
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
대중적인 주제에 대한 창의적 생각이 데이터 분석의 시작이자 끝! 수요자 성향에 맞춘 어린이집 확대 방안 저출산 문제와 더불어 맞벌이 부부들의 증가로 육아 부담이 증가하고 있는 가운데 보육환경에 대한 신뢰성을 의심하게 만드는 사건사고가 잇달아 터지고 있다. 분석전문가 과정 13기 2조는 이 런 현실에 착안해 실생활과 밀접하게 연관된 육아·보육 문제의 해결책 찾기에 나섰다. 프로젝트 주제는 ‘수요자 성향을 반영한 어린이집 확대 방안’으로 정했다. 지역별 수요자 요구에 맞는 보 육환경 정보 제공에서 한발 더 나아가 보육환경 개선을 위한 정책에 반영할 수 있는 데이터 분석 모델을 제안하기 위해서다. The Challenges 집체 교육 첫날부터 조별 프로젝트 주제를 선정하는 미션이 주어졌고, 우리 조는 점심시간 및 자투리 시간 등을 활용해 프 로젝트 주제를 정하기 위해 수시로 미팅을 가졌다. 여러 주제 중 실질적이고 유의미한 데이터 확보가 가능한 ‘사용자 패턴 에 따른 펜션 추천’이라는 주제를 선정했다. 그런데 데이터 확보를 위해 해당 회사의 동의를 얻는 과정에서 개인정보 및 보 안상의 이유로 거부를 당했다. 해당 주제에 대한 미련과 새로운 주제를 결정하기 위해 고민하고 망설이는 사이 주어진 시 간이 흘러갔고, 다시 새로운 주제 찾기를 위한 미팅을 진행하면서 분석할 수 있는 데이터의 확보 및 분석결과 활용이 중요 하다는 것을 깨닫게 되었다. 우리는 사회적으로도 이슈인 맞벌이 가족, 한부모 가족 등 가족구조의 변화와 저출산 문제에 대해 조심스럽게 접근을 시 도했다. ‘저출산 문제’를 해결하기 위한 설문조사에서 아이를 더 나을 수 있는 환경 조성에 대한 분석 결과 ‘가족돌봄 서비 스 확대’와 ‘보육환경’ 부분이 50% 정도라는 것에 주목했다. 우리는 육아휴직을 보장하는 것 역시 부모가 직접 양육하는 보육환경을 조성하는 것이라고 생각했다. The Approach 주제가 정해지자 어떠한 데이터가 필요할까라는 고민으로 이 어졌고 바로 데이터 수집을 시작했다. 데이터를 이해하기 위해서는 반드시 필요한 일이 바로 탐색 적 자료분석(EDA)이다. 그런데 이 작업이 만만치 않다. 노동 집약적인 일인데 막일보다 힘들다. 무지막지한 양의 결과를 검토하고 확인하는 작업을 해야 한다. 분석기법을 적용하기 전부터 적용하는 과정에서, 그리고 적용 이후에도 EDA 작업을 계속 해야 한다. 그런데 각 과정마다 EDA 작업 내용은 약 간씩 차이가 있다. 분석 전에는 데이터 의미를 파악하기 위한 과정이라면, 분석 후에는 분석결과의 의미를 확인하고 검증 하는 작업을 해야 한다. 우리는 수집된 데이터를 활용한 EDA를 통해 총 16개의 파생변수를 만들었다. 다음에는 랜덤 포레스트 분석을 이용해서 중요변수가 무엇인지 식별해 보고자 했다. 열심히 변수를 넣고 실행 하니 생각하지 못한 에러가 발생했다. 