DB2 튜닝 가이드 Part 8: 튜닝과 트러블슈팅(4) 시스템 지연
대부분의 DB2 시스템은 '성능 전개(performance evolution)' 과정을 거친다. 시스템을 배포한 후 시스템 모니터링을 하고, 만약 문제점이 발생되면 문제해결 과정을 거친다. DB2 튜닝 가이드는 단계별로 최상의 성능을 위한 최적의 설정을 제시함으로써, DB2 시스템 성능이 최상을 유지하도록 도와준다. 이번 회는 이 시리즈의 마지막 회로, 성능 튜닝과 트러블슈팅 과정 중 지연(Lazy) 시스템의 병목 상태에서의 해결 방안과 성능 관리에 대한 Best Practice 등을 살펴본다.<연재순서>
DB2 튜닝 가이드 - Part 1: 최상의 성능을 위한 시스템 구성
DB2 튜닝 가이드 - Part 2: 최상의 성능을 위한 DB 구성 (1)
DB2 튜닝 가이드 - Part 3: 최상의 성능을 위한 DB 구성 (2)
DB2 튜닝 가이드 - Part 4: 시스템 성능 모니터링
DB2 튜닝 가이드 - Part 5: 튜닝과 트러블슈팅(1) - 디스크 병목
DB2 튜닝 가이드 - Part 6: 튜닝과 트러블슈팅(1) - CPU 병목
DB2 튜닝 가이드 Part 7: 튜닝과 트러블슈팅(3) 메모리 병목
DB2 튜닝 가이드 Part 8: 튜닝과 트러블슈팅(4) 시스템 지연
시스템 병목상태 > 지연 시스템 > 불충분한 프리패치
대량의 데이터를 디스크에서 순차적으로 읽어야 하는 쿼리는 에이전트가 직접 데이터를 읽을 때보다 DB2 프리페처(prefetcher)가 데이터를 읽을 때 훨씬 더 효율적으로 실행된다. 이에 대한 이유는 다음과 같다.
- 프리페처는 한 번 읽을 때마다 여러 페이지를 가져온다. 이 때 크기는 데이터베이스 또는 테이블 스페이스 프리페치 크기로 제어된다. 반면 에이전트는 한 번에 페이지 한 개를 읽는다.
- 에이전트는 쿼리에 속하여 실행될 수 있지만 프리페처는 스스로 일을 처리하기 때문에 계산과 I/O의 일련화를 줄인다.
- 읽을 페이지의 범위에 여러 프리페처를 각각 할당할 수 있어 I/O 병렬 처리를 수행할 수 있다.
에이전트는 페이지의 범위에 있는 데이터가 필요할 때 프리페치 요청을 대기시킨다. 에이전트가 페이지를 사용할 시간이 되었지만 프리페처가 해당 페이지에 대한 I/O를 아직 시작하지 않은 경우, 즉 해당 페이지가 프리페처에서 요청조차 되지 않았거나 요청이 여전히 프리페치 큐에 있는 경우 에이전트가 직접 해당 단일 페이지를 읽는다. 이렇게 하면 에이전트가 프리페처를 기다려야 하는 빈도가 줄어든다(에이전트는 I/O가 실제로 진행중인 경우에만 대기한다). 하지만 에이전트 I/O를 사용해야 하는 경우 프리페치의 모든 장점이 사라진다.이러한 문제의 증상은 다음과 같다.
- 스캔이 많은 문에 대한 100% 이하의 ‘프리페치 비율'. (데이터베이스 또는 버퍼 풀 레벨에서는 스캔 기반이 아닌 총 활동의 부분에 따라 목표 값이 내려간다.) 이 메트릭은 버퍼 풀 적중률에도 마찬가지로 정의되지만 여기서는 다음과 같이 프리페처에 의해 수행된 물리적 읽기 수의 비율을 물리적 읽기의 총 수와 비교하여 계산한다.

