
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
예제를 통해 보는 Apache Storm의 핵심기능(1) 지금까지는 실시간처리에 대한 개념적인 이야기를 다루었고 2번에 걸쳐 예제를 통해 스톰의 실제 기능을 알아보는 시간을 가지도록 하겠습니다.
public class ExclamationTopology {public static class ExclamationBolt extends BaseRichBolt { 이렇게 짧은 프로그램만으로 실시간 분산 처리가 가능합니다. 이 짧은 코드 안에 스톰의 주요 개념이 모두 들어 있습니다. 다소 생소한 코드가 포함돼 있으므로 첫 번째 코드는 하나하나 설명하겠습니다. 일단 위의 코드를 실행해 보겠습니다. 여러 복잡한 로그가 나오지만 그중에 “!!!”나 “!!!!!!”가 붙은 영어 단어가 계속 출력될 것 입니다. 왜 이런 결과가 나오는지 아래에서 코드와 함께 핵심 기능들을 살펴 보겠습니다.
소스코드 TopologyBuilder라는 이름을 보면, 정확히 어떻게 구성돼 있는지는 몰라도 토폴로지를 만드는 Builder가 있고, 그 builder에 이전에 배웠던 spout과 bolt라는 것을 set해 줌을 알 수 있습니다.
public void nextTuple() { TestWordSpout이 어떤 역할을 하는지 알아보겠습니다. 사실 이 코드는 맨 위에서 언급하지는 않았었지만, 자체적으로 내장된 샘플 코드입니다. "nathan", "mike", "jackson", "golda", "bertels"와 같은 리스트에서 무작위로 하나씩 뽑아서 하나의 Tuple로 emit하고 있습니다. emit은 다음 단계로 처리할 데이터를 전달해주고 데이터 전송이 되었음을 알려줍니다.
public static class ExclamationBolt extends BaseRichBolt { - prepare(): bolt로부터 내보내지는 Tuple들에 사용되는 OutputCollector라는 형식을 미리 준비해 둡니다.
소스코드 설명
소스코드 설명 실시간 처리 시스템은 성능보다 장애 대비 기능이 매우 중요한 요소입니다. 물론 배치 작업도 장애가 발생해서는 안되겠지만, 실시간 처리 시스템은 더욱 더 장애에 민감하고 무중단을 추구해야 합니다. 그래서 스톰에서는 주키퍼를 이용해 시스템 장애가 발생하더라도 무중단으로 대처할 수 있도록 구성되어 있습니다. 처리 데이터에 따라 다르겠지만, 스트리밍으로 처리하더라도 데이터 유실은 발생하지 않는 것이 좋습니다. 많은 실시간 스트리밍 소프트웨어들이 최대한 데이터 유실을 하지 않으면서 성능을 내기 위해서 노력중이지만, 모든 것을 다 만족시킬 수는 없는 트레이드오프 성격을 갖고 있습니다.
public class SplitSentence extends BaseRichBolt { 일반적으로 메시지가 무사히 다음 단계로 전달되면 ack() 함수를 호출합니다. 마지막 Bolt까지 ack() 함수가 호출된다면, 해당 Tuple이 완전히 처리했다고 인지하고 Spout에서 해당 Message(Tuple)를 큐에서 삭제하도록 합니다. 특수한 경우 Fail() 함수를 호출해 고의로 전달 실패를 발생시킬 수도 있지만, 장애로 인해 ack() 함수를 호출할 수 없을 때가 있습니다. Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS에서 설정된 시간 안에 완전히 처리되지 못하면, 해당 Tuple은 실패한 것으로 간주합니다. 그리고 실패한 Tuple은 님버스에 의해 다시 Tuple을 만들어서 전달하도록 재시도합니다.예제를 통해 보는 Apache Storm의 핵심기능(1)
트위터에서 스톰을 오프소스로 전환하면서 코드를 단순히 공개만 해놓은 것이 아니라, 스톰의 기본 개념과 핵심 기능을 이해할 수 있도록 소스코드와 설명을 공개해놓고 꾸준히 업데이트하고 있습니다. 혼자서도 학습이 가능하도록 가능한 기본적인 설명은 Storm github에서 제공하는 코드 위주로 소개하겠습니다.
