
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
최상운의 사선(死線)에서 (5회) : 현행 모델 개선방향과 TO-BE 모델링 방향성 수립
작성자
관리자
작성일
2020-08-28 18:18
조회
1765
최상운의 사선(死線)에서 (5회)
현행 모델 개선방향과 TO-BE 모델링 방향성 수립
?| [필자 소개]?
최상운은 2000년 중반부터 데이터 관련 직무를 수행하고 있다. 은행·보험·증권·신용카드사 프로젝트에서 데이터 아키텍트, 데이터 모델러, PMO(Project Management Officer)를 수행했고, ISP 컨설팅에 참여했다. 한국데이터산업진흥원(KDATA)에서 주최하는 ‘DA 설계 공모대전’에서 2018년에 대상을, 2016년에는 금상을 각각 수상했다. 복잡하고 어려운 모델이 아닌 ‘업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델’을 만들기 위해 현장에서 땀 흘리고 있다. |
|
현장에서 전하는 데이터 모델링 이야기 필자는 수년간 시스템 통합(SI) 프로젝트에서 데이터 아키텍터, 데이터 모델러, PMO, 컨설턴트로서 역할을 했다. 그때마다 ‘왜 저렇게 데이터 모델링을 하지? 어떻게 하면 사람들이 데이터 모델 이론을 쉽게 익히고 베스트는 아니지만 모델에 업무를 표현하고 관련자에게 공유할 수 있도록 도와줄 수 있을까?’를 놓고 고민했다.정답은 아니지만 데이터 모델링 과정을 이해하고 각 과정에서 해야 할 것과 점검할 것을 자료 형태로 정리하면 도움이 될 것 같아 조금씩 정리하고 있었다. 어렵고 복잡한 데이터 모델 이론은 배제하고 개발자 입장에서 접근 가능한 데이터 모델 이론을 소개하고, 실제 베스트와 워스트 데이터 모델 사례를 소개함으로써 '제대로 된 상당한 수준의 모델'보다는 '업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델'을 작성할 수 있도록 하고 싶다는 생각에 감히 도전하게 되었다. 필자는 SI 프로젝트 현장에서 데이터 모델러로서 생사가 갈리는 전쟁터, 그 사선(死線)을 넘나들고 있다. 어떻게 하면 이 사선을 넘어 목표 지점에 도달할 수 있을까? 이 차원에서 다소 무겁지만 현장에서 겪는 문제점들을 먼저 알아보고, 나름대로 대책도 제시해 보고자 한다. 대책이 정답은 아니더라도, 모든 것을 해결할 수는 없더라도, 새롭고 획기적인 방법은 아니더라도 모델 다운 데이터 모델을 만들기 위한 방법을 생각했고 그것을 나누고자 이 글을 시작한다. |
현행 모델의 문제점으로부터 개선방향을 도출하고 고객 요구사항을 정리해, 고객과 이해 관계자에게 TO-BE 모델의 방향성을 제시한다.
? 개선방향 정의
지난 회에는 리버스 ERD로 엔터티, 식별자, 관계, 속성을 분석했다. 이 분석을 통해 현행 데이터 모델에 있는 문제점을 발견할 수 있었다. 이번 회에는 이 문제점을 데이터 모델 이론과 각 프로젝트에서 세운 데이터 모델 원칙에 입각해 어떻게 개선할 것인가를 알아본다.모델의 구성요소인 엔터티, 식별자, 관계, 속성을 상위 카테고리로 하고 토픽별로 정리해 발견된 문제점과 이를 어떻게 개선해야 하는지와 어떤 시사점이 있는지 기술한다.
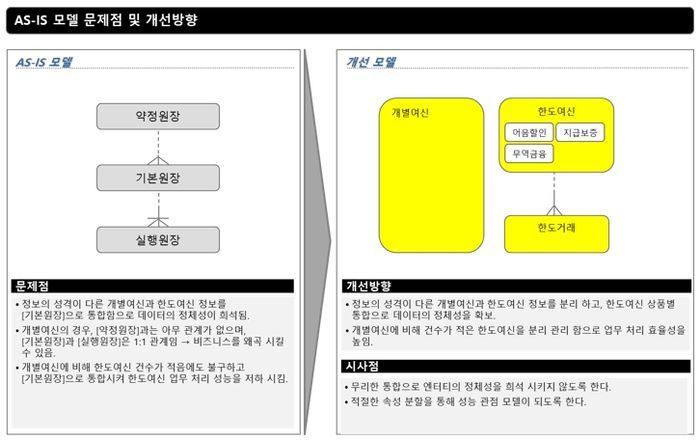
[그림 1] AS-IS 모델 문제점과 개선방향 PPT 예제
[그림 1]은 AS-IS 모델의 문제점에 대한 개선 모델과 TO-BE 모델의 방향성 수립 시 고려해야 할 것을 정리한 예제다.