결측치가 있으면 안된다는 것이었다. 그래서 결측치를 제거하고 다시 실 행했다. 이번에는 factor형 변수의 유일한 값의 수가 53 개 이상이면 안된다는 에러가 나왔다. ‘시도별 시군구 명’ 변수가 259개의 유일한 값이어서 문제가 된 것이었 다. 이번에는 ‘시도별 시군구명’ 변수를 제외시키고 다 시 실행했다. 이번에는 메모리가 부족하다는 에러가 발 생했다. 이처럼 R은 메모리를 사용해 작업을 하기 때문 에 메모리 용량이 초과되면 에러가 발생한다. 서울시에 위치한 구별로 어린이집을 인증평가점수로 평가하고자, 유사한 성질끼리 서로 묶이는 군집분석을 수행했다. 군 집 분석 결과 클러스터 1은 6개의 종합 평균점수 순위에서 하위에 해당되고, 클러스터 2는 종합평가점수 순위에서 상위에 해당됐다. 분석결과가 도출되기 전에는 총 평균과 상관없이 6개의 인증평가 중 같이 높은 그룹끼리 묶일 것이라 예상했지 만 실제로는 종합 평균 점수와 거의 비슷하게 클러스터링 됐다 연관성 분석하면 흔히 장바구니 분석을 생각한다. 연관성 분석의 예로 전형적으로 널리 사용되는 것이 장바구니 분석이 기 때문에 그렇게 생각하는 것이다. 연관성 분석은 주어진 아이템들의 집합에서 어떤 아이템(들)이 나타날지를 다른 아이 템(들)의 발생으로부터 예측하는 규칙을 찾는 작업이다. 쉽게 이야기 하자면 어떤 아이템(들)이 발생한다는 조건에서 다른 아이템(들)이 나타날 확률을 계산해 일정 수준 이상의 확률인 것들만 찾아내는 것이다. The Outcome 인증평가점수를 사용한 군집분석과 주성분 분석의 결과에 따르면 보호자가 선호하는 어린이집은 보육환경과 상호작용 및 교습법 요소가 가장 중요하게 나왔으며, 이 분석의 결과를 토대로 부족한 인증평가 점수를 더 향상시켜서 보육의 질을 향 상시킬 수 있을 것으로 기대된다. 조건부 확률로 의미있는 정보를 찾는 연관성 분석의 결과를 보면 각 지역별 수요자들이 선호하거나 필요로 하는 어린이집 유형 및 보육서비스가 다르다는 결과가 나왔고, 현재의 어린이집 공급 상황에 비추어 본다면 어떠한 어린이집이 더 필요한지를 알 수 있었다. 흔히 데이터 분석이라고 하면 도깨비 방망이처럼 짧은 시간에 원하는 목표 대로 결과가 나올 수 있다고 생각할 지 모르겠 다. 그러나 막상 프로젝트를 진행해보니 데이터 분석은 결코 쉬운 일이 아니었다. 주제를 정하고 처음 시작할 때는 수요자 중심의 맞춤형 어린이집 추천 정보를 제공할 수 있는 분석 결과를 기대했지만 실제 결과는 아니었다. 목표를 달성하기 위 해서는 더 많은 시간이 필요했고, 더 많은 데이터를 수집해야 했다. 아쉬움 속에서도 다행인 것은 분석과정에서 여러 가지 다양한 분석을 시도했고 그 중에 의미있는 정보들이 부산물처럼 나왔다는 것이다. 그 의미있는 정보를 더 깊이 분석하고 결과를 정리하면서 뿌듯함을 느끼기도 했다.[분석13기] 수요자 성향에 맞춘 어린이집 확대 방안
주제 선정의 요건 ‘데이터 확보 가능성’ ‘대중적인 관심’
