
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
딥러닝 방법을 이용한 유방암 메디컬 이미지 분류·예측 모형화 THE CHALLENGES
파일럿 프로젝트를 진행함에 앞서 우리 조는 프로젝트 주제를 도전할 가치가 있고, 사회적으로 기여할 수 있는 것이면 좋겠다는 공통 의견을 모았다. 의료 분야라면 도전적 가치·사회 모두 만족할 것이라 생각해 의료 분야를 큰 주제로 선정했다. 그럼 다양한 의료 분야중 어떤 세부 주제를 선택할 것인가 현대 인 간 삶의 수준이 향상됨에 따라 건강한 삶의 욕구 및 관심도가 증가하고 있다. 하지만 건강에 대한 욕구와 다르게 환경적·유전적 요인 등 다양한 요인에 의해 암 발병률이 높아지고 있는 추세다. THE APPROACH
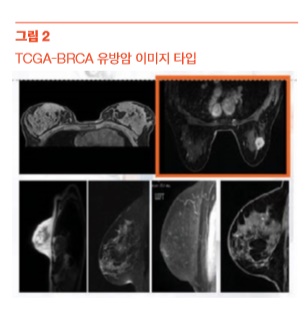
데이터 수집 미국 TCIA 데이터베이스로부터 TCGA(The Cancer Genome Atlas) 유방암 이미지 데이터(BRCA)를 확보 했다. 데이터는 139명 환자의 23만 167개 이미지(용 량 88.58GB)로 MRI, MG(일반 유방암 검사) 검사 이미 지다. 환자별로 수십에서 수백 장까지의 이미지를 갖 도록 구성돼 있다. 유방암 MRI 이미지는 다양한 방 향에서 촬하는데 이번 분석에서는 분석 복잡도 (complexity)를 줄이기 위해 [그림 2]의 박스로 구분 한 이미지만 이용했다. 환자의 모든 이미지를 사용하 지 않고 종양 조직(tumor)이 직관적으로 확인되는 이 미지만 선별했다. 최종 49명 환자에 대한 747개 이미 지를 분석에 이용하기 위해 추출했다. 수집된 데이터는 49명의 유방암 환자 이미지이므로 실제 모형을 평가하기 위해 대조군인 정상인 유방 이 미지가 필요했다. 온/오프라인에서 분석에 이용할 정 상인 유방 MRI 이미지를 구하기 어려워 다음과 같이 한 가지 가정을 했다. ‘한 쪽 유방에만 암 조직이 있다 일단 두 그룹, 즉 암 또는 정상 이미지의 모든 픽셀(pixel) 값 분포를 확인하기 위해 R 패키지를 이용해 상자그림(boxplot)과 도곡선(density curve)을 그려 보았다. 단순히 이미지를 살펴 보면 대부분의 픽셀이 검정색으로, 몇몇 부분에 서 검정과 흰색 사이의 값으로 된 그림이다. 모형을 구축하기 위해 사전에 수집된 1,494 이미지 데이터는 모형을 훈련 시 키기 위한 데이터 1,294개, 모형을 검증할 데이터 200개로 이미지를 구분했 다. 판별모형 구현은 현재 딥러닝 및 AI 분야에서 많이 사용되고 있는 파이썬 기반의 텐서플로(TensorFlow)를 이용했다. 유방암/정상 이미지를 판별하기 위한 판별 모형은 3가지를 적용했다. 크 게 딥러닝 이전에 전통적으로 사용했던 기계학습(machine learning) 방법 인 kNN(k-Nearest Neighbors), RF(Random Forest)과 CDNN(Convolutional Deep Neural Network) 기반의 딥러닝 방법이다. 여기서 딥러닝 방법은 2012 년 구에서 자체 이미지 분류를 위해 구축해 놓은 모형인 Inception V3를 우 리 조의 유방암 이미지를 이용해 다시 훈련시켜 사용했다.
