
데이터 인사이트
데이터 전문가 칼럼
데이터 전문가가 전하는 데이터 노하우
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (1회) : 헷갈리는 릴레이션십 개념, 제대로 이해하기
작성자
관리자
작성일
2020-08-28 18:12
조회
1030
?
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (1회) : 헷갈리는 릴레이션십 개념, 제대로 이해하기
?
?
‘제로에서 시작하는 데이터 모델링’ 시즌II는 릴레이션십을 알아보는 것으로부터 시작한다. 엔터티 개념을 이해하기도 어려운데 다시 릴레이션이 등장하니 부담스러울 수 있을 것이다. 하지만 데이터 모델링 분야로 진입을 위해서는 꼭 알고 넘어가야 할 존재이다. 개발 현장에서 릴레이션십을 잘못 이해하고 접근하는 경우를 종종 보곤한다. 릴레이션 방향을 반대로 하거나 간접적인 관계에도 릴레이션을 설정하는 경우가 있다. 개발 시스템의 문제와 성능 저하야기 지점이다.
?
릴레이션십(relationship)이란 엔터티와 엔터티의 비즈니적 관계를 나타내며, 엔터티 혼자 표현할 수 없는 집합을 다룬다. 따라서 릴레이션십은 집합이며, 합집합·교집합·차집합 등의 특징을 그대로 갖는다. 엔터티와 마찬가지로 통합과 분리가 가능하다.
릴레이션십은 두 엔터티 사이의 직접적인 관계만 정의한다. 따라서 릴레이션은 두 엔터티 간 비즈니스 연관성을 표현하며 name, cardinality, optionality(selectivity)라는 3가지 요소를 이용해 표현된다. 릴레이션십 없이 데이터 모델에서 분리된 엔터티 내의 데이터들은 서로 고립돼 정보로서의 가치를 잃게 된다.
릴레이션은 개발자들이 어떻게 SQL을 작성할지를 결정해 주는 요소이기도 하다. 릴레이션이 잘못되면 SQL 작성이 잘못되며, 그로 인해 시스템 성능 저하와 원하는 데이터 추출이 힘들어질 수 있다.
데이터 모델은 데이터를 중복없이 관리하고 필요할 때 연결해서 보는 것이 핵심이다. 데이터 모델은 비즈니스를 집합으로 보고 엔터티로 표현한 것으로서 엔터티만으로는 전체 집합을 완성할 수 없다.
연결해서 본다는 말은 SQL의 JOIN을 의미하는 것으로, 연결하기 위해서는 엔터티 간의 관계가 있어야 한다. 엔터티가 도출되고 엔터티 간 관계가 도출돼야만 전체 집합을 완성할 수 있다. 릴레이션은 엔터티와 엔터티 간의 비즈니스 관계를 나타내며, 엔터티가 표현할 수 없는 집합을 다룬다.
릴레이션 설정은 엔터티와 엔터티 사이에 줄을 그어 연결해 주면 된다. 이때 부모자식 관계인지, 상위하위 관계인지, 식별관계인지, 비식별관계인지에 따라 릴레이션의 방향과 모양이 달라진다.
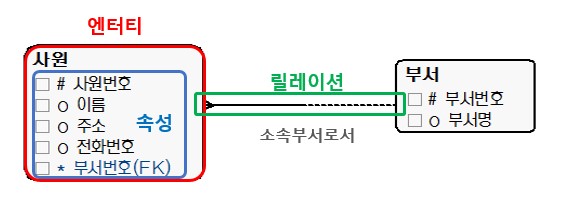
[그림 1] ER 다이어그램으로 본 엔터티와 속성, 릴레이션

[표 1] 엔터티·속성·릴레이션의 관계
앞서 릴레이션은 엔터티와 마찬가지로 집합적 특성을 그대로 갖고 있으며 통합과 분리가 가능하다고 했다. 고등학교때 배웠던 집합의 핵심은 A합집합B, A교집합B, A차집합B 등을 보면 A합집합B는 A집합과 B집합이 합쳐져서 또 다른 집합이 되고, A교집합B는 A집합과 B집합에 공통적으로 있는 요소들이 또 다른 집합이 되고, A차집합 B는 A집합에서 B집합을 빼서 또 다른 집합이 된다는 것이었다. 이와 같이 릴레이션 관계를 갖고 있는 두 엔터티에서 필요한 데이터를 추출할 때 합집합, 교집합, 차집합 개념을 이용해 데이터를 추출함으로써 다른 집합(엔터티)를 만들 수 있게 된다.
