
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
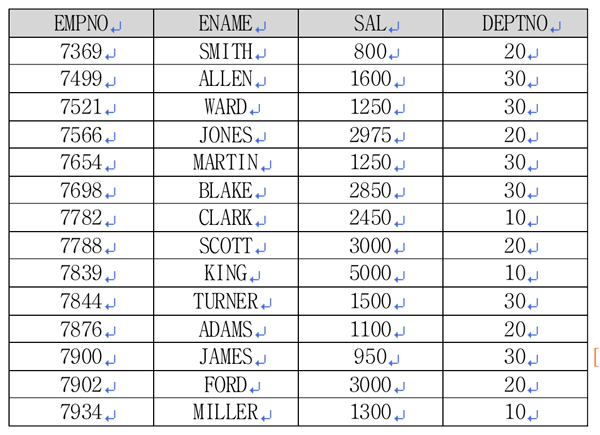
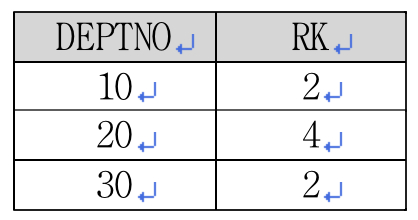
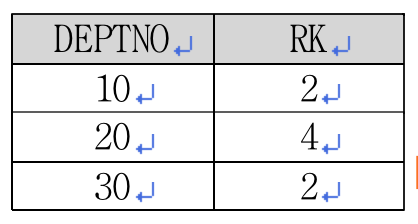
퀴즈로 배우는 SQL 신입사원 부서 배치에 따른 급여 랭킹 시뮬레이션 이번 퀴즈로 배워보는 SQL 시간에는 신입사원의 부서 배치에 따른 배치 부서별 급여 랭킹을 미리 시뮬레이션해서 결과를 출력하는 SQL 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다. 진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결한 다음 정답과 해설을 참조하길 바란다. 공부를 잘하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 기억하자. <리스트 1> 오라클(Oracle) 교육 실습용 유저인 스캇(SCOTT)의 EMP 테이블로부터 <표 2>의 결과를 출력하는 SQL을 작성하세요.
<리스트 1> 원본 리스트SELECT empno, ename, sal, deptno <리스트 1>은 사원정보 테이블입니다. 이 테이블에는 사원번호, 사원이름, 연봉, 부서 정보가 저장돼 있습니다. 이 회사에 신입직원 마농(MANON94) 군이 연봉 2500으로 입사하게 됐습니다. 마농 군이 어느 부서로 배치될지는 아직 정해지지 않은 상태입니다. 마농 군이 각 부서에 배치될 경우의 각 부서별 연봉 랭킹을 미리 구해보고자 합니다. <표 2>는 마농 군이 각 부서에 배치됐을 경우에 해당부서에서의 연봉 랭킹입니다. 문제를 스스로 해결해 보셨나요 이제 정답을 알아보겠습니다.
<리스트 2> 정답 리스트 어떤가요 여러분이 만들어본 정답과 같은가요 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다. 이번 문제는 부서별 연봉 랭킹을 구하는 문제입니다. 특이한 점은 실제 데이터가 아닌 가상 데이터를 추가해서 랭킹을 구해야 한다는 것입니다. 우선 실제 emp 테이블의 자료만 가지고 랭킹을 구해보겠습니다.
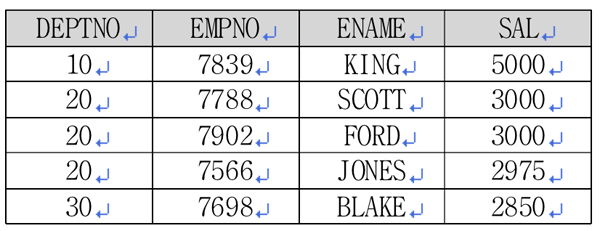
<리스트 3> 원본 테이블 랭킹 구하기SELECT deptno, empno, ename, sal <리스트 4> 원본 테이블에 마농 군 부서별 배치 자료 추가하기SELECT deptno, empno, ename, sal FROM emp 부서의 개수만큼 UNION ALL로 데이터를 추가했습니다. 이제 <리스트 4>의 자료를 이용해 전체 랭킹을 구해보겠습니다.