이는 데이터베이스 레벨에서 SYSIBMADM.SNAPDB로, 버퍼 풀 레벨에서 SYSIBMADM.SNAPBP로,또는 동적 SQL 문 레벨에서 SYSIBMADM.SNAPDYN_SQL로 계산될 수 있다.
- 높고 증가하는 ‘프리페치 대기에 소요된 시간'. SYSIBMADM.SNAPDB와 SYSIBMADM.SNAPAPPL의 PREFETCH_WAIT_TIME에 나타난다. 위에서 언급한 것처럼 에이전트는 실제로 ‘실행중인' 프리페치 I/O만 기다린다.
- 다른 ‘지연 시스템' 문제에서와 같이 일반적으로 vmstat와 perfmon에 많은 양의 유휴 시간이 표시 된다. 하지만 단일 페이지를 읽는 에이전트는 큰 블록을 읽는 프리페처보다 훨씬 효율적이지 못하기 때문에 I/O 대기 시간의 증가도 나타날 수 있다. 그렇다 하더라도 I/O 대기가 병목상태로 나타날 만큼 높이 올라가는 경우는 별로 없다.
이러한 문제의 가장 가능한 원인은 프리페처의 수(데이터베이스 구성 매개변수 NUM_IOSERVERS)가 너무 낮은 것이다. DB2 버전 9.1 이상에서 사용할 수 있는 AUTOMATIC 설정은 예를 들어 프리페처의 수를 계산하는 데 테이블 스페이스 병렬 처리와 같은 요소를 사용하며 일반적으로 튜닝이 필요 없다. 하지만 낮은 프리페치 비율을 기반으로 튜닝이 필요한 것으로 나타나는 경우 다음과 같이 처리한다.
- 모든 프리페처가 비슷한 양의 CPU 시간을 사용하는지 확인한다. 이것은 UNIX 시스템에서 DB2 버전 9.1 이전의 경우 ps 명령을 사용하여 또는 DB2 버전 9.5 이상인 경우 db2pd edu를 사용하여 수행할 수 있다. 일부 프리페처가 다른 프리페처보다 CPU를 현저하게 덜 사용하는 경우는 이미 프리페처가 충분히 (또는 너무 많이) 있기 때문이다. ‘유휴' 프리페처가 여러 개 있는 경우 NUM_IOSERVERS를 약간 줄일 수 있지만 일반적으로 추가 프리페처가 있는 것은 문제가 되지 않는다.
- NUM_IOSERVERS를 10% 증가시킨다. 시스템에서 많은 수의 프리페처를 실행하게 한다. 프리페치 비율 또는 과중한 스캔 쿼리의 성능에 전혀 개선이 없으면 문제를 제대로 되돌려야 한다.
- 시스템에 대한 최적의 프리페처 레벨을 찾을 때까지 이 과정을 반복한다.
- 프리페칭이 표준 이하로 운영되는 것으로 나타나는 경우 PREFETCHSIZE가 제대로 설정되었는지 확인할 필요가 있다. 이에 대한 과정은 DB2 정보 센터에서 자세하게 설명되므로 여기서는 반복하지 않는다.