새로운 주제 중 2가지가 최종적으로 남았고 이번에는 두 주제에 대해 데이터 확보 가능성을 먼저 확인하기로 했다. 이 확 인 과정은 집체교육 마지막 날까지 계속돼 초조함이 더해갔다. 2주간의 집체 교육 과정이 끝나고 각자 주제를 고민한 후 가진 프로젝트 첫 정기모임에서 주제를 선정할 수 있었다. 데이터 확보가 용이한 공공데이터를 활용할 수 있는 조달청 관 련 주제와 보육정보 관련 두 가지 주제 중 조원 모두가 공감해 선정한 주제는 육아와 보육환경과 관련된 것이었다. 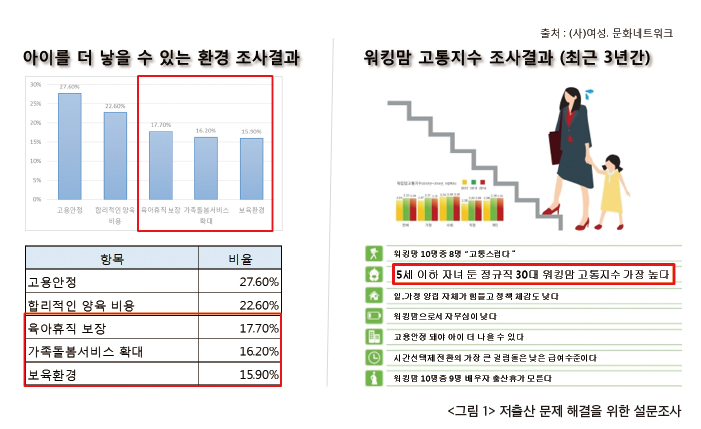
내 아이를 안심하고 맡길 수 있는 어린이집 찾기
조금 더 세부적인 조사 결과도 있었다. ‘맞벌이 부부 중 워킹맘의 고통지수’라는 설문조사에서는 ‘5세 이하 자녀를 둔 정규 직 30대 워킹맘의 고통지수가 가장 높다’라는 응답에 집중했다. 30대 정규직 워킹맘들의 고통지수가 높은 이유는 무엇일 까 원인은 자녀양육에 대한 부담으로 함축됐다. 실제로 출산율 저하의 원인 중 하나가 맞벌이 부부들이 안심하고 신뢰할 수 있는 자녀양육 기관을 찾기가 쉽지 않고, 거기에 따른 부담도 매우 크다는 것이었다. 정부에서도 보육환경 개선을 위해 다각적으로 노력하고 있지만, 짧은 시간에 문제를 해결하는 것은 쉽지 않아 보였다.
대한민국에서 영유아 자녀를 둔 부모라면 자녀 양육에 대해 고민하지 않을 사람은 없을 것이다. 우리 조원 중에도 한 명 을 제외한 모두가 영유아를 둔 부모이거나 그런 경험을 가진 부모이며, 결혼을 앞두고 있는 한 명의 조원 역시 이런 고민을 느끼고 있었다. 영유아 자녀를 둔 부모에게 그들이 필요로 하는 어린이집을 추천할 수 있는 정보를 제공하는 분석시스템 을 만들면 좋겠다는 공감대가 형성되면서 프로젝트 주제에 대한 접근방법이 더 명확해졌다. 시간에 쫓기면서 분석 주제를 확정했지만 조금이라도 시간을 벌기 위해 분석 플랫폼의 구성을 병행했다. 분석 플랫폼으로 CentOS에 파이썬과 R 서버, MySQL을 설치했고, 파이썬을 이용한 크롤링으로 데이터를 수집해 MySQL에 저장하고, 저장된 데이터를 이용해 분석하 기로 했다.
의미있는 자료 찾아 ‘삼만리’
먼저, 공공자료 활용을 위한 공공데이터포털(https://www. data.go.kr)에서 제공하는 정보를 검색하고, 어린이집 정보 공 개 포털(http://info.childcare.go.kr/)에서 제공하는 오픈 API 정보를 확보했다. 여기서 ‘시군구정보 조회’, ‘전국 어린이집 정 보 조회’를 통해 데이터를 확보했지만 의미있는 분석을 위해서 는 추가의 데이터가 더 필요하다는 것도 알게 됐다.
위의 공식적인 정보 외에 영유아 부모들의 실제적인 소리를 모 아보자는 한 조원의 제안에 따라 SNS, 블로그, 커뮤니티 등의 소셜 데이터를 찾아 샘플 분석을 시도했다. 그런데 지역별 동일 이름의 어린이집에 대한 처리 문제와 수 많은 페이지로부터 정 보를 가져오는데 소요되는 작업시간이 많다는 현실적인 문제에 직면하게 됐다.
