
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
최상운의 사선(死線)에서 (4회) : 현행 모델 분석 3: 리버스 ERD를 이용한 관계, 속성 분석
작성자
관리자
작성일
2020-08-28 18:16
조회
4692
최상운의 사선(死線)에서 (4회)
현행 모델 분석 3: 리버스 ERD를 이용한 관계, 속성 분석
| [필자 소개]?최상운은 2000년 중반부터 데이터 관련 직무를 수행하고 있다. 은행·보험·증권·신용카드사 프로젝트에서 데이터 아키텍트, 데이터 모델러, PMO(Project Management Officer)를 수행했고, ISP 컨설팅에 참여했다. 한국데이터산업진흥원(KDATA)에서 주최하는 ‘DA 설계 공모대전’에서 2018년에 대상을, 2016년에는 금상을 각각 수상했다. 복잡하고 어려운 모델이 아닌 ‘업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델’을 만들기 위해 현장에서 땀 흘리고 있다. |
|
현장에서 전하는 데이터 모델링 이야기 필자는 수년간 시스템 통합(SI) 프로젝트에서 데이터 아키텍터, 데이터 모델러, PMO, 컨설턴트로서 역할을 했다. 그때마다 ‘왜 저렇게 데이터 모델링을 하지? 어떻게 하면 사람들이 데이터 모델 이론을 쉽게 익히고 베스트는 아니지만 모델에 업무를 표현하고 관련자에게 공유할 수 있도록 도와줄 수 있을까?’를 놓고 고민했다.정답은 아니지만 데이터 모델링 과정을 이해하고 각 과정에서 해야 할 것과 점검할 것을 자료 형태로 정리하면 도움이 될 것 같아 조금씩 정리하고 있었다. 어렵고 복잡한 데이터 모델 이론은 배제하고 개발자 입장에서 접근 가능한 데이터 모델 이론을 소개하고, 실제 베스트와 워스트 데이터 모델 사례를 소개함으로써 '제대로 된 상당한 수준의 모델'보다는 '업무가 정확히 담겨 있고 모두가 이해할 수 있는 모델'을 작성할 수 있도록 하고 싶다는 생각에 감히 도전하게 되었다. 필자는 SI 프로젝트 현장에서 데이터 모델러로서 생사가 갈리는 전쟁터, 그 사선(死線)을 넘나들고 있다. 어떻게 하면 이 사선을 넘어 목표 지점에 도달할 수 있을까? 이 차원에서 다소 무겁지만 현장에서 겪는 문제점들을 먼저 알아보고, 나름대로 대책도 제시해 보고자 한다. 대책이 정답은 아니더라도, 모든 것을 해결할 수는 없더라도, 새롭고 획기적인 방법은 아니더라도 모델 다운 데이터 모델을 만들기 위한 방법을 생각했고 그것을 나누고자 이 글을 시작한다. |
ERD(Entity Relationship Diagram)란 말 그대로 엔터티(Entity)간 관계(Relationship)를 표시한 그림(Diagram)이다.
관계형 DB(RDB, Relationship Database)는 데이터를 중복하지 않고 한 곳에서만 관리하고, 파생되거나 연관성이 있는 데이터를 참조 키로 연결해 필요 시 참조 키로 조인하여(Join) 필요한 데이터를 조회하는 것이다. 그만큼 관계는 ERD의 핵심 요소다.
? 관계 분석
관계는 엔터티 간 존재하는, 즉 데이터 집합 간 존재하는 연관성을 정해진 표기법(Notation)에 따라 표현하는 것이다.이 후 연재에서 자세히 알아 보겠지만 엔터티간에는 많은 관계가 존재한다. 이 모든 관계를 다 분석할 필요도 없고, 다 ERD에 표시 할 필요도 없다. 리버스 ERD를 이용한 현행 모델 분석 단계에서는 직접관계만 분석한다.
SNS에서는 아는 사람을 몇 단계만 거치면 미국 대통령과도 관계가 연결된다고 한다. 하지만 데이터모델링에서 관계는 1촌까지만 관리한다. 데이터모델링에서 관계는 마치 점조직과 같아서 바로 옆에 있는 접촉점이 있는 엔터티만 알면 된다. 그 다음 관계는 그 다음 엔터티의 접촉점이 있는 엔터티를 통해 알 수 있다.