시스템 병목상태 > 지연 시스템 > 불충분한 페이지 정리
프리페칭과 마찬가지로 버퍼 풀 페이지 정리에 문제가 있으면 일반적으로 DB2 ‘작업자 스레드' 중 하나가 처리해야 하는 I/O를 수행하는 정상적인 처리를 인터럽트하기 위한 SQL 문을 에이전트가 실행하게 한다. 하지만 이 경우 에이전트는 읽는 대신 (수정된 페이지를) 써야 한다. 이것을 일반적으로 ‘dirty steal'이라고 부른다.버퍼 풀 페이지 정리 문제에 대한 증상은 위에서 설명한 ‘프리페칭 부족' 문제의 증상만큼 확실하게 결정되어 있지 않다. 잘못된 페이지 정리는 많은 DB2 에이전트가 동시에 작동하는 온라인 트랜잭션 처리(OLTP) 환경에서 주로 더 많이 문제가 된다. 에이전트가 정리된 버퍼 풀 페이지를 찾을 수 없어서 dirty steal을 해야 하는 경우 잠재적으로 매우 많은 추가 단일 페이지 쓰기가 컨테이너로 이동할 수 있다. 이 경우 일반적으로 유휴 ‘지연 시스템' 대신 I/O 병목상태가 나타날 수 있다. 이러한 일이 발생하는 정도는 예를 들어 연결 수와 페이지 정리 성능에 따라 다르다.관련된 증상은 vmstat에 표시되는 ‘버스트' 시스템 활동이다. 시스템이 짧은 시간동안 잘 실행되고 모든 에이전트가 정상적으로 작동하다가 대부분의 에이전트가 차단되고 dirty 페이지가 디스크로 플러시되는 기간으로 이어질 수 있다. 이것은 높은 I/O 대기와 vmstat의 비우기에 짧은(short-to-empty) 실행 큐로 나타난다. 에이전트가 dirty steal을 완료하면 성능 스파이크가 다시 회복되고 사이클이 반복된다.DB2의 모니터링 데이터에 있는 dirty page steal의 카운트(SYSIBMADM.SNAPDB의 POOL_DRTY_PG_STEAL_CLNS)는 이 문제를 가장 잘 나타낸다. 원만히 실행되는 시스템에서는 일반적으로 이러한 경우가 매우 적기 때문에 무시하지 못할 만큼 증가하는 숫자는 일부 문제의 원인일 수 있다.페이지 정리가 늦어지고 dirty steal이 발생하는 경우 확인해야 할 첫 번째는 페이지 클리너의 수(데이터베이스 구성 매개변수 NUM_IOCLEANERS)다. DB2 버전 9.1 이상 버전에서는 현재 파티션에서 프로세서당 한 개의 클리너라는 우수 사례를 따르는 AUTOMATIC 설정을 지원한다. DB2 버전 9.5의 경우 권장되는 수 이상의 추가 클리너를 사용하면 실제로 성능이 저하될 수 있다.DB2 데이터베이스 제품은 두 가지 유형의 페이지 정리, 즉 DB2 UDB 버전 8.2에 도입된 ‘클래식'한 리액티브 페이지 클리닝(Reactive page cleaning; 디폴트 설정값)와 프로액티브 페이지 클리닝(Proactive page cleaning)을 지원한다.
- 클래식 페이지 정리는 다음 두 데이터베이스 구성 매개변수로 제어된다.
- chngpgs_thresh: 페이지 정리를 활성화하는 수정된 버퍼 풀 페이지의 비율을 결정한다.
- Softmax: 버퍼 풀에서 가장 오래된 수정된 페이지의 기간(LSN 차이)을 제한하여 복구 시간을 제어한다.
- 이러한 매개변수 중 하나를 줄이면 일반적으로 정리가 좀더 되지만 chngpgs_thresh는 버퍼 풀에서 정리된 페이지의 수에 영향을 주기 위한 기본 방법이다. chngpgs_thresh를 감소시키면 dirty page steal의 수를 줄이고 고르지 않은 정리를 안정시킬 수 있다. 이 매개변수를 너무 낮게 설정하면 과도한 디스크 쓰기를 초래할 수 있으므로 dirty steal을 방지할 만큼만 낮게 설정해야 한다.