프로젝트에 주어진 시간은 한정돼 있고 직장인이기에 시간을 마음껏 낼 수 없다는 점, 조원들의 현실적인 상황을 고려하면서 도 최고의 산출물을 제출할 수 있을까 천신만고 끝에 자료를 확보한다고 해도 여기에서 의미있는 정보를 찾을 수 있을까 고민을 거듭하던 중 한 조원이 해결책을 들고 왔다. 어린이집 정보 공개 포털(http://info.childcare.go.kr/)의 정보공시 메뉴 에서 제공하는 ‘우리 어린이집 찾기’ 화면에서 어린이집 운영현 황 정보를 파악할 수 있다는 것이다.
놀랍게도 이 사이트에는 어린이집에 대한 정보공시 데이터와 평가인증정보 데이터가 있었고, 이 공공데이터를 잘 활용해 구 축하면 의미있는 자료가 될 수도 있다는 생각이 들었다. ‘실낱같 은 희망’이 생긴 것이다.
웹사이트상에 있는 데이터를 가져오기 위해서는 크롤링을 해야 한다. 이번 교육과정에서 파이썬을 이용한 크롤링을 배우기는 했지만 이 방법을 적용하기는 쉽지 않았다.
그래서 우선 자바로 크롤링한 경험이 있는 조원이 자바로 데 이터를 수집해서 분석에 들어가고, R을 이용한 크롤링을 재 시도 했다. 크롤링을 하기 위해 ‘RHTMLForms’, ‘XML’ 두 가 지의 패키지를 사용했다. 관련된 자료를 찾아서 공부하고 실 제 크롤링을 위해 코드를 만들고 노력하는 과정에서 R의 방 대한 활용성과 유용함을 느끼게 됐다. 결국 크롤링을 통한 데이터 구축은 성공적으로 끝났다.
우리는 ‘우리 어린이집 찾기’의 정보공시 자료와 평가인증점 수 자료를 수집해 총 20여 개의 변수를 생성할 수 있었다. 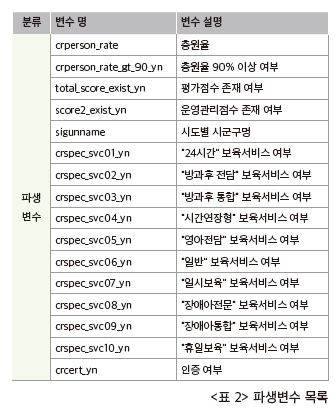
노동집약적인 작업 ‘EDA’에 빠지다
첫번째로 만든 것은 충원율 관련 파생변수였다.
‘충원율’ 파생 변수는 정원 중 얼마만큼 원아가 모집됐는지를 비율로 표현하는 파생변수로, ‘현원/정원’의 비율값이다. 다시 충원율이라는 변수를 이용해 ‘충원율 90% 이상 여부’ 파생변수를 만들었다. ‘충원율 90% 이상 여부’ 파생변수는 정 원이 거의 찬 것으로 판단하는 정보로, 충원율 90% 이상이면 True로 표시된다. ‘정원’ 기본변수의 데이터 분포를 보면 75% 이상이 50명 미만이며, 50% 이상이 20명 이하이다. 그러므로 정원의 10%는 5명 이하이고 이 정도는 금방 채워질 수 있다고 판단했다. 물론 이 기준을 다르게 가져 갈 수도 있다. 판단의 기준은 실제 이 정보를 활용할 담당자들과 협의해 서 결정해야 하나, 이 프로젝트에서는 그런 담당자가 없기에 임의적으로 판단해 결정했다. 
두번째로 만든 것은 평가점수 존재여부 파생변수였다.