직접관계란 말 그대로 엔터티 인스턴스(데이터) 생성에 직접 관련된 관계를 말한다.
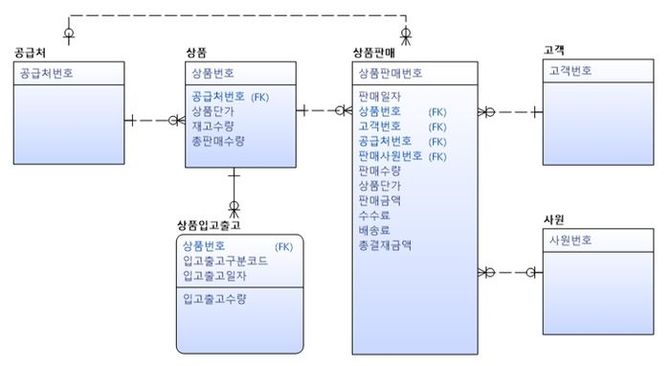
[그림 1] 관계 설명 ERD(IE(Information Engineering) Notation으로 표기)
[그림 1] ERD에서 상품판매 엔터티 정의를 '고객에게 자사가 제공하는 유형/무형의 상품을 판매한 내역'이라고 한다면 상품판매 엔터티는 고객 엔터티, 상품 엔터티와 직접적인 관계가 있다. 또한 사원 엔터티도 상품을 판매한 사원으로서 상품판매 엔터티와 직접적인 관계가 있다. 반면 공급처 엔터티는 상품 엔터티와 직접적인 관계가 있으나, 상품판매 엔터티와는 직접적인 관계가 없다. 상품판매 인스턴스는 공급처 없이도 생성되기 때문이다.
그러면 왜 [공급처]→ [상품판매] 관계를 ERD에 표시했을까? 결론부터 말하면 표시하지 말아야 할 관계를 표시한 것이다. 상품판매 엔터티에서 공급처번호는 상품판매 엔터티가 본질적으로 가지고 있는 속성이 아닌 상품 엔터티에서 가져온 속성이다(이 후 설명하겠으나 공급처번호는 추출 속성 중 중복 속성에 해당한다.).
만일 상품판매 엔터티에 공급처번호가 없다면 상품에 대한 공급처를 가져오기 위해서는 상품 엔터티와 조인해야 한다. 상품판매 내역 조회 시 상품의 공급처를 포함해 조회하기 때문에 상품 엔터티와 조인을 하지 않으려고 가져다 놓은 속성이다.
직접관계와 대비되는 관계를 간접관계라고 한다.?간접관계는 직접적인 관계가 없는 엔터티의 식별자를 일반 속성으로 갖다 놓음으로써 생기는 관계다. 인스턴스 생성에 관여하지 않는 관계 임으로 제거돼야 한다.
간접관계는 조인 단계를 줄이기 위해 2촌 이상 엔터티 식별자를 일반 속성으로 갖다 놓은 것이다. [그림 1]에서 [공급처]→ [상품판매] 관계가 간접관계에 해당한다. 본질이 아닌 속성을 갖다 놓은 것이기 때문에 추출 속성(Derived Attribute) 가운데 중복 속성이며, 추출 속성 특성상 이 속성을 삭제하더라도 원천만 존재하면 언제라도 재현할 수 있다. 성능 또는 관리상 이유로 제한적으로 허용되기도 하지만, 이러한 간접관계는 ERD에 관계를 표시하지 않는다.
단 ERD는 이해 당사자간 커뮤니케이션 도구 역할도 하기 때문에, 이해 당사자의 모델에 대한 이해를 높이기 위해 ERwin에서는 관계를 Logical Only로, DA#에서는 가상 관계로 표시하여 어떤 엔터티와 간접관계가 있는지 표현할 수 있다(이 방법 또한 이후 연재에서 설명한다.).
