 객체를 저장하고 불러오는 작업이 원활하게 작동한다. 따라서 다음과 같은 코드를 출력해 보는 것은 각 코드 조각이 어떻게 작동하고 어떤 데이터를 갖고 있는지 확인하기 위한 좋은 습관이다.
위 코드는 (2)번 코드의 앞부분의 실행 결과로 나온 객체에 summary() 함수를 실행한 결과다. ‘x=carat, y=price’와 같은 미적 요소 매핑을 한 정보가 있는 것을 알 수 있다.
필자가 ggplot2에서 가장 좋아하는 특징을 설명할 때가 온 것 같다.
(2)번 코드에서 미적 요소 매핑을 시킨 특징은 ‘+’ 연산자로 레이어를 추가하더라도 해당 레이어에 상속된다는 것이다. 따라서 반복적인 코드 작성을 최소화할 수 있다. 물론 상속 내용을 쓰지 않고 재정의(overriding)해 사용할 수 있다. 아예 매핑 정보를 무효화할 수도 있다. 하지만 대부분 같은 데이터를 활용해 한 플롯에 중복적으로 시각화하는 경우가 많아 이 부분이 상당히 유용하다. 따라서 (2)번 코드의 볼드체 부분의 코드는 실제로 다음 코드와 같다.
추가된 레이어에서 미적 요소 매핑을 한 코드는 그 다음 레이어로 상속되지 않는다. 그 차이를 알 수 있는 코드는 다음과 같다.
앞의 코드 (1)은 ggplot()에서 행한 매핑이 하부 레이어에 상속이 됐음을 보여준다. 더불어 geom_point()에서 정의된 colour 매핑 정보는 geom_smooth()에 전달되지 않았음을 확인할 수 있다. 하지만 (2)의 경우 colour까지 매핑시켰더니 의도된 대로 clarity에 따른 회귀 곡선이 그려진 것을 알 수 있다
ggplot2에서는 매핑 작업만 소개했는데, 설정(set) 옵션도 제공한다. 위 코드에서 colour 인자에 clarity 명목형(nominal) 값을 매핑해 색깔을 입혔다. 단일 색상으로 다음과 같이 설정할 수도 있다.
?
그래프의 포인트가 모두 청색으로 찍힌 것을 활인할 수 있다. 물론 ggplot()에서 colour 매핑을 시켰지만, geom_point를 그리는 레이어에서 다시 색상을 지정한 것이 출력된 것이다.
이로써 많은 미적 매핑 요소를 살펴봤다. 이 요소들 중에서 아직 소개하지 않은 group 매핑 요소를 알아보자. 사실 이 요소는 colour 매핑 요소와 매우 유사한 성격을 갖고 있다. colour 요소 역시 데이터는 colour에 매핑된 데이터 기준으로 쪼개 각 데이터 그룹마다 서로 다른 색상을 입히는 역할을 한다. group 역시 기준값을 갖고 소그룹으로 나눠 각 요소에 stat과 geom을 적용시키는 역할을 한다.
일단 다음 코드를 보면서 알아보자.
이 코드의 결과는 <그림 6>과 같다.
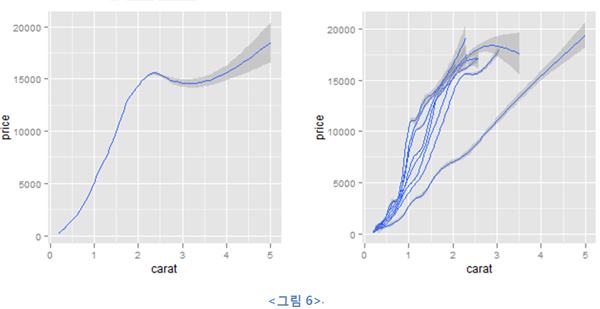
그룹 매핑을 하지 않은 앞 코드의 (1)은 전체의 데이터를 하나의 회귀 곡선에 피팅시킨 왼쪽의 그래프를 출력한다. Group 매핑을 한 (2)는 각 clarity 그룹별로 데이터를 나눠 각기 별도의 회귀곡선을 피팅시킨 라인을 출력한다.
?
기하객체(geometric object)는 실제 레이어를 랜더링하는 역할을 한다. 각 기하객체는 그에 맞는 미적 매핑 요소를 필요로 한다. 예를 들어 point 기하객체의 경우 x, y 미적 요소를 필요로 하며, geom_bar 객체의 경우 ymax 값과 더불어 테두리 색상과 내부 채움 색상을 필요로 한다.
?
앞서 geom의 경우 그에 맞는 데이터가 필요하다고 소개했다. stat은 (stat에 기본적으로 적용되는) geom에 필요한 데이터를 주어진 데이터에서 생성하는 역할을 한다. 예를 들어 stat_bin의 경우 histogram을 그리기 위한 통계계산 작업을 통해 다음과 같은 데이터를 갖는 data.frame을 출력한다.
?
-count: 각 빈(bin)에 해당하는 관측값의 개수
-density: 각 빈(bin)의 밀도(전체의 합이 1이 된다)
-ncount: count와 같으나 [0,1]로 스케일링됨
-ndensity: density와 같으나 값의 범위가 [0,1]로 스케일링됨
기본값으로는 count를 가지고 histogram을 그리게 된다. 아래의 코드에서 stat_bar에서 생성된 데이터를 어떻게 쓰는지 확인해 보자!