릴레이션의 방향은 상위에서 하위로, 부모에서 자식으로 설정하는 것이 일반적이며, 직접적인 관계만 설정한다. 그런데 데이터 모델링에 익숙하지 않을 경우, 릴레이션 방향을 반대로 하거나 간접적인 관계에도 릴레이션을 설정하는 경우가 있다. 이렇게 하는 이유는 아마도 엔터티에 대한 명확한 정의 부족으로 두 엔터티가 어떤 관계인지를 명확하게 구분하지 못함에 따라 발생한다. 또한 간접관계에 릴레이션을 설정하는 경우는 왠지 관계가 있을 것 같다는 생각과 프로그램 개발 시에 더 편리하게 할 수 있을 것이라는 기대 때문으로 보인다.
이제 릴레이션십의 종류와 어떻게 하면 릴레이션을 잘 설정할 수 있는지 좀 더 자세히 알아보자.
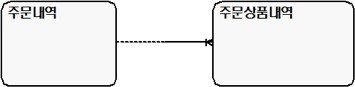
[그림 2] 1:M 관계
온라인 서점에서 책 주문의 예로서 알아보자. 옷이나 화장품 쇼핑몰을 머리 속에 떠올려도 좋다.
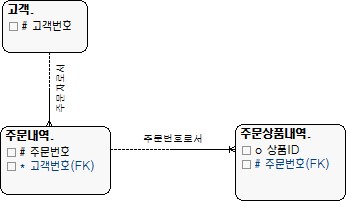
온라인 서점에서 책을 고르고 나면 바로 구매하거나 여러 책을 장바구니에 담았다가 한꺼번에 주문을 한다. 한 권만 주문하면 위 모델에서 ‘주문내역’에 데이터 1건이 쌓이고 ‘주문상품내역’에 책 1권에 대한 정보가 쌓이게 된다. 주문내역과 주문상품내역은 1:1 관계가 형성된다. 여러 책을 한꺼번에 주문하면 주문내역에는 1건의 데이터가 쌓이고 주문상품내역에는 여러 책에 대한 정보가 쌓이게 돼 1:M 관계가 형성된다.
여기서 주문상품내역이 있는데 주문내역이 없는 것은 말이 안 된다는 것을 금방 알 것이다. 따라서 주문내역이 부모가 되고 주문상품내역이 자식이 된다. 부모자식 관계가 된다는 것은 부모 없이는 자식이 존재할 수 없듯이 주문내역 없이는 주문상품내역이 없다는 말이 된다. 바꿔서 말하면 부모 엔터티인 주문내역에 데이터가 쌓이고 자식 엔터티인 주문상품내역에 데이터가 쌓인다는 것을 말한다.
이때 주문내역에서 -> 주문상품내역으로 릴레이션을 설정해 주면 되고, 부모자식 관계이므로 식별관계와?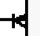 으로 설정해 주면 된다.
으로 설정해 주면 된다.
식별관계란 부모 식별자를 자식이 자신의 식별자로 물려받는 것을 말한다. 자녀가 아버지의 성을 물려받는 것과 비슷하다고 생각하면 된다(ER-Win이나 DA# 등 케이스툴을 이용하면 쉽게 릴레이션을 설정할 수 있다).
