
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
DB2 튜닝 가이드 Part 5: 튜닝과 트러블슈팅(1) 디스크 병목 대부분의 DB2 시스템은 '성능 전개(performance evolution)' 과정을 거친다. 시스템을 배포한 후 시스템 모니터링을 하고, 만약 문제점이 발생되면 문제해결 과정을 거친다. DB2 튜닝 가이드는 단계별로 최상의 성능을 위한 최적의 설정을 제시함으로써, DB2 시스템 성능이 최상을 유지하도록 도와준다. 이번 회에서는 성능 튜닝과 트러블슈팅 과정 중 디스크 병목 상태에서의 해결 방안을 살펴본다.<연재순서>
DB2 튜닝 가이드 Part 1: 최상의 성능을 위한 시스템 구성 필자소개DB2 튜닝 가이드 Part 5: 튜닝과 트러블슈팅(1) 디스크 병목
DB2 튜닝 가이드 Part 2: 최상의 성능을 위한 DB 구성 (1)
DB2 튜닝 가이드 Part 3: 최상의 성능을 위한 DB 구성 (2)
DB2 튜닝 가이드 Part 4: 시스템 성능 모니터링
DB2 튜닝 가이드 Part 5: 튜닝과 트러블슈팅(1) 디스크
튜닝과 트러블슈팅에 대해서는 계통적인 접근 방법을 유지하는 것이 중요하다. 문제가 발생하는 경우 그 문제를 해결하려는 마음으로 되는대로 아무 변경사항이나 적용해서 처리하고 싶을 때가 많을 것이다. 하지만 그렇게 하면 실제로 근본적인 원인을 해결할 가능성이 상대적으로 낮으며 때로는 오히려 문제를 악화시킬 수도 있다. 다음은 성능 튜닝을 위한 몇 가지 기본 규칙이다.
성능 문제는 대체로 두 개의 큰 범주, 즉 전체 시스템에 영향을 미치는 문제와 특정 애플리케이션 또는 SQL 문과 같이 시스템 일부에만 영향을 미치는 문제로 나눌 수 있다. 문제를 조사하는 과정에서 한 가지 유형의 문제가 다른 유형으로 또는 그 반대로 전환될 수도 있다. 예를 들어 전체 시스템 성능 저하의 근본 원인은 단일 문(single statement)일 수 있다. 또는 시스템 전반의 문제가 초기에는 특정 영역에서만 나타날 수도 있다. 여기서는 시스템 전반의 문제부터 시작하기로 한다.성능 저하의 원인을 찾기 위한 전반적인 접근 방법은 상위 수준에서 시작하여 점차적으로 진단을 세분화하는 것이다. 이러한 “결정 트리(decision tree)” 전략을 사용하면 설명하기 어려운 증상의 원인을 가능한 빨리 제외시킬 수 있으며 시스템 전반의 문제와 보다 지엽적인 문제 모두에 적용할 수 있다. 또한 거의 또는 전혀 영향을 미치지 않는 변경을 하는 데 소비되는 노력을 덜어 준다.DB2 데이터베이스에 대한 조사를 시작하기 전에 다음과 같은 사전 질문을 해보는 것도 도움이 될 수 있다.
이러한 질문은 일반적으로 데이터베이스 전문가들이 애플리케이션 또는 인프라 전문가와 공동 작업하는 통합 분석 접근법의 중요한 부분이다. DB2 서버는 거의 항상 복잡한 하드웨어 환경, 다른 미들웨어, 애플리케이션에 속해 있으므로 문제를 해결하기 위해 여러 영역으로부터의 기술 검토가 필요하다.병목상태에는 다음 네 개의 일반 유형이 있으며 각각에 대해 약 2~3회에 걸쳐 차례로 설명한다.
1. 디스크
2. CPU
3. 메모리
4. ‘지연 시스템(lazy system)
시스템 병목상태 > 디스크 병목상태
디스크 병목상태의 기본 증상은 다음과 같다.
결국 디스크를 더 추가해야 할 수도 있지만 지금은 병목상태를 제거하기 위해 DB2 시스템을 튜닝할 수 있는지 검사하는 것으로 시작한다.
디스크 병목상태가 있는 경우 시스템 관리자는 사용률이 높은 장치의 이름을 영향을 받은 파일 시스템 경로에 매핑시킬 수 있다. 이로부터 DB2가 영향을 받은 경로를 어떻게 사용하는지 다음과 같이 확인할 수 있다.