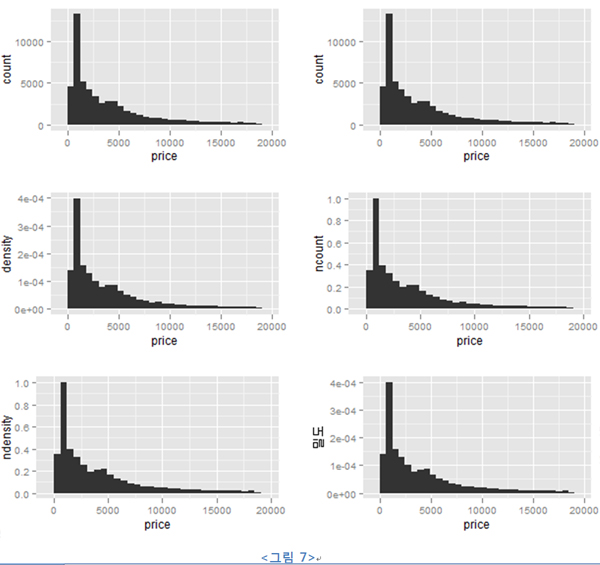
(1), (2) 코드가 차례로 제일 위의 그래프를 출력하고, 나머지는 y축의 이름으로 구분해 보면 된다(위에서 아래로, 왼쪽에서 오른쪽으로 순서다).
그림에서 보듯이 stat에서 생성된 data.frame의 필드를 사용하려면 ‘..’기호를 쓰면 된다. 이는 주어진 원본 data.frame의 데이터 필드 이름과 혼용되는 것을 피하기 위함이다.
geom과 stat 객체들은 먼저 소개했던 링크(http://had.co.nz/ggplot2)에 정리돼 있으니 참고 바란다.
?
위치 조정의 경우 이산형 값에 대해 주로 행해진다. 필자의 경우 막대그림(bar plot)이나 히스토그램(histogram)을 그릴 경우 이 기능을 주로 사용한다. 백 마디 말보다 그림 한장이 더 도움이 될 수 있으니 다음 코드를 보자.
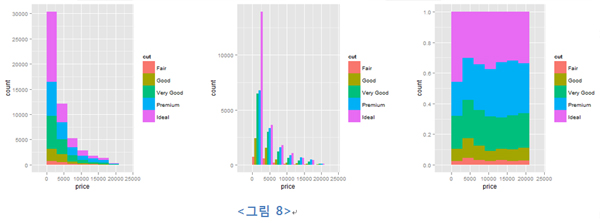
위 두 번째 그래프와 유사한 결과는 facet이라는 기법으로 표현이 가능하다. facet이라는 기법은
데이터를 특정 기준에 따라 서브세트로 나눈 뒤 각 서브세트를 각기 다른 그래프 패널에 출력하는 것을 의미한다. 따라서 위의 두번째 그래프는 다음과 같이 표현할 수 있다.
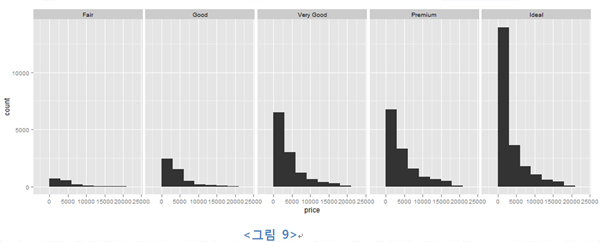
비슷한 역할을 하는 face_wrap이라는 함수도 있다.
geom과 stat은 다양한 방법으로 결합될 수 있다. 물론 어떻게 결합이 될 수 있는지 그리고 목표로 하는 geom에 필요한 통계 데이터가 무엇인지는 확인해야 한다. 자세한 내용은 메뉴얼을 참고하고 다음 같이 다양한 그래프가 같은 stat을 기반으로 도출될 수 있음 염두에 두길 바란다.
곰곰이 위와 같은 그래프가 어떻게 그려질까 하고 생각해보자. 이것을 그리기 위해서 어떤 데이터와 가공이 필요한가를 생각해보면 더욱 다양한 그래프를 생성할 수 있다.
?
이제 마지막 예제를 제시해야 될 시점이다. 실제 지금까지 설명한 내용만으로도 수많은 그래프를 만들어볼 수 있다. 하지만 실무에서 특정 데이터를 갖고 원하는 그래프를 만드는 것이 그렇게 말처럼 쉽지만은 않다. 따라서 그런 경우를 가정해 그래프를 그려보는 예제를 제시한다.
우리가 마지막으로 쓸 예제 데이터는 통계청에서 제공하는 산업생산지수다. 이 산업생산지수는 다음과 같은 의미를 갖고 있는 국가 통계 데이터다.
자료 출처는 통계청이며, 실습 목적상 데이터는 저자가 온라인으로 제공하겠다. 우리의 목적은 산업생산지수의 원계열과 계절조정 계열의 데이터를 x를 시간축으로 하는 시계열 도표로 표현하는 것이다. 이곳에 여러 정보를 가미한 텍스트와 색상을 입히는 작업을 시도할 것이다.
일단 기본 플로팅을 해보도록 하자!
보다시피 x, y축의 레이블이 적당하지 않으며, 오른쪽 레전드(legend)의 제목?순서도 적절하지 않고 시간 간격도 너무 먼 것을 확인 수 있다.
일단 x, y축 레이블과 레전드 제목을 바꿔 보자.
scale_color_hue 함수는 사실 기본 옵션으로 사용되는 함수다. Colour 미적 요소 매핑한 정보에서 제목을 재정의하기 위해 호출된 함수다. 보듯이 첫 번째 인자가 스케일링되는 레전드의 제목이 된다. scale_* 유의 함수가 ggplot2에서는 상당히 많다. 이는 미적 요소 매핑을 한 결과를 어떻게 화면에 출력할지 방법을 적용하는 함수이기에 alpha, fill, shape, size와 같은 미적 요소를 사용할 때에는 scale을 어떻게 할지 위와 같은 함수를 찾아볼 필요가 있다.