이렇게 설정하면, 자식이 부모 식별자를 자신의 식별자로 물려받았으므로 부모 식별자로 연결된다. 이 부모 식별자를 통해 JOIN할 수 있게 된다. SQL에서 쓴다면 다음과 같다. 이때 주무내역과 주문상품내역에 각각 있는 데이터를 JOIN해 함께 조회할 수 있다.

2) 반복 그룹을 제거하는 1:M 릴레이션십
주문에 대하여 [그림 3] 모델처럼 설계하지 않고 주문내역에 주문상품내역을 함께 넣는 형태로 접근했다면 개념적으로 [그림 3]과 같을 것이다.

[그림 3] 주문내역에 주문상품을 함께 관리하는 경우
이런 모델은 주문 상품이 3개 이하인 경우는 아무런 문제가 없지만, 3개가 넘는 경우는 주문상품을 담을 수 없다. 3개 이상의 상품을 담으려면 상품4라는 속성을 늘려줘야 한다. 5개를 주문하고 싶다면 다시 상품 5를 추가하면 된다. 그러나 이렇게 속성을 추가하는 방법은 데이터 모델을 수정해야하기 때문에 좋지 않다.
이것을 해결하는 방법은 주문내역과 주문상품내역으로 엔터티를 분리해 1:M 관계를 만들어 줌으로써 반복을 제거하면서 확장성를 높일 수 있다([그림 4]와 같이 모델을 설계하면 정규화 위반이다. 어느 정규화 위반인지 한 번 생각해 보기 바란다. 정규화는 뒤에 자세히 소개하겠다).
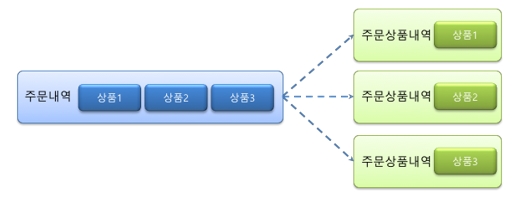
[그림 4] 주문상품을 분리해 관리하는 경우
[그림 5] 부자관계를 통한 직접적인 관계
[그림 6] 직접관계로 구성된 주문 모델

[그림 7] 간접관계 릴레이션십
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (1회) : 헷갈리는 릴레이션십 개념, 제대로 이해하기
노찬형의 제로에서 시작하는 데이터 모델링 시즌II (1회)
헷갈리는 릴레이션십 개념, 제대로 이해하기
| 필자: 노찬형
빅터플랫폼 CIO. 대학에서 소프트웨어공학을 전공했으며 개발자로 사회 생활을 시작했다. 사회 생활 10년을 넘기고 시작했던 DB 공부가 프로그래머로서 자신을 분명하게 되돌아볼 수 있는 기회를 주었다. 사회 초년생 또는 대학생에게 도움이 되는 데이터 모델링 글을 쓰고 싶은 게 그의 작은 바람이다. pemaker@gmail.com |
|
주경야독하는 이들을 위해 우연한 일이 계기가 돼 필자는 DB와 데이터 모델링을 글로 정리할 수밖에 없는 상황에 맞닥뜨렸다. 필자는 2012년부터 2013년까지 한 대학에서 DB 강의를 했다. 강의를 요청받았을 때, 어떻게 해야 할지 난감했다. 필자가 맡은 반은 낮에는 일하고 저녁에 공부하는 학생들로 구성돼 있었다. 일반 대학생들처럼 많은 시간을 공부에 쓸 수 없는 학생들에 DB를 알려줘야 했다. 어떻게 하면 그들에게 작으나마 도움이 될까 하고 고민하던중 시중 교재 대신, 필자가 직접 강의 자료를 만들어 보면 좋겠다는 생각을 하기에 이르렀다.물론 시중의 책이 부족해서 그런 것은 아니다. 필자가 자료를 직접 만들어 쓰면, 일반 책으로 했을 때보다 더 쉽게 소개할 수 있을 것 같아서 그랬다. 