- 순리적인 페이지 정리(대체 페이지 정리 또는 APC로도 알려짐)는 레지스트리 변수 DB2_USE_ALTERNATE_PAGE_CLEANING을 사용하여 활성화된다. 이 정리는 원하는 LSN 차이를 유지하기 위해 정리 비율을 조정하는 면에서 클래식 페이지 정리와 다르다. 정리를 ‘켜기' 또는 ‘끄기, 또는 발생시키거나 발생시키지 않는 것이 아니라 APC는 클래식 페이지 정리에서 가끔 나타나는 ‘버스트' 동작을 방지하도록 해당 활동을 조절할 수 있다. 클래식 페이지 정리와 마찬가지로 softmax를 줄이면 정리 비율이 효과적으로 증가하고 dirty steal이 줄어 든다. APC는 chngpgs_thersh가 아닌 softmax에 의해서만 제어되므로 APC를 처음 활성화하는 DBA는 시스템이 이전에 효과적인 chngpgs_thresh를 기반으로 정리된 경우, 즉 dirty page 임계값이 발생하는 경우 softmax를 조정해야 할 수도 있다.
시스템 병목상태 > 지연 시스템 > 애플리케이션 측 문제
클라이언트 애플리케이션과 DB2 서버간의 요청과 응답에 대한 앞뒤 동기 흐름은 둘 모두가 전체 시스템의 성능에서 제 역할을 수행함을 의미한다. 예를 들어 일괄 처리 애플리케이션에서 런타임의 증가는 서버 측의 성능 저하 때문일 수도 있지만 애플리케이션이 DB2 데이터베이스에 요청하는 비율의 감소 때문일 수도 있다. 이러한 유형의 문제에 대한 서버 측 증상은 ‘지연 시스템' 틀에 잘 맞을 수 있다.DB2 데이터베이스에 요청이 도착하는 비율의 감소에 대한 증상은 다음과 같다. 애플리케이션의 ‘UOW 대기' 상태에서 증가된 에이전트 수(SYSIBMADM.SNAPAPPL_INFO의 APPL_STATUS). 이는 에이전트가 더 많은 작업을 위해 더 오래 대기함을 의미한다.
- 에이전트로 요청이 도착하는 사이의 증가된 시간(SYSIBMADM.SNAPAPPL_INFO의 STATUS_CHANGE_TIME)
- 문 이벤트 모니터 또는 CLI나 JDBC 추적에 표시되는 클라이언트에서 수행한 요청 사이의 증가된 시간. CLI와 JDBC 추적은 클라이언트 측에서 API 호출을 캡처하고 호출이 수행되면 타임스탬프를 기록한다. 클라이언트 측 추적을 위한 오버헤드가 높지만 타이밍에 네트워크 응답 시간 및 DB2 엔진 외부의 다른 요소가 포함된다는 이점이 있다.
- 만약 가능한 경우 비즈니스 레벨 트랜잭션 처리량 또는 응답 시간과 같은 애플리케이션 측 메트릭이 성능 저하를 나타낼 수 있다.
애플리케이션 측 성능 저하가 문제로 나타나는 경우 가능한 원인은 다음과 같다.
- 애플리케이션의 새로운 버전 배포
- 클라이언트와 서버간 네트워크 병목상태
- 클라이언트 시스템의 과도한 로드. 너무 많은 사용자 또는 너무 많은 애플리케이션 복사본이 실행중인 경우
>> 시스템 병목 전체 그림
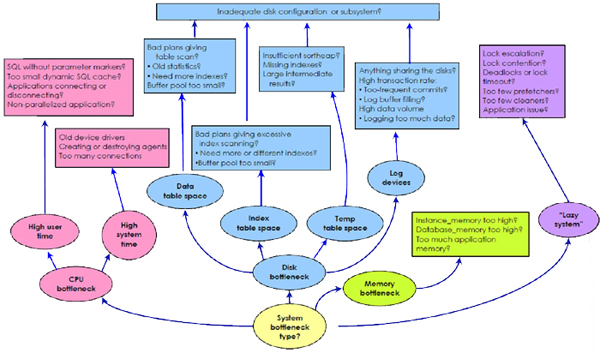
지엽적인 문제 해결과 시스템 전반 문제 해결
지금까지 시스템에 나타나는 성능 문제, 즉 최상위 디스크, CPU, 메모리, 지연 시스템 문제를 전체적으로 다뤘다. 하지만 성능 문제가 항상 이러한 형태로 발생하는 것은 아니다. 시스템이 전반적으로 잘 실행되지만 한 명의 사용자 또는 애플리케이션 한 개, 저장 프로시저 한 개 또는 SQL 문 한 개에 문제가 발생할 수도 있다. 시스템 전반의 성능 문제 처리와 지엽적인 문제를 처리하는 것은 어떻게 다를까다행히 이번 글에 포함된 성능 문제 해결에 대한 계통적인 접근 방법은 문제가 보편적이건 또는 보다 선택적이건 똑같이 적용될 수 있다. 다만 시스템에서 제공하는 많은 양의 모니터링 데이터에서 관련된 부분을 추출할 수 있어야 한다.애플리케이션이 기대 수준 이하로 수행된다고 가정해 보자. 진단 프로그램을 시작하기 전에 이 애플리케이션에서 일어나는 시스템의 활동을 확인할 수 있어야 한다.