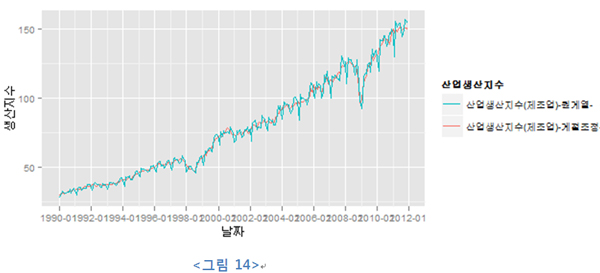
scales 패키지는 date_format 함수를 사용하기 위해 불러들였다. 위의 코드는 2년 간격으로 x축 레이블의 날짜를 출력하는 역할을 하며, guide 함수는 각 스케일이 적용되는 요소에 옵션을 재정의해 주는 역할을 한다. 물론 레전드의 제목을 설정하기 위해 scale_color_hue를 사용한 것을 빼고 guide를 다음과 같이 정의해도 된다. reverse=TRUE 옵션은 레전드의 출력 순서를 바꾸기 위함이다.
그런데 그래프 x축을 보면 텍스트를 표현하기에 너무 좁은 것을 알 수 있다. 물론 그래프의 x축 너비를 늘리면 되겠지만, 그것은 이 강좌의 교육 목적상 적절하지 않으므로 x축의 텍스트를 90도 시계 반대 방향으로 돌려서 표현하겠다. 이를 위해 opts 함수를 사용한다. 이 함수는 ggplot2의 테마(theme) 시스템의 상세 설정을 하는 함수다. 따라서 x축의 텍스트 회전도 역시 ggplot2에서는 테마의 영역에 해당하는 부분이라 할 수 있다. 아쉽게도 테마에 대한 내용은 이 강좌의 교육 범위를 넘어가므로 자세한 내용은 앞서 소개한 책을 참고하기 바란다. 여기서는 간략히 코드 소개만 한다.
그동안 연재 중에서 가장 길게 설명했다. 이마저도 이 패키지를 설명하는 데 부족하다. 세세한 부분을 설명하기 위해서는 책 한 권 정도의 분량이 필요할 것인데, 그마저도 모든 옵션을 설명하기엔 부족하다. 따라서 이번 연재를 통해 그래프를 그리는 감을 얻어 매뉴얼과 인터넷의 정보를 기반으로 하나하나 섭렵해 나가길 바란다.
?
출처 : 한국데이터베이스진흥원
제공 : DB포탈사이트 DBguide.net
?
?
| [필자] 전희원 | 넥스알에서 데이터 사이언티스트로 일하고 있다.
드디어 이번 연재의 핵심 주제에 다다랐다. R 기본 graphics를 건너뛰고 이렇게 ggplot2를 소개하는 이유는 다음과 같다. ggplot2는 기본 R 그래픽스에서 제공하는 대부분의 작업을 아주 효과적으로 수행할 수 있어서 많은 책에서 시각화의 기본 패키지로 이미 ggplot2를 사용하고 있기 때문이다. 필자도 기본 R 그래픽을 주로 사용해 왔다. 기본 R 그래픽은 확장성을 보장하지만 기본적으로 미려한 그래픽 측면에서 아쉽고 설정도 복잡하다. 망설이고 있던 차에 한 책에서 ggplot2를 만나 본격적으로 사용하기 시작했다. 필자가 ggplot2를 실무에 적용하면서 느낀 장점들 중에서 가장 마음에 들었던 것은 기본 옵션으로 플로팅해도 아주 실용적인 색상 조합과 더불어 미려한 그래픽으로 정보를 시각화해 준다는 점이다. 이는 미적 감각이 부족한 필자에게 더없이 매력적이었다. 게다가 컬러도 눈에 잘 들어오도록 아주 세심하게 조합해 준다. 이를 흑백 프린터에 출력하더라도 범주값에 따른 색상 구분이 눈으로 가능해, 작은 부분 하나까지 꼼꼼하게 신경 썼다는 느낌을 주기에 충분했다. 특히 ‘Grammar of Graphics’의 개념은 흡사 객제지향 프로그래밍(OOP) 언어를 처음 배울 때의 느낌과 비슷했다. 데이터 객체, 그래픽 객체의 분리와 재사용에 초점을 둬 그 논리 정연함이 기본 R 패키지의 그것보다 훨씬 뛰어남을 느낄 수 있었다. 2005년부터 이를 개발하기 시작한 Hadley Wickham 교수는 R 기본 그래픽 시스템의 장점을 가져와 발전시키는 데 또 한 가지 초점을 두었기 때문에 이런 탁월한 느낌을 줄 수 있었던 것 같다. |
? 왜 ggplot2 툴이 필요하나?
?얼마 전 필자는, Hadley 교수가 강연 중에 한 참석자로부터 “왜 사람들이 R 기본 그래픽에서 ggplot2로 바꿔야 하나요?” 하는 질문을 받고 답하는 장면 영상을 보았다. 이에 대해 Hadley 교수는 “기본 그래픽 시스템은 그림을 그리기 위해 좋은 툴이지만, ggplot2는 데이터를 이해하는 데 좋은 시각화 툴이기 때문”이라고 답했다.진짜 이유는 ggplot2의 문법에 기인하는데, 기본 그래픽에서는 데이터 입력 포맷에 대한 함수 내 규정을 상세하게 하고 있어 한번 그려 놓기도 번거로울뿐더러 같은 데이터로 다른 형식의 그래프를 그릴 때 다른 입력 포맷에 대한 적응과 적용이 필요하다. 그러나 ggplot2는 다른 그래프라 하더라도 문법 내에서 간단한 코드 추가/삭제로 플로팅을 할 수 있다. 하나의 데이터를 기반으로 이런저런 그래프를 많이 그려봐야 할 빅데이터 시대에서 가장 필요한 기술 중 하나가 아닐까 하는 생각을 해본다.
ggplot2를 설치하고 사용하기 위한 명령어는 아래와 같이 단 두 줄이다.
