
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
빅데이터 시대 인프라 아키텍처에 대한 이해 고경두 1. 빅데이터 인프라 아키텍처 개요 빅데이터 시대가 되면서 정형/비정형 데이터를 수집, 저장, 분석, 활용하는 빅데이터 시스템을 신규 구축하려는 수요가 증가하고 있습니다. 이런 빅데이터 시스템을 구축하기 위해서는 기존 일반적인 인프라 아키텍처에 비해 훨씬 많은 인프라 자원을 이용해서 구성되어야 하기 때문에 인프라 아키텍처 측면에서 더 많은 고려사항이 존재합니다. 2. 일반적인 인프라 아키텍처 일반적인 인프라 아키텍처를 이해하기 위해서 그 구축 절차별로 어떤 고려사항이 있는 지 살펴보겠습니다. 인프라 아키텍처 구축은 일반적으로 [표 1] 같이 요구사항 정의, 기본 설계, 상세 설계, 구축, 시험, 운영 단계로 구성됩니다. 3. 빅데이터 인프라 아키텍처 고려사항 빅데이터 인프라 아키텍처 구축도 일반적인 인프라 아키텍처 구축 단계와 동일하게 요구사항 정의, 기본 설계, 상세 설계, 구축, 시험, 운영 단계로 진행됩니다. 일반적인 인프라 아키텍처와 다른 점은 기본 설계 단계에서 WEB-WAS-DB의 전통적인 OLTP 시스템이 아닌 빅데이터 시스템의 특성을 고려해야 한다는 점입니다. 그럼 구체적인 고려사항에 대해서 알아보겠습니다. Hadoop Cluster의 구성요소는 Hadoop 2.X 기준으로 [그림 2]와 같이 Name Node, Resource Manager, Data Node, Node Manager가 있습니다. 이 때, Data Node와 Node Manager는 보통 물리적으로 같은 서버에 구성하고 Resource Manager도 Name Node와 물리적으로 같은 서버에 구성하는 경우가 많습니다. 빅데이터 시스템에서 HA 구성은 인프라적으로 구성하는 하는 것이 아니라 Hadoop에서 제공해주는 기능에 의존합니다. Hadoop Cluster의 구성요소별로 다운 시 src="https://dataonair.or.kr/publishing/img/knowledge/column_img_3060.jpg"> 일반적인 인프라 아키텍처에서는 Data영역에 대해서 가용성을 위해서 RAID 1+0이나 RAID 5로 구성하여 Disk 장애 시 데이터가 손실되지 않도록 구성합니다. 그러나, 빅데이터 시스템에서는 자체적으로 Replication를 통해서 기본적으로 데이터를 3중화해서 보관하기 때문에 속도 향상을 위한 구성인 RAID 0 으로 구성해야 합니다. 만약, 빅데이터 시스템의 Data 영역의 Disk를 RAID 1로 구성하게 되면 전체 Disk 용량의 반을 활용 못 하는 큰 손실이 발생하게 됩니다. 이 때, OS 영역의 경우는 인프라 자체적인 관리 영역이기 때문에 일반적인 인프라 아키텍처와 마찬가지로 RAID 1+0이나 RAID 5로 구성하면 됩니다. 4. 빅데이터 시대 인프라 아키텍처에 대한 이해 빅데이터 아키텍처에 있어서 인프라적으로 중요한 이러한 고려사항 외에도 수집을 위해서 어떤 도구를 사용할 것인지 Yarn의 Core, Memory, Disk 설정을 어떻게 할 것인지 등 Application적으로 고려해야 할 사항들도 많이 있습니다. 인프라 아키텍처 담당자는 이런 Application 고려사항이 존재하는 것을 인지하고 이에 대한 인프라적인 조언 및 지원을 해줘야 합니다. 예를 들어 데이터 수집을 위해서 별도의 Flume과 Kafka 서버가 필요하다고 하면 기존에 Data Node로 구성된 서버를 떼어서 사용할 수 없음을 이해해야 합니다. 초기 설계가 잘못된 경우 기존 유휴 서버를 이용해서 보충하는 경우도 있는데 그럴 경우 되도록 Data Node의 스펙을 동일하게 맞추는 것이 좋습니다. 그렇지 않을 경우 안정적인 성능을 기대할 수 없습니다.빅데이터 시대 인프라 아키텍처에 대한 이해
소속 : SK(주) C&C
경력사항
現 아이리포 기술사회, 컴퓨터시스템응용기술사
- 통신 분야 인프라 구축 및 운영
- SKT Swing(U.key3.0) 프로젝트 미들웨어 총괄
- 한이음 ICT 멘토링 주멘토
실제 빅데이터 시스템 구축 프로젝트 현장에서는 인프라 아키텍처 담당자는 하둡, 스파크 등 빅데이터 아키텍처에 대한 이해가 부족하고 빅데이터 Application 담당자는 인프라에 대한 이해가 부족하여 구축 이후에 추가로 서버를 증설하거나 설계를 변경해야 하는 경우도 발생하고 있습니다.
