
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
빅데이터 분산 스트리밍 플랫폼, Apache Kafka
최근 2년 동안 생성된 데이터가 전 세계 데이터의 80%를 차지한다고 합니다. 급속하게 증가하고 있는 이 많은 데이터 중 80%가 빅데이터 분석이 필요한 비정형 데이터(SNS, IOT, 이미지, 음성, 비디오)라고 예상되고 있습니다. 다른 IT 신기술에 비해 빅데이터는 ‘3V’라는 표현으로 매우 명확하게 정의하고 있습니다. 빅데이터는 데이터의 크기(Volume), 데이터 입출력 속도(Velocity), 데이터 종류의 다양성(Variety)으로 규정되며, 이제는 진실성(Veracity), 시각화(Visualization), 가치(Value)까지 개념이 확장될 만큼 많은 의미를 담고 있습니다. 1. 빅데이터 구현 기술
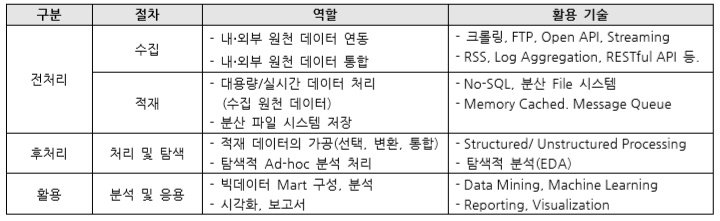
빅데이터 구축 단계는 역할별로 수집, 적재, 처리 및 탐색, 분석 및 응용으로 크게 4단계로 나눌 수 있습니다.
* 수집 구현 기술 2. 분산 스트리밍 플랫폼, Apache Kafka 이해하기
kafka 공식 사이트(kafka.apache.org)의 Introduction에서 Kafka의 정의를 아래와 같이 내리고 있습니다.
대량의 발생·소비 요건이 없고 업무 도메인이 단순한 경우에는 1개의 Broker만 구성하는 아키텍처를 구성할 수 있습니다. 물리적으로 카프카 서버는 1대인데, 업무 도메인이 복잡해서 메시지 처리를 분리 관리해야 하는 경우에는 2개 이상의 Broker를 운영할 수 있지만, 대량 발생·소비 요건에는 사용하기 어렵습니다. 따라서 대규모 발생·소비되는 데이터 처리에 적합하기 위해서는 2대 이상의 카프카 서버로 멀티 Broker를 구성하고 Clustering을 해야 합니다.
기존의 메시징 시스템은 주로 고성능을 위해서 메모리 시스템을 사용하면서 메시지의 영속성을 위해서 성을 사용했지만, kafka는 주 저장소로 파일 시스템을 사용하면서도 기존 메시징 시스템 보다 뛰어나 성능을 보여 주고 있습니다. 이는 하드디스크의 특성을 이용하여 별도의 메모리 캐시를 사용하지 않고, zero-copy를 구현했기 때문일 것입니다. 3. Apache Kafka 설치 및 확인
Kafka는 두 가지 방법으로 설치할 수 있습니다. 먼저 공식 다운로드 사이트에서 압축 파일을 다운로드(2.0.0 release: https://www.apache.org/dyn/closer.cgipath=/kafka/2.0.0/kafka_2.11-2.0.0.tgz) 받아서 설치 프로그램이 아니기 때문에 압축만 해제하면 됩니다. 두 번째로는 Cloudera Manager와 같은 자동화 도구를 통해서 [서비스 추가]로 설치하면 됩니다. 여기서는 첫 번째 방법으로 설치했다고 가정하고 진행하도록 하겠습니다. 4. 맺음말
Kafka를 활용하는 주된 목적은 수집 단계에서 아주 빠르게 발생하는 데이터를 실시간 수집하면서 안정적으로 적재하기 위해 안정적인 버퍼링 처리하기 위해서 입니다. 분산 환경의 대규모 중간 저장소가 완충 역할을 함으로써 안정적으로 수집 아키텍처를 구성할 수 있습니다.
[참고문헌]빅데이터 분산 스트리밍 플랫폼, Apache Kafka
기고자 김우태
연락처 matica5127@naver.com
소속 아이리포기술사회
경력사항 컴퓨터시스템응용기술사, 수석 감리원
ATSC 3.0기반 지상파 UHD방송 시스템 및 콘텐츠 보호시스템 개발/구축
지상파DMB HD-DMB/케이블/IPTV 방송사 CAS솔루션 설계/개발
케이블 방송사 VOD 시스템 개발/구축
Technical Architect
Software Architect
우리는 빅데이터로 무엇을 하고자 합니까 기업 또는 산업분야 마다 그 방향과 적용하는 기술에 차이가 있겠지만 결국 기존 문제점을 개선해 비용을 절감하거나, 새로운 사업모델을 만들어 수익을 창출하고자 하는 것으로 귀결될 수 있을 겁니다. 이번 기고에서는 이 빅데이터의 구현 기술에 대해서 전반적으로 알아 보고, 그 중에서 적재 단계에 많이 활용하는 Kafka에 대해서 이해하는 시간을 가지고자 합니다.
1.1 빅데이터 구축 단계별 역할
1.2 수집 및 적재 구현 기술
빅데이터 수집 기술은 구축하고자 하는 시스템의 내외부에 있는 다양한 원천 데이터를 효과적으로 수집하기 위한 기술이며, 기존의 수집 시스템(EAI, ETL, ESB 등)보다 더 크고 다양한 형식의 데이터를 빠르게 처리해야 하는 능력이 필요하며, 이를 위해 분산 처리가 가능한 구조를 가집니다. 그리고 원천 데이터의 다양한 인터페이스와 연동하여 정형 또는 반/비정형 데이터를 수집합니다. 수집 처리에는 배치성 데이터와 실시간 스트림 데이터로 구분할 수 있으며, 이 중에서 실시간 데이터의 경우, CEP(Complex Event Processing), ESP(Event Stream Processing)기술을 적용하여 실시간으로 이벤트를 감지해 빠른 후속 처리를 수행할 수 있습니다. 필요에 따라서 수집 데이터 품질 향상을 위해 정제, 변환, 필터링이 수반될 수도 있습니다.
* 적재 구현 기술
빅데이터 적재 기술은 수집된 데이터를 분산 스토리지에 영구적으로나, In Memory 형태의 임시로 적재하는 기술이며, 대용량 파일 전체를 영구적으로 저장하는 HDFS, 메시징 데이터 전체를 영구 저장하기 위한 NoSQL, 메시징 데이터를 임시 저장하기 위한 InMemory 캐시, 메시징 데이터 전체를 버퍼링 처리하기 위한 Message Oriented Middleware(Kafka)로 나눌 수 있습니다. 4가지 유형으로 구분된 적재 기술을 구축하고자 하는 시스템에 적합하게 아키텍처를 구성하면 되는데, 예를 들어 실시간 및 대량으로 발생하는 작은 메시지 데이터를 HDFS에 저장하는 경우에는 파일만 많아지고, 저장소 효율이 크게 떨어질 수 있습니다. 그래서 NoSQL, InMemory 캐시, MOM등을 선택적으로 추가 구성하여야 합니다.
Kafka는 수집 단계의 backend와 적재 단계의 frontend의 중간에서 비동기식 방식으로 버퍼링 처리를 해주어 시스템의 안정성을 확보해 줍니다.
2.1 Apache Kafka 란
Apache Kafka? is a distributed streaming platform.
그러면서 streaming platform에 대해서 Three key Capabilities가 있다고 설명하고 있습니다.
- message queue 또는 enterprise messaging system과 유사하게 레코드 스트림을 게시하고 구독(Publish)한다.
- fault-tolerant이 강한 방식(durable way)으로 레코드 스트림을 저장한다
- 발생하는 만큼 레코드 스트림을 처리한다.
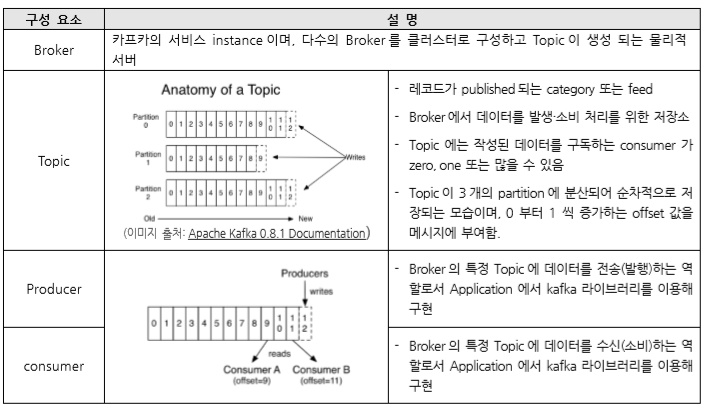
Kafka는 일반적으로 시스템 또는 응용 프로그램간의 데이터를 안정적으로 얻을 수 있는 실시간 스트리밍 데이터 파이프 라인 구축 및 데이터 스트림의 react나 이에 반응하는 real-time streaming application 구축에 주로 활용됩니다. 따라서, Kafka는 여러 데이터 센터로 확장 될 수 있는 하나 이상의 서버에서 클러스터로 실행됩니다. 그 클러스터는 Topic이라는 카테고리에 Record 스크림을 저장하는데, Record는 key, a value, timestamp로 구성됩니다.
2.2 broker에서의 Partition
Topic은 partition이라는 단위로 쪼개어져 cluster의 각 서버들에 분산되어 저장되고, 가용성을 높이기 위해 복제(replication) 설정을 할 경우, 이 또한 partition 단위로 각 서버들에 분산되어 복제되고 장애가 발생하면 partition단위로 fail over가 수행 됩니다.
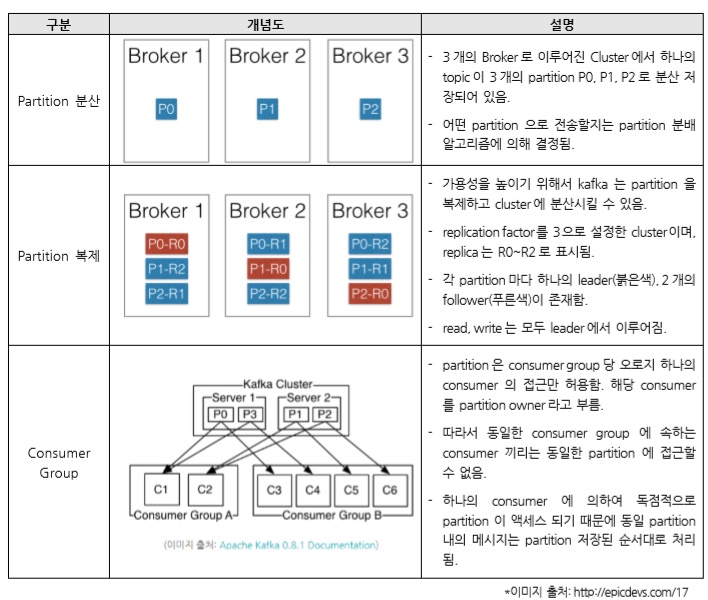
다른 partition에 속한 메시지의 순차적 처리는 보장되어 있지 않기 때문에, 발생 시간 순으로 처리하고 싶으면 topic을 하나의 partition만을 가지도록 설정해야 합니다.
V2.3 kafka의 파일 시스템 활용