결론적으로 여러 가지 이미지 분류 모형을 이용해 본 결과, 세 가지 모형 중에 서는 CDNN 의 파생형인 Google Inception V3 모형이 (속도 제외) 결과적으 로 가장 좋은 성능을 보여주었다. 그럼 이 Inception v3 모형을 현장에 바로 적용할 수 있을까 어디까지나 수치적으로 76%의 정확도와 87%의 민감도를 얻었을 뿐, 이 모형을 실제 의료 현장에 바로 적용할 수 있을 것이라고는 생각 하지 않는다. 하지만 인간의 건강한 삶을 실현하기 위해서는 정확도는 높으면서 더 저렴 하며 쉽게 조기에 질병을 진단할 수 있는 방법이 필요한 관점에서 가능성을 어 느 정도 보여준 프로젝트라 생각한다. 이러한 시도와 도전 자체가 의미가 있다 고 생각한다. 이번 프로젝트에 수행했던 유방암 이미지 판별 모형은 유방암뿐 아니라 다른 암과 질병으로 확대·적용해 분류할 수 있는 모형이라 생각한다. [분석20기] 딥러닝 방법을 이용한 유방암 메디컬 이미지 분류·예측 모형화
그중 유방암은 전 세계적으로 여성암 1위 를 차지할 정도로 발병률이 높다. 관련 자료를 조사하면서 유방암 의심 환자들 중 실제 암으로 판정받는 비율이 0.6%에 그친다는 신문 기사를 접할 수 있었다. 이렇듯 검사 비용 대 비 판정률이 낮게 나오면서 의료보험 등 사회적 비용이 낭비되는 것은 아닌 가, 실제 검강검진의 목적인 조기진단의 역할을 생각하게 되었다. 우리 조 가 제시하는 모형이 오분류를 낮출 수 있다면, 검진으로 낭비되는 비용을 줄 이고 더 빠르게 유방암을 판별해 조기 치료에 도움이 될 것으로 본다. 문제 는 유방암 데이터 중 어떤 것을 사용할 수 있는지, 실제 데이터를 구할 수 있 는지다.
모든 의료 데이터는 인간 윤리 문제 때문에 심의를 받아야 사용 할 수 있다. 하지만 미국 TCIA(The Cancer Image Archive)에서는 임상정보 를 삭제한 유방암 MRI(magnetic resonance imaging) 및 일반 검사 이미지인 MG(MammoGraphy)를 서비스하고 있어 제약없이 분석에 사용할 수 있었다
우리 조의 프로젝트 목표는 실제 유방암 환자의 MRI 이미지를 이용해 판 별 모형을 만들고 만들어진 모형의 오분류율을 최소화하여 임상의사 또는 건 강검진을 통해 얻은 유방 이미지를 소유한 일반인을 대상으로 유방 MRI 이미 지를 이용해 빠르고 쉽게 암 유무를 판별할 수 있는 판별 모형을 구축하는 것 이다.
데이터 전처리
면 다른 쪽 유방은 정상이다.’
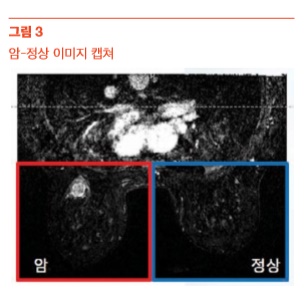
따라서 [그림 3]과 같이 암 환자의 유방 이미지 에서 한 쪽 유방에 종양 조직이 있다면, 종양 조직이 있는 유방을 암-유방, 그 반대쪽 유방을 정상-유방으로 분리하는 작업을 수행했다. 이미지 분리 작업은 R을 이용했다. TCIA에서 제공하는