‘평가점수 존재 여부’ 파생 변수는 평가점수가 있는지 여부를 나타내는 변수로 평가점수 존재시 True로 표시된다. 인증이 됐다면 평가점수가 존재해야 하나 실제 미인증 9,826곳, 평가점수의 총점의 결측치 10,476곳으로 나왔다. 인증됐더라도 평가점수가 존재하지 않는 경우도 존재해 해당 파생변수를 만들었다.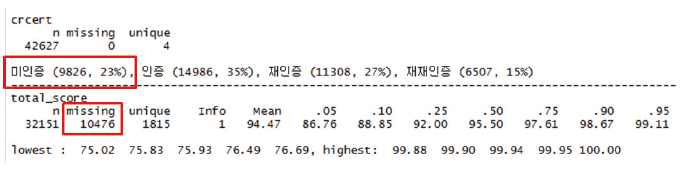
세번째로 만든 것은 ‘시도별 시군구명’이라는 파생변수였다. 이 변수는 여러 시도에 시군구명이 동일한 경우가 발생해 ‘시 도명’과 ‘시군구명’이라는 기본변수를 결합해 만들었다. 파생변수를 생성해 탐색적 자료분석을 해 보니 259개의 유일한 값 이 생성됐다.
네번째로 만든 것은 보육서비스 제공여부 관련한 10개의 파생변수였다.
‘보육서비스 구분(crspec)’ 기본변수의 값을 보니 ‘/’(슬래쉬)를 구분자로 해 여러 개가 같이 존재했는데 하나의 어린이집이 여러 가지의 보육서비스를 제공하고 있었다. 그래서 보육서비스 구분의 기초요소를 파싱을 통해 찾아보니 10개의 기초단 위의 보육서비스 항목이 나왔고, 각 10개의 기초단위 보육서비스를 제공할 경우 True로 표시하도록 파생변수를 생성했다
마지막으로 만든 것은 ‘인증여부’ 파생변수였다.
‘인증유형’ 기본변수의 값을 보니 인증된 상태를 인증, 재인증, 재재인증로 나누어 표시돼 있었다. 이는 인증됐는지 미인증 됐는지 구분하는 변수가 필요해 생성했다.
메모리 용량 초과로 서울시 데이터만 분석
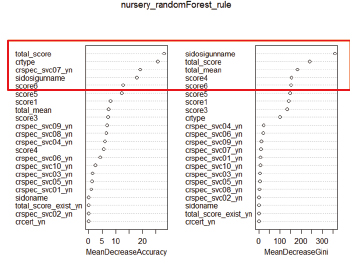
어떻게 해야 할까 시간은 부족하고 메모리 용량의 한계를 타파할 방법은 없었다. 이 외에도 ‘운영관리점수’ 변수의 결측치 비율이 75% 이상이어서 결측치를 제거하면 75%의 데이터가 사라지고 25% 데 이터만 가지고 분석해야 하는 문제도 있었다. 그래서 랜덤 포레스트 분석에서는 ‘운영관리점수’ 변수를 제외시키기로 했 고, 메모리 용량 초과로 인해 서울시 데이터로 한정해 분석하기로 방향을 수정했다. 중요 변수로는 ‘시도별 시군구명’, ‘총점’, ‘인증유형’이 나왔고, 보육서비스는 10개의 변수로 쪼개져서인지 상위권에는 ‘일 시보육 보육서비스 여부’ 1개만 나왔다.
이어 우리는 서울시 어린이집 현황에 대하여 EDA를 통해 서울시 구별 어린이집 현황과 서울시 어린이집 유형별 현황, 서 울시 보육서비스별 현황으로 나누어 살펴 보았다.