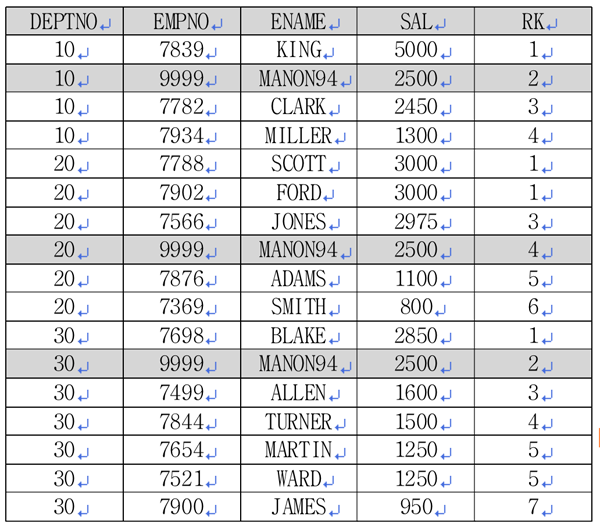
<리스트 5> 마농 군을 추가해 랭킹 구하기WITH t AS <리스트 5>의 쿼리를 통해 <표 5>의 결과를 얻었습니다. 여기에서 마농 군의 자료만 추출하면 원하는 결과가 나올 것입니다.
<리스트 6> 마농 군을 추가해 랭킹 구하기WITH t AS 결과가 완성됐습니다. 하지만 이 방법은 각 부서 코드의 개수와 값을 알고 있다는 가정 하에 사용 가능합니다. 이번에는 UNION이 아닌 다른 방법으로 접근해 보겠습니다. 마농 군의 자료를 기준으로 마농 군보다 더 많은 연봉을 가진 사람을 찾는 것입니다.
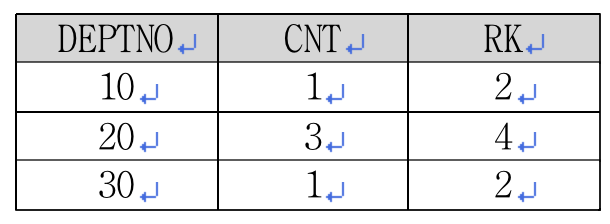
<리스트 7> 마농 군보다 연봉이 높은 직원 구하기SELECT deptno, empno, ename, sal <리스트 7>의 쿼리를 통해 <표 7>의 결과를 얻었습니다. 단순하게 새로운 연봉 2500보다 크다라는 조건을 주고 자료를 뽑았습니다. 이를 부서별로 집계해 카운트 해보면 <표 8>과 같은 결과를 얻을 수 있습니다.
<리스트 8> 마농 군보다 연봉이 높은 직원 카운트 <리스트 8>의 쿼리를 통해 <표 8>의 결과를 얻었습니다. 마농 군의 연봉 2500보다 연봉이 높은 직원의 부서별 카운트 값에 1을 더해주었더니 원하는 결과가 나왔습니다. 그런데 만약 마농 군의 연봉이 2500이 아니라 3000이라면 어찌 될까요
<리스트 9> 마농 군의 연봉 인상SELECT deptno <리스트 9>의 쿼리를 통해 <표 9>의 결과를 얻었습니다. 그런데 20번 부서와 30번 부서의 랭킹이 없습니다. 이는 해당 부서에는 마농 군보다 높은 연봉을 가진 사원이 없기 때문입니다. 이를 해결하기 위해 조건식을 WHERE 절에서 제거하고 SELECT 절로 올려보겠습니다.
<리스트 10> 마농 군의 연봉 인상SELECT deptno <리스트 10>에서는 <리스트 9>의 문제점이 해결됐습니다. 제일 처음 제시했던 정답 쿼리 <리스트 2>와는 전혀 다른 방법이네요. 이번에는 정답 리스트를 살펴보겠습니다. <리스트 2>에서는 특별한 구문이 사용됐습니다.퀴즈로 배우는 SQL : 신입사원 부서 배치에 따른 급여 랭킹 시뮬레이션
[문제]
FROM scott.emp
;
[문제설명]
[정답]
SELECT deptno
, RANK(2500) WITHIN GROUP(ORDER BY sal DESC) rk
FROM emp
GROUP BY deptno
ORDER BY deptno
;
[해설]
, RANK() OVER(
PARTITION BY deptno ORDER BY sal DESC) rk
FROM emp
;
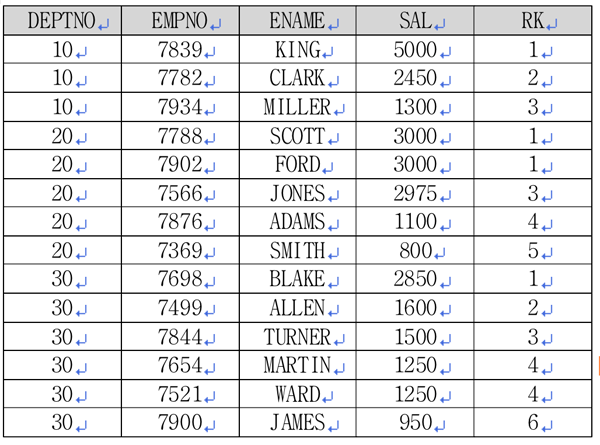
<리스트 3>의 쿼리를 통해 <표 3>의 결과를 얻었습니다. 순위를 구하는 분석함수인 RANK 함수를 이용해 부서별 순위를 구했습니다. <표 3>의 결과에 마농 군의 자료를 삽입해 보도록 하겠습니다.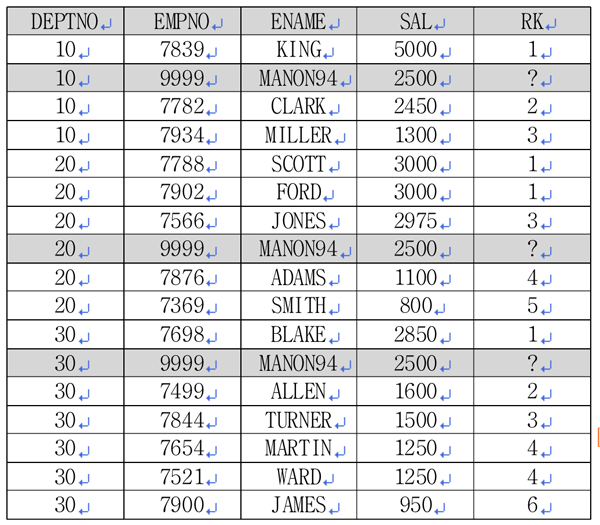
<표 4>는 각각의 부서별로 마농 군이 배치된 모습입니다. <표 4>의 결과를 얻기 위해서는 다음 <리스트 4>의 쿼리가 필요합니다.