이러한 경우를 개별적으로 살펴보자.
시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블
컨테이너에 병목상태를 일으키는 원인을 확인하려면 해당 테이블 스페이스에 저장되어 있는 테이블과 그 중 가장 사용률이 높은 테이블을 확인해야 한다.
시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블 > 동적 SQL 문
좀 더 드릴다운하여 이 테이블에서 사용량이 높아지는 원인을 찾아야 한다. 동적 SQL 문이 사용량을 높이는가 관심 있는 테이블을 사용하는 문을 확인하려면 STMT_TEXT에서 LIKE 술어를 사용하여 SYSIBMADM.SNAPDYN_SQL.TBSP_ID를 통해 동적 SQL 스냅샷을 쿼리한다. 반환된 열에는 읽은 행과 쓴 행, 버퍼 풀 사용량, 실행 시간, CPU 시간 등이 포함될 수 있다. ROWS_READ, ROWS_WRITTEN, NUM_EXECUTIONS와 같은 열에서 ORDER BY 절을 사용하여 테이블에 가장 큰 영향을 미치는 문에 집중할 수 있다. 여기서는 테이블 이름이 SQL 문의 첫 32672 문자 범위 내에 있다. 완벽한 가정은 아니지만 대부분의 경우가 그렇기 때문에 LIKE 술어에서 필요하다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블 > 정적 SQL 문
반환된 열에는 읽은 행과 쓴 행, 버퍼 풀 사용량, 실행 시간, CPU 시간 등이 포함될 수 있다. ROWS_READ, ROWS_WRITTEN, NUM_EXECUTIONS와 같은 열에서 ORDER BY 절을 사용하여 테이블에 가장 큰 영향을 미치는 문에 집중할 수 있다. 여기서는 테이블 이름이 SQL 문의 첫 32672 문자 범위 내에 있다. 완벽한 가정은 아니지만 대부분의 경우가 그렇기 때문에 LIKE 술어에서 필요하다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블 > 정적 SQL 문
정적 SQL이 사용량을 높이는가 여기서는 시스템 카탈로그와 db2pd를 사용하여 어떤 문이 가장 사용량이 높은지 찾아야 한다. 다음과 같이 관심 있는 테이블을 참조하는 문에 대해 PKGSCHEMA, PKGNAME, SECTNO를 선택하여 SYSCAT.STATEMENTS를 쿼리한다.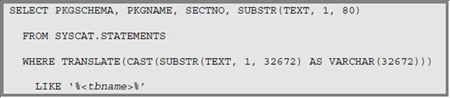 관심 있는 테이블을 사용하는 정적 SQL 문의 패키지 이름과 섹션 번호를 찾은 다음 db2pd static을 사용하여 이들 중 어떤 것이 사용량이 높은지(있는 경우) 찾는다. db2pd static 실행 결과에는 db2start가 시작된 후 시스템이 실행한 각 정적 SQL 문에 대한 행이 있다. NumRef 카운터는 해당 문이 실행된 횟수를 나타내고 RefCount 카운터는 현재 해당 문을 실행 중인 DB2 에이전트의 수를 나타낸다. db2pd static을 여러 번 실행하여 결과를 모니터링한다. 이렇게 하여 NumRef의 값이 빠르게 증가하거나 RefCount의 값이 2 또는 3 이상인 경우가 잦으면 사용량이 높은 문임을 나타낼 수 있다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블 > 핫 SQL 문
관심 있는 테이블을 사용하는 정적 SQL 문의 패키지 이름과 섹션 번호를 찾은 다음 db2pd static을 사용하여 이들 중 어떤 것이 사용량이 높은지(있는 경우) 찾는다. db2pd static 실행 결과에는 db2start가 시작된 후 시스템이 실행한 각 정적 SQL 문에 대한 행이 있다. NumRef 카운터는 해당 문이 실행된 횟수를 나타내고 RefCount 카운터는 현재 해당 문을 실행 중인 DB2 에이전트의 수를 나타낸다. db2pd static을 여러 번 실행하여 결과를 모니터링한다. 이렇게 하여 NumRef의 값이 빠르게 증가하거나 RefCount의 값이 2 또는 3 이상인 경우가 잦으면 사용량이 높은 문임을 나타낼 수 있다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 데이터 컨테이너 > 핫 테이블 > 핫 SQL 문
요점으로 돌아가서 I/O 병목상태를 일으키는 하나 이상의 SQL 문을 확인하면 다음은 I/O를 감소시키도록 문을 최적화할 수 있는지 여부를 판단해야 한다. 문이 원하지 않는 테이블 스캔을 발생시키는가 이는 db2exfmt로 액세스 플랜을 검사하고 문제가 된 문에 대해 ROWS_READ와 ROWS_SELECTED를 비교하여 확인할 수 있다.테이블 스캔은 임시 쿼리에서는 불가피한 경우가 많지만 I/O를 너무 많이 발생시켜서 병목상태를 만드는 반복되는 쿼리는 해결해야 한다. 더 이상 사용되지 않는 문이나 인덱스 문제는 테이블 스캔의 사용을 늦어지게 만들 수 있다. 반면 영향을 받은 테이블이 아주 작은 경우 버퍼 풀 크기를 늘리는 것으로도 I/O를 줄이고 병목상태를 제거하기에 충분할 수 있다.마지막으로 데이터 컨테이너 병목상태의 특별한 경우 두 가지를 살펴보자.