?
| install.packages(“ggplot2”) library(ggplot2) |
이 밖에 개발 버전을 사용해볼 생각이라면 아래와 같은 명령어를 사용하면 된다.
| install.packages(“devtools”)
library(devtools) dev_mode() #인스톨된 버전에 덮어쓰지 하지 않기 위해 install_github(“ggplot2”) |
이 링크에서는 100여 개의 ggplot2 객체에 대한 소개와 함께 500여 개가 넘는 예제를 제공한다. 이 온라인 페이지는 늘 가까히 두고 익힐 필요가 있다. 그리고 필자가 ggplot2를 공부하면서 참고한 책은?이다. ggplot2에 대한 유일한 책으로 Hadley 교수가 친근한 단어로 쉽게 소개하고 있다. 다양한 시각화 기술을 포함하고 있으므로 ggplot2를 심도 있게 공부하고 싶은 독자께서는 반드시 봐야 될 책이라 할 수 있다. 그리고 이 글 역시 위 두 참고문헌을 기반으로 작성했음을 밝혀둔다.
일단 동기 부여는 이쯤에서 마치고, 실제 이 패키지의 근간이 된 ‘Grammar of Graphics’에 대해 알아보자. Grammar of Graphics는 데이터를 각 기하 객체(geometric object)의 미적 속성(aesthetic attributes)에 매핑하는 방법을 제공한다. 이를 통해 통계적인 시각화를 가능하게 하는 효과적인 방법을 제안한다. 이 와중에 통계적인 데이터 변환이 필요하다면 그 변환까지 수행해 준다. 국소(faceting) 시각화 기법을 사용하면 각 데이터의 부분 데이터만 사용해 여러 개의 그래프를 한꺼번에 그려주기도 한다.
먼저 문법(Grammar of Graphics) 설명 차원에서 데이터 하나를 소개한다.
ggplot2를 로딩해 그 안에 포함된 데이터를 사용해 볼 수 있다. diamonds 데이터도 역시 패키지와 함께 배포되는 데이터다. 이 데이터에는 5만 4000여 개의 다이아몬드에 대한 가격을 포함한 10개의 속성 정보가 포함돼 있다. 아마도 다이아몬드의 가치에 대해 궁금한 독자라면 시각화에 관심이 더 갈 것이다.
ggplot2에서는 qplot라는 함수를 제공한다. 이는 R에서 기본적으로 제공하는 plot()과 유사한 인터페이스를 제공하는 데 목적을 둔 함수다. 이를 사용하는 예는 다음과 같다.
?
| qplot(diamonds$carat, diamonds$price)
qplot(carat, price, data = diamonds) qplot(carat, price, data = diamonds, geom="point" ,colour=clarity) # ?--(1) qplot(carat, price, data = diamonds, geom=c("point", "smooth"), method=lm) qplot(carat, data = diamonds,geom="histogram") qplot(carat, data = diamonds,geom="histogram", binwidth = 100) |
qplot() 함수의 형태는 plot()과 유사하게도 첫 번째 인자에 x축의 변수명이 오며, 이어서 y축의 변수명이 따라온다. 그리고 data라는 인자로 data.frame 형태의 데이터의 객체명을 입력받는 형식이다. 뒤 이어 오는 인자들은 ggplot2에서만 해당되는 특수 인자들이 오게 된다.
예를 들어 앞 코드 (1)을 실행한 결과는 다음과 같다.
이 그래프를 코드와 매핑해 보면 아주 쉽게 그 의미를 파악할 수 있다. 이 그래프는 x축은 caret를, y축은 price를 의미한다. 그래프의 종류는 각 점마다 point를 찍는 scatter plot을 그려준다. 이와 동시에 다이아몬드의 선명도(clarity)에 따른 컬러도 매핑을 시켜줬다.
?qplot()에 대한 설명은 더 이상 하지 않을 생각이다. 여기엔 이유가 있다. 일단 ggplot2를 다양하게 활용하기 위해서는 레이서(layer)를 잘 활용할 필요가 있다. qplot()으로는 문법을 효과적으로 활용하는 데 한계가 따른다는 점과 이 때문에 그래프를 핸들링하는 데 인터페이스 상의 복잡함이 존재한다는 점이다. 다른 한 가지는 qplot()으로는 문법을 배우고 가르치기가 어렵다는 것이다. 따라서 다음과 같은 플로팅 방식의 문법을 사용할 것이다.
| ggplot(data=diamonds, aes(x=carat,y=price)) + geom_point(aes(colour=clarity)) |
? 문법(GRAMMAR OF GRAPHICS)
?일단 간단한 데이터를 갖고 문법의 각 단계가 어떻게 적용되는지 살펴보자. 이 예제는 Hadley 교수의 발표자료에서 가져왔다. 이유는 내부 데이터가 어떻게 바뀌면서 각 문법이 적용되는지 ggplot2의 내부를 들여다 보기가 여의치 않기 때문이다. 이 점을 이해해주기 바란다.
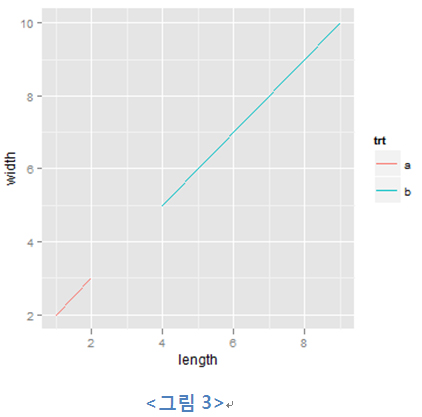
위 데이터의 length, width를 기반으로 아래와 같이 scatter plot을 그린다고 해보자.
| test.data<- data.frame(length=c(2,1,4,9), width=c(3,2,5,10),
depth=c(4,1,15,80), trt=c("a","a","b","b")) ggplot(test.data, aes(x=length, y=width)) + geom_point(aes(colour=trt)) |
일단 scatter plot은 각 축에 숫자형 데이터를 입력받아 좌표계에 점을 찍는 것이다. 점은 ggplot2에서 기하객체(geometric object)라고 불리며, 문법에서는 짧게 geom이라고 한다. 여기에는 점(points), 선(lines), 다각형(polygons) 등 많은 객체가 존재한다.