인증평가점수를 사용한 의미있는 정보 찾기
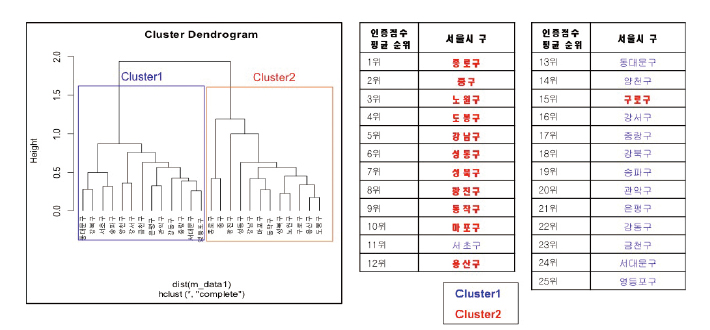
클러스터 1과 2에 해당되는 구를 시각화 하기 위해, gvisMap을 사용하려 했으나, 두 개의 군집을 다른색 아이콘으로 구별 하는 코딩이 쉽지 않았다. 처음에는 ‘지도를 각각 따로 그려야 되나’ 라는 생각도 했지만, 또 다른 서울시 맵을 시각화할 수 있는 ggmap 함수를 찾아 두 개의 클러스터를 다른 색으로 시각화할 수 있었다. 상위그룹인 클러스터 2에 해당되는 구는 서울시 중심에 위치함을 볼 수 있으며, 강남보다 강북에 더 많이 위치한다.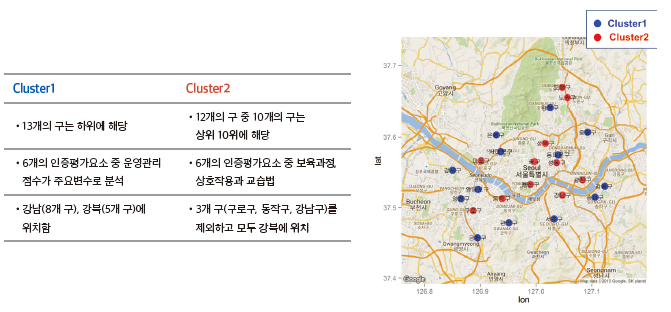
두 개의 그룹 특성을 분석하기 위해 주성분 분석을 수행했다. 주성분 분석은 수행후 summary() 함수의 결과 중 Proportion of Variance로 주성분들이 데이 터의 분산 중 얼마만큼을 설명해주는지를 알 수 있다. Cumulative Proportion은 Proportion of Variance의 누적값으로 누적값의 80% 수준에 가 까운 값까지의 주성분을 선택하게 된다.
각각의 군집에 대한 주성분 분석후의 결과에서 Cumulative proportion을 보고, 누적 80% 분산 비율을 나타내는 주성분을 선택했고 각 주성분에 서 종속변수에 가장 영향을 많이 미치는 변수를 축 약한 결과, 클러스터1에서는 운영관리와 보육과정 이, 클러스터2에서는 보육과정과 상호작용 및 교 습법이 중요변수임을 알 수 있었다.
조건부 확률로 의미있는 정보 찾기
그런데 연관성 분석은 제약사항이 있다. 사용할 수 있는 데이터가 factor형이나 boolean형이어야 하는데 연속형 변수는 사용할 수 없으므로 연속형 변수를 factor형이나 boolean형의 변수로 가공해 파생변수를 만들어 사용해야 한다. 아래의 표와 같이 변수를 서울특별시 데이터만을 대상으로 연관성분석에 입력했다. 최소 support는 0.001, confidence 는 0.9 이상을 적용한 결과는 아래와 같이 나왔다.
위의 연관성 분석 결과를 보면 지역과 어린이집 유형, 보육서비스가 주로 결합돼 rule이 발생했음을 알 수 있다. 최소 support는 0.001, confidence는 0.9 이상을 적용시켰으나, 이 값을 변동시키면 결과가 변화되는 것을 확인할 수 있다. Confidence는 앞의 조건 중에서 뒤의 조건(여기서는 {충원율 90%이상})이 되는 조건부 확률을 나타내고, support는 입 력된 데이터 건수 중에서 앞의 조건과 뒤의 조건을 동시에 만족하는 건수에 대한 비율을 나타낸다.