?
다소 차이는 있으나 다수 프로젝트에 공통적으로 발견되는 문제점과 개선방향을 정리해 보았다.
?
1. 엔터티
- 동일 데이터 엔터티의 중복 관리
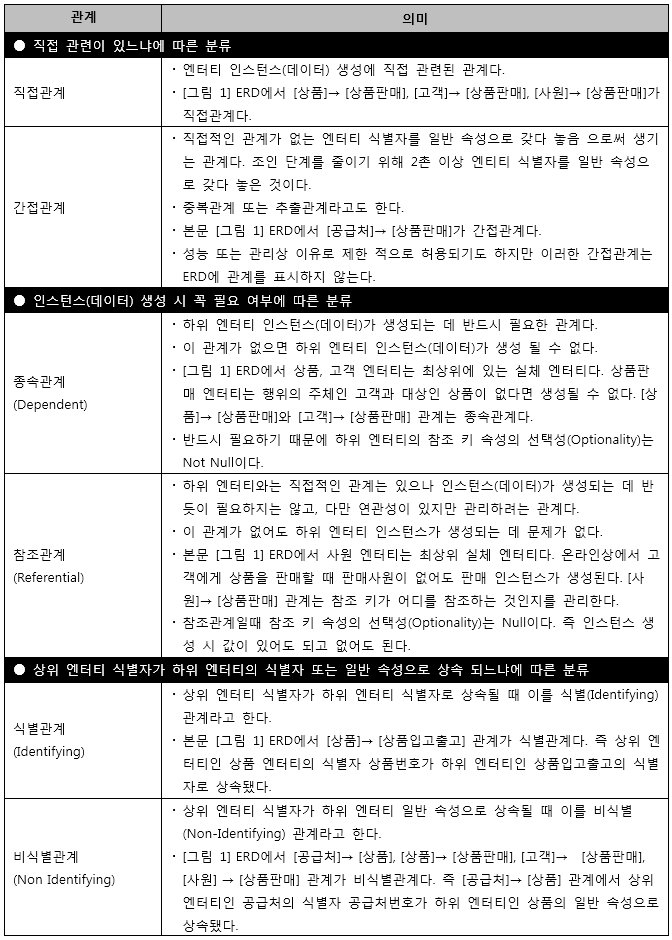
[표 1] 분류 기준에 따른 관계 종류
프로젝트 현장에선 관계선이 그어져 있는 ERD를 보기 힘들다. 혹 관계선이 그어져 있더라도 1차원적 관계만 그어져 있고, 중요한 업무 규칙을 반영한 관계가 그어져 있지 않다. 그나마 그어져 있는 관계선도 정해진 표기법(Notation, 식별/비식별, 관계비, Null 옵션 등)과 틀리게 그어져 있는 경우도 많다(두 엔터티의 식별자가 동일한데 관계비(Cardinality)를 1:N으로 한 것 등).
우리는 리버스 ERD를 분석하고 있다. 따라서 아직 ERD에는 관계선이 없는 상태다. 지금부터는 리버스 ERD에서 어떻게 엔터티간 관계를 도출(분석)하는 방법을 설명한다.
앞서 전체 업무의 80%을 담당하는 20% 엔터티에 집중하기로 했다. 20%에 해당되는 엔터티를 리버스 ERD에 보기 좋게 엔터티명 또는 테이블명에 공통된 단어가 있는 것끼리 모아 놓고 좌우 정렬한다.
엔터티명 또는 테이블명에 공통된 단어가 있으면 관련성이 높을 수 있다. 많은 사이트에서 테이블명을 부여할 때 특정 규칙에 따라 부여한다. 업무 코드라든지, 같은 업무내에서도 특정 영역을 구분하는 구분자를 테이블명에 포함시킨다. 따라서 현행 테이블 명명 규칙을 사전에 파악해 두어야 한다.