이런 문제에 있어 인프라 아키텍처 담당자와 빅데이터 Application 담당자 모두에게 도움을 주기 위해서 일반적인 인프라 아키텍처에 대해서 먼저 살펴보고 빅데이터 인프라 아키텍처 고려사항에 대해 알아보겠습니다.
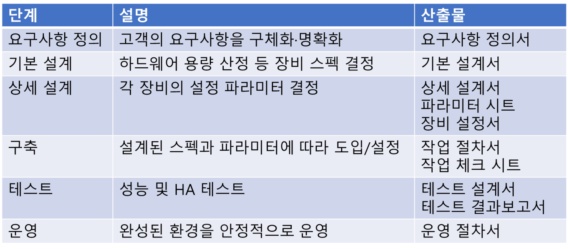
[표1] 전통적인 인프라 구축 절차
요구사항 정의 단계에서는 고객이 가지고 있는 요구 사항을 확인하고 명확화/구체화 합니다. 이 때 인프라 측면에서 요구사항을 명확화?구체화 하기 위해서 [표 2]같은 점검항목을 이용합니다.
[표 2] 인프라 점검항목
기본 설계 단계에서는 부하 분산 및 가용성을 고려하여 용량 설계를 진행합니다. 먼저 서버의 형태를 결정하고 결정된 형태에 따라 각 서버의 CPU, 메모리, 디스크의 용량을 설계합니다. 일반적인 OLTP성 시스템의 경우 WEB-WAS-DB의 3-Tier로 서버의 형태를 결정하고 부하 분산 및 가용성을 고려하여 각 Tier당 2개의 서버를 배치합니다. 이 때 용량 산정에는 [표 3]과 같이 3가지 방법을 이용합니다. 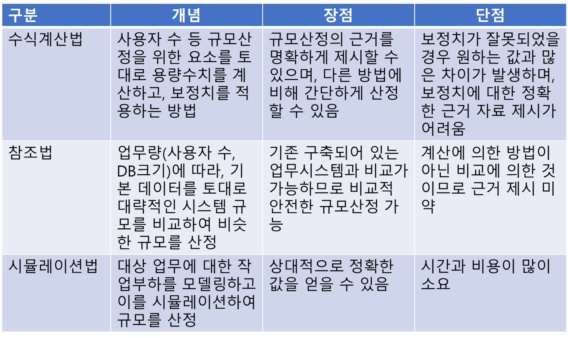
[표 3] H/W 용량 산정 방법
상세 설계 단계에서는 서버의 역할에 따라 서버의 파라미터를 결정합니다. [표 4]는 서버 유형에 따른 파라미터 권장값입니다.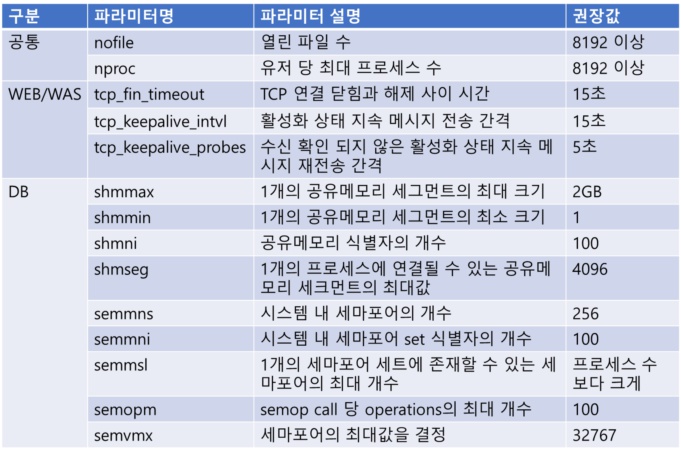
[표 4] 서버 유형에 따른 파라미터 권장값
구축 단계에서는 기본 설계 단계에서 결정된 장비 스펙과 상세 설계 단계에서 결정된 파라미터에 따라 장비를 도입하고 설정합니다. 이 때, 작업절차서를 만들어 작업의 누락이 발생하지 않도록 하고 설정 후에는 서버별 체크리스트를 작성하여 설정 확인을 하여야 합니다.