연관성 분석 결과의 첫번째인 “{어린이집유형=가정,영아전담} => {충원율_90%이상} : confidence = 1.0000, support = 0.001220256 이다. 과연 이 rule이 의미가 있을까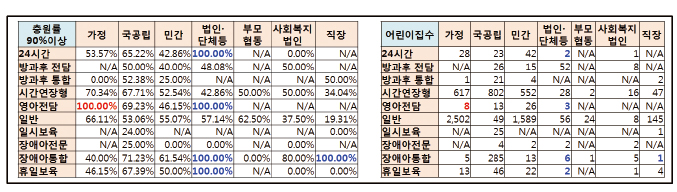
위의 표는 서울시의 어린이집 유형별 보육서비스별 현황 정보이다. 보다시피 빨간색으로 표시된 것처럼 가정형 영아전담 어린이집은 서울시에 8곳이 존재하고, 이 8곳 모두 충원율 90% 이상임을 확인할 수 있다. 그런데 조건부 확률이 100% 인 파란색으로 표시된 곳은 연관성 분석 결과에서는 나오지 않았다. 왜 그럴까 서울시의 어린이집 수는 6,602곳이다. 최 소 support가 0.001이므로 연관성 분석의 결과로 나올 수 있기 위해서는 그 rule에 해당하는 어린이집은 7곳 이상이어야 하는데, 파란색으로 표시된 곳은 그 수치를 넘어서지 못해서 연관석 분석의 결과에서 제외된 것이다.
그럼 서울시 각 구별 영아전담 서비스를 제공하는 어린이집 현황을 살펴보자. 아래의 표를 보면 알겠지만 대부분이 빨간 색으로 높은 충원율을 보이고 일부는 80%대 수준을 보인다. 다만 저조한 충원율을 보이는 곳이 3개로 파란색으로 표시 된 것이다. 이 중 마포구의 민간형은 현원이 0명이므로 분석대상에서 제외했고, 종로구의 민간형과 성북구의 민간형의 경 우의 저조한 상태는 지역적 특성 또는 어린이집 개별 특성으로 판단됐다. 서울시의 한 개의 구라고 할 지라도 지역이 넓다 는 것을 고려할 때 조금 더 구체적인 입지조건 및 환경 요건을 따져 본다면 영아전담 보육서비스를 제공하는 어린이집이 더 필요함을 알 수 있다.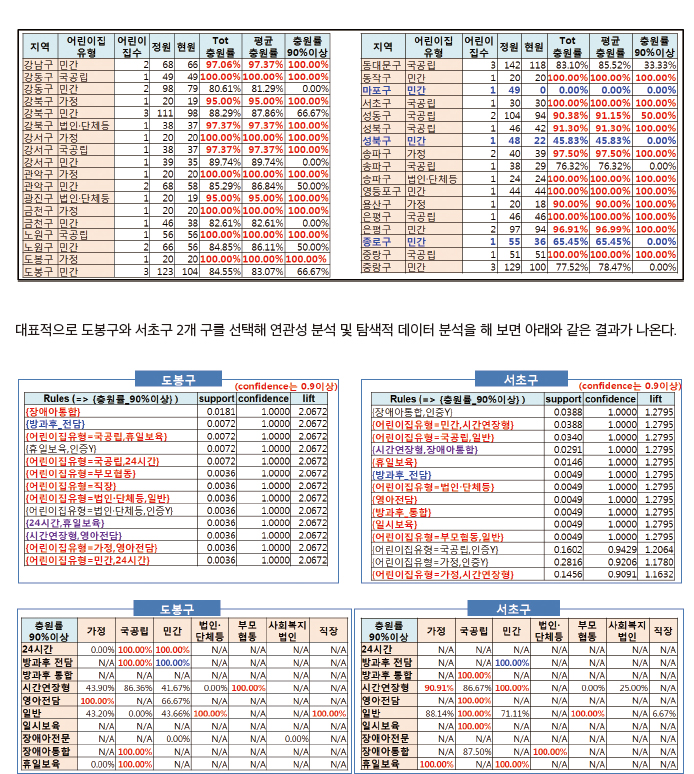
2개 구만 비교했지만, 그 결과를 보면 각 구 간의 공통적인 부분도 있고 차이가 존재하는 부분도 있다. 연관성 분석의 결과 인 rule 역시 차이를 보인다. 공통적인 부분으로 본다면 방과후 전담에 대해 높은 충원율을 보이고 있다는 점이다. 국공립 역시 서초구의 경우에는 높은 충원율을 보이고 있어서 추가적으로 국공립이 필요하다고 판단되며, 도봉구의 경우 일반 보 육서비스만 제공하는 한 곳의 국공립을 제외하고 나머지 국공립형 어린이집은 높은 충원율을 보이고 있어 해당 어린이집 이 추가적인 보육서비스를 제공한다면 충원율이 높아질 수 있는 가능성이 있다고 판단된다. 물론 그 어린이집 만의 입지 조건이나 특성 때문일 수 있다는 것도 고려해야 한다.