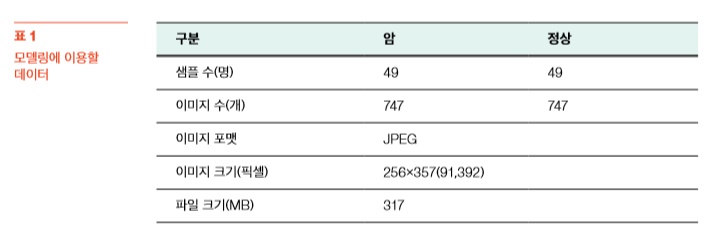
이미지 데이터는 DICOM(Digital Imaging and COmmunications in Medicine) 포맷 파일로 ‘oro. dicom R’ 패키지를 이용해 이미지를 읽어 들이고 필요한 이미지를 부분 캡처 해 JPEG 이미지로 변환·저장했다. 이렇게 모은 데이터는 [표 1] 과 같다
테이터 탐색

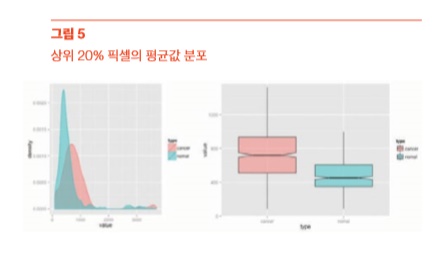
따라서 [그림 4]와 같이 도곡선 이나 상자그림 모두 그룹 간 분포 차이를 가늠하기 힘든, 즉 검정(0)으로 많은 데이터가 치우쳐 있는 형태의 분포를 확인할 수 있다. 하지만 대부분의 종양은 이미지 에서 밝기가 높은 픽셀값을 갖기 때 문에 상위 몇 % 값의 차이를 보는 데 에 의미가 있을 것으로 판단됐다. 이 에 따라 모든 이미지에 대해 상위 20%의 픽셀값만 추출했다. 확보한 이미지 픽셀값 평균을 구해 분포를 살펴 보았다. ggplot2를 이용해 분포를 그 려보니 [그림 5]와 같이 암과 정상 이미지의 상위 20% 픽셀 평균값의 분포에 서 차이가 남을 확인할 수 있었다. T-검정을 이용해 두 그룹간 평균의 차이가 있는지 테스트한 결과 유의확률(p-value)이 1.802e-12로 아주 유의하게 나와 암/정상 간의 상위 20% 픽셀값의 평균은 차이가 있음을 알 수 있었다.
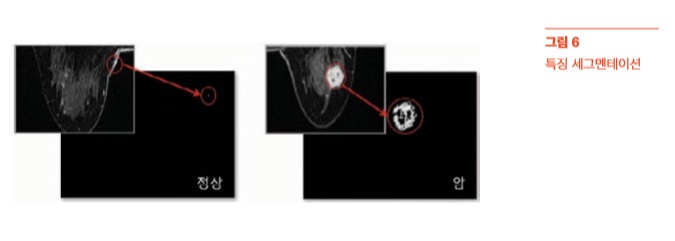
특징 세그멘테이션 그렇다면 실제 픽셀값의 조작으로 암/정상을 구분할 수 있는 특징(종양)을 찾 을 수 있을까 일단 하나의 이미지 샘플만 암/정상을 판별할 수 있는지 테스트 했다. 위 데이터 탐색에서도 설명했듯이 종양의 픽셀값은 다른 조직보다 밝고 여러 개 픽셀이 모여 도가 높기 때문에 픽셀의 밝기 강도만을 이용해 종양 조직을 분할(segmentation)해 보았다. 일단 정상 이미지 픽셀의 최상위 값을 threshold값으로 하고, 암/정상 이미지 모두 threshold값보다 크거나 같은 픽셀값만 그대로 두고 나머지는 검정색으로 바꿔보았다. [그림 6]과 같이 종양 조직 부분만 정확하게 찾을 수 있었다.
유방암 이미지 판별과 평가
첫 번째로 k=3인 kNN을 이용한 분류 결과는 [그림 7]과 같이 실제 암환 자를 암으로 판단한 민감도(Sensitivity)가 100명 중 59명(59%), 정상인을 정 상으로 판단한 특이도(Specificity)가 100명 중 61명(61%)으로 전체 정확도는 60% 정도를 보다. 두 번째인 랜덤포레스트 모형(500번 반복, 100개 트리 생성, 500개 이미지 샘
플링)을 적용한 결과에서는 암환자를 암으로 판단한 민감도가 100명 중 71명 (71%), 정상인을 정상으로 판단한 특이도가 100명 중 42명(42%)으로 전체 정 확도는 56.5%를 보다.