이러한 두 문제를 진단하고 해결하는 방법에 대한 자세한 내용은 이 시리즈 Part 7의 '지연 시스템 병목 상태'에 포함되어 있다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 인뎃스 컨테이너 > 핫 인덱스
컨테이너의 병목상태는 인덱스 작업보다는 테이블 작업으로 인해 일어날 가능성이 높지만 가능한 원인에서 테이블을 제외시킨 후에 인덱스 작업이 문제를 일으키는 가능성을 조사해야 한다. 사용할 인덱스 스냅샷이 없기 때문에 어느 정도 간접적으로 문제에 접근해야 한다.
시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 인덱스 컨테이너 > 핫 인덱스 > 너무 작은 버퍼 풀

인덱스 액세스는 일반적으로 바람직하다. 따라서 현 시점에서는 핫 인덱스를 디스크로부터 읽어야 하기보다는 버퍼 풀에 보관할 수 있는지 여부를 조사하는 것이 적절하다. 버퍼 풀 크기를 늘리거나 인덱스를 전용 버퍼 풀로 재배치하면 병목상태를 제거하기에 충분하도록 I/O를 감소시킬 수 있다. 인덱스가 큰 경우가 많은 데이터 웨어하우징 환경에서는 I/O를 줄이는데 사용할 수 있는 충분한 버퍼 풀 공간을 만드는 것이 불가능할 수도 있다. 그런 경우 컨테이너를 추가하여 디스크 I/O 대역폭을 향상시킴으로써 병목상태를 줄이는 것이 보다 효과적일 수 있다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 인덱스 컨테이너 > 핫 인덱스 > 핫 SQL 문
‘핫 테이블'을 확인했을 때 일어난 것처럼 튜닝을 통해서 인덱스 I/O 병목상태를 없앨 수 없는 경우 좀더 드릴다운하여 인덱스 I/O를 발생시키는 SQL문을 찾아야 할 수도 있다. 유감스럽게도 이전에 했던 것처럼 적어도 직접적이지 않게 SQL 문 텍스트를 조사할 수는 없다.사용량이 높은 것으로 나타나는 인덱스 이름을 사용하여 해당 인덱스에 상응하는 테이블을 확인한 다음 핫 테이블에 대해 위에서 설명한 테이블 이름과 메서드를 사용하여 해당 인덱스를 사용하고 있을 수 있는 동적 및 정적 SQL 문을 찾는다(테이블에 대한 참조가 인덱스를 사용했음을 의미한다는 보장은 없다). 그런 다음 db2exfmt를 사용하여 문에서 해당 인덱스를 사용했는지 여부를 확인해야 한다.시스템 병목상태 > 컨테이너 디스크 병목상태 > 핫 임시 테이블 스페이스 컨테이너
핫 컨테이너가 임시 테이블 스페이스에 속한 경우 다음 몇 가지 가능한 원인을 고려해야 한다.1. 임시 테이블 스페이스 I/O의 높은 레벨이 유출된 정렬로 인한 것인가이것은 정렬 작업이 지정된 메모리 내부 버퍼를 오버플로하여 임시 테이블 스페이스를 대신 사용해야 하는 경우이다. 정렬 시간과 유출된 정렬 스냅샷 모니터 요소가 높고 증가하는 경우 이로 인한 것일 수 있다. STMM은 이러한 종류의 상황을 방지하려고 시도한다. 하지만 sheapthres_shr과 sortheap을 제어하는 데 STMM을 사용하지 않는 경우 이 값을 수동으로 늘려야 할 수도 있다.2. I/O가 대량의 중간 결과로 인한 것인가이것은 많은 수의 임시 데이터 물리적 읽기 또는 쓰기를 통해 나타난다. 또한 초기에 테이블 스페이스 레벨 스냅샷 데이터에서 확인할 수 있다. 높은 임시 데이터 I/O의 증거가 있는 경우 동적 SQL 스냅샷 또는 정적 SQL 이벤트 모니터 데이터를 드릴다운하여 임시 버퍼풀 활동의 사용량을 높이는 개별 문을 찾는다.