데이터를 플로팅 하기 위해 데이터의 각 레코드를 갖고 그래픽 요소에 매핑할 필요가 있다. 이를 ‘미적 요소 매핑(aesthetic mapping)’이라고 표현하며, ggplot2의 문법에서는 aes라는 함수가 이 역할을 한다. ‘aes(x=length, y=width)’ 코드가 의미하는 바는 x축에 length 컬럼을 매칭시키고, y축에 width 컬럼을 매칭시키라는 것이다.
미적 요소 매핑은 데이터의 각 속성을 그래프 속성에 매핑을 시킨다. scatter plot의 경우 좌표계 속성에 필요한 x, y, 점의 모양, 점의 크기, 점의 색깔 등이 그에 해당한다. 이를 위해 ggplot2 내부에서는 다음과 같이 데이터를 변환시킨다.
?
‘length→ x, width→ y, trt→ colour’로 변환된 것을 확인할 수 있다. 점의 크기나 모양은 매핑 속성에 없으므로 매핑되지 않았으나, 모두 같은 기본 값으로 암묵적으로 생성된다. 모양의 기본값은 속이 꽉찬 점이고, 점의 크기는 1이 기본값이다. 미적 요소 매핑은 어느 데이터가 어떤 곳에 쓰일지를 명시하는 작업이라고 생각하면 된다. 앞의 매핑된 데이터는 line chart에서도 사용될 수 있다. 잘 생각해보면 이들 그래프를 그리기 위해 필요한 것은 x, y축에 따른 값과 색상을 구분하는 변수뿐이다. 그러나 이런 그래프는 이 상황에서는 그다지 의미가 없으니 그냥 참고하기 바란다.
?
미적 매핑을 한 후에 진행되는 작업은 매핑된 데이터를 갖고 컴퓨터가 알아볼 수 있는 데이터로 변환시키는 것이다. 이는 흡사 디지털 카메라 자동 프로세스를 통해 이해하면 쉬울 것이다. 디지털 카메라는 피사체를 CCD에 매핑한 후 디지털 이미지화해 메모리에 저장하는 과정으로 작동한다. 컴퓨터가 이해할 수 있는 이미지 포맷으로 변환하는 작업이 바로 ggplot2의 스케일링(scaling) 작업이다.
x, y축 데이터는 이미지를 출력하는 대상에 맞게 변수 변환이 이뤄진다. ggplot2에서 사용하는 시스템은 grid이기 때문에 [0,1] 사이의 값으로 스케일링된다. 그리고 colour 값은 자동으로 사람의 눈으로 구분하기 쉬운 색상으로 매핑된다. 사람이 구분하기 쉬운 색상을 사용하기 위한 작업도 이뤄지는데 컬러휠(color wheel)을 구분하고 싶은 레벨 개수로 색상과 명암 기준으로 일정하게 분할해 색상을 매칭시킨다. ggplot2는 자동으로 이 작업을 해주기 때문에 다변량에 대한 그래프를 그릴 때 매우 편하다. 물론 사용자가 이 값들을 직접 정해줄 수 있다.
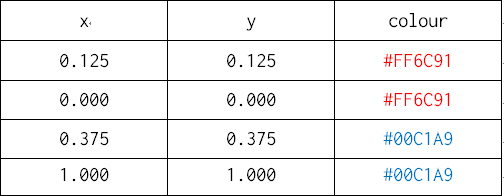
스케일링을 통해 나온 데이터는 다음과 같다.
재미있게도 x, y의 스케일링된 데이터 값은 동일한다. 이것이 앞 <그림 3>에서 어떻게 표현되는지 비교·확인해 보면 이해가 빠를 것이다.
사실 x, y의 변환된 데이터를 일반적인 직교 좌표계를 사용하거나 극 좌표계를 사용하느냐에 따라서 한 번의 변환이 더 일어난다. 기본값은 직교 좌표계이기 때문에 예상대로 출력된 것을 확인할 수 있다.
이들 데이터 말고도 하나의 그래프를 그리기 위해서는 더 많은 것이 필요하다. 예를 들면, 축(axis), 레전드(legend), 레이블(lable), 그리드(grid) 라인 등인다. 이들은 사용자가 직접 설정하지 않으면 기본값으로 출력된다. 이들을 직접 핸들링하기 위해서는 ggplot2의 테마(theme)와 관련된 매뉴얼을 찾아봐야 한다.
이상으로 개략적인 ggplot2의 동작 방식을 살펴봤다. 이 이외에 ggplot2에서 중요한 레이어(layer) 시스템이 있다. 이 레이어 시스템 덕분에 그래프 위에 다양한 정보를 추가해 그래프를 더욱 ‘정보성 있게’ 만들 수 있다.
| ggplot(test.data, aes(x=length, y=width)) + geom_point(aes(colour=trt)) + geom_smooth() |
이런 레이어를 플롯에 올릴 때 원 데이터는 다음과 같은 변환 과정을 통해 레이어 개별적으로 적용받는다.
1. 미적 매핑
2. 통계적인 변환(stat)
3. 기하객체에 적용(geom)
4. 위치 조정(position adjustment)
1번과 2번 사이에 스케일링이 작업이 들어간다는 것을 명심하자. 4번 위치 조정의 경우 동일 좌표계에 여러 종류의 그래프를 올려놓기 위해 개별 레이어의 위치 정보에 대해 학습(train)을 하는 과정이 포함된다. 만일 이 과정이 없다면 특정 레이어에 특화된 스케일만 적용돼 적절하지 못한 그래프가 출력될 것이다.