ExclamationTopology의 기본 원리
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();builder.setSpout("word", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("word");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");Configconf = new Config();
conf.setDebug(true);if (args != null &&args.length> 0) {
conf.setNumWorkers(3);StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
}
else {LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
1. 토폴로지
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3).shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2).shuffleGrouping("exclaim1");
코드 설명
- 토폴로지를 Builder를 통해 만듭니다.
- TestWordSpout이라는 Spout Class에 “word”라는 이름을 붙여서 할당합니다.
- 위에서 설정한 “words spout”을 shuffleGrouping이라는 방식으로 ExclamationBolt라는 Bolt Class로 보낸다. 그리고 이름은 “exclaim1”으로 합니다.
- 위에서 설정한 “exclaim1”을 shuffleGrouping해 이번에도 똑같이 ExclamationBolt로 보내고 그 이름을 “exclaim2”로 합니다.
Spout은 토폴로지의 원천 소스가 되고, 다음 단계로(bolt) 넘기는 역할을 합니다. 이 코드는 Spout에서 특정 데이터를 생성하고, 동일하게 ExclamationBolt를 두 번 수행하는 것이 이 토폴로지의 전체 흐름이다.
2. TestWordSpout
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
}
3. ExclamationBolt
OutputCollector _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
@Override
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
- excute(): bolt로 들어온 Tuple을 한 개씩 받아서 excute()내의 로직을 처리합니다. ExclamationBolt에 excute() 내에서 첫 번째 라인은 받아온 Tuple에 “!!!”를 붙여서 내보냅니다(emit). 두 번째 라인은 입력 받은 Tuple을 ack하는 것 입니다. 이것은 스톰의 데이터 손실을 막기 위한 방법입니다.
declareOutputFields() :ExclamationBolt가 "word"라는 하나의 필드를 내 보내도록 선언하고 있습니다.
이로써 중요 코드를 모두 보았습니다. 종합해 보자면, TestWordSpout에서 임의의 단어를 내 보내고, 2번의 Bolt를 통해 “!!!”를 한 번씩 추가하는 작업을 함을 알 수 있습니다. 그래서 맨 처음 나왔던 결과와 같이 특정 단어에 “!!!!!!”이 붙어서 출력되는 것 입니다.
이러한 작업은 로컬에서 단독으로 수행할 수도 있고(Local mode) 클러스터에서 병렬로 처리(Distributed mode)할 수도 있습니다.
4. 로컬 모드
스톰은 스레드를 이용해 워커 노드들을 모의 수행합니다. 로컬 모드는 topology 개발과 테스트할 때에 유용합니다. ExclamationToplogy에서 사용됐던 코드를 통해 로컬 모드가 어떻게 동작하는지 알아보겠습니다.
conf.setDebug(true);
conf.setNumWorkers(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
1). debug 모드: true로 설정하면, spout과 bolt에서 나오는 모든 tuple들이 로그로 기록됩니다 디버깅할 때 유용합니다.
2). number of threads: 로컬 모드에서 몇 개의 프로세스를 할당할 것인지 설정합니다.
3). LocalCluster 객체를 생성해 클러스터를 정의합니다.
4). 로컬l 내 가상 클러스터에 Topology를 제출하는 것으로 submitTopology(Topology name, Config, Topology)와 같은 형식을 가집니다
5). 10초 동안 대기합니다.
6). 2번에서 사용한 Topology name을 갖는 Topology를 kill합니다.
7). 로컬 클러스터를 종료합니다.