UNION ALL SELECT 10, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 20, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 30, 9999, 'MANON', 2500 FROM dual
;
(
SELECT deptno, empno, ename, sal FROM emp
UNION ALL SELECT 10, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 20, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 30, 9999, 'MANON', 2500 FROM dual
)
SELECT deptno, empno, ename, sal
, RANK() OVER(
PARTITION BY deptno ORDER BY sal DESC) rk
FROM t
;
(
SELECT deptno, empno, ename, sal FROM emp
UNION ALL SELECT 10, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 20, 9999, 'MANON', 2500 FROM dual
UNION ALL SELECT 30, 9999, 'MANON', 2500 FROM dual
)
SELECT deptno, rk
FROM (SELECT deptno, empno, ename, sal
, RANK() OVER(
PARTITION BY deptno
ORDER BY sal DESC) rk
FROM t
)
WHERE empno = 9999
;
FROM emp
WHERE sal > 2500
ORDER BY deptno, sal DESC
;
SELECT deptno
, COUNT(*) cnt
, COUNT(*) + 1 rk
FROM emp
WHERE sal > 2500
GROUP BY deptno
ORDER BY deptno
;
, COUNT(*) + 1 rk
FROM emp
WHERE sal > 3000
GROUP BY deptno
ORDER BY deptno
;
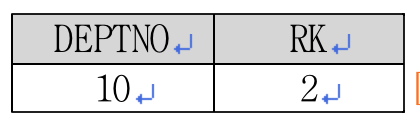
, COUNT(CASE WHEN sal > 3000 THEN 1 END) + 1 rk
FROM emp
-- WHERE sal > 3000
GROUP BY deptno
ORDER BY deptno
;
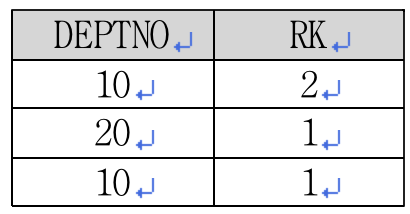
, RANK(2500) WITHIN GROUP(ORDER BY sal DESC) rk
<리스트 3>에서 봤던 RANK와는 문법이 다릅니다.
, RANK() OVER(
PARTITION BY deptno ORDER BY sal DESC) rk
OVER 대신 WITHIN GROUP이 사용됐습니다. OVER가 분석함수의 역할을 한다면 WITHIN GROUP는 집계함수의 역할을 한다고 볼 수 있습니다. 구문을 논리적인 순서로 해석해 보면 다음과 같습니다.
● WITHIN GROUP : 그룹 안에서
● ORDER BY sal DESC : 연봉으로 정렬했을 때
● RANK(2500) : 2500이라는 연봉의 랭킹을 구하라.