STMM은 이러한 종류의 상황을 방지하려고 시도한다. 하지만 sheapthres_shr과 sortheap을 제어하는 데 STMM을 사용하지 않는 경우 이 값을 수동으로 늘려야 할 수도 있다.2. I/O가 대량의 중간 결과로 인한 것인가이것은 많은 수의 임시 데이터 물리적 읽기 또는 쓰기를 통해 나타난다. 또한 초기에 테이블 스페이스 레벨 스냅샷 데이터에서 확인할 수 있다. 높은 임시 데이터 I/O의 증거가 있는 경우 동적 SQL 스냅샷 또는 정적 SQL 이벤트 모니터 데이터를 드릴다운하여 임시 버퍼풀 활동의 사용량을 높이는 개별 문을 찾는다. 시스템 병목상태 > 컨테이너 디스크 병목상태 > 잘못된 구성
시스템 병목상태 > 컨테이너 디스크 병목상태 > 잘못된 구성
명백하게 확인할 수 있는 원인은 없지만 가끔 문제가 되는 위 유형의 컨테이너 중 하나를 병목상태로 확인했다고 가정해 보자. 핫 테이블, 핫 인덱스, 핫 SQL 문에도 문제가 없다. 이 경우 다음과 같이 조사할 만한 원인이 몇 가지 있다.
1. 테이블 스페이스에 ‘사용량이 꽤 높은' 테이블 또는 인덱스가 너무 많은가이들 중 개별적으로는 어느 것도 혼자서 병목상태를 발생시킬 만큼 사용량이 충분히 높지 않지만 집계 활동이 기본 디스크에 비해 너무 많을 수도 있다. 이를 해결할 방법 한 가지는 테이블과 인덱스를 여러 테이블 스페이스에 배분하는 것이다. 또 다른 방법은 기존 컨테이너와 다른 디스크에서 I/O 용량이 증가된 테이블 스페이스에 컨테이너를 더 많이 추가하는 것이다.2. 너무 많은 테이블 스페이스가 같은 디스크를 공유하는가이 경우 테이블 스페이스가 표면적으로는 개별적이지만 그럼에도 불구하고 이면에는 동일한 물리적 디스크를 사용하는 논리적 볼륨을 차지하는 경우 부주의하게 발생할 수 있다. 위에서처럼 이번에는 테이블이 아니라 전체 테이블 스페이스의 총 사용량이 문제일 수 있다. 이에 대한 논리적 해답은 하나 이상의 테이블 스페이스를 다른 디스크로 이동하는 것일 수 있다.컨테이너 디스크 병목상태에 대한 특정 원인을 찾지 않고 이와 같은 요점에 이른 경우 ‘조정할 수 있는 문제'를 대부분 효과적으로 제외시키고 문제가 된 테이블 스페이스에 추가 디스크 처리량 용량을 추가하여 성능을 향상시키는 것을 고려해야 한다.시스템 병목상태 > 로그 디스크 병목상태
컨테이너 디스크 병목상태는 보다 일반적이지만 로그 디스크 병목상태가 시스템 성능에 더 큰 영향을 미칠 수 있다. 이것은 느린 로그가 특정 테이블 또는 인덱스에만 영향을 미치는 것이 아니라 시스템에 있는 전체 INSERT, UPDATE 또는 DELETE 문을 방해할 수 있기 때문이다. 다른 유형의 디스크 병목상태에서와 같이 주요 증상은 iostat 또는 perfmon에 표시되는 높은 사용률(90% 이상)이다. 또한 로그 병목상태는 문 이벤트 모니터에서 긴 커밋 시간을 발생시키고 애플리케이션 스냅샷의 ‘commit active' 상태에 정상보다 높은 비율의 에이전트를 발생시킨다.로그 구성의 섹션에서 언급한 바와 같이 로그는 데이터베이스 작업을 수행하는 동안 ‘활성인' 어떤 것(예: 컨테이너 등)과도 디스크를 공유하지 않는다. 이것은 로그 병목상태의 경우에 확인할 첫 번째 사항 중 하나이다.로그에 자신의 디스크가 있는 경우 병목상태의 특성을 이해해야 한다.