누가 보더라도 이해하기 쉽게 전달하겠다는 목표로 강의 자료를 만들기 시작했다. 2년 넘게 강의 자료를 준비하다 보니, DB의 기초와 데이터 모델링의 기초에 대한 내용을 어느 정도 만들어 낼 수 있었다. 학생들이 강의자료를 요청하면 줬다. 하지만 설명이 없는 프레젠테이션 문서라서 아쉬웠다. 설명이 추가되면 학생들이 예습/복습을 할 때도 훨씬 좋을 텐데…. 배웠거나 배울 학생들을 위해 프레젠테이션 문서를 글로 정리하기 시작했다. 말보다 글로 정리하는 게 더 어렵다는 걸 실감하는 순간의 연속이었다. ‘하늘 아래 새로운 건 없다’는 말처럼 필자의 강의 자료 역시 인식하든 못하든 수많은 자료와 가르침을 받았던 결과물들이다. 물론 보고 들었던 이론을 개발 현장에서 적용?확인하는 과정을 거친, 경험의 산물이다. 앞으로 몇 회에 걸쳐 ‘제로에서 시작하는 데이터 모델링’ 연재를 하겠다고 용기를 내보았다. 독자 여러분과 함께 쓴다는 생각으로 수많은 의견이나 접근 방법을 댓글 또는 이메일로 받을 수 있었으면 좋겠다. |
‘제로에서 시작하는 데이터 모델링’ 시즌II는 릴레이션십을 알아보는 것으로부터 시작한다. 엔터티 개념을 이해하기도 어려운데 다시 릴레이션이 등장하니 부담스러울 수 있을 것이다. 하지만 데이터 모델링 분야로 진입을 위해서는 꼭 알고 넘어가야 할 존재이다. 개발 현장에서 릴레이션십을 잘못 이해하고 접근하는 경우를 종종 보곤한다. 릴레이션 방향을 반대로 하거나 간접적인 관계에도 릴레이션을 설정하는 경우가 있다. 개발 시스템의 문제와 성능 저하야기 지점이다.
?
? 릴레이션십이란 무엇인가?
데이터 모델은 비즈니스를 만족하기 위해 많은 엔터티와 엔터티 간 관계로 구성된다. 상품을 구매한 사람이라는 비즈니스 모델은 ‘구매+사람’이라는 집합으로 표현된다. 이렇듯 독립된 엔터티만으로는 비즈니스를 만족하는 전체 집합을 완성할 수 없으므로 엔터티들 간에 관계(relation)를 맺어 관리한다.릴레이션십(relationship)이란 엔터티와 엔터티의 비즈니적 관계를 나타내며, 엔터티 혼자 표현할 수 없는 집합을 다룬다. 따라서 릴레이션십은 집합이며, 합집합·교집합·차집합 등의 특징을 그대로 갖는다. 엔터티와 마찬가지로 통합과 분리가 가능하다.
릴레이션십은 두 엔터티 사이의 직접적인 관계만 정의한다. 따라서 릴레이션은 두 엔터티 간 비즈니스 연관성을 표현하며 name, cardinality, optionality(selectivity)라는 3가지 요소를 이용해 표현된다. 릴레이션십 없이 데이터 모델에서 분리된 엔터티 내의 데이터들은 서로 고립돼 정보로서의 가치를 잃게 된다.
릴레이션은 개발자들이 어떻게 SQL을 작성할지를 결정해 주는 요소이기도 하다. 릴레이션이 잘못되면 SQL 작성이 잘못되며, 그로 인해 시스템 성능 저하와 원하는 데이터 추출이 힘들어질 수 있다.
데이터 모델은 데이터를 중복없이 관리하고 필요할 때 연결해서 보는 것이 핵심이다. 데이터 모델은 비즈니스를 집합으로 보고 엔터티로 표현한 것으로서 엔터티만으로는 전체 집합을 완성할 수 없다.
