
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
실시간 분산 처리, Apache Storm Topology 구현하기 기고자 김우태 1. 빅데이터 실시간 적재 활용 기술 여러 단계를 거치거나, 여러 모양의 빅데이터가 수집되면 다음 단계로 적재를 하게 되는데, 먼저 대용량 배치성 데이터(로그 파일) 적재의 경우에는 수집한 파일을 하둡에 적재한 후, 장시간을 활용해서 대용량 배치성 작업등으로 가치 있는 정보들을 찾아 내는데(Mining) 주력하며, 실시간성의 메시지 데이터는 적재하기 직전에 실시간 분석(집계, 분류, 관계화)을 수행해 그 결과를 인메모리 구조로 전달하여 기존의 legacy 시스템이나 비즈니스 시스템에 실시간 공유되어 활용도를 극대화할 수 있어야 합니다. * HBase 2. 실시간분산처리, Apache Storm 이해하기 Storm 공식 사이트(storm.apache.org)의 Home page에서 왜 Storm을 사용해야 하는지에 대해서 아래 그림과 함께 기술되어 있습니다. 3. Apache Storm Topology 구현하기 4. 맺음말실시간 분산 처리, Apache Storm Topology 구현하기
소속 아이리포기술사회
경력사항
컴퓨터시스템응용기술사, 수석감리원, 정보보안기사
ATSC 3.0기반 지상파 UHD방송 시스템 및 콘텐츠 보호시스템 개발/구축
지상파DMB HD-DMB/케이블/IPTV 방송사 CAS솔루션 설계/개발
케이블 방송사 VOD 시스템 개발/구축
Technical Architect
Software Architect
빅데이터 시스템 구축은 일반적으로 수집 > 적재 > 탐색(처리) > 분석(응용) 단계로 이루어지며, 이중 수집 단계가 전체 공정 과정에의 절반에 가까운 부분을 차지한다고 할 수 있습니다. 빅데이터 수집은 일반적인 수집과는 다르게 수집 영역이 조직내의 전체 시스템에서부터 외부 시스템(SNS, 포털, 공공 데이터 등)에 이르기까지 매우 광범위하고 다양하다고 할 수 있습니다. 수집 대상을 선정하고 계획을 수립해서 수집을 실행하면, 수많은 실시간 데이터가 유입되게 될 것이며, 이 데이터를 다음 단계로써 적재하게 됩니다.
적재는 크게 대용량의 배치성 데이터와 실시간성의 메시지 데이터로 구분할 수 있으며, 이번 기고에서는 실시간으로 발생하는 대규모 실시간 메시지 데이터를 Storm에 의해 실시간 분산 처리를 가능하게 하여, 영구적으로 저장하기 위해 효율성이 떨어지는 하둡보다는 NoSQL 데이터베이스인 HBase을 활용할 수 있도록 Storm Topology을 구현하는 시간을 가지고자 합니다.
1.1 빅데이터 실시간 적재 개요
1.2 빅데이터 실시간 적재 활용 기술
NoSQL 데이터베이스(File 기반)를 대표하여 HBase를 간단하게 설명 드리면, 하둡 기반의 Column-Oriented 지향 NoSQL 데이터베이스이며, 데이터를 Key/value 형식으로 단순하게 구조화하는 대신 고성능의 쓰기/읽기가 가능하도록 만들었습니다.
쓰기 성능에 좀 더 최적화돼 있으며, 대용량 처리가 필요한 대규모 시스템에 활용이 많이 되며, 가장 큰 특징으로는 하둡의 HDFS를 기반으로 설치 및 구성된다는 것입니다. 간단히 아키텍처를 설명하면 Client가 Zookeeper를 통해 HTable의 기본 정보와 해당 HRegion의 위치 정보를 알아와서, 그 정보를 기반으로 직접 HRegionServer에 접속해서 HRegion의 MemStore(메모리 영역)에 데이터를 저장하고 임계치에 다다르면 해당 데이터가 HFile로 Flush되고, HFile 또한 특정 임계치가 되면 하둡의 HDFS로 데이터를 Flush합니다. 이 과정을 Major/Minor Compaction이라고 합니다.
