
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
함수형 프로그래밍 F# 예측 가능한 수학적 함수 구현하기 ‘변경 불가능성(Immutability)’은 함수형 언어의 핵심 개념이다. 데이터를 변경하지 않음으로써 명령형 언어에 비해 좀 더 쉽게 예측 가능한 함수를 구현할 수 있다. 이번 시간에는 참조 투명성(Referential Transparency)과 부작용(Side-Effect) 그리고 순수 함수(Pure Function)의 개념을 살펴보고, 수학적 함수로 인한 최적화와 데이터 레이스, 데드락을 제거하는 방법을 소개한다. 예측 가능한(Predictable) 코드를 작성한다는 것은 무엇을 의미할까 그리고 왜 필요할까 국립국어원 표준국어대사전은 ‘예측(豫測)’의 뜻을 “미리 헤아려 짐작함”이라고 기술하고 있다. 비슷한 말로는 예상, 예견, 짐작, 추측, 추리, 지레짐작 등이 있다. 우선 중앙 처리 장치(Central Processing Unit, 이하 CPU)의 입장에서 예측을 살펴보자. CPU에는 예측과 관련된 대표적인 기술 중 하나로 ‘분기 예측(Branch Prediction)’이 있다. 요약하면 분기 예측은 다음 분기를 예측하는 것이다. 왜 다음 분기를 예측할까 이 질문에 대한 답변은 매우 단순하다. CPU의 고속화를 위해서다.
<리스트 1> PlusOne 함수int PlusOne(int value) <리스트 1>과 같이 PlusOne이 구현돼 있다면 PlusOne 함수의 입력 값 value가 2015일 때 호출 순서나 외부 환경과 상관없이 항상 같은 결과 값 2016을 돌려주게 된다. 이러한 성질을 다음과 같이 정의할 수 있다.
<리스트 2> 최적화 전 <리스트 2>를 앞서 살펴본 개념으로 접근해 보자. 우선 ‘int result = PlusOne(x) + PlusOne(x) * (PlusOne(x) - PlusOne(x));’에서 ‘PlusOne(x) = PlusOne(x)’가 성립한다면 ‘PlusOne(x) PlusOne(x)’는 0이 될 것이다. 그렇다면 ’PlusOne(x) PlusOne(x)’를 ‘0’으로 바꿔도 전체 구문에 의미가 변하지 않는다. 이제 전체 구문은 ‘int result = PlusOne(x) + PlusOne(x) * (0);’으로 변경할 수 있다.
<리스트 3> 최적화 후int result = PlusOne(x) + PlusOne(x) * (PlusOne(x) PlusOne(x)); 코드를 변경하는 과정을 통해 필수 조건은 입력 값 x에 같은 값을 주면 PlusOne 결과 값 역시 항상 같다는 것을 알 수 있다. 이를 바탕으로 ‘PlusOne(x) = PlusOne(x)’가 성립하게 되며, ‘PlusOne(x) - PlusOne(x)’가 0으로 대체될 수 있다. 이는 ‘(PlusOne(x) - PlusOne(x)) = 0’이 성립하기 때문에 가능한 것이다. 그 이후 코드를 변경하는 과정에서도 역시 ‘(PlusOne(x) * 0) = 0’과 ‘(PlusOne(x) + 0) = PlusOne(x)’가 성립한다. 이는 수학적 상식에 기반을 두고 코드를 최적화할 수 있음을 의미한다. 좀 더 간단한 예제 <리스트 4>를 통해 다른 최적화 방법을 살펴보자.
<리스트 4> 최적화 전int result = PlusOne(x) * PlusOne(x) <리스트 4>의 코드는 현재 PlusOne을 중복 호출하고 있다. PlusOne이 ‘value에 같은 값을 주면 PlusOne 함수는 항상 같은 결과를 돌려준다’를 준수하고 있다면 PlusOne(x)를 한 번만 호출해 그 결과를 저장한 후 temp 변수로 동일한 결과를 얻을 수 있다. 이번 예제는 함수를 변수로 대체해 결과 값을 저장하고 중복 호출 없이 PlusOne 함수를 한 번의 호출로 최적화한다.