(이미지 출처: https://queue.acm.org/detail.cfmid=1563874 )
일반적으로 하드디스크는 메모리보다 많이 느리지만, 특정 조건에서는 10배 이내로 느리거나 심지어는 빠를 수도 있습니다. ACM Queue에 게재된 The Pathologies of Big Data라는 글에 따르면 Sequential, HDD는 Random, memory보다 빠르며, Sequential, memory보다는 7배 정도 느리다고 합니다.
kafka는 이를 적극적으로 활용해서 하드디스크의 성능 단점을 보완했으며, 동시에 메모리에 별도의 캐시를 구현하지 않고 OS 페이지 캐시를 효과적으로 활용해서 JVM 객체로 변환되면서 크기가 커지는 것을 방지할 수 있고 GC로 인한 성능 저하 또한 피할 수 있었습니다. 그리고 마지막으로 파일 시스템에서 저장된 메시지를 N/W를 통해 consumer에게 전송할 때 zero-copy 기법을 사용하여 데이터 전송 성능을 향상시킬 수 있었습니다.
(zero-copy 기법 참고 URL: https://www.ibm.com/developerworks/linux/library/j-zerocopy/ )
* 서버 시작
- kafka는 Zookeeper에 매우 의존적으로 동작하기 때문에 Zookeeper 서버가 없는 경우 먼저 Zookeeper 서버를 시작해야 합니다. Kafka와 함께 패키지 된 편리한 스크립트를 사용하면 쉽게 실행 시킬 수 있습니다.
- Zookeeper 시작: bin/zookeeper-server-start.sh config/zookeeper.properties
- kafka 시작: bin/kafka-server-start.sh config/server.properties
* topic create
- 단일 partition과 하나의 replication으로 “test” 주제로 만듦.

