
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
Machine Learning을 통한 고객(광고주) 이탈 예측 빅데이터 분석으로 광고주의 이탈을 막고 수익을 지켜라 그리고 광고사와 대리인들의 다양한 이해관계가 얽혀 있다. 광고를 통해 매출이 증가하면 모두가 만족스럽겠지만, 그렇지 못해 광고주 가 이탈하는 경우도 있다. 분석전문가 14기 우수조는 과거에 이탈한 광고주의 데이터를 분석하여 이탈 가능성이 높은 광고주를 미리 예 측하고, 사전에 조치를 취해 광고주의 이탈방지를 도울 수 있는 시스 템 개발을 위한 프로젝트를 진행하였다. The Challenges 최근 다양한 유명 오픈마켓 사이트에서는 검색창에 키워드를 입력하면 상단에 광고를 노출 시켜주고, 노출된 광고가 클릭되면 광고주가 사전에 정해준 광고비에 클릭수를 곱한 액수 를 광고비로 받고 있다. 광고마다 일정 금액을 충전하고 소비자가 클릭할 때 금액이 광고비 로 빠져나가며, 금액이 완전히 소진되면 자동으로 광고가 내려가는 구조로 이루어져 있다. 이 업계에는 광고주와 소비자 외에도 포털이나 대형쇼핑몰 등 광고가 노출되는 지면과 소 비자를 보유한 매체사가 있다. 또 매체에 노출될 광고 플랫폼을 개발하고 운영과 영업을 하 는 플랫폼사와, 플랫폼사의 영업 및 운영을 대리하는 에이전트도 존재한다. 광고 노출 서비스의 세계에서는, 사이트에 광고를 주던 광고주가 광고효율 또는 매출이 감 소하거나 수익이 맞지 않는 등의 이유로 더 이상 광고를 주지 않는 경우가 생기게 마련이 다. 우리는 이런 경우를 ‘이탈’이라고 부른다. 그런데 플랫폼사나 에이전트는 광고 이탈의 사전 징후 등을 포착하지 못한 채 이탈 후의 뒤늦은 사후 조치만 행하는 실정이다. The Approach 2013년 1월부터 2015년 12월까지 2~3만 건 가량의 ID별로 합산된 데이터를 추출하였다. 이 중 분석에 필요한 데이터를 2013년 10월 8일부터 2014년 10월 7일까지의 데이터(이하 2014년 데이터)와 2014년 10월 8일부터 2015년 10월 7일까지의 데이터(이하 2015년 데 이터)로 정하였다. 데이터는 실무자가 전체 데이터 중 의미가 있다고 판단되는 70%의 변수 를 요약하였다. 나머지 30%는 파일의 크기에 비해 실제 분석에 영향을 끼치는 정도가 낮아 프로젝트에 큰 도움이 되지 않는다는 판단 하에 제외하였다. ⊙ 중요 변수 이제 모델 구축과 검증 세트를 마련하는데, 1차 모델 내 평가를 위해 2014년 데이터를 7:3 으로 나눠 7로 모델을 만들고 3으로 검증하기로 하였다. 모델선정에 있어 SVM, Random Forest, C5.0을 모두 진행하여 비교 분석하기로 하였다. 이 중 Random Forest와 C5.0은 정 규화 과정이 필요 없으나 SVM은 정규화 과정이 필요하여 정규화를 진행하였다. 지금까지 이탈고객의 요인분석과 군집분석을 통해 크게 다섯 가지의 광고이탈자 그룹이 도 출되었다. 제1그룹은 짧은 기간에 광고비를 적게 사용하여 체감 광고 효과가 높지 않은 그 룹이다. 이들에게는 광고 사용 기간과 사용 광고비를 늘리기 위해 초기 충전금액을 상향 조 정하고 사용 예산 한도를 올리기 위한 정책 마련이 필요해 보인다. The Outcome[분석14기] 빅데이터 분석으로 광고주의 이탈을 막고 수익을 지켜라
1) 광고 노출 서비스의 개요
업계에서 성과를 판단하는 주요 지표로는 인터넷상에서 배너 하나가 노출될 때 클릭되는 횟수인 CTR(Click Through Ratio. 일명 클릭률)이 있다. 예컨대 특정 광고가 1백 번 노출될 때 3번 클릭되면 CTR은 3%가 되는 식이다. 또 광고를 클릭하여 사이트에 들어온 방문자가 실제 구매로 이어지는 비율인 CVR(Conversion Rate. 전환율)도 있다. 아울러 매출액을 광 고비로 나눈 값인 ROAS는 광고비가 작고 매출액이 클수록 값이 커지므로 광고의 효율을 측정하는 중요한 척도이다.