분류 기준에 따른 관계 종류를 간단하게 정리하면 [표 1]과 같다.
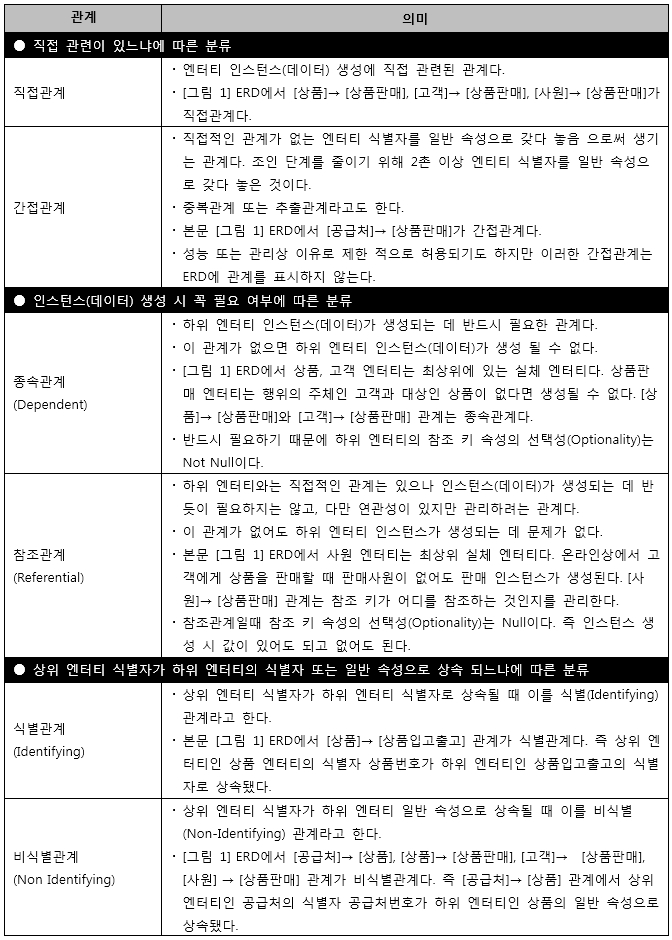
[표 1] 분류 기준에 따른 관계 종류
프로젝트 현장에선 관계선이 그어져 있는 ERD를 보기 힘들다. 혹 관계선이 그어져 있더라도 1차원적 관계만 그어져 있고, 중요한 업무 규칙을 반영한 관계가 그어져 있지 않다. 그나마 그어져 있는 관계선도 정해진 표기법(Notation, 식별/비식별, 관계비, Null 옵션 등)과 틀리게 그어져 있는 경우도 많다(두 엔터티의 식별자가 동일한데 관계비(Cardinality)를 1:N으로 한 것 등).
우리는 리버스 ERD를 분석하고 있다. 따라서 아직 ERD에는 관계선이 없는 상태다. 지금부터는 리버스 ERD에서 어떻게 엔터티간 관계를 도출(분석)하는 방법을 설명한다.
앞서 전체 업무의 80%을 담당하는 20% 엔터티에스 ERD에 보기 좋게 엔터티명 또는 테이블명에 공통된 단어가 있는 것끼리 모아 놓고 좌우 정렬한다.
엔터티명 또는 테이블명에 공통된 단어가 있으면 관련성이 높을 수 있다. 많은 사이트에서 테이블명을 부여할 때 특정 규칙에 따라 부여한다. 업무 코드라든지, 같은 업무내에서도 특정 영역을 구분하는 구분자를 테이블명에 포함시킨다. 따라서 현행 테이블 명명 규칙을 사전에 파악해 두어야 한다.