- list topic 명령을 실행하면 해당 topic이 생성된 것을 확인할 수 있음.

* 메시지 보내고 받기
- producer console client을 실행해서 console level에서 메시지를 입력해 보고, consumer console client를 통해서 해당 메시지를 수신(소비)할 수 있어서, 정상적으로 kafka가 설치 및 동작하는 것을 확인할 수 있습니다.

? terminal을 새로 열어서 producer console client을 실행하고 추가적으로 terminal을 하나 더 열어서 consumer console client을 아래와 같은 명령으로 실행합니다.

? producer console client에서 단어를 입력하고 엔터 키를 누르면, consumer console client에 메시지가 성공적을 전송되는 것을 확인할 수 있습니다.
만약 kafka와 같은 중간 저장소가 없이 바로 수집된 데이터가 No-SQL이나 HDFS에 적재되는 아키텍처라면, 적재 단계의 장애가 발생하면 전송하지 못한 데이터가 수집 단계에서 쌓이면서 연쇄적으로 수집 단계의 장애로도 이어질 것입니다. 따라서 빅데이터 아키텍처를 구성할 때에는 꼭, 중간 저장소이며 대규모 분산 환경을 구성하는 기술이 필요합니다. 추가적으로 kafka는 비동기식 방식을 택하고 있기 때문에 수집 속도 향상에도 장점이 있습니다.
실무로 배우는 빅데이터 기술, 위키북스
[참고사이트]
http://kafka.apache.org/documentation/#topicconfigs
http://epicdevs.com/17