2) 문제점과 프로젝트의 목적
과거에 이탈했던 광고주의 데이터를 분석하여 이탈 가능성이 높은 광고주를 사전에 예측 하고, 광고주의 이탈이 발생하기 전에 사전 조치를 취해 이탈과 매출 하락을 방지하는 것이 이 프로젝트의 목적이다.
분석전문가 14기 우수조 구성원들은 연도별 광고주와 월 및 주별로 광고를 시행한 횟수, 그리고 연도별로 이탈한 광고주의 수를 파악하였다. 또한 이탈한 광고주와 이탈하지 않은 광고주의 광고일, 클릭수, 광고비, 매출액을 비교하고, 데이터 분석 프로세스를 구성하였다 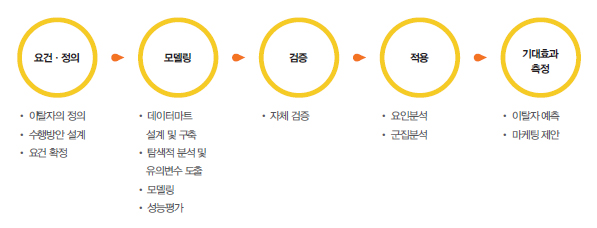
1) 데이터 수집
전체 데이터를 식별하고 1차 데이터마트에서 이탈과 연관된 테이블 10개를 선정한 뒤 연 단위로 요약한 데이터를 추출하였다. 이후 이탈과의 연관성을 분석해 데이터의 유효성을 검증한 뒤 최종 데이터마트에서 이탈과 연관된 테이블을 최종적으로 선정하고 주단위로 요 약한 데이터를 추출하였다. 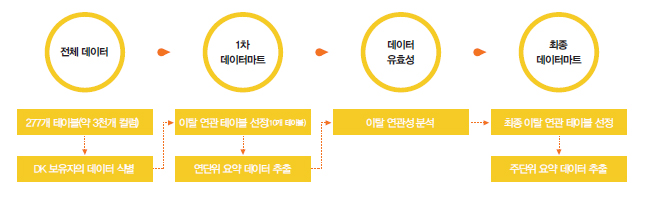
2014년도에 사용했지만 2015년에 사용하지 않은 고객을 이탈자로 정의하였다. 학습기간 (패턴)은 1년을 주기로 반복된다고 가정하였다. 2014년부터 2년간 사용하고 이탈한 사람은 예측할 수 없다. 또 2014년에 사용하고 2015년에 이탈했지만 2016년에 들어오는 사람을 이탈자로 판별하였다. 지금의 모델은 사용자의 1년간의 행동을 주 단위로 관찰한 내용을 바탕으로 이 고객이 지금까지 이탈한 고객의 패턴을 가진 고객인지 아닌지를 판별한다. 위와 같이 이탈자를 정의한 후, 수행방안을 다음과 같이 설계하였다. 전체 기간을 둘로 나 눈 뒤 앞 기간의 주요 변수의 시계열적 패턴을 통해 뒤 기간의 미래 상황을 예측한다. 전체 의 기간을 X개로 나누고, X기간에 있던 사람은 정상으로 보는 반면 X-Y기간 이하에 있었던 사람은 이탈자로 보는 것이다. 데이터를 어떻게 쪼개서 어느 기간에 있는 고객을 정상으로 보고, 어느 기간에 있던 고객을 이탈자로 볼 것인지는 모델링 이후에 정의하기로 하였다. 이 기간에 대해 노출수, 클릭수, 판매금액 등의 중요한 변수를 선정하고, 이 중요한 변수를 주 단위로 쪼개어 추가하기로 하였다.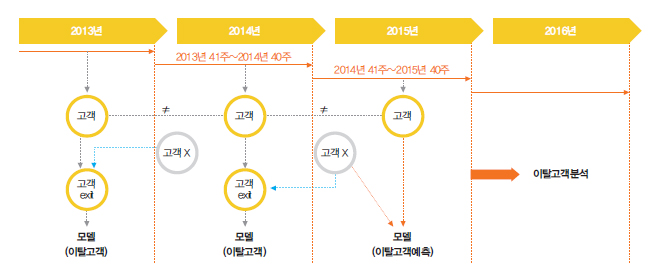