<리스트 5> 최적화 후int temp = PlusOne(x); 두 가지 최적화 예제 모두 PlusOne(x) 함수의 결과 값을 예측할 수 있었다. 이는 CPU에서 제공하는 분기 예측과 달리 예측 실패가 존재하지 않기 때문에 가능한 것이다. 이러한 성질 덕분에 ①함수를 값이나 변수로 바꿔도 전체 구문에 의미가 변하지 않으며, ②수학적으로 최적화할 수 있다. 이와 같은 성질을 갖는 함수를 참조에 투명(Referentially Transparent)한 함수라고 한다. 또한 참조에 투명한 함수는 입력 값에 따라 결과 값이 결정되기 때문에 결정 함수(Deterministic Function)라고 한다. 이에 상반되는 개념은 참조에 불투명(Referentially Opaque)한 함수 또는 비결정 함수(Non-deterministic Function)라 한다. 참조에 불투명한 함수는 동일한 입력 값에도 불구하고 결과 값이 항상 같지 않다.
<리스트 6> 참조에 불투명한 함수int globalValue = 0;int PlusOne(int value) 그 때문에 입력 값 value가 같아도 결과 값이 항상 같지 않게 된다. 예를 들어, PlusOne(2015)를 중복해서 호출하면 처음에는 2016, 다음에는 2017을 돌려주게 된다. 이는 ‘PlusOne(2015) = PlusOne(2015)’가 성립될 수 없게 된다. 또한 ‘((PlusOne(2015) - PlusOne(2015)) = 0’ 역시 성립하지 않는다.
<리스트 7> 데이터 레이스using System; <리스트 7>의 코드를 컴파일해 실행하면 결과 값이 항상 같지 않다. WorkThreadJob1 함수와 WorkThreadJob2 함수에 부작용이 있기 때문이다. 그러므로 참조에 투명하지도 않다. <리스트 7>의 데이터 레이스 발생 과정을 좀 더 자세히 확인하기 위해 Sleep 함수와 화면 출력 함수를 추가한 후 데이터 레이스 발생 과정을 살펴보자(<리스트 8> 참조).
<리스트 8> 데이터 레이스 발생 과정 확인하기using System; <리스트 8>의 코드를 컴파일해 실행하면 <그림 1>과 같이 데이터 레이스 발생 과정을 확인할 수 있다. ‘Work Thread1’에서 count 값을 읽은 후에 ‘Work Thread2’에서도 count 값을 읽고 연산(count++) 후 count 값을 변경시킨다. 그러나 ‘Work Thread1’에서는 ‘Work Thread2’에서 변경된 count 값을 확인하지 못하고 이전 값으로 연산해 count 값을 변경시키기 때문에 올바른 count 값을 얻지 못한다. 그 결과 ‘6’이라는 잘못된 결과 데이터를 얻게 된다.
<리스트 9> 동기화를 통한 데이터 레이스 제거하기using System; <리스트 9>의 실행 결과는 <그림 2>와 같이 데이터 레이스가 제거돼 항상 같은 결과 값을 얻게 된다. WorkThreadJob1과 WorkThreadJob2 함수는 부작용이 근본적으로 존재하지만, 이를 동기화로 제거하고 있다. 부작용은 동기화를 통해 제거할 수 있지만, 이러한 데이터 레이스 문제는 발견하기도 재현하기도 쉽지 않다. <리스트 10> 데드락using System; <리스트 10>을 실행하면 <그림 3>과 같이 WorkThreadJob1과 WorkThreadJob2 모두 임계 영역에 해당하는 코드 블록을 절대 호출하지 않는다. 서로 임계 영역이 끝나기만을 기다리고 있어 결과적으로 프로그램은 더는 진행하지 않게 된다. 데드락은 동기화를 위해 임계 영역을 들어가기 위한 무한 기다림으로 발생한다. 데드락을 해결하기 위해서는 어느 한쪽 스레드에서 기다림을 포기해야 한다. 근본적인 해결책은 당연히 데드락이 발생하지 않도록 하는 것이다. 대표적으로 타이머를 이용하는 방법이 있다. 임계 영역에 들어가기 위한 대기 시간을 설정함으로써 지정한 시간이 초과하면 기다림을 포기하도록 하는 것이다.
