
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
[빅데이터 분석] R로 하는 데이터 시각화의 시작
작성자
관리자
작성일
2020-10-23 13:41
조회
1187
R로 하는 데이터 시각화의 시작
?| 전희원 | 넥스알에서 데이터 사이언티스트로 일하고 있다. |
필자는 한 금융사의 금융 데이터를 빅데이터 플랫폼에서 파일럿 프로젝트로 분석해본 경험이 있다. 빅데이터 처리 플랫폼에서 아무리 빨리 데이터를 처리하더라도 처리 결과가 의미가 있어야 빅데이터 플랫폼의 가치를 사람들이 인지한다는 것을 알 수 있었다. 그 정점에 서 있는 기술이 바로 시각화이다. ‘많은 데이터를 처리한 결과, 우리가 얻게 되는 정보나 혜택이 무엇인가?’ 하고 물었을 때 바로 답해줄 수 있는 몇 가지 안 되는 기술 중에 하나가 바로 시각화였다. 이 연재에서 소개할 ggplot2로 시각화해 프로젝트를 제대로 마무리했던 경험을 독자들과 나누고자 한다. 한마디로 빅데이터 플랫폼 엔지니어뿐만 아니라 데이터를 다루는 사람들은 배워볼 필요가 충분한 기술이라는 것이다. 이제 본격적으로 시각화에 대한 맛을 보도록 해보자!
? MS 엑셀로 분석
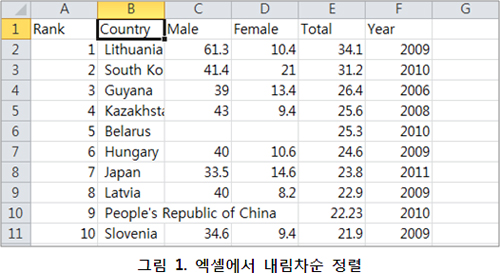
?한 예로 각 나라의 자살률을 살펴본다고 한다. 데이터는 http://en.wikipedia.org/wiki/List_of_countries_by_suicide_rate 에서 가져왔다. 위키에서 보면 데이터의 신빙성에 대한 논란은 있으니 참고 바란다. 이 예제의 제시 목적은 시각화 학습을 위한 목적도 있으나, 한국의 자살률이 세계적으로 높다는 측면을 강조해 경각심을 키우기 위함도 있다. ‘다른 나라에 비해 우리나라의 자살률이 왜 높을까?’라는 의문을 독자들이 갖는 순간 아마도 이와 상관된 데이터를 찾아볼 수 있을 것이고, 관련 연구의 촉매가 될 수도 있을 거란 소망을 가져본다. 물론 그런 연구에서 시각화가 좋은 도구가 될 것임은 분명하다.이 데이터 시각화에 부담을 갖고 있거나 시도를 해볼 여력이 없는 독자라면 <그림 1>과 같이 그저 엑셀에서 10만 명당 몇 명이 자살하는지에 대해 내림차순으로 정렬해 가장 높은 나라들이 어떤 나라들인지 살펴볼 수 있다.
?
물론 아래와 같이 단순한 통계량을 가지고 전체적인 관점으로 여자보다 남자의 자살이 더 많다는 것을 알 수 있으나 어떤 나라에서 그런 차이를 보이는지는 알 수 없다.
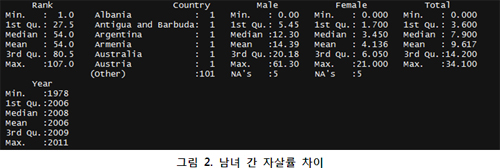
[그림 2]의 결과에서 얻을 수 있는 건 남녀 간 자살률의 차이일 뿐인데, 이를 [그림 3]과 같이 단순한 상자그림(boxplot)으로 표현하면 더 보기 쉽다.