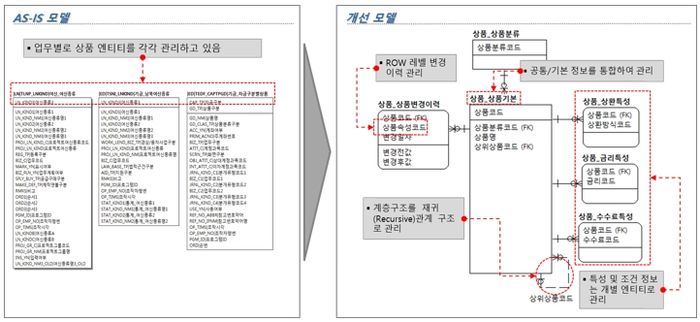
[그림 2] 동일 데이터 엔터티 중복 관리 개선방향
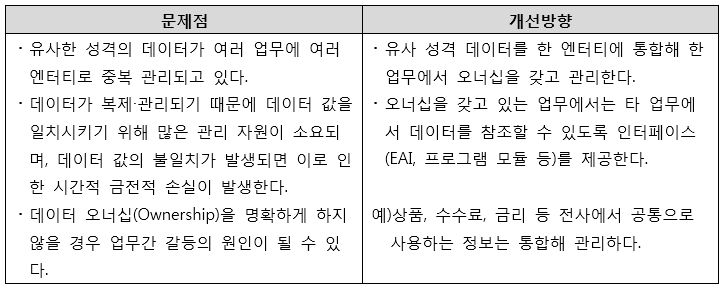
[그림 3] 유연성과 확장성 부족 개선방향

- 서브타입 오류
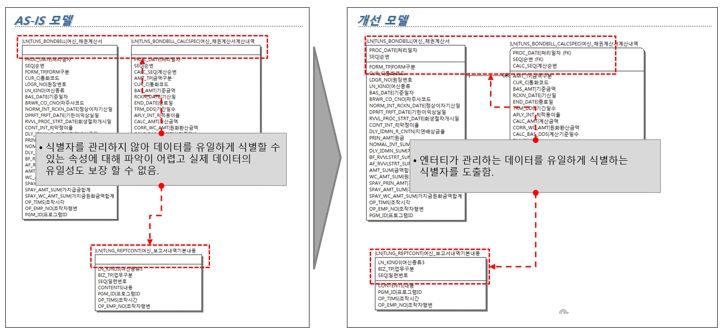
[그림 4] 식별자 부재 개선방향

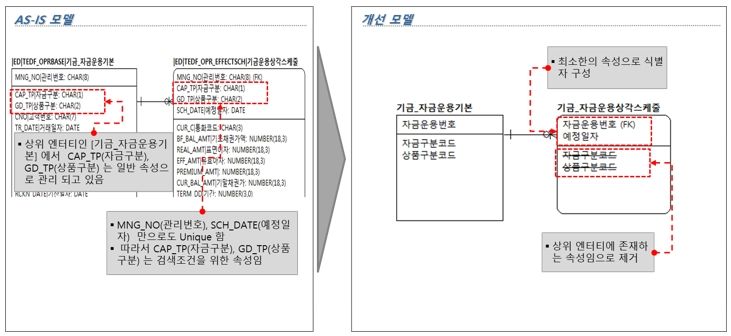
[그림 5] 정확하지 않은 식별자 개선방향
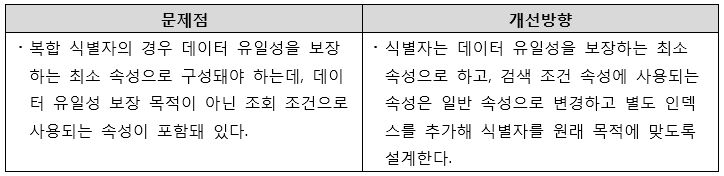