5. 분산 모드
스톰은 여러 서버들에서 분산해 동작합니다. Master로 Topology를 submit하면, master는 분산 실행을 위해 그 Topology의 코드를 전달합니다. 만약 worker가 죽게 되면, master가 해당 작업을 다른 곳에 재할당합니다.
conf.setNumWorkers(20);
conf.setMaxSpoutPending(5000);
StormSubmitter.submitTopology("mytopology", conf, topology);
1. Topology를 실행하기 위한 worker process 수를 설정합니다.
2. Spout의 pending 숫자를 조절합니다. 너무 크면 queue overflow가 발생할 수 있고, 너무 작으면 성능이 나오지 않습니다.
3. 로컬 클러스터에 Topology를 제출하는 것과 동일한 방법으로 처리하면 됩니다.
참고사항
- worker = process
- executor = thread
- tasks = spout/bolt의 instance
- 0.8 이하 버전에서는 task = tread.
간단하게 분산 모드의 작동 원리를 알아보겠습니다.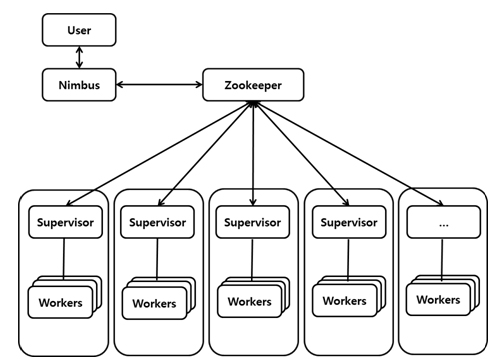
- bin/storm jar를 실행하면 toplogy sumitter가 topology 관련 파일(구현 로직과 설정 파일)을 업로드합니다.
- 님버스는 주키퍼를 통해 현재 가용한 자원(supervisor)들을 확인합니다.
- supervior는 님버스로부터 topology를 내려 받습니다.
- 이후 supervisor는 JVM processor인 worker를 실행해 실제 작업을 시작합니다.
폴트톨러런스
1. Worker가 죽었을 때
작업시간이 너무 오래 걸리거나 메모리 등의 문제로 worker가 제대로 동작을 못하고 죽는 경우가 있습니다. 이 경우에는 worker를 관장하는 해당 노드의 supervisor가 worker를 새로 구동시키고 새로운 작업을 할당합니다. 또한 하나의 노드에서 worker가 계속 죽을 경우 님버스에 요청해 해당 worker를 다른 노드에 재할당해 줍니다
2. Supervisor가 죽었을 때
Worker는 여전히 살아있으므로 할당된 작업까지는 계속 수행합니다.
3. Worker 노드가 죽었을 때
전원 등의 문제로 노드 자체가 죽었을 때 님버스는 다른 worker 노드에 작업을 재할당합니다.
4. 님버스가 죽었을 때
Supervisor와 worker가 계속 살아 있으므로 작업은 계속 수행됩니다. 그러나 님버스에서 수행하던 작업 재할당 같은 것은 수행되지 않으므로 최대한 빨리 님버스를 복구하는 것이 좋습니다.
5. Single point of failure
현재로써는 님버스가 죽으면 작업은 계속 수행되지만 작업 재할당 등이 되지 않으므로 님버스가 살아있는 것이 매우 중요합니다. 이러한 점 때문에 nimbus HA를 준비중에 있습니다.
Guaranteeing Message Processing
스톰에서는 이것을 위해서 여러 가지 옵션을 준비했습니다. 위에서 실습한 소스코드에서 ack(), fail() 함수를 보았을 것 입니다. 스톰에서는 이 함수를 이용해 Message(Tuple)가 완전히 처리되었는지 확인합니다.
OutputCollector _collector; public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
} public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
이때 모든 Message들을 다 추적하려면 메모리 사용이 많아지므로 Tuple마다 Task ID와 64비트 ack val을 부여합니다. 그리고 이 ack val은 xor 연산을 이용해 전체 과정을 완료하면, 해당 ack val이 0이 됩니다. 0이 되면 Tuple tree가 완료된 것으로 인지하고, 님버스가 큐에서 해당 Message(Tuple)를 삭제하여 전체 과정이 완료됩니다.
다음시간에는 메시지 처리시 그룹핑 방법과 트라이던트라고 하는 새로운 처리 방법에 대해 알아보고 스톰에 대한 간단한 설명을 마치겠습니다.