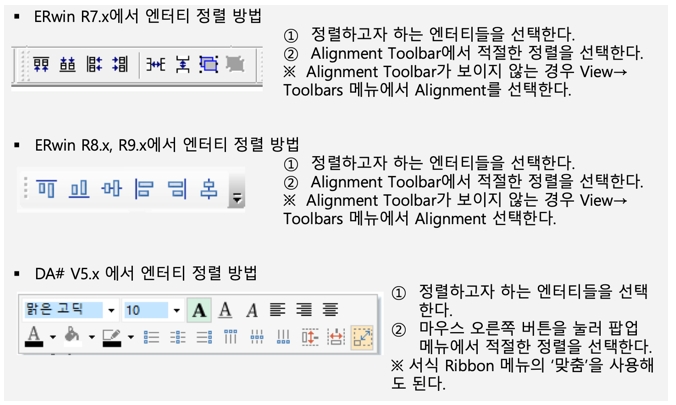
[그림 2] 모델링 Tool 에서 엔터티 정렬 방법
(1) 실체·주요 엔터티 식별자와 주위 엔터티 식별자 간 비교
- 실체·주요 엔터티를 가운데 배치하고 그 주위에 나머지 엔터티를 배치한다.
- 가운데에 있는 실체·주요 엔터티의 식별자와 주위에 있는 엔터티의 식별자와 비교한다.
- 실체·주요 엔터티 식별자명 앞에 수식어를 붙여 사용하는 경우가 있으므로 데이터타입 길이도 감안하여 실체·주요 엔터티와 식별자가 같거나(1:1 관계, 식별자를 구성하는 속성의 명칭, 데이터타입 길이가 같아야 한다.). 실체·주요 엔터티의 식별자 + 추가 속성(1:N 관계)인 것을 찾아 관계선을 맺는다.
- 이때 주의해야 할 것은 관계선을 맺으면 상위 엔터티의 식별자가 하위 엔터티에 상속되면서 하위 엔터티 속성에 FK가 설정되는데, 나중에 검증 시 잘못 맺은 관계선을 삭제하면 하위 엔터티에서 FK 속성이 삭제되고 만다. 이 때문에 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용해 일단 두 엔터티 간 관계가 ‘있는 것 같다’는 것만 표시해 두고 나중에 관계 검증 후 정상적인 관계선을 맺도록 한다.
(2) 실체·주요 엔터티 식별자와 주위 엔터티 일반 속성 간 비교
이번에는 실체·주요 엔터티 식별자와 주위에 있는 엔터티의 일반 속성과 비교한다.
- 기본 적인 방법은 식별자 간 비교하는 것과 동일하다.
- 일반 속성이 많으면 ~번호, ~일련번호, ~식별자, ~코드 속성을 위주로 보면서 실체·주요 엔터티 식별자와 유사한 속성이 있는지 확인한다.
- 용어 표준화가 잘된 모델은 상위 엔터티의 식별자가 하위 엔터티에 상속될 때 속성명을 그대로 사용하거나 '수식어+식별자'로 돼 있어 쉽게 찾을 수 있다. 하지만 우리가 수행하는 대부분의 프로젝트는 용어 표준화가 잘 돼 있지 않거나, 일부 업무에만 적용돼 있는 경우가 많다. 따라서 가운데에 있는 실체·주요 엔터티 식별자 속성과 일반 속성과 데이터타입 길이를 함께 비교해 보고 관계 존재 유무를 판단하도록 한다.
(3) 다른 모델에 있는 엔터티와 관계 찾기 및 ERD 표시 방법
지금까지 같은 모델에 있는 엔터티 중 업무의 80%을 담당하는 20% 엔터티 간 관계를 분석(도출) 했다.
그런데 같은 모델이 아닌 다른 모델에 있는 엔터티를 참조하는 경우는 어떻게 할까? 예를 들어 계약 모델에서 상품이나 고객 모델에 있는 엔터티를 참조할 때, 참조하고 있음을 어떻게 확인할 수 있고, 또 그 관계를 ERD에 어떻게 표시할 수 있을까? 모든 모델을 다 분석해야 하나? 짧은 분석 기간 중 내가 맡은 모델도 분석하기 힘든데 다른 사람이 맡고 있는 모델까지 모두 분석하기 란 불가능에 가깝다.
다른 모델에 있는 엔터티와 관계 분석은 다음과 같이 한다.
- 일단 내가 맡고 있는 모델의 실체 엔터티와 주요 엔터티의 식별자 속성의 의미를 확실하게 파악한다.