? 레이어를 이용한 GGPLOT2 시각화
이전 장을 통해 ggplot2에서 문법이 어떤식으로 동작하는지 이해했을 것이다. 이제 기본적인 내용은 다 설명했으니 실제 예제를 통해 알아보자. 이제부터 본격적으로 앞서 설명한 diamonds 데이터를 사용하겠다. 다음 코드는 앞서 소개한 코드다.아래 두 코드는 같은 그래프를 그린다. 사실 qplot()은 ‘+’ 연산자 없이도 그래프 한장을 그리고 아래 코드의 (2)는 앞 부분만 실행하면 그래프가 생성되지 않는다. 이유는 그래프를 플로팅하기 위해서는 최소 하나 이상의 레이어가 있어야 하기 때문이다. 아래 코드의 (2)의 ggplot(..) 부분은 단지 데이터와 미적 요소 매핑을 하는 메타 데이터만을 생성한다. 실제 볼드 처리된 부분이 비로소 레이어 하나를 추가 하는 코드다.
| qplot(carat, price, data = diamonds, geom="point" ,colour=clarity) #--(1) ggplot(data=diamonds, aes(x=carat,y=price)) + geom_point(aes(colour=clarity))#--(2) |
| > s <- ggplot(data=diamonds, aes(x=carat,y=price))
> summary(s) data: carat, cut, color, clarity, depth, table, price, x, y, z [53940x10] mapping: x = carat, y = price faceting: facet_null() |
필자가 ggplot2에서 가장 좋아하는 특징을 설명할 때가 온 것 같다.
(2)번 코드에서 미적 요소 매핑을 시킨 특징은 ‘+’ 연산자로 레이어를 추가하더라도 해당 레이어에 상속된다는 것이다. 따라서 반복적인 코드 작성을 최소화할 수 있다. 물론 상속 내용을 쓰지 않고 재정의(overriding)해 사용할 수 있다. 아예 매핑 정보를 무효화할 수도 있다. 하지만 대부분 같은 데이터를 활용해 한 플롯에 중복적으로 시각화하는 경우가 많아 이 부분이 상당히 유용하다. 따라서 (2)번 코드의 볼드체 부분의 코드는 실제로 다음 코드와 같다.
| ...+ geom_point(aes(x=carat, y=price, colour=clarity)) |
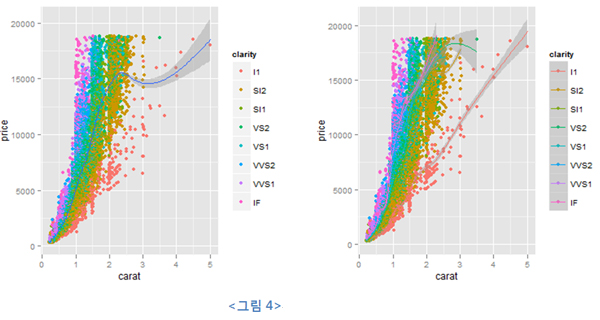
| ggplot(data=diamonds, aes(x=carat,y=price)) +
geom_point(aes(colour=clarity)) + geom_smooth() # ---(1) ggplot(data=diamonds, aes(x=carat,y=price, colour=clarity)) + geom_point() + geom_smooth() # ---(2) |
앞의 코드 (1)은 ggplot()에서 행한 매핑이 하부 레이어에 상속이 됐음을 보여준다. 더불어 geom_point()에서 정의된 colour 매핑 정보는 geom_smooth()에 전달되지 않았음을 확인할 수 있다. 하지만 (2)의 경우 colour까지 매핑시켰더니 의도된 대로 clarity에 따른 회귀 곡선이 그려진 것을 알 수 있다
ggplot2에서는 매핑 작업만 소개했는데, 설정(set) 옵션도 제공한다. 위 코드에서 colour 인자에 clarity 명목형(nominal) 값을 매핑해 색깔을 입혔다. 단일 색상으로 다음과 같이 설정할 수도 있다.
?
| ggplot(data=diamonds, aes(x=carat,y=price, colour=clarity))+ geom_point(colour=”darkblue”) |
이로써 많은 미적 매핑 요소를 살펴봤다. 이 요소들 중에서 아직 소개하지 않은 group 매핑 요소를 알아보자. 사실 이 요소는 colour 매핑 요소와 매우 유사한 성격을 갖고 있다. colour 요소 역시 데이터는 colour에 매핑된 데이터 기준으로 쪼개 각 데이터 그룹마다 서로 다른 색상을 입히는 역할을 한다. group 역시 기준값을 갖고 소그룹으로 나눠 각 요소에 stat과 geom을 적용시키는 역할을 한다.
일단 다음 코드를 보면서 알아보자.
| p <- ggplot(data=diamonds, aes(x=carat,y=price))
p + geom_smooth() # --- (1) p + geom_smooth(aes(group=clarity)) # --- (2) |
그룹 매핑을 하지 않은 앞 코드의 (1)은 전체의 데이터를 하나의 회귀 곡선에 피팅시킨 왼쪽의 그래프를 출력한다. Group 매핑을 한 (2)는 각 clarity 그룹별로 데이터를 나눠 각기 별도의 회귀곡선을 피팅시킨 라인을 출력한다.
?
? GEOM
?기하객체(geometric object)는 실제 레이어를 랜더링하는 역할을 한다. 각 기하객체는 그에 맞는 미적 매핑 요소를 필요로 한다. 예를 들어 point 기하객체의 경우 x, y 미적 요소를 필요로 하며, geom_bar 객체의 경우 ymax 값과 더불어 테두리 색상과 내부 채움 색상을 필요로 한다.
?
? STAT
?앞서 geom의 경우 그에 맞는 데이터가 필요하다고 소개했다. stat은 (stat에 기본적으로 적용되는) geom에 필요한 데이터를 주어진 데이터에서 생성하는 역할을 한다. 예를 들어 stat_bin의 경우 histogram을 그리기 위한 통계계산 작업을 통해 다음과 같은 데이터를 갖는 data.frame을 출력한다.