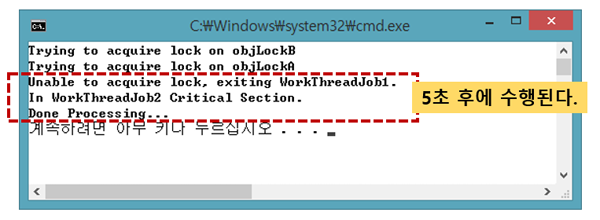
<리스트 11> 타이머를 통한 데드락 제거using System; Monitor 클래스에 제공하는 TryEnter 함수를 통해 <그림 4>와 같이 5초 이후에는 WorkThreadJob2 함수가 수행되는 것을 확인할 수 있다.함수형 프로그래밍 F# : 예측 가능한 수학적 함수 구현하기
CPU에는 조건 분기 명령이 있는데, 이는 분기로 인해 명령어 파이프라인이 일시적으로 정지되는 상황을 제거함으로써 성능을 향상하는 것이다. 분기 예측은 해당 조건 분기문이 분기한 이력이나 루프 구조, 함수 구조 등의 정보를 기반으로 수행한다. 그 때문에 분기 예측이 항상 정확한 것은 아니다. 이번에는 코드 입장에서 예측을 살펴보자.
{
return value + 1;
}
“함수의 인자 value 값이 변하지 않는다면 PlusOne 함수는 항상 같은 결과를 돌려준다.”
이 정의를 활용하면 ‘PlusOne(2015) = PlusOne(2000 + 15) = 2016’이 성립하게 된다. value로 전달된 값 2015와 2000 + 15가 같기 때문이다. 이를 좀 더 활용하면 ‘(PlusOne(2015) - PlusOne (2015)) = 0’도 역시 성립하게 된다.
int result = PlusOne(x) + PlusOne(x) * (PlusOne(x) PlusOne(x));
변경된 코드에서 ‘PlusOne(x) * (0)’은 수학적 상식을 고려할 때 당연히 0으로 변경할 수 있다. 이를 다시 적용하면 ‘int result = PlusOne(x) + 0;’이 된다. 결국 ‘int result = PlusOne(x);’로 변경할 수 있다. 지금까지의 코드 변경 과정을 정리하면 <리스트 3>과 같다.
→ int result = PlusOne(x) + PlusOne(x) * (0);
→ int result = PlusOne(x) + 0;
→ int result = PlusOne(x);
int result = temp * temp;
<리스트 6>에 구현된 PlusOne 함수는 함수의 외부 globalValue 변수 값을 변경시킨(write) 후에 해당 변수의 값을 참조해 결과 값을 만든다.
{
globalValue = globalValue + 1;
return value + globalValue;
}
이를 통해 앞에서 살펴본 최적화 예제 2개 모두 <리스트 6>에서 구현한 참조에 불투명한 함수 PlusOne이라면 해당 사항이 없을 것이다. 참조에 불투명한 함수는 최적화할 기회 자체가 줄어들 것이며, 수학적으로 함수를 다루기도 어렵다. 또 함수 외부 데이터를 변경시키므로 의도하지 않는 결과를 발생시킬 수 있다. 이처럼 함수 결과 값 외에 함수 외부에 있는 상태를 변경시키는 걸 ‘부작용(Side-Effect)이 있다’고 말한다. 부작용은 다음과 같이 대표적으로 네 가지 경우에 발생한다.
1. 함수 외부의 변수를 변경시킬 때(예: 전역 변수, 정적 변수)
2. 함수 인자를 변경할 때(예: 참조 변수)
3. 화면이나 파일에 데이터를 쓸 때
4. 다른 부작용이 있는 함수의 결과를 참조할 때
참조에 불투명한 함수는 대개 부작용이 있다. 그러나 부작용이 없다고 해서 모두 참조에 투명한 함수는 아니다. 가령 현재 시간을 돌려주는 함수가 있다고 가정해 보자. 해당 함수는 외부 데이터를 전혀 변경시키지 않지만(부작용이 없지만) 해당 함수를 호출할 때마다 시간이라는 전역 상태 변경으로 인해 매번 다른 결과 값을 돌려줄 것이다.