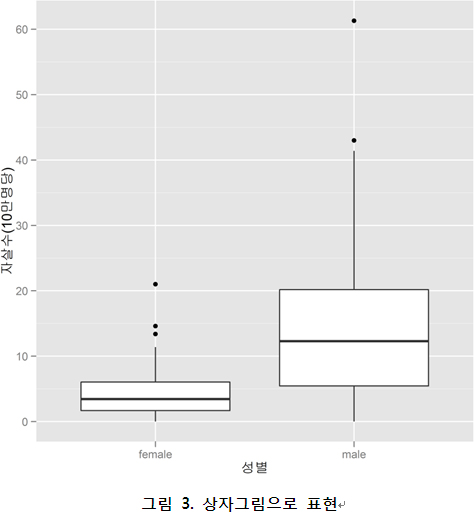
? 아웃라이어로 알아보기 쉽게
?이런 식으로 데이터를 시각적으로 표현함으로써 많은 정보를 한눈에 볼 수 있도록 해주는 게 바로 데이터 시각화이다. 하지만 뭔가 아쉬운 점이 있다. 실제 아웃라이어(outlier)라는 평균이나 중앙값에서 멀리 떨어진 값이 어떤 것인지 <그림 4>와 같이 표시해 주면 훨씬 알아보기 쉬울 것이다.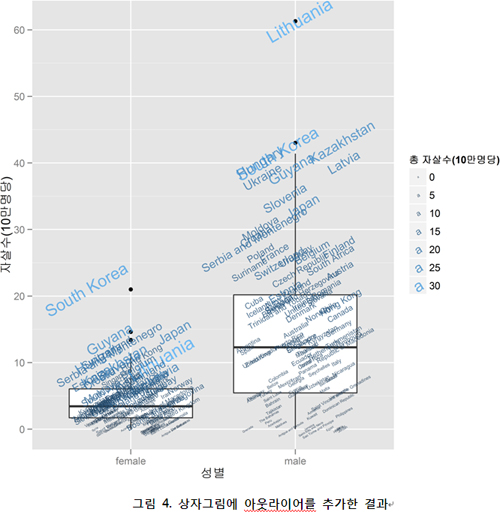
이렇게 하면 아웃라이어에 어떤 나라들이 있는지 확인할 수 있을 것이다. 안타깝지만 여자든 남자든 한국의 자살률이 세계적이라는 것을 알 수 있는데, 기분 좋지 않은 상위권이 아닐 수 없다. [그림 4]만으로 데이터 파일의 거의 모든 정보를 보여줄 수 있는데, 텍스트 크기와 색깔은 10만 명당 남녀 자살자 수의 상대적인 크기를 알려주고 있고, 남녀 개별적인 자살자 수도 역시 보여주고 있어 상대적인 비교가 가능함을 알 수 있다.
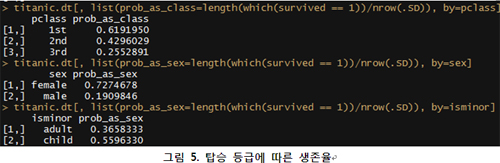
다른 예를 통해 알아보자. 얼마 전에 필자가 블로그에 올려둔 ‘타이타닉호 데이터 분석’ 포스팅을 더 자세히 살펴보자(http://freesearch.pe.kr/archives/2855). 이 포스팅의 목적은 타이타닉호 사고로 인한 사망자 통계를 기반으로 남자가 여자에 비해 죽을 확률이 높았음을 데이터를 통해 보여주고, 영화가 비극적인 결말로 끝날 가능성이 애초부터 높았음을 알려주기 위해서였다. 여기서 성별에 따른 생존율이 어떻게 다르고, 승객 등급에 따라 생존율이 어떻게 변하는지 확인하고 싶어질 것이다. 일단 개별적으로 생존율을 확인하기 위해 아래와 같은 결과를 확인할 수 있다.
? 통계적 분석을 쉽게 해주는 시각화
?각 등급에 따른 생존율은 [그림 5]와 같이 숫자로 표현할 수 있다(상세한 코드 설명은 첫 회의 범위를 넘어가므로 나중에 소개하겠다). 이를 보면 높은 등급의 승객(pclass)이, 남자보다 여자가, 어린이보다 성인(isminor=adult)이 각각 생존율이 더 높음을 알 수 있다. 하지만 이들 간의 상호작용은 위 통계만으로는 알기 어렵다. 상호작용이라 하면 승객 등급이 여자와 남자의 생존율 차이에 어떤 영향을 줄 수 있느냐이다. 이를 보기 위해서는 chi-square와 같은 통계적 방법이 필요하다. 하지만, 일반인을 이해시키기 위해 부연설명이 너무 길어지기 때문에 필자의 경우에는 시각화를 이용한다.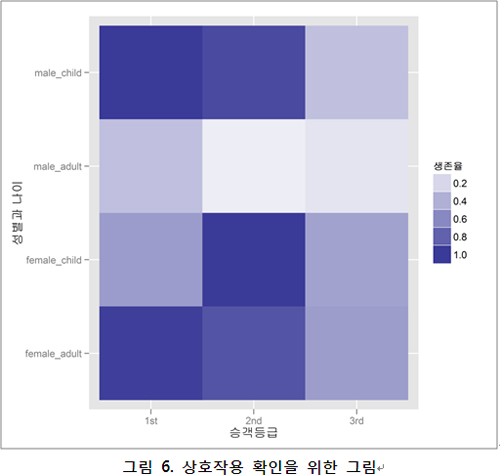
[그림 6]의 Y축에는 성별에 따른 나이를, X축에는 승객 등급을 나타냈다. 오른쪽 끝에 생존율 범례를 확률 값으로 넣었다. 그래프 내부에서는 박스 형태로 구간을 나눠 확률 범례를 기준으로 색상의 밝기로 생존율을 표기했다. 이렇게 되면서 등급과 성별, 성인 여부에 따른 생존율을 한눈에 볼 수 있게 됐다. 이를 볼 때 등급이 올라갈수록 생존율이 높아지는 경향이 있으나 이 또한 성별과 성인여부에 따라 영향을 받는 것으로 볼 수 있다.