수집된 데이터를 가공하기 위해 데이터마트의 설계 및 구축 과정이 필요하다. 먼저 연도별 변수의 패턴이 일정하다고 보고 이를 연단위로 학습시켰다. 이 모델로 다음 해의 이탈 고객 을 예측할 수 있을 것으로 판단하였다. 2013년과 2014년에 사용했지만 다음해에 이탈한 고 객의 성향을 파악한 결과 이탈고객과 비이탈고객의 광고일수, 클릭수, 광고비, 매출액 차이 가 현저하게 발생했다. 그 패턴도 매년 유사했다. 그렇다면 주단위로 전처리된 이탈에 영향 을 주는 것으로 판단된 변수들을 사용하여 분류 모델을 생성한 후 적용하면 이탈 고객의 예 측도 가능할 것이라 판단하였다. 이에 따라 데이터마트를 설계하고 실행코드를 구축하였다.
2) 데이터 분석
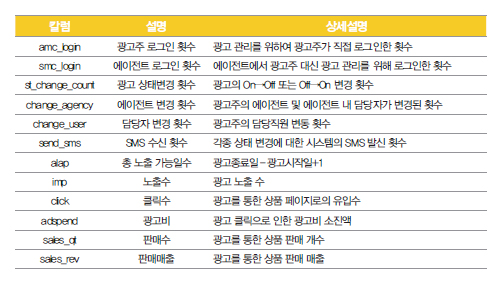
먼저 SVM의 교차검증 결과 24시간 이상의 많은 시간이 소비되었으며 정확도는 88.27%였 다. 반면 일반검증 결과 1분 내에 연산이 완료되며 과적합은 없었고, 정확도는 88.29%였다. 둘째로 Random Forest를 사용한 결과, No Information Rate의 경우는 정확도 61%인 반면 준비한 모델을 사용할 경우 정확도가 88%에 달했다. Random Forest를 Tuning한 결과 반 나절 이상의 러닝타임을 보였으며 정확도는 1% 가량 상승했다. 끝으로 C5.0으로 교차분석 을 한 결과 과적합 문제는 없으나 변수를 너무 적게 사용한다는 문제가 있었 Random Forest가 정확도가 높고 530개의 변수를 모두 사용하여 적합한 모델로 채택하였다. SVM은 정확도가 다소 낮고 해석이 어려웠으며, C5.0은 빠르고 정확도가 유사했지만 일부 변수만 선택해 사용하여 채택하지 않았다. 데이터 분석 결과, 고객 에이전트와 고객사 담당자 변경은 이탈자와 미이탈자 간에 유의미 한 차이를 도출하기 어려웠다. 그러나 고객사 광고 노출 수, 고객 클릭수, 매출, 광고일의 경 우 미이탈자가 이탈자보다 더 많은 수치를 기록하며 각각 일정한 패턴으로 큰 폭의 차이를 보였다. 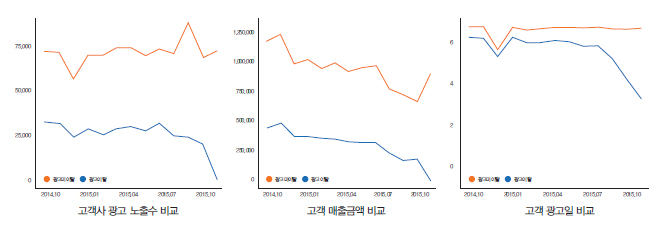