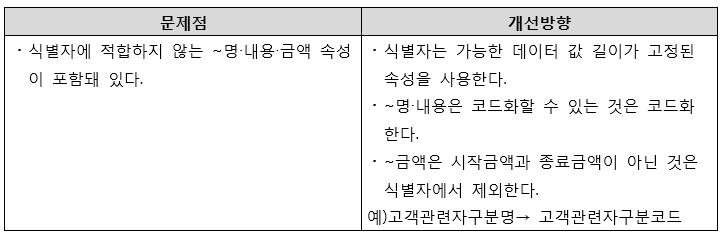
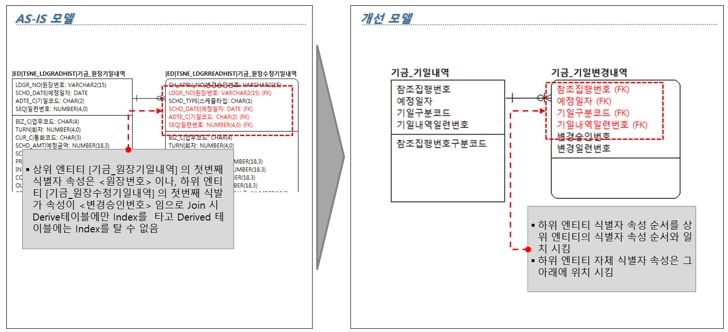
[그림 6] 복합 식별자 상속 순서 오류 개선방향

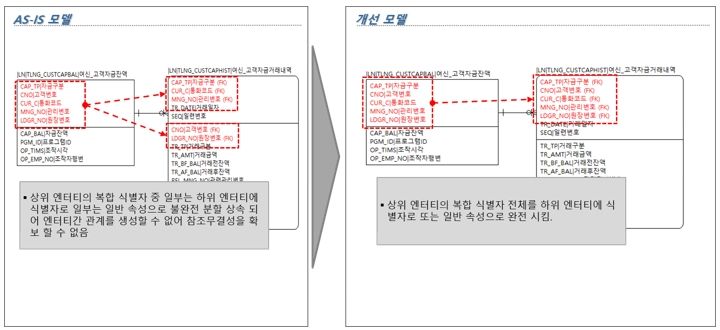
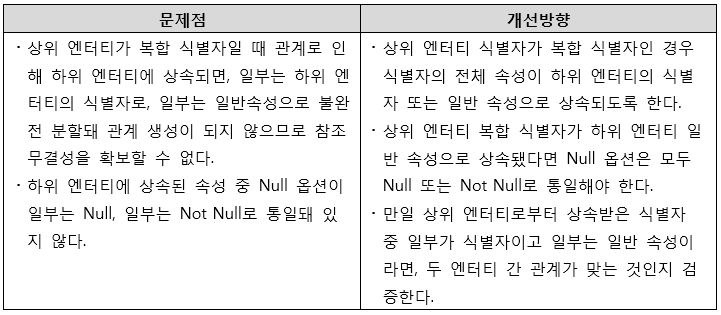
[그림 7] 복합 식별자 분할 상속 오류 개선방향
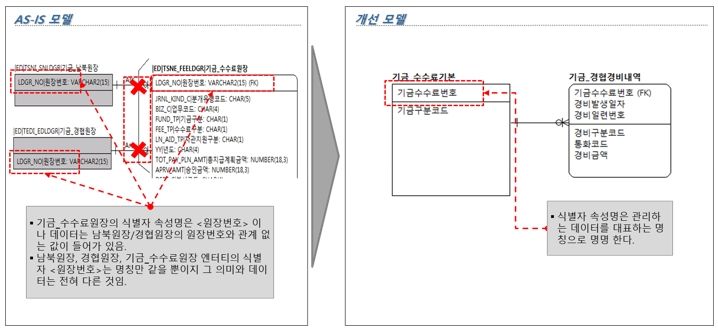
[그림 8] 식별자 명칭 유일성 부재 개선방향

3. 관계
ERD에 관계가 없는 엔터티가 많으므로 ERD에 표시된 관계를 기준으로 개선방향을 도출한다.