보육환경 관리와 개선에 필요한 정책 방향의 참고 정보
특히 최근 서울시의 국공립 어린이집 단계적 확대 정책은 서울시 전체의 높은 충원율을 비추어 볼 때 올바른 정책이라고 할 수 있다. 다만, 일부 국공립 어린이집이 낮은 충원율을 보이기도 해 무조건적인 국공립 어린이집 확대가 아닌 수요자들 이 필요로 하는 위치에 수요자가 원하는 보육서비스를 제공하는 어린이집을 제공하는 것이 필요하다고 본다. 이와 함께 높은 충원율이 나온 것은 영아 전담, 시간연장형, 휴일 보육 서비스로 맞벌이 부부들에게 필요한 보육서비스였다. 그러나 이러한 서비스들이 특정 지역에서는 부족하거나 없는 것으로 분석됐다.
서초구의 경우 전체적으로 높은 충원율을 보였고 특히 방과후전담, 영아전담, 일시보육, 휴일보육 등의 보육서비스가 추가 적으로 필요한 상태를 보였다. 그러나 24시간 보육서비스를 제공하는 어린이집은 없었는데 서울시 다른 구에서 높은 충 원율을 보이는 것을 고려할 때 서초구에도 이러한 서비스를 제공하는 어린이집은 필요할 것으로 예상된다. 도봉구의 경우 80%대의 충원율을 보였으나, 특히 방과후전담, 영아전담 등의 보육서비스가 추가로 필요하며, 일시보육 서비스를 제공 하는 곳은 한 곳도 없지만 필요할 것으로 예상된다.
앞에서 분석한 결과를 활용한다면, 어린이집을 창업하고자 하는 신규 창업자에게는 지역별 어린이집 창업 유형 정보 제공 을 통한 맞춤형 창업을 지원해 수요자 중심의 보육서비스를 제공할 수 있고, 어린이집을 관리하는 정책담당자에게는 보육 환경 수요 요구분석을 통한 관리 및 개선에 필요한 정책 방향에 참고할 수 있는 정보를 제공할 수 있다고 자신한다.
데이터를 많이 이해하면 얻을 수 있는 정보도 많아진다
데이터 분석을 하면서 느끼는 것은 데이터를 보면서 무엇을 보려고 하는지 명확한 만큼 더 잘 볼수 있다는 것이었다. 프로 젝트 주제를 정하고 어떠한 의미있는 정보를 찾을 것인가에 대해 토의할 때 다양한 의견들이 나왔고 그 의견은 데이터 분 석의 시초가 됐다. 그 생각들을 토대로 데이터 분석을 하면서 제약사항 내에서 할 수 있는 내용들을 찾을 수 있었다.
8주간의 길다면 긴 장정! 배웠던 내용을 바로 적용할 수 있는 프로젝트를 통해 데이터에서 의미를 찾아내는 과정이었다. 그 과정 과정에는 토요일뿐만 아니라 평상시에도 카톡을 통해 조언을 아끼지 않은 조인호 멘토가 있었다. 팀원들과는 계 속 토의하고 고민하면서 해결방안을 찾아 내며 데이터 분석의 맛과 즐거움을 함께 느꼈다. 분석전문가 과정을 제공해준 한국데이터베이스진흥원과 교육이 원활하게 진행되도록 수고해준 김정훈 연구원, 그리고 교수님들 덕분이다. 앞으로 기 회가 된다면 빅데이터 아카데미에서 개설된 기술전문가 과정과 기획전문가 과정 모두를 수강해 빅데이터 분석만이 아닌 통합적인 시각에서 데이터를 바라 볼 수 있는 전문가가 되고 싶다.