대부분 다른 모델에서 참조되는 엔터티는 실체 또는 주요 엔터티이기 때문에 내가 맡고 있는 모델의 실체 엔터티와 주요 엔터티 식별자를 확실하게 파악해 둬야 한다.
- 내 모델에서 다른 모델 엔터티를 참조하는 엔터티 역시 대부분 실체·주요 엔터티다. 다른 모델 엔터티 식별자와 비식별 관계가 있는 경우 다른 모델 엔터티 식별자가 내 모델에 일반 속성으로 상속되기 때문에 내 모델의 실체·주요 엔터티의 일반 속성 중 ~번호, ~식별자, ~코드(개별코드) 속성 또는 이들 속성과 ~일련번호, ~일자, ~구분코드(통합코드) 속성과의 속성 조합을 ERD에 표시해 두고(예를 들어 붉은색·기울임·굵게로 구분한다.) 의미를 파악한다.
- 각자 맡고 있는 모델의 실체·주요 엔터티에 대한 분석이 끝나면, 전체 모델러 회의를 하여 내가 맡고 있는 모델의 실체·주요 엔터티 식별자와 표시해 둔 일반 속성을 식별자로 하고 있는 다른 모델 엔터티가 있는지 크로스 체크한다.
- 모델러 간 크로스 체크로 내가 맡고 있는 모델에 표시한 속성 또는 속성 조합이 다른 모델의 엔터티 식별자와 동일하거나 유사하고 의미가 동일한지가 확인되면, 내가 맡고 있는 모델에 엔터티 명을 '[업무명] + 다른 모델의 참조 엔터티명'으로 하고, 다른 모델의 엔터티에서 식별자(속성 명, 개수, 순서로 똑같이 하여)만 표시한 엔터티를 추가하고, 해당 엔터티와 관계를 맺어 ERD에 표시한다. 이때 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용해 향후 검증 단계에서 관계를 삭제해도 원래 있던 속성이 삭제되지 않도록 한다.
?
|
통합코드와 개별코드 코드는 통합코드(공통코드)와 개별코드(목록성코드)로 분류된다.통합코드 특성은 아래와 같다. - 코드, 유효값, 유효값명 등 정해진 정보만 관리한다. - 일반적으로 공통 모델에서 한 엔터티에서 통합·관리된다. - 유효값 입력·조회는 메타시스템을 통해 이뤄진다. - 유효값(인스턴스)이 100개 미만이다. - 일반적으로 코드 앞에 구분·유형·종류·행태·상태 등과 같은 수식어를 붙인다. 예) 고객구분코드, 상품종류코드, 거래종류코드 등 개별코드 특성은 아래와 같다. - 코드, 유효값, 유효값명 이외의 다양한 부가 정보를 관리한다. - 부가 정보가 다양해서 하나의 엔터티에서 관리하기 힘들어, 개별 엔터티에서 관리한다. 이 엔터티의 식별자는 ~코드이다. - 개별코드 엔터티는 오너쉽을 갖는 업무 모델에서 관리된다. - 유효값 입력·조회는 오너십을 갖는 업무의 화면에서 입력·조회된다. - 유효값(인스턴스)가 100개 이상이다. - 일반적으로 구분·유형·종류·행태·상태 등과 같은 수식어를 붙이지 않는다. 예) 부서코드, 증권종목코드, 계정과목코드, 지점코드, 서비스코드 등 |
다음 [그림 3]은 은행 여신 리버스 ERD에서 실체·주요 엔터티를 중심으로 주위 엔터티 간 관계와 다른 모델 엔터티와의 관계를 분석한 예제다.