* Redis
NoSQL 데이터베이스(In-Memory기반)를 대표하여 Redis를 간단하게 설명 드리면, 분산 캐시 시스템이면서 Key/value 형식의 데이터 구조를 분산 서버상의 메모리에 저장하면서 고성능의 응답 속도를 보장합니다. 다양한 데이터 타입을 지원하기 때문에 데이터를 구조화해서 저장할 수 있어 단순 Key/value 이상의 데이터 복잡성도 처리할 수 있는 아키텍처를 가지고 있으며, 스냅샷 기능, 데이터 유실에 대비한 AOF(Append Only File) 기능, 데이터 Sharding, Replication도 지원하고 있어 높은 성능이 필요한 서비스에 주로 사용되고 있습니다.
Redis 3.x부터는 Sentinel이라는 노드 모니터링/제어 컴포넌트가 추가되어, Master 노드에 문제가 발생하면 Slave 노드 중 하나를 Master노드로 지정하고, 문제가 됐던 Master 노드와 연결을 끊으면서 HA기능을 제공합니다.
* Esper
실시간 스트리밍 데이터의 복잡한 이벤트 처리가 필요할 때 사용하는 롤 엔진 즉, CEP 엔진이라고 할 수 있습니다. 다양한 조건과 복합적인 이벤트를 하나의 룰로 정의할 수 있어 CEP를 처리하고 룰을 관리하는 것이 손쉽다고 할 수 있는 자바 라이브러리 프로그램이기 때문에 어플리케이션 응용 프로그램에 설치해서 프로그래밍이 가능합니다.
단, Esper는 GPL 2.0 라이선스를 채택하고 있어서, 주의하여 사용하여야 합니다.
(실시간으로 발생하는 데이터 간의 관계를 복합적으로 판단하고 처리하는 기술을 CEP(Complex Event Processing)라고 함.)
* Elasticsearch
실시간 검색을 제공하는 검색 엔진이며, 강력한 집계 기능도 제공해 실시간 분석 엔진으로 활용도 가능하며, 데이터를 저장할 수 있어 NoSQL 데이터베이스로도 활용할 수 있습니다. 응용 프로그램 인터페이스 CRUD REST API를 통한 데이터 추가, 업데이트, 검색 및 삭제가 가능합니다. ‘키바나(Kibana)’를 통해 데이터를 가져와서 키바나 쿼리를 이용해서 원하는 데이터를 화면에 시각화가 가능합니다.
2.1 Apache Storm 이란

Legacy 시스템이나 수집 단계에서부터 데이터가 끊이지 않고 매우 빠른 속도로 유입되는 스피드 데이터는 워낙 양도 많고 빠르게 발생하다 보니 대규모 병렬 처리를 이용해 실시간 데이터를 프로세싱(분리, 정제, 조합, 카운팅)할 수 있는 S/W가 필요해졌고 이를 해결하기 위해 개발된 것이 Storm이라고 할 수 있습니다.
Storm 은 데이터를 적재하기도 전에 발생과 동시에 이벤트를 감지해서 처리하는 방식으로 실시간 데이터를 분산 처리합니다.
2.2 Storm 아키텍처
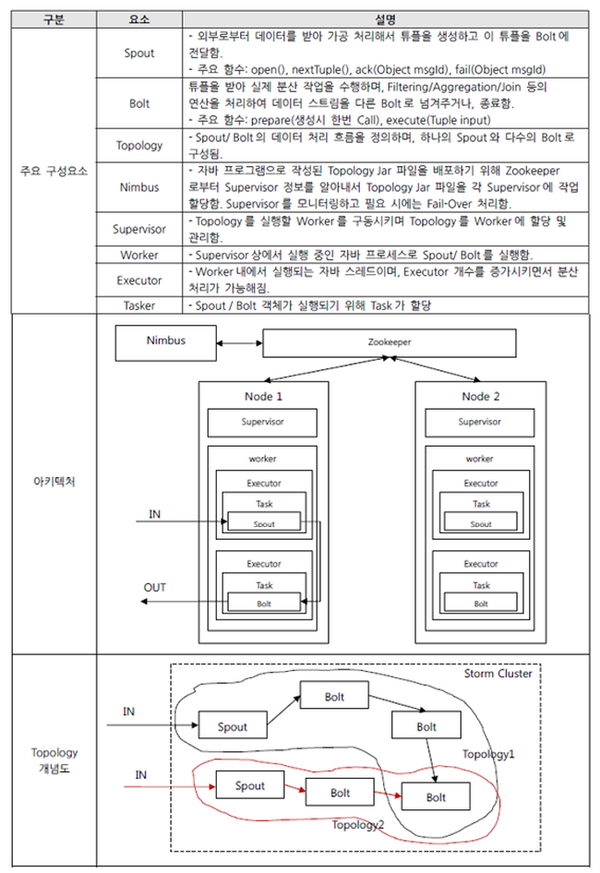
- Storm은 매우 견고한 장애 복구 기능을 제공하고 있는데, Worker 프로세스가 특정 원인에 의해서 장애가 발생해서 종료되는 경우, Supervisor는 새로운 Worker 프로세스를 다시 생성해서 복구합니다. 처리 중이던 Tuple은 rollback되고 Topology가 다시 정상적으로 복구되면 rollback 시점부터 Spout이 다시 처리하면서 데이터 정합성을 보장해 줍니다.