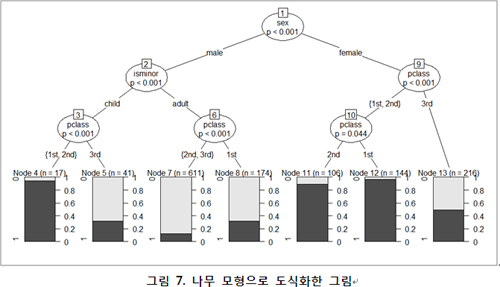
[그림 7]은 결정나무(Decision Tree)의 한 알고리즘을 통해 데이터를 분석, 생존에 영향을 미치는 인자들이 어떤 것들이 있는지 나무 모형으로 도식화한 것이다. 이를 보면 일단 성별이 생다 다름을 알 수 있다. 남자는 성인여부, 여자의 경우 승객등급의 영향이 생존에 가장 큰 영향을 끼치는 것을 알 수?다는 더 많은 정보를 보여줌을 알 수 있다.
? 정리 그리고 앞으로 방향
?시각화를 하는 방법은 굉장히 많다. 예를 들어 flowingdata.com에서 어떤 툴로 시각화하는지 설문을 한 적이 있었는데, 아래와 같은 결과를 보여줬다.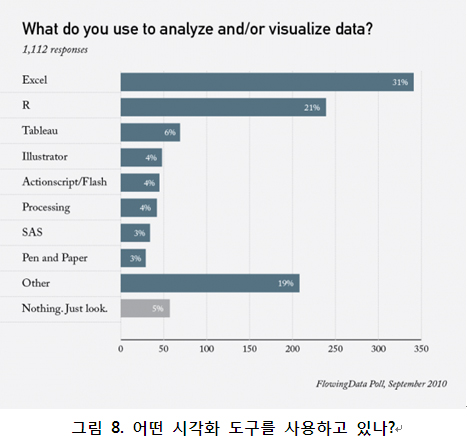
?
마이크로소프트 엑셀과 R가 과반을 넘고 있는 상황을 알 수 있다. flowingdata가 시각화와 관련해 유한 사이트라는 것을 감안할 때 유의미한 설문 결과이다. 사실 엑셀은 훌륭한 도구이지만, 이에 대한 책은 주변에 굉장히 많고 다룰 수 있는 데이터 레코드 개수에 한계가 있다는 점 때문에 필자는 R로 데이터를 시각화하는 방법을 소개하겠다. 데이터를 시각화하는 세 단계는 아래와 같다.
① 데이터를 (어떻게든지) 구한다.
② 데이터를 시각화하기 위한 데이터로 변형시킨다.
③ 데이터를 시각화한다.
④ 시각화 꾸미기(옵션)
위 과정을 거치려면 다양한 지식이 필요하다. 그러나 다행스럽게도 2?3번의 경우 R라는 언어에서 탁월한 기능을 제공한다. 물론 1의 경우는 data.gov, UCI Machine Learning Repository(http://archive.ics.uci.edu/ml/) 등과 같은 오픈 데이터 사이트에서 구할 수 있으며, 몇몇 유명한 데이터는 R에서도 제공하고 있으니 크게 걱정하지 않아도 된다. 4의 경우 많은 독자들이 비싼 툴인 어도비 일러스트레이터를 주로 활용하지만, 필자의 경우 오픈소스인 Inkscape로 간단하게 편집하곤 한다. 그럼 다음 연재부터 다음과 같은 주제로 복잡한 데이터 시각화 방법을 여러분과 함께 알아보겠다.
출처 : 한국데이터베이스진흥원
제공 : DB포탈사이트 DBguide.net
?