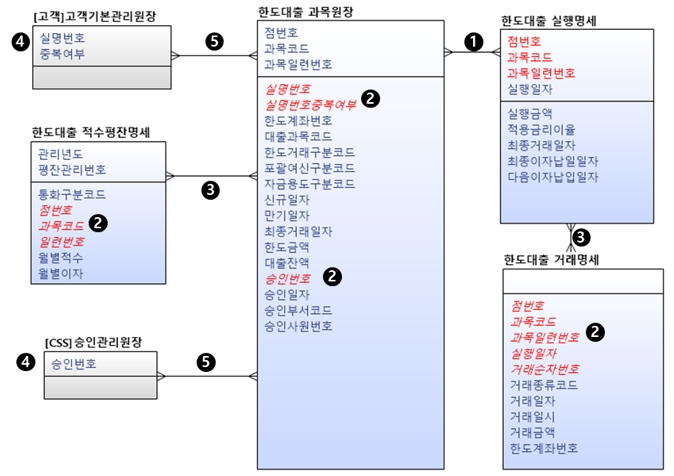
[그림 3] 여신 리버스 ERD 관계 분석(도출) 예제 ERD
|
통합코드와 개별코드 ‘한도대출’ 단어가 들어간 엔터티를 실체·주요 엔터티를 중심으로 배치했다.① 실체·주요 엔터티 식별자와 주위의 엔터티 식별자와 비교해 다대다(Many-to-Many Relationship) 관계선을 사용해 관계를 표시했다. ② 일반 속성 중 ~번호, ~식별자, ~코드 속성 또는 이들 속성과 ~일련번호, ~일자, ~구분코드 속성과의 속성 조합을 ERD에 붉은색과 기울임으로 표시했다. ③ 실체·주요 엔터티 식별자와 주위에 있는 엔터티 일반속성과 비교하여 다대다 관계선을 사용하여 관계를 표시했다. ④ 모델러 간 크로스 체크로 확인된 다른 모델 엔터티를 ‘[업무명] + 엔터티명’으로 하고 식별자만 표시해 ⑤ 다대다 관계선을 사용해 관계를 표시했다. 지금까지 리버스 ERD로 관계를 분석하면서 관계로 인한 식별자 상속이 되지 않도록 하고, 나중에 관계 검증 시 관계 삭제로 인한 속성 삭제를 막기 위해 ERwin에서는 다대다(Many-to-Many Relationship) 관계선을 사용하고, DA#에서는 가상(Pseudo) 관계선을 사용했다. 정확하게 관계를 ERD에 표시하기 위해서는 관계비(Cardinality, 카디널리티), 선택성(Optionality, 옵션널리티), 관계차수(Degree, 디그리)를 관계선에 표시해야 하지만 여기서는 엔터티 간 관계가 있다는 것만 분석하기로 하고, 이후 데이터모델링 단계에서 관계 구성 요소를 정확히 ERD에 표시 하도록 한다. 또한 특수한 관계로 재귀 관계(Recursive)와 배타 관계(Exclusive)가 있으나 이후 연재에서 다루기로 한다. |
? 속성 분석
엔터티에 비해 속성은 수가 너무 많다. 따라서 리버스 ERD 분석에서 속성 하나 하나를 상세하게 분석 하기에는 물리적인 시간이 부족하다.관계와 마찬 가지로 속성도 전체 업무의 80%을 담당하는 20% 엔터티를 대상으로 속성 분석을 한다.
(1) 속성을 분류한다
이 단계에서 모든 속성을 100% 분류할 수도 없고 그럴 필요도 없다. 여기서는 확실히 식별되는 것만 분류하고 기록한다.
엔터티에는 많은 속성들이 있다. 속성 분류 역시 나 혼자서 한다는 생각에서 벗어날 필요가 있다. 사전에 고객사 담당자에게 20% 엔터티가 정렬된 리버스 ERD를 출력·제공하고 ERD에 중요 속성을 표시해 달라고 하고, 인터뷰를 통해 표시된 속성이 기본·관계·추출·시스템 속성인지 분류 한다.
[표 2]는 속성 종류를 정리한 것이다.