연결해서 본다는 말은 SQL의 JOIN을 의미하는 것으로, 연결하기 위해서는 엔터티 간의 관계가 있어야 한다. 엔터티가 도출되고 엔터티 간 관계가 도출돼야만 전체 집합을 완성할 수 있다. 릴레이션은 엔터티와 엔터티 간의 비즈니스 관계를 나타내며, 엔터티가 표현할 수 없는 집합을 다룬다.
릴레이션 설정은 엔터티와 엔터티 사이에 줄을 그어 연결해 주면 된다. 이때 부모자식 관계인지, 상위하위 관계인지, 식별관계인지, 비식별관계인지에 따라 릴레이션의 방향과 모양이 달라진다.
[그림 1] ER 다이어그램으로 본 엔터티와 속성, 릴레이션
[표 1] 엔터티·속성·릴레이션의 관계
앞서 릴레이션은 엔터티와 마찬가지로 집합적 특성을 그대로 갖고 있으며 통합과 분리가 가능하다고 했다. 고등학교때 배웠던 집합의 핵심은 A합집합B, A교집합B, A차집합B 등을 보면 A합집합B는 A집합과 B집합이 합쳐져서 또 다른 집합이 되고, A교집합B는 A집합과 B집합에 공통적으로 있는 요소들이 또 다른 집합이 되고, A차집합 B는 A집합에서 B집합을 빼서 또 다른 집합이 된다는 것이었다. 이와 같이 릴레이션 관계를 갖고 있는 두 엔터티에서 필요한 데이터를 추출할 때 합집합, 교집합, 차집합 개념을 이용해 데이터를 추출함으로써 다른 집합(엔터티)를 만들 수 있게 된다.
릴레이션의 방향은 상위에서 하위로, 부모에서 자식으로 설정하는 것이 일반적이며, 직접적인 관계만 설정한다. 그런데 데이터 모델링에 익숙하지 않을 경우, 릴레이션 방향을 반대로 하거나 간접적인 관계에도 릴레이션을 설정하는 경우가 있다. 이렇게 하는 이유는 아마도 엔터티에 대한 명확한 정의 부족으로 두 엔터티가 어떤 관계인지를 명확하게 구분하지 못함에 따라 발생한다. 또한 간접관계에 릴레이션을 설정하는 경우는 왠지 관계가 있을 것 같다는 생각과 프로그램 개발 시에 더 편리하게 할 수 있을 것이라는 기대 때문으로 보인다.
이제 릴레이션십의 종류와 어떻게 하면 릴레이션을 잘 설정할 수 있는지 좀 더 자세히 알아보자.
기본 형태의 릴레이션십
1) 전형적인 1:M 관계/Cardinality[그림 2] 1:M 관계
온라인 서점에서 책 주문의 예로서 알아보자. 옷이나 화장품 쇼핑몰을 머리 속에 떠올려도 좋다.
온라인 서점에서 책을 고르고 나면 바로 구매하거나 여러 책을 장바구니에 담았다가 한꺼번에 주문을 한다. 한 권만 주문하면 위 모델에서 ‘주문내역’에 데이터 1건이 쌓이고 ‘주문상품내역’에 책 1권에 대한 정보가 쌓이게 된다. 주문내역과 주문상품내역은 1:1 관계가 형성된다. 여러 책을 한꺼번에 주문하면 주문내역에는 1건의 데이터가 쌓이고 주문상품내역에는 여러 책에 대한 정보가 쌓이게 돼 1:M 관계가 형성된다.