3) 이탈방지 대책 제안
제2그룹은 광고주 내부의 담당자가 변경되면서 광고의 필요성이나 성과를 알지 못해 이탈한 그룹이다. 이렇게 광고주 내부 담당자가 변경되면 즉시 광고 시스템과 관련된 교육을 시행하 여 새 담당자에게 광고의 필요성을 인식시키고 지속적인 광고사용을 독려해야 할 것이다. 제3그룹은 광고효과에 대한 만족도가 크지 않은 상태에서 잦은 대행사 내 담당자 변경으로 인해 서비스에 대한 부정적인 인식이 높아진 그룹이다. 이렇게 광고 대행사 내부 담당자의 변경이 잦은 경우, 수수료를 지급하지 않거나 영업권을 철회하는 등 해당 광고주의 대행사 에 대한 제약 조건을 마련해야 할 것이다.
제4그룹은 광고 운영 성과는 매우 높은데, 광고 외적 요인으로 광고를 이탈하는 그룹이다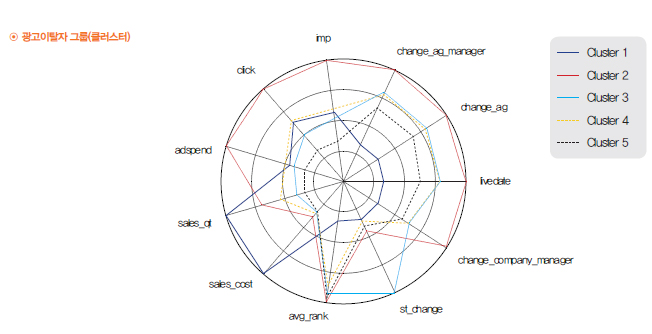
예컨대 과세기준을 간이과세에서 일반과세로 변경하는 것 등으로 인해 폐업한 그룹을 들 수 있다. 이런 그룹에 대해서는 가입 시점에서 간이과세로 확인되는 경우 과세기준 변경 시점을 예측하여 메일이나 해피콜 등을 통해 재가입을 독려하는 방안이 필요할 것으로 보인다. 제5그룹은 장기간 일정규모 이상의 광고를 사용하였으나 광고 효과가 낮아 이탈한 그룹이 다. 예산을 낮게 설정하는 바람에 광고효과가 높은 시간에 광고를 집행하지 못하여 효율적 인 광고 운영이 이뤄지지 못한 경우도 이에 포함된다. 이런 그룹은 광고를 설정할 때 알맞 은 예산을 권장하는 방향으로 시스템을 개선하고, 광고 효과의 향상을 위해 필요한 교육을 실시하는 등 광고주의 만족도를 향상시킬 수 있는 프로그램을 마련해야 할 것이다.
이번에 만든 모델은 검색광고 업계뿐만 아니라 게임, 쇼핑, SNS 등 온·오프라인 산업 전반 에서 이탈 분석을 할 때 참고 모델로 활용할 수 있을 것으로 보인다. 연도별로 마케팅을 통 해 수집된 개인이나 기업의 결제 또는 멤버십의 데이터를 바탕으로 이탈을 예측하여 사업 수익 극대화에 도움을 줄 것으로 기대된다. 또한 이탈고객의 군집분석을 통해 얻은 결과로 광고비 등의 비용을 조절하는 데 활용할 수 있을 것이다