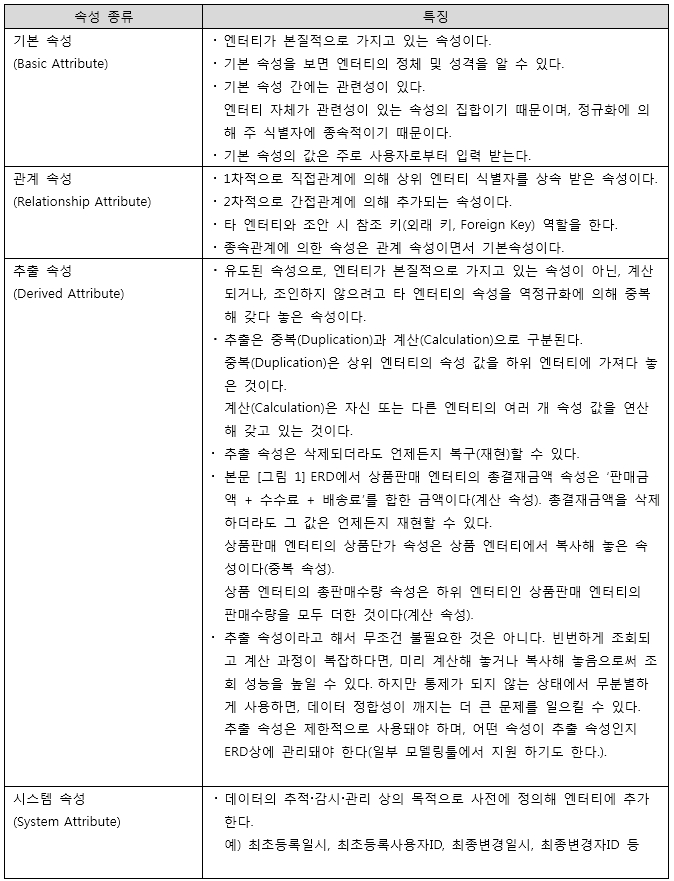
[표 2] 속성 종류
관계 속성은 관계에 의해 또는 조인을 줄이기 위해 추가되는 속성이기 때문에 그리 많지 않다.
시스템 속성은 사전에 정의돼 있기 때문에 쉽게 분류할 수 있다.
문제는 추출 속성인데, 추출 속성을 식별하기 위해서는 엔터티가 관리하는 데이터의 성격을 명확히 파악해야 한다. 이것은 엔터티 정의(Definition)를 정확하게 해야 하는 이유이기도 하다. 상위 엔터티에 있는 속성을 갖다 놓았다고 무조건 추출 속성이라고 할 수 없는 경우도 있다. 또한 계산 속성이라고 해서 무조건 추출 속성이라고 할 수 없는 경우도 있다. 경우에 따라서는 추출 속성으로 보이지만 기본 속성으로 취급해야 하는 경우도 있다. 추출 속성을 식별하기 위해서는 이론적인 배경과 경험이 필요하다.
?
(2) 미사용 속성을 식별한다
리버스 ERD 분석 단계에서는 미사용 속성을 식별 하도록 한다. 물론 대상 엔터티는 20%에 해당 하는 엔터티다.
그 많은 속성에서 어떤 것이 미사용 속성인지를 식별해 내기란 쉬운 일이 아니다. 고객사 담당자도 중요한 속성은 식별해 줄 수 있으나, 미사용 속성은 바로 식별해 주지 못 한다. 그 이유는 엔터티가 생성된 후 고객사 담당자가 변경됐기 때문에, 엔터티 속성 추가 이력에 대한 기록이 없기 때문에, 최근 몇 년간은 데이터가 입력되지 않았지만 그 이전에는 데이터가 있었기 때문에 등 다양하다.
일단 리버스 ERD 분석에서는 미 사용 속성을 식별하도록 하는데, 유의 해야할 것은 이번에 미 사용으로 식별되더라도 이후 데이터모델링 단계에서 사용으로 바뀔 수 있으니 리버스 ERD에서 삭제는 하지 말고 아래 [그림 4]에서와 같이 ERD에 표시를 해두도록 한다.
?
|
통합코드와 개별코드 - 미 사용 속성은 속성 뒤에 (x)를 붙여 표시한다.- 추출 속성은 속성 뒤에 (d)를 붙여 표시한다. - 시스템 속성은 속성 뒤에 (s)를 붙여 표시한다. - 관계 속성은 속성 뒤에 (r)를 붙여 표시한다. ? |

[그림 4] 추출·시스템·미사용 속성 표시 ERD
?
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)