?
-count: 각 빈(bin)에 해당하는 관측값의 개수
-density: 각 빈(bin)의 밀도(전체의 합이 1이 된다)
-ncount: count와 같으나 [0,1]로 스케일링됨
-ndensity: density와 같으나 값의 범위가 [0,1]로 스케일링됨
기본값으로는 count를 가지고 histogram을 그리게 된다. 아래의 코드에서 stat_bar에서 생성된 데이터를 어떻게 쓰는지 확인해 보자!
| ggplot(data=diamonds, aes(x=price)) + geom_bar() # --(1)
ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(y=..count..)) # --(2) ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(y=..density..)) ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(y=..ncount..)) ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(y=..ndensity..)) ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(y=..density..)) + ylab("밀도") |
그림에서 보듯이 stat에서 생성된 data.frame의 필드를 사용하려면 ‘..’기호를 쓰면 된다. 이는 주어진 원본 data.frame의 데이터 필드 이름과 혼용되는 것을 피하기 위함이다.
geom과 stat 객체들은 먼저 소개했던 링크(http://had.co.nz/ggplot2)에 정리돼 있으니 참고 바란다.
?
? 위치 조정
?위치 조정의 경우 이산형 값에 대해 주로 행해진다. 필자의 경우 막대그림(bar plot)이나 히스토그램(histogram)을 그릴 경우 이 기능을 주로 사용한다. 백 마디 말보다 그림 한장이 더 도움이 될 수 있으니 다음 코드를 보자.
| ggplot(data=diamonds, aes(x=price)) +
geom_bar(aes(fill=cut), binwidth=3000) ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(fill=cut), binwidth=3000, position="dodge") ggplot(data=diamonds, aes(x=price)) + geom_bar(aes(fill=cut), binwidth=3000, position="fill") |
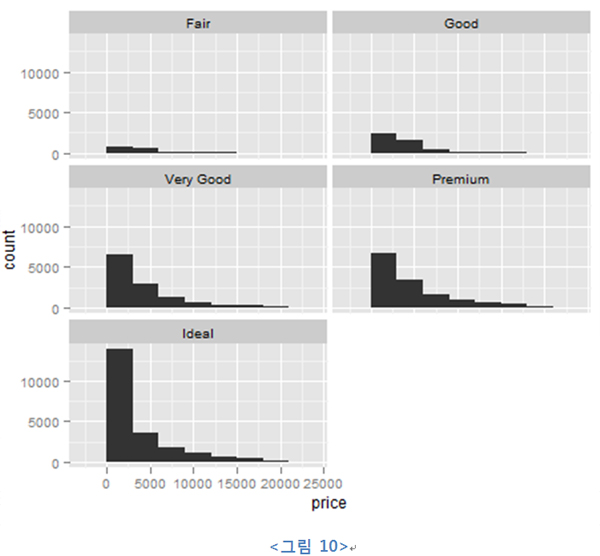
위 두 번째 그래프와 유사한 결과는 facet이라는 기법으로 표현이 가능하다. facet이라는 기법은
데이터를 특정 기준에 따라 서브세트로 나눈 뒤 각 서브세트를 각기 다른 그래프 패널에 출력하는 것을 의미한다. 따라서 위의 두번째 그래프는 다음과 같이 표현할 수 있다.
| ggplot(data=diamonds, aes(x=price)) + geom_bar(binwidth=3000) + facet_grid( . ~ cut) |
비슷한 역할을 하는 face_wrap이라는 함수도 있다.
| ggplot(data=diamonds, aes(x=price))+ geom_bar(binwidth=3000) + facet_wrap( ~ cut,nrow=3) |
? GEOM과 STAT의 결합
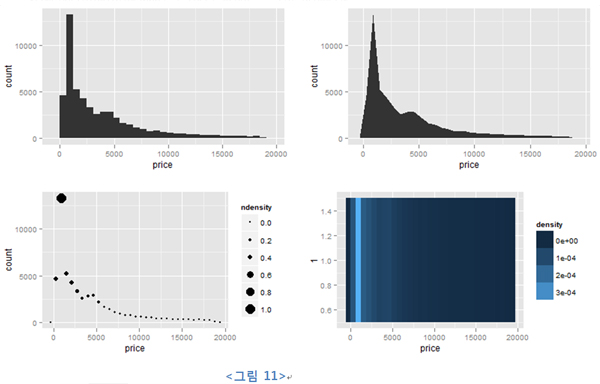
?geom과 stat은 다양한 방법으로 결합될 수 있다. 물론 어떻게 결합이 될 수 있는지 그리고 목표로 하는 geom에 필요한 통계 데이터가 무엇인지는 확인해야 한다. 자세한 내용은 메뉴얼을 참고하고 다음 같이 다양한 그래프가 같은 stat을 기반으로 도출될 수 있음 염두에 두길 바란다.
| d <- ggplot(diamonds, aes(price))
d + stat_bin(geom="bar") d + stat_bin(geom="area") d + stat_bin(aes(size=..ndensity..),geom="point") d + stat_bin(aes(y=1, fill=..density..),geom="tile") |
곰곰이 위와 같은 그래프가 어떻게 그려질까 하고 생각해보자. 이것을 그리기 위해서 어떤 데이터와 가공이 필요한가를 생각해보면 더욱 다양한 그래프를 생성할 수 있다.
?
? 마지막 예제
?이제 마지막 예제를 제시해야 될 시점이다. 실제 지금까지 설명한 내용만으로도 수많은 그래프를 만들어볼 수 있다. 하지만 실무에서 특정 데이터를 갖고 원하는 그래프를 만드는 것이 그렇게 말처럼 쉽지만은 않다. 따라서 그런 경우를 가정해 그래프를 그려보는 예제를 제시한다.