C#, Java, C++와 같은 명령형 언어들은 부작용을 사용해 프로그래밍하게 된다. 그러나 F#, Scala, Haskell과 같은 함수형 언어들은 부작용을 최소화해 프로그래밍한다. 특히 함수형 언어에서는 부작용이 없으며, 참조에 투명한 함수를 ‘순수 함수(Pure Function)’라고 한다. 순수 함수는 참조에 투명하므로 예측이 가능하다. 그 덕분에 함수를 값이나 변수로 대체할 수 있어 명령형 프로그래밍보다 더 많은 최적화 기회를 얻을 수 있다. 또 함수를 수학적으로 다룰 수 있어 정확성 증명이 쉬워짐으로 테스트와 디버깅에도 용이하다.
부작용이 없으므로 함수 내부 구현에서 필요한 지역 변수와 결과 값 외에는 외부에 영향을 주지 않는다. 이는 함수가 원자적(Atomic) 성질을 갖게 돼 특정 기능을 함수 단위로 완료하도록 설계를 강요한다. 이는 코드의 가독성과 유지 관리 편의성을 향상하게 된다. 객체지향 설계 원칙에서 바라보면 함수 단위로 단일 책임 원칙(SRP, Single Responsibility Principle)을 준수하게 된다. 함수형 언어는 이러한 성질을 갖는 함수 구현을 언어 차원에서 지원하고 강요한다.
이 모든 특징은 예측 가능한 함수로부터 시작됐다. 예측 가능한 함수를 만들기 위해서는 부작용이 존재해서는 안 된다. 부작용은 결국 외부에 영향을 주지 않는 것이다. 이를 좀 더 구체적으로 코드 수준으로 해석하면, 한 번 초기화된 데이터는 변경시키지 않는 것이다. 이러한 특징에 기인해 함수형 언어는 변경 불가능성(Immutability)이라는 프로그래밍 모델에 뿌리를 두고 있다. 이론적으로는 람다 대수에 근간을 두고 있다.
2005년 이후 멀티 코어로 CPU가 발전하면서 병렬 프로그래밍은 필수 사항이 되고 있다. 그러나 다양한 병렬 라이브러리를 사용하는 것만으로 성능 향상을 기대하기가 쉽지 않다. 그 이유는 병렬 라이브러리의 문제라기보다는 명령형 언어가 지향하고 있는 데이터 변경 프로그래밍 모델에 있다. 데이터 변경으로 인한 대표적인 문제 중 하나는 데이터 레이스(Data Race)다.
using System.Threading;namespace DataRace
{
class Program
{
static int count = 0;
static void Main()
{
Thread workThread1 = new Thread(WorkThreadJob1);
Thread workThread2 = new Thread(WorkThreadJob2);
workThread1.Start();
workThread2.Start(); workThread1.Join();
workThread2.Join(); Console.WriteLine ("Final count: {0}", count);
} static void WorkThreadJob1()
{
for (int i = 0; i < 5; i++)
{
count++;
}
} static void WorkThreadJob2()
{
for (int i = 0; i < 5; i++)
{
count++;
}
}
}
}
using System.Threading;namespace DataRace_in_Detail
{
class Program
{
static int count = 0; static void Main()
{
Console.WriteLine("Work Thread1\t\t\tWork Thread2");
Console.WriteLine("========================================================="); Thread workThread1 = new Thread(WorkThreadJob1);
Thread workThread2 = new Thread(WorkThreadJob2);
workThread1.Start();
workThread2.Start(); workThread1.Join();
workThread2.Join(); Console.WriteLine("=========================================================");
Console.WriteLine("Final count: {0}\n", count);
} static void WorkThreadJob1()
{
for (int i = 0; i < 5; i++)
{
int tmp = count;
Console.WriteLine("Read count={0}", tmp);
Thread.Sleep(50);
tmp++;
Console.WriteLine("Incremented tmp to {0}", tmp);
Thread.Sleep(20);
count = tmp;
Console.WriteLine("Written count={0}", tmp);
Thread.Sleep(30);
}
} static void WorkThreadJob2()
{
for (int i = 0; i < 5; i++)
{
int tmp = count;
Console.WriteLine("\t\t\t\tRead count={0}", tmp);
Thread.Sleep(20);
tmp++;
Console.WriteLine("\t\t\t\tIncremented tmp to {0}", tmp);
Thread.Sleep(10);
count = tmp;