여기서 주문상품내역이 있는데 주문내역이 없는 것은 말이 안 된다는 것을 금방 알 것이다. 따라서 주문내역이 부모가 되고 주문상품내역이 자식이 된다. 부모자식 관계가 된다는 것은 부모 없이는 자식이 존재할 수 없듯이 주문내역 없이는 주문상품내역이 없다는 말이 된다. 바꿔서 말하면 부모 엔터티인 주문내역에 데이터가 쌓이고 자식 엔터티인 주문상품내역에 데이터가 쌓인다는 것을 말한다.
이때 주문내역에서 -> 주문상품내역으로 릴레이션을 설정해 주면 되고, 부모자식 관계이므로 식별관계와?
으로 설정해 주면 된다.식별관계란 부모 식별자를 자식이 자신의 식별자로 물려받는 것을 말한다. 자녀가 아버지의 성을 물려받는 것과 비슷하다고 생각하면 된다(ER-Win이나 DA# 등 케이스툴을 이용하면 쉽게 릴레이션을 설정할 수 있다).
이렇게 설정하면, 자식이 부모 식별자를 자신의 식별자로 물려받았으므로 부모 식별자로 연결된다. 이 부모 식별자를 통해 JOIN할 수 있게 된다. SQL에서 쓴다면 다음과 같다. 이때 주무내역과 주문상품내역에 각각 있는 데이터를 JOIN해 함께 조회할 수 있다.
2) 반복 그룹을 제거하는 1:M 릴레이션십
주문에 대하여 [그림 3] 모델처럼 설계하지 않고 주문내역에 주문상품내역을 함께 넣는 형태로 접근했다면 개념적으로 [그림 3]과 같을 것이다.
[그림 3] 주문내역에 주문상품을 함께 관리하는 경우
이런 모델은 주문 상품이 3개 이하인 경우는 아무런 문제가 없지만, 3개가 넘는 경우는 주문상품을 담을 수 없다. 3개 이상의 상품을 담으려면 상품4라는 속성을 늘려줘야 한다. 5개를 주문하고 싶다면 다시 상품 5를 추가하면 된다. 그러나 이렇게 속성을 추가하는 방법은 데이터 모델을 수정해야하기 때문에 좋지 않다.
이것을 해결하는 방법은 주문내역과 주문상품내역으로 엔터티를 분리해 1:M 관계를 만들어 줌으로써 반복을 제거하면서 확장성를 높일 수 있다([그림 4]와 같이 모델을 설계하면 정규화 위반이다. 어느 정규화 위반인지 한 번 생각해 보기 바란다. 정규화는 뒤에 자세히 소개하겠다).
[그림 4] 주문상품을 분리해 관리하는 경우
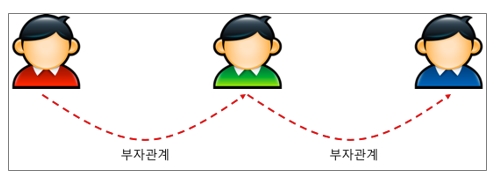
? 직접적인 관계만 설정
직접적인 관계, 다른 말로 하면 직접적으로 관련 있는 2개 엔터티 사이에만 관계를 설정해주어야 하고, 직접 관계를 모두 정의하면 데이터 모델 전체 관계가 완성된다.[그림 5] 부자관계를 통한 직접적인 관계
[그림 6] 직접관계로 구성된 주문 모델
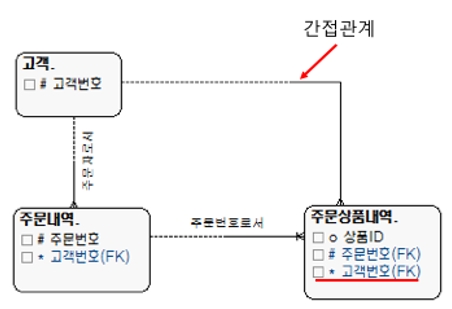
[그림 7] 간접관계 릴레이션십
?
출처 : 한국데이터산업진흥원
제공 : 데이터 전문가 지식포털 데이터온에어(dataonair.or.kr)