우리가 마지막으로 쓸 예제 데이터는 통계청에서 제공하는 산업생산지수다. 이 산업생산지수는 다음과 같은 의미를 갖고 있는 국가 통계 데이터다.
| “2007년까지는 산업생산지수라 표현하였고, 현재 광공업생산지수라고 표현하고 있다. 광공업생산지수는 다종 다양한 생산활동의 결과인 작업량(work done)을 측정하여 전체 광업, 제조업, 전기·가스업 생산의 수준과 변동추이를 알기 위해 작성한다. 이 지수는 광업, 제조업, 전기·가스업의 생산활동 동향, 경기동향을 알 수 있게 하는 기본적인 경기지표이다. 생산지수에서 '생산'이라는 개념은 국내총생산(GDP)에서의 생산(부가가치 개념) 이라는 개념과 같다. 광공업지수가 포괄하고 있는 산업의 경제활동은 전체 경제활동의 약 30%를 차지하고 있다. 따라서 광공업생산지수는 전체 경제의 생산활동의 움직임을 월별로 판단할 수 있는 속보성 외에도?? 지표 중 가장 공표가 빠른 지표이다" |
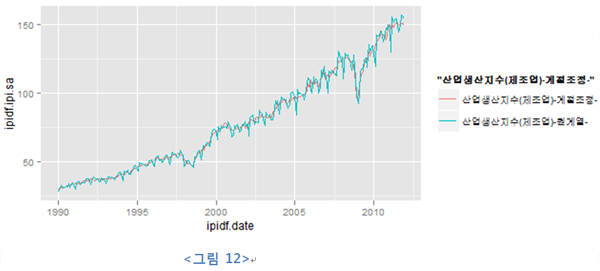
일단 기본 플로팅을 해보도록 하자!
| load(url("https://dl.dropbox.com/u/8686172/ipidf.RData"))
ipidfg<- ggplot(ipidf, aes(ipidf.date)) + geom_line(aes(y=ipidf.ipi.sa, colour="산업생산지수(제조업)-계절조정-")) + geom_line(aes(y=ipidf.ipi, colour="산업생산지수(제조업)-원계열-") ) ipidfg |
보다시피 x, y축의 레이블이 적당하지 않으며, 오른쪽 레전드(legend)의 제목?순서도 적절하지 않고 시간 간격도 너무 먼 것을 확인 수 있다.
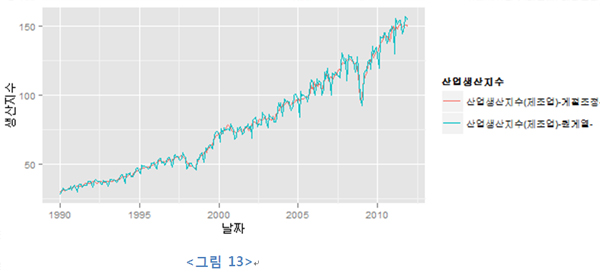
일단 x, y축 레이블과 레전드 제목을 바꿔 보자.
| ipidfg2 <- ipidfg + xlab("날짜") + ylab("생산지수") + scale_color_hue("산업생산지수") ipidfg2 |
scale_color_hue 함수는 사실 기본 옵션으로 사용되는 함수다. Colour 미적 요소 매핑한 정보에서 제목을 재정의하기 위해 호출된 함수다. 보듯이 첫 번째 인자가 스케일링되는 레전드의 제목이 된다. scale_* 유의 함수가 ggplot2에서는 상당히 많다. 이는 미적 요소 매핑을 한 결과를 어떻게 화면에 출력할지 방법을 적용하는 함수이기에 alpha, fill, shape, size와 같은 미적 요소를 사용할 때에는 scale을 어떻게 할지 위와 같은 함수를 찾아볼 필요가 있다.
| library(scales)
ipidfg3 <- ipidfg2 + scale_x_date(breaks="2 years", labels = date_format("%Y-%m")) + guides(colour = guide_legend(reverse=TRUE)) ipidfg3 |
scales 패키지는 date_format 함수를 사용하기 위해 불러들였다. 위의 코드는 2년 간격으로 x축 레이블의 날짜를 출력하는 역할을 하며, guide 함수는 각 스케일이 적용되는 요소에 옵션을 재정의해 주는 역할을 한다. 물론 레전드의 제목을 설정하기 위해 scale_color_hue를 사용한 것을 빼고 guide를 다음과 같이 정의해도 된다. reverse=TRUE 옵션은 레전드의 출력 순서를 바꾸기 위함이다.
| ... + guides(colour = guide_legend(“산업생산지수”,reverse=TRUE)) |
| ipidfg3 + opts(axis.text.x=theme_text(angle=90, hjust=1)) |
? 마치며
지금까지 ggplot2에 대한 많은 내용을 살펴봤다. 하나부터 열까지 모두 한꺼번에 다 자동으로 되는 패키지였으면 좋겠지만, 생각보다 원하는 바를 도출하려면 손봐야 할 것이 많음을 실감했을 것이다. 대부분 유연함과 난이도는 서로 정비례한다. 그러나 유연함과 난이도의 많은 부분을 문법이라는 것으로 정리해 놓았다는 게 이 패키지의 가장 큰 장점이다.그동안 연재 중에서 가장 길게 설명했다. 이마저도 이 패키지를 설명하는 데 부족하다. 세세한 부분을 설명하기 위해서는 책 한 권 정도의 분량이 필요할 것인데, 그마저도 모든 옵션을 설명하기엔 부족하다. 따라서 이번 연재를 통해 그래프를 그리는 감을 얻어 매뉴얼과 인터넷의 정보를 기반으로 하나하나 섭렵해 나가길 바란다.
?
출처 : 한국데이터베이스진흥원
제공 : DB포탈사이트 DBguide.net
?