
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (3회) : 엔터티 계층과 릴레이션십 구성
작성자
관리자
작성일
2020-08-28 18:17
조회
838
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (3회)
엔터티 계층과 릴레이션십 구성
| 필자: 노찬형
빅터플랫폼 CIO. 대학에서 소프트웨어공학을 전공했으며 개발자로 사회 생활을 시작했다. 사회 생활 10년을 넘기고 시작했던 DB 공부가 프로그래머로서 자신을 분명하게 되돌아볼 수 있는 기회를 주었다. 사회 초년생 또는 대학생에게 도움이 되는 데이터 모델링 글을 쓰고 싶은 게 그의 작은 바람이다. pemaker@gmail.com |
|
주경야독하는 이들을 위해 우연한 일이 계기가 돼 필자는 DB와 데이터 모델링을 글로 정리할 수밖에 없는 상황에 맞닥뜨렸다. 필자는 2012년부터 2013년까지 한 대학에서 DB 강의를 했다. 강의를 요청받았을 때, 어떻게 해야 할지 난감했다. 필자가 맡은 반은 낮에는 일하고 저녁에 공부하는 학생들로 구성돼 있었다. 일반 대학생들처럼 많은 시간을 공부에 쓸 수 없는 학생들에 DB를 알려줘야 했다. 어떻게 하면 그들에게 작으나마 도움이 될까 하고 고민하던중 시중 교재 대신, 필자가 직접 강의 자료를 만들어 보면 좋겠다는 생각을 하기에 이르렀다.물론 시중의 책이 부족해서 그런 것은 아니다. 필자가 자료를 직접 만들어 쓰면, 일반 책으로 했을 때보다 더 쉽게 소개할 수 있을 것 같아서 그랬다. 누가 보더라도 이해하기 쉽게 전달하겠다는 목표로 강의 자료를 만들기 시작했다. 2년 넘게 강의 자료를 준비하다 보니, DB의 기초와 데이터 모델링의 기초에 대한 내용을 어느 정도 만들어 낼 수 있었다. 학생들이 강의자료를 요청하면 줬다. 하지만 설명이 없는 프레젠테이션 문서라서 아쉬웠다. 설명이 추가되면 학생들이 예습/복습을 할 때도 훨씬 좋을 텐데…. 배웠거나 배울 학생들을 위해 프레젠테이션 문서를 글로 정리하기 시작했다. 말보다 글로 정리하는 게 더 어렵다는 걸 실감하는 순간의 연속이었다. ‘하늘 아래 새로운 건 없다’는 말처럼 필자의 강의 자료 역시 인식하든 못하든 수많은 자료와 가르침을 받았던 결과물들이다. 물론 보고 들었던 이론을 개발 현장에서 적용?확인하는 과정을 거친, 경험의 산물이다. 앞으로 몇 회에 걸쳐 ‘제로에서 시작하는 데이터 모델링’ 연재를 하겠다고 용기를 내보았다. 독자 여러분과 함께 쓴다는 생각으로 수많은 의견이나 접근 방법을 댓글 또는 이메일로 받을 수 있었으면 좋겠다. |
지난 1~2회에 이어 이번 회에도 릴레이션십에 대해 알아본다.
?
? 엔터티 계층
1) 엔터티 계층엔터티를 도출하고 릴레이션을 설정하면 상속을 통해 전체적으로 자연스럽게 계층화가 이뤄진다. 부모로부터 자식으로 상속되고 그 자식으로부터 자식에게 상속돼 현실 세계의 가족 구조와 비슷하게 된다.
다음의 예를 같이 보자.
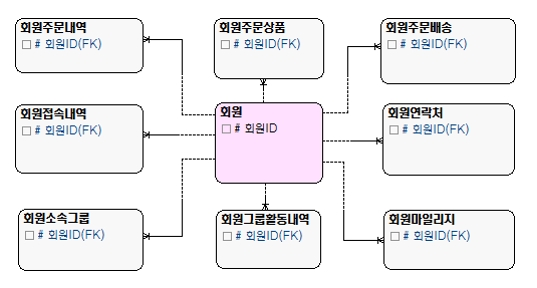
[그림 1] 계층이 없는 모델
다음 [그림 2]는 비교적 잘 도출한 모델이다. 그림이 작아서 자세한 내용을 볼 수 없겠지만, 모델의 전체적인 모습을 보고 그 모양을 느껴보기 바란다.