- 애플리케이션이 실행중인 경우 애플리케이션의 이름과 인증 ID를 알면 LIST APPLICATIONS 명령을 사용하여 ‘appl ID'(예: LOCAL.srees.0804250311139)를 가져올 수 있다. 이 ID는 이 애플리케이션과 관련된 모니터 데이터를 확인하기 위한 키다.
- 애플리케이션 스냅샷은 애플리케이션 관련 모니터링 데이터의 훌륭한 소스다. appl ID를 지정하여 관심 있는 연결에 집중할 수 있다.
 여기에서 (또는 SYSIBMADM.SNAPAPPL, SYSIBMADM.SNAPAPPLINFO에서) 애플리케이션에 대한 많은 주요 정보를 확인할 수 있다. 이러한 정보는 예를 들어 스냅샷을 만들었을 때 실행된 문, 버퍼 풀 적중률, 정렬 시간의 양, 선택한 행과 읽은 행의 비율, CPU 시간, 경과 시간 등이다. 간단히 말하면 시스템 레벨 문제를 디버깅하는데 사용되는 것과 거의 같은 정보를 얻지만, 이 경우 관심 있는 애플리케이션의 정보에 초점을 맞춘다.
여기에서 (또는 SYSIBMADM.SNAPAPPL, SYSIBMADM.SNAPAPPLINFO에서) 애플리케이션에 대한 많은 주요 정보를 확인할 수 있다. 이러한 정보는 예를 들어 스냅샷을 만들었을 때 실행된 문, 버퍼 풀 적중률, 정렬 시간의 양, 선택한 행과 읽은 행의 비율, CPU 시간, 경과 시간 등이다. 간단히 말하면 시스템 레벨 문제를 디버깅하는데 사용되는 것과 거의 같은 정보를 얻지만, 이 경우 관심 있는 애플리케이션의 정보에 초점을 맞춘다.
- 좀더 깊게 들어가서 관심 있는 애플리케이션에 대해서만 보다 과중한 이벤트 모니터 데이터를 수집하도록 애플리케이션 ID를 문 이벤트 모니터의 WHERE 절에 인수로 사용한다. 이렇게 하면 애플리케이션에 대해 문별로 타이밍, 버퍼 풀 정보, CPU 소비 정보가 제공된다.
여러 애플리케이션 스냅샷 또는 이벤트 모니터 추적을 수집하고 나면 시스템 문제 전반의 해결에 사용할 수 있는 거의 같은 유형의 모니터링 데이터를 얻게 된다. 기본 목표는 애플리케이션의 어느 지점에서 시간을 대량으로 소비했는지 확인하는 것이다.즉, 정확하게 어디가 병목 상태인가 애플리케이션의 어떤 SQL 문이 가장 오래 실행되는가 어떤 문이 대부분의 CPU를 소비하는가 또는 대부분의 물리적 디스크 I/O를 사용하는가 이러한 질문에 대한 대답은 시스템 전반 결정 트리의 초기 단계와 같다.문제가 된 SQL 문을 하나 이상 확인하고 발생한 종류의 병목상태가 어떤 것인지 알고 나면 이전 섹션에서 설명한 것과 같은 방법을 적용할 수 있다. 특히 여기에는 ‘핫 SQL 문', 핫 테이블 등 지엽적인 문제와 연관된 요소를 드릴 다운하는 것과 관련된 기술이 포함된다.