- 관계 표기(Notation) 오류
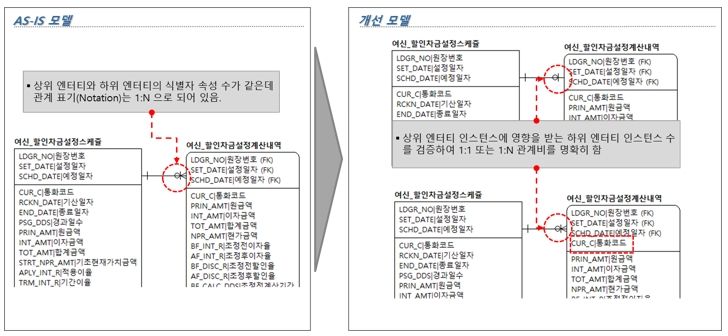
[그림 9] 관계 표기 오류 개선방향
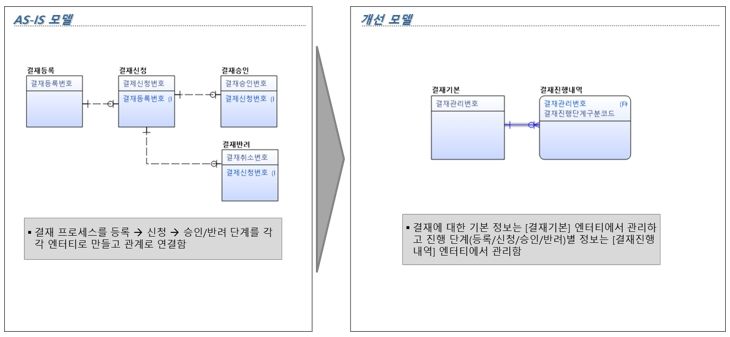
[그림 10] 업무 프로세스를 관계로 표현해 오류 개선
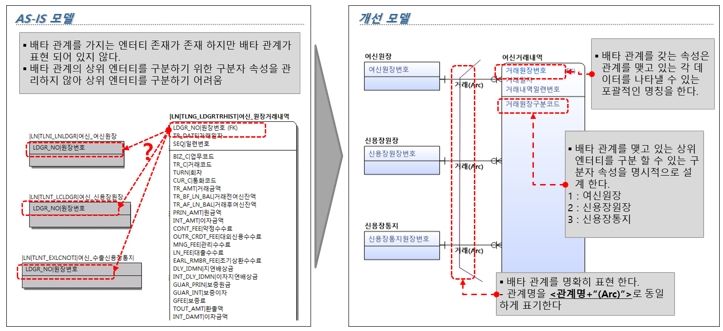
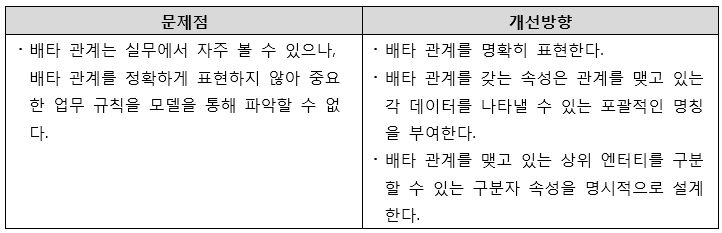
※ 배타 관계(Exculsive Relationship): 엔터티가 두 개 이상의 상위 엔터티와 관계를 갖는데, 그 관계는 동등하며 상호 배타 적일 때의 관계를 말한다. 하위 엔터티 인스턴스는 두 개 이상의 상위 엔터티 중 한 상위 엔터티와만 관계를 갖는다.
4. 속성
- 반복 속성
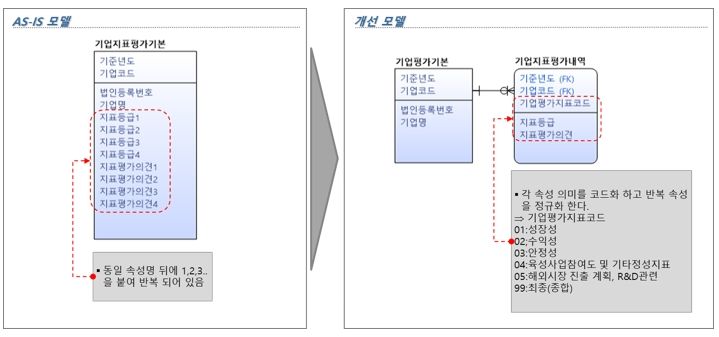
[그림 12] 반복 속성 개선방향

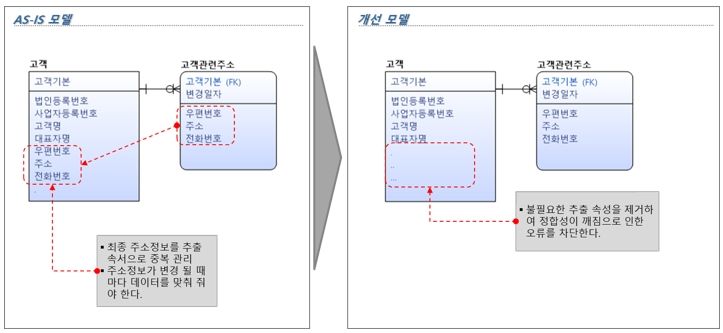
[그림 13] 무분별한 추출(Derived, 중복) 속성 개선방향