Console.WriteLine("\t\t\t\tWritten count={0}", tmp);
Thread.Sleep(40);
}
}
}
}
이러한 데이터 레이스 문제는 동기화를 통해 해결할 수 있다. 동기화를 구현하는 방법은 매우 다양하다. <리스트 9>는 C#에서 제공하는 lock 키워드를 사용해 데이터 레이스를 해결한다. lock은 C#에서 제공하는 키워드 가운데 가장 쉽게 동기화를 구현하는 방법이다. lock 키워드 블록은 임계 영역(Critical Section)으로 처리되며, 특정 스레드가 임계 영역에 있는 동안 다른 스레드는 lock 블록이 해제될 때까지 대기한다. lock 블록이 해제되면 다른 스레드가 임계 영역에 들어갈 수 있게 된다. 이를 통해 데이터 변경과 관련된 작업을 상호 배타적(Mutual-Exclusion)으로 수행할 수 있다.
using System.Threading;namespace DataRace_Solution_byLock
{
public class Test
{
static int count = 0;
static readonly object countLock = new object(); static void Main()
{
Console.WriteLine("Work Thread1\t\t\tWork Thread2");
Console.WriteLine("========================================================="); Thread workThread1 = new Thread(WorkThreadJob1);
Thread workThread2 = new Thread(WorkThreadJob2);
workThread1.Start();
workThread2.Start(); workThread1.Join();
workThread2.Join(); Console.WriteLine("=========================================================");
Console.WriteLine("Final count: {0}\n", count);
Console.WriteLine("Final count: {0}", count);
} static void WorkThreadJob1()
{
for (int i = 0; i < 5; i++)
{
lock (countLock)
{
int tmp = count;
Console.WriteLine("Read count={0}", tmp);
Thread.Sleep(50);
tmp++;
Console.WriteLine("Incremented tmp to {0}", tmp);
Thread.Sleep(20);
count = tmp;
Console.WriteLine("Written count={0}", tmp);
}
Thread.Sleep(30);
}
} static void WorkThreadJob2()
{
for (int i = 0; i < 5; i++)
{
lock (countLock)
{
int tmp = count;
Console.WriteLine("\t\t\t\tRead count={0}", tmp);
Thread.Sleep(20);
tmp++;
Console.WriteLine("\t\t\t\tIncremented tmp to {0}", tmp);
Thread.Sleep(10);
count = tmp;
Console.WriteLine("\t\t\t\tWritten count={0}", tmp);
}
Thread.Sleep(40);
}
}
}
}

더욱이 동기화로 인해 성능 향상에 큰 장애를 초래하는 경우도 많다. 그래서 대부분 병렬 라이브러리들은 성능 장애를 최소화는 아주 가벼운 동기화 기능을 제공한다. 또 동기화로 인해 데드락(Deadlock)이라는 새로운 문제가 발생할 수 있다. 데드락은 ‘2개 이상의 작업이 상대방의 작업이 끝나기만을 기다리다가 결과적으로 아무것도 완료하지 못하는 상태’를 의미한다. <리스트 9>에서 부작용을 해결하기 위해 사용한 동기화 lock 키워드로 데드락이 발생하는 예를 살펴보자(<리스트 10> 참조).
using System.Threading;namespace Deadlock
{
class Program
{
private static object objLockA = new Object();
private static object objLockB = new Object(); public static void Main()
{
Thread workThread1 = new Thread(WorkThreadJob1);
Thread workThread2 = new Thread(WorkThreadJob2); workThread1.Start();
workThread2.Start(); workThread1.Join();
workThread2.Join(); Console.WriteLine("Done Processing...");
} private static void WorkThreadJob1()
{
lock (objLockA)
{
Console.WriteLine("Trying to acquire lock on ObjLockB"); Thread.Sleep(1000);
lock (objLockB)
{
// 데이터 변경 영역, 그러나 절대 호출되지 않는다.