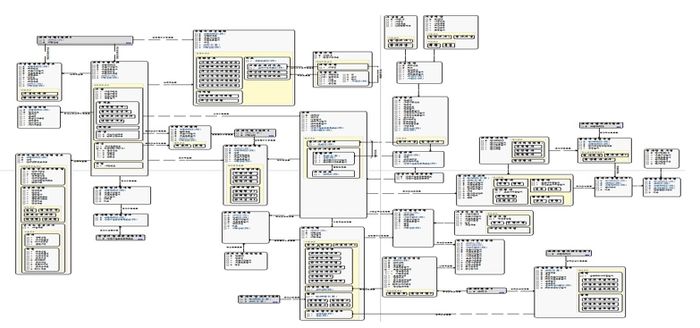
[그림 2] 계층이 있는 모델
2) 관계와 SQL
엔터티 간 관계를 통해 자연스럽게 엔터티의 계층화가 이뤄지면, 차상위의 엔터티 정보 찾기가 어렵다고 생각하는 경우가 있다. 그런데 아버지 엔터티가 할아버지 엔터티의 식별자를 물려주었다면, 할아버지의 정보를 직접 찾을 수 있으므로 SQL이 복합하지 않을 수 있다. 즉 관계는 반드시 지나가야 하는 경로(path)가 아니다.
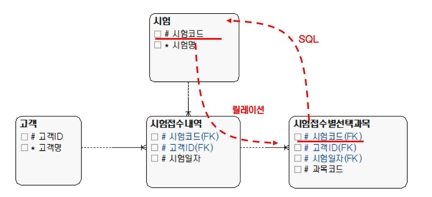
[그림 3] 엔터티의 계층과 SQL Join
관계는 시험-시험접수내역-시험접수별선택과목 순이지만, SQL을 작성할 때는 시험과 시험접수별선택과목을 직접 조인해 사용할 수 있다. 과목코드 ‘10’인 고객목록을 조회하는 SQL은 다음과 같이 간단하게 작성할 수 있다.

? 릴레이션십의 구성
릴레이션십은 name, cardinality, optionality(selectivity)라는 3가지 요소를 이용해 표현된다.1) Name
릴레이션십이 설정되면 해당 릴레이션십의 이름, 즉 관계명을 기술하는 것이 좋다. 해당 릴레이션을 단순히 관계선만 보고 추정 가능한 때도 있지만, 그렇지 않은 경우도 있다. 따라서 본인을 위해서나 추후 모델을 관리하고 참조해야 하는 담당자를 위해서도 기술하는 것이 좋다.
기억력을 자만해서는 안된다. 다들 알겠지만 순간의 기억이 장기 기억으로 가기 위해서는 많은 노력과 반복이 필요하다. 그러므로 자신의 머리와 기억력을 믿지 말고 가능하면 기록을 습관화해야 한다.
관계에 명칭을 정의하는 것은 엔터티와 마찬가지로 해당 릴레이션이 어떤 집합인지를 보여준다.
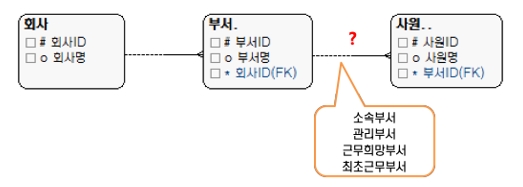
[그림 4] 관계 명칭
관계명은 바라보는 관점에 따라 달라진다. 예를 들어 부부에서 남자는 여자의 남편이 되고, 반대일 경우는 아내가 되듯>
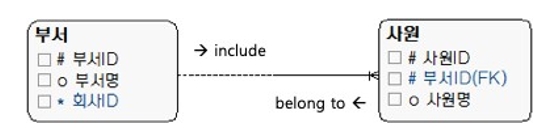
[그림 5] 관계명 관점
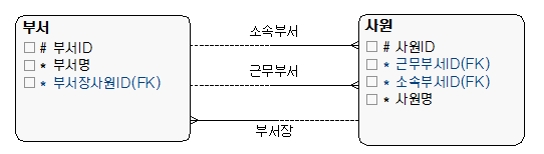
[그림 6] 관계 명칭
관계명칭을 써야 하는 경우는 롤(Role) 이름이 필요할 때, 순환 관계일 때, 추출 관계일 때, 양방향 관계일 때, 다대다 관계일 때다. 반면에 부모(상위) 엔터티에 일대다(1:M)로 종속되는 관계는 관계명을 굳이 쓰지 않아도 되나, 처음에는 쓰는 것을 습관화하면 좋다.
다음 회에는 릴레이션십 구성에 대해 살펴보겠다. (다음 회에 계속)
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)