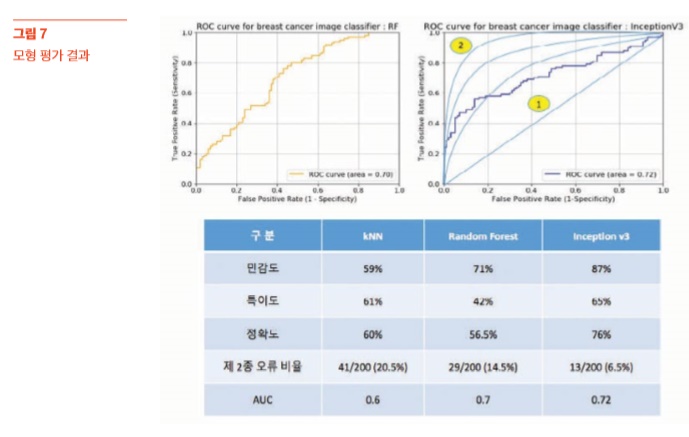
마지막으로 [그림 7]과 같이 딥러닝을 적용한 Inception V3 모형의 예측 결과는 암환자를 암으로 판단한 민감도가 100명 중 87명(87%), 정상인을 정상 으로 판단한 특이도가 100명 중 65명(65%)으로 전체 정확도는 76%를 보다. 의료 데이터에서의 모형 평가를 위해서는 얼마나 암 또는 정상을 정확하 게 분류할 수 있는 정확도가 중요하지만, 제 2종 오류(Type II error), 여기서는 실제 암환자인데 정상으로 판정 받는 경우가 아주 위험(Critical)한 문제가 될 것이다. 따라서 제 2종 오류가 작은 모형이 좋은 모형이라고 볼 수 있다.
[그림 7] 아래의 테이블에서 보는 것과 같이 실제 제 2종 오류도 딥러닝을 이용한 모 형이 다른 2가지 모형보다 2~3배 이상 적게 검출됨을 확인할 수 있었다. 좀 더 시각화 해서 3가지의 모형을 평가해 보기 위해 ROC(Receiver Operating Characteristic) 곡선을 그려 보았다. [그림 7] 위쪽 그래프는 False Positive(제 1종 오류) 비율 대비 True Positive 비율을 그래프로 표현한 것이 다.
그림에서 정상을 암으로 판단하는 비율(Fale Positive Rate)을 0.2로 고정 시켜 보면, 랜덤포레스트는 약 40% 미만의 암환자를 암으로 분류하며, 딥러 닝 방법은 60% 근처로 좀더 높은 비율로 암 이미지를 정확히 판단할 것으로 보인다. 또한 실제 그래프 아래쪽의 면적을 수치로 표현한 AUC(Area Under Curve) 값을 보더라도 딥러닝 방법이 가장 좋은 0.72로 나타나 3개의 모형 중 가장 뛰어난 것으로 나타났다. 분석의 마지막으로 그럼 어떤 이미지들이 잘못 분류(암을 정상으로, 정상을 암으로)가 되었 는지 오분류된 이미지를 살펴보았다.

[그림 8] 의 위쪽 그림과 같이 암환자가 정상으로 분류된 True Positive(제 2종 오류) 이미지를 살펴 보면 유방에 밝기강도(Intensity) 값이 높은 픽셀이 전반적으로 퍼져 있는 형상의 이미지 다. 반 대로 아래쪽 그림에서 정상인이 암으로 분류된 False Positive(제 1종 오류) 이미지를 살펴 보면, 전반적으로 검정색이지만 유독 몇몇 지역에 높은 픽셀값들이 모여 있는 것 을 확인할 수 있다. 결과적으로 암/정상을 구분하는 요인이 밝기 강도가 높은 픽셀값들의 특징 지역 그룹화 여부로 구분하는 것으로 보인다.
THE OUTCOME
물론 이미지를 이용한 질병 판별·예측 분야에도 넘어야 할 장애물이 많다. 예를 들어 의학 이미지에서 실제 비교 대상이 되는 부분(유방, 폐, 위 등) 이외의 다른 장기(Organ) 조직에 대한 처리, 노이즈, 여러 제조사의 의료 기계로부터 생산된 이질적인 이미지 처리 등 데이터의 품질부터 이를 처리할 수 있는 알고 리즘 개발까지 다양한 장애물들이 존재한다. 이러한 부분에 대한 발전이 있다 면 기계학습을 이용한 의료 진단 분야에서 획기적인 발전이 있을 것으로 기대 된다. 마지막으로 우리가 구현한 유방암 이미지 판별 모형을 특정 이미지 형태 만 이용하는 것이 아니라, 일반적인 유방암 이미지 전체를 이용해 재훈련시키 고 모델을 최적화해 정확도를 높이고 오분류율을 낮추어 실제 의료 현장에서 이용될 수 있는 모형으로 발전시켜 나가고 싶다.