먼저 Zookeeper에 의존적으로 동작하는 Kafka에 Topic을 생성하여야 하며, 해당 Topic이 Zookeeper의 Znode에 등록되어 있어야 합니다. 이 정보를 가지고 Storm Topology에서 kafkaSpout를 설정 등록하여야지만, 데이터 유입이 가능해집니다.
* Apache Storm Topology 시작하기
- Storm Topology는 최종적으로 Java Jar파일로 등록되기 때문에 Eclipse 에서 Maven Project로 구성하면 되며, 필요한 Library는 pom파일에 등록해서 repository 에 다운로드 받아서 작성하면 됩니다.
- 단, 참조된 Library는 차후에 Storm Topology가 구동되는 서버에도 동일하게 라이브러리로 등록되어 있어야 Storm이 동작합니다.
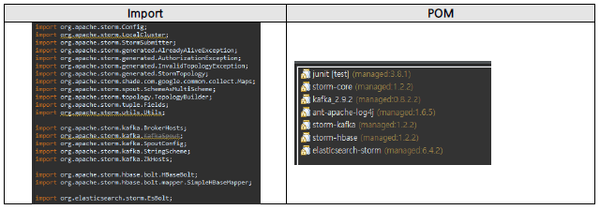
- 위는 Apache Storm Topology를 구현하면서 참조된 Package와 Library에 대한 정보입니다.
? Apache Storm Topology: main 함수
- main 함수는 먼저 각종 Configuration을 등록하는 것에서 시작됩니다.
- 이후 makeTopology 함수에서 Spout, Bolt을 정의하고 연동하는 작업을 합니다.

? Apache Storm Topology: makeTopology 함수
- Spout와 Bolt간의 연관 관계를 정의해서 데이터 흐름을 정의하는 역할을 구현합니다. 데이터가 어디로 들어와서 어디로 나가는지를 정의하는 것인데, 여기서는 Kafka에서 들어온 데이터를 Hbase와 elasticsearch로 나가도록 정의합니다.

- Hbase Table 생성 command 명령어: hbase org.apache.hadoop.hbase.util.RegionSplitter ChannelReportInfo HexStringSplit -c 3 -f cri
- elasticsearch index생성 Command 명령어: curl -XPUT 'http://am4.dta.digicap:9200/channel_reportpretty'
- 간단하게 Storm Topology 구현하는 것을 예제를 통해서 알아봤습니다. 추가적으로 Topology를 생성할 때, Topology에 상세 Worker, Executor, Task의 수를 정의할 수 있으며, conf/storm.yaml에 정의된 설정에 따라서 Worker프로세스가 실행됩니다.
- 그리고 Storm또한 Kafka와 같이 Zookeeper에 의존도가 높다고 할 수 있습니다. Znode인 /Storm의 위치에 주요 설정값이 관리되고 있기 때문입니다.
적재된 데이터를 이해하기 위해서 패턴, 관계, 트렌드 등을 찾게 되는 탐색적 분석(EDA, Exploratory Data Analysis)을 통하고, 기계학습에 의해Prediction과 비즈니스 가치의 창출이 가능해 질 것입니다.
따라서 4차 산업 혁명 시대의 밑거름이 될 수 있는 빅데이터의 활용 방안을 다양한 분야에서 적극적으로 모색하여야 하며, 국가적인 정책 또한 세밀하게 마련되어야 할 것입니다.
[참고문헌]
실무로 배우는 빅데이터 기술, 위키북스
[참고사이트]
http://storm.apache.org/index.html
http://bcho.tistory.com/995category=563141