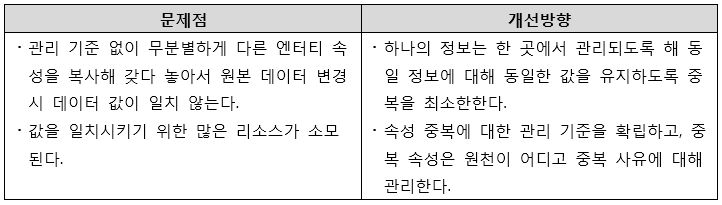
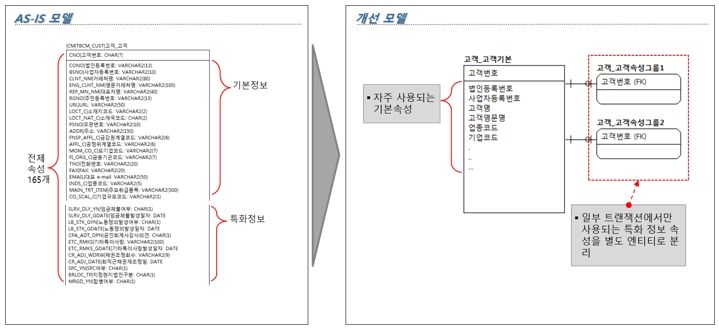 [그림 14] 한 엔터티에 너무 많은 속성 존재 개선방향
[그림 14] 한 엔터티에 너무 많은 속성 존재 개선방향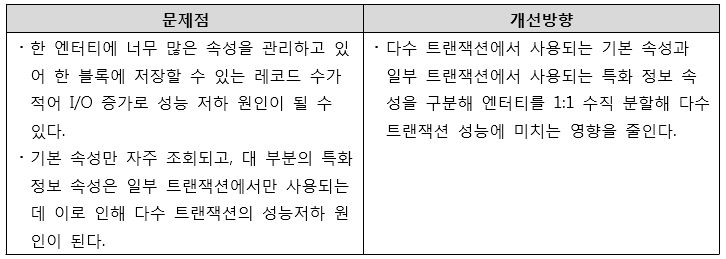
?
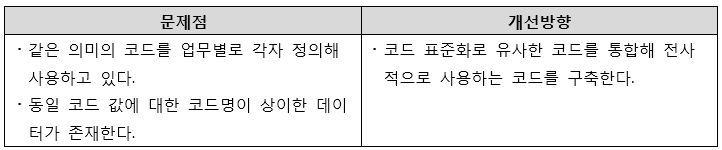
- 속성 표준화 미 적용
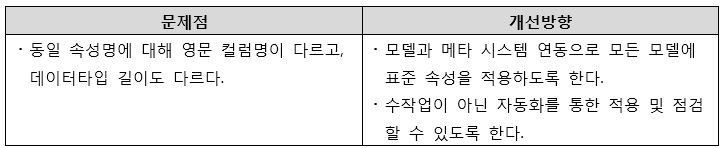
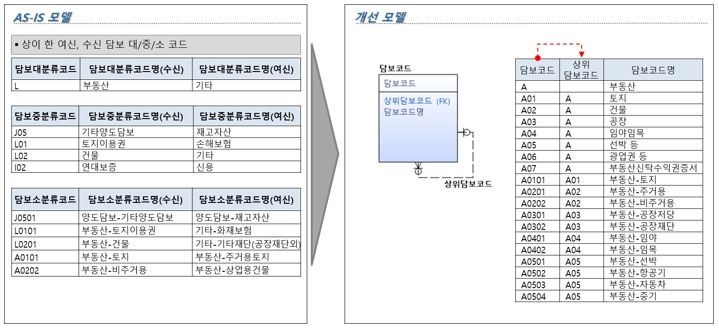
[그림 15] 코드 표준화 미비 개선방향
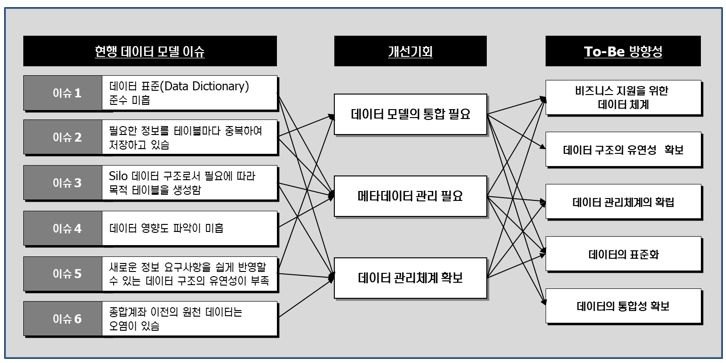
[그림 16] TO-BE 데이터 모델링 방향성 예시
지금까지 현행분석 단계에서 해야 할 것을 소개했다. 다음 연재부터 본격적으로 데이터 모델링을 다루겠다. (다음 회에 계속)
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)