Best Practice
설정
- 스핀들 수 측면에서 적절한 디스크 용량을 확보한다.
- 트랜잭션 로그를 전용 디스크에 배치한다.
- 300GB 이상인 데이터 웨어하우징 배포에 대해 DB2 데이터 분할 기능을 사용한다.
- 유니코드를 사용하면서 최적의 성능을 내려면 언어 인식 데이터 정렬을 고려한다.
- SAP과 같은 ISV 애플리케이션의 경우 공급업체의 구성 권장사항을 따른다.
- AUTOCONFIGURE 명령을 사용하여 최상의 초기 구성 설정을 가져온다.
- STMM과 기타 자율 매개변수는 안정성과 강력한 성능을 제공한다.
- 분할된 데이터베이스 환경인 경우 DIAGPATH에 대해 NFS 마운트된 파일 시스템 보다는 로컬 파일 시스템을 사용한다.
모니터링
- 문제가 발생하는 경우 배경 정보를 사용할 수 있도록 기본 운영 모니터링 데이터를 정기적으로 수집한다.
- 관리 뷰를 사용하여 모니터링 데이터를 SQL로 액세스하고 조작한다.
- CPU 사용과 애플리케이션 레벨 응답 시간과 같은 DB2가 아닌 메트릭을 모니터링한다.
- 구성 또는 환경 설정의 변경사항을 추적한다.
문제 해결
- 계통적이 된다. 한 번에 한 가지만 변경하고 신중하게 결과를 관찰한다.
- 최상위 증상(예: CPU, 디스크 또는 메모리 병목상태)에서 시작하며 있음직하지 않거나 불가능한 원인을 초기에 제외시킨다.
- 각 단계별로 세분화하여 가능한 원인을 드릴다운한다. 예를 들어 I/O 병목상태는 컨테이너 C로 연결되고, 컨테이너 C가 테이블 T로, 테이블 T가 비효율적인 문 S로 이어질 수 있다.
- ‘예감'만으로 시스템을 변경하지 않는다. 해결하려는 문제가 현재 나타난 증상을 어떻게 발생시킬 수 있었는지 이해한다.
- 시스템 전반 문제와 보다 지엽적인 문제 모두에 대해 동일한 하향식의 계통적 접근 방법을 사용한다.
결론
이번 튜닝 가이드에서는 시스템의 성능 저하를 방지하려는 경우 이해해야 하는 세 가지 주요 영역인 구성, 모니터링, 성능 문제 해결을 살펴보았다.최상의 시스템 성능을 보장하기 위한 하드웨어와 소프트웨어 구성 관련 권장사항이 언급되었으며 운영 상황과 문제 해결 상황 모두에서 시스템 성능을 이해하는데 도움이 되는 여러 모니터링 기술을 설명했다. 또한 단계별 계통적 방법으로 문제를 처리하기 위한 여러 DB2 성능 문제 해결 우수 사례를 소개했다.시스템이 적절하게 구성되고 제대로 모니터링되면 발생할 수 있는 성능 문제를 보다 효과적으로 해결할 수 있으며 이에 따라 총소유비용(TCO)을 줄이고 잠재적으로 비즈니스의 투자수익률(ROI)을 높일 수 있다.
필자소개
Steve Rees:DB2 성능 품질관리 선임 매니저
Thomas Rech:DB2 SAP Center of Excellence 선임 컨설턴트
Gang Shen:IBM Data Servers 기술 영업 전문가
Roman B. Melnyk:DB2 Information Development
출처 : KDUG (http://www.kdug.kr/)제공 : DB포탈사이트 DBguide.net