테스트 단계에서는 성능 테스트와 HA 테스트를 통해서 구축된 서버들이 고객의 요구사항에 맞게 구축되었는지 최종 점검을 합니다. 수행해야할 성능테스트의 유형은 [표 5]와 같습니다. HA 테스트는 HA 구성된 하나의 서버를 강제로 다운 시켜 HA 구성된 또다른 서버로 서비스가 정상적으로 되는지 확인합니다.
[표 5] 성능테스트의 유형
운영 단계에서는 작성된 운영 절차서를 바탕으로 실제 운영을 수행합니다. 특히, 주기적 예방점검(PM)과 모니터링으로 장애를 사전에 예방하는 것이 중요합니다.
1) Hadoop Cluster 규모산정
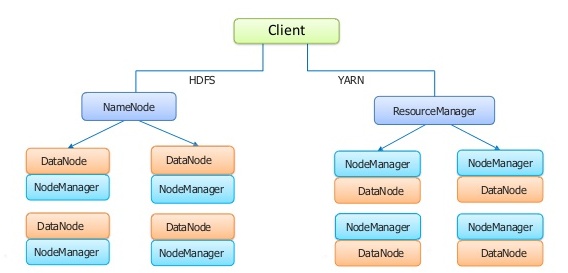
[그림 2] Hadoop Cluster 개념도
Hadoop Cluster 규모산정에 대한 이해를 돕기 위해 예를 들어 설명하겠습니다. 400 TB를 수용해야 하는 빅데이터 시스템을 구축한다고 가정하면, 20 TB짜리 Disk를 가진 서버 20대로 구성하면 될까요 결론부터 말씀드리면 아닙니다. [표 6] Cluster 규모산정 시 고려사항을 보시면 거의 2배의 서버가 필요한 것을 알 수 있습니다.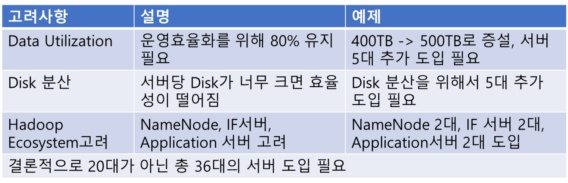
[표 6] Cluster 규모산정 시 고려사항
여기에 추가로 고려해야 할 사항이 한 가지 더 있습니다. 그것은 Disk 실제 사용량입니다. Disk의 제조사 표기용량은 10진수 기반인 반면, OS에서 인식하는 용량은 2진수 기반이라서 2 TB라고 표시된 Disk의 경우 실제로는 1.82 TB정도만 사용할 수 있습니다. 일반적인 상황에서는 큰 차이가 아니라고 생각할 수도 있지만 다수의 Disk를 사용하는 빅데이터 시스템에서는 큰 차이가 발생하게 됩니다. [그림 1] Disk 실제사용량 계산을 보시면 600 TB로 예상했던 사용량이 546 TB로 줄어든 것을 확인할 수 있습니다. 따라서, 빅데이터 인프라 아키텍처 설계 시에는 이런 Disk 용량의 차이까지 고려해서 용량을 산정해야 합니다.
[그림 1] Disk 실제사용량 계산
2) HA 구성
[표 7] Hadoop Cluster 구성요소별 다운 시 영향도
최신 버전을 기준으로 Hadoop Cluster의 구성요소는 모두 HA를 지원하고 있습니다. HA 구성에 따라 인프라적으로는 Secondary Name Node 구성을 위한 서버의 추가 도입을 고려해야 합니다. 문제는 Hadoop Ecosystem의 모든 구성요소들이 HA를 지원하고 있지는 않다는 것입니다. 버전별로 지원하기도 하고 지원하지 않기도 하기 때문에 구축하는 빅데이터 시스템에서 필요한 Hadoop Ecosystem 구성요소 별로 HA 가능 여부를 확인하여야 합니다. 예를 들면 Spark의 경우 구성 방식이 Standalone, YARN, Mesos으로 나뉘는데 Standalone 방식에서는 HA가 지원되지 않고, YARN과 Mesos방식에서는 HA가 지원됩니다.
3) RAID
빅데이터 시대에서는 인프라와 Application의 업무 영역이 점점 엷어지고 있습니다. 인프라 설계를 효율적으로 하기 위해서는 Application를 이해해야 하고, Application를 효율적으로 개발하기 위해서는 인프라에 대한 이해가 필요합니다. 위에서 언급된 일반적인 인프라 아키텍처에 대한 이해를 바탕으로 빅데이터 시스템의 특성을 고려해서 빅데이터 인프라 아키텍처를 구축한다면 보다 효율적이고 강력한 빅데이터 시스템이 만들어질 것입니다.