iostat에 로그 장치가 초당 80-100 작업 이상을 수행하는 것으로 표시되고 평균 I/O 크기가 4KB인 경우 로그가 순수한 데이터 볼륨보다 I/O 작업에 의해 더 많이 사용됨을 보여 준다.다음은 여기에 영향을 주기 위한 여러 방법이다.
시스템 병목상태 > 로그 디스크 병목상태 > 많은 수의 로그 쓰기
로그 병목상태는 쓰여지는 데이터의 과도한 볼륨에 의해 발생될 수도 있다. 높은 장치 사용률과 함께 iostat에 로그 장치로 쓰기가 4KB보다 훨씬 크게 나타나는 경우 높은 트랜잭션 비율보다 데이터 볼륨이 보다 중요한 요소임을 보여준다.로그되는 데이터의 볼륨은 다음과 같이 줄일 수 있다.
시스템 병목상태 > 로그 디스크 병목상태 > 고용량의 로그된 데이터
로그 병목상태가 매우 높은 로그 쓰기 비율에 의한 것이건 쓰여지는 고용량의 데이터 볼륨으로 인한 것이건 간에 문제의 원인을 제거하는 것이 가능하거나 실제적이지 않은 경우가 많다. 로그 구성이 위에 기술된 우수 사례를 따랐는지 확인한 후 로그 RAID 어레이에 디스크를 추가하거나 전용 또는 업그레이드된 캐시 디스크 컨트롤러를 제공하여 로그 서브시스템의 용량을 증가해야 할 수 있다.시스템 병목상태 > 진단 경로 병목상태
db2diag.log가 있는 DB2 진단 경로에 디스크 쓰기를 과중하게 하면 정상적인 DB2 모니터링 기능이 이를 추적하지 못하기 때문에 격리하기 힘든 전체 시스템 성능 저하가 발생할 수 있다. 분할된 데이터베이스 환경에서는 모든 파티션이 일반적으로 NFS를 사용하여 네트워크를 통해 공유되는 동일한 진단 경로에 쓴다. 많은 수의 파티션에서 db2diag.log에 동시에 쓰면 네트워크와 I/O 로드를 높일 수 있을 뿐만 아니라 파티션간 동기화도 높일 수 있기 때문에 시스템 성능이 저하된다. 위의 구성 섹션에서 언급한 것처럼 이에 대한 간단한 솔루션은 각 파티션에 대해 전용 진단 경로(전용 db2diag.log 파일)를 사용하는 것이다.diaglevel 데이터베이스 매니저 구성 매개변수를 4로 설정하면 여러 요소로 진단 메시지의 양을 증가시켜서 특히 크게 분할된 데이터베이스 환경의 경우 성능에 중대한 영향을 미칠 수 있다. 성능의 급격한 저하는 DIAGPATH의 파일 시스템을 꽉 채움으로 인해 결과적인 시스템 지연으로 이어질 수 있다. 이를 방지하려면 DB2 진단 정보를 보관하거나 DB2 진단 정보를 위한 전용 파일 시스템을 할당하여 진단 파일 시스템에 사용 가능한 공간이 충분하도록 해야 한다.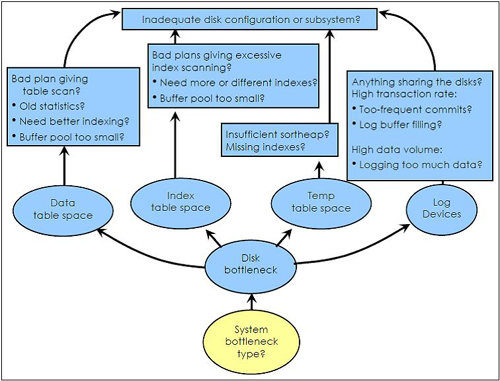 디스크 병목상태: 전체적인 그림
디스크 병목상태: 전체적인 그림
Thomas Rech:DB2 SAP Center of Excellence 선임 컨설턴트
Gang Shen:IBM Data Servers 기술 영업 전문가
Roman B. Melnyk:DB2 Information Development