Console.WriteLine("In WorkThreadJob1 Critical Section.");
}
}
} private static void WorkThreadJob2()
{
lock (objLockB)
{
Console.WriteLine("Trying to acquire lock on ObjLockA");
lock (objLockA)
{
// 데이터 변경 영역, 그러나 절대 호출되지 않는다.
Console.WriteLine("In WorkThreadJob2 Critical Section.");
}
}
}
}
}
<리스트 11>은 Monitor 클래스에서 제공하는 ‘public static bool TryEnter(object obj, int millisecondsTimeout);’ 정적 멤버 함수를 사용했다. 5초를 기다리고 그 안에 임계 영역에 들어갈 수 없다고 판단되면 임계 영역 진입을 포기할 것이다.
using System.Threading;namespace Deaklock_Solution_byTime
{
class Program
{
private static object objLockA = new Object();
private static object objLockB = new Object(); public static void Main()
{
Thread workThread1 = new Thread(WorkThreadJob1);
Thread workThread2 = new Thread(WorkThreadJob2); workThread1.Start();
workThread2.Start(); workThread1.Join();
workThread2.Join(); Console.WriteLine("Done Processing...");
} private static void WorkThreadJob1()
{
lock (objLockA)
{
Console.WriteLine("Trying to acquire lock on objLockB");
Thread.Sleep(1000);
if (Monitor.TryEnter(objLockB, 5000))
{
try
{
Console.WriteLine("In WorkThreadJob1 Critical Section.");
}
finally
{
Monitor.Exit(objLockB);
}
}
else
{
Console.WriteLine("Unable to acquire lock, exiting WorkThreadJob1.");
}
}
} private static void WorkThreadJob2()
{
lock (objLockB)
{
Console.WriteLine("Trying to acquire lock on objLockA");
lock (objLockA)
{
Console.WriteLine("In WorkThreadJob2 Critical Section.");
}
}
}
}
}
데이터 레이스는 데이터 변경 때문에 발생하는 문제이며, 이를 해결하고자 동기화를 도입했다. 그러나 동기화는 데드락이라는 새로운 문제를 유발할 수 있다. 문제 해결 방법이 새로운 문제를 낳는 웃지 못할 상황이 발생한 것이다. 이러한 문제들은 모두 데이터 변경으로 인해 발생한다. 멀티 코어와 매니 코어로 발전하는 과정에서 데이터 변경으로 로직을 작성하게 되면 이러한 문제들이 더욱 빈번하게 생겨날 것이다. 이를 해결하기 위한 노력과 시간 역시 필요하다는 얘기다. 그렇다면 이러한 문제를 근본적으로 해결할 수 없을까 데이터 레이스와 데드락 같은 문제가 존재할 수 없도록 할 수는 없을까 동기화가 없는 프로그래밍 모델은 없을까
이러한 문제의 근본적인 원인은 데이터 변경으로부터 발생하는 부작용이다. 함수형 언어는 기본적으로 데이터 변경을 제공하지 않기 때문에 데이터 레이스 문제 자체가 발생하지 않는다. 동기화 역시 함수형 언어에서는 주요 관심사가 될 수 없다. 동기화가 제거되기 때문에 자연스럽게 데드락 또한 해결된다. 함수형 언어가 최근 들어 주목받고 있는 이유 중 하나다.
함수형 언어에서는 데이터 변경으로 발생하는 문제들을 고민할 필요가 없다. 그러나 이러한 프로그래밍 모델이 장점만 있는 건 아니다. 데이터 변경 불가능성으로 인해 초래하는 애로 사항 역시 존재한다. 그러나 데이터 변경 불가능성으로 인해 함수의 인자 값이 변하지 않는다면 함수는 항상 같은 결과를 돌려주고(참조 투명성), 결과 값 외에는 함수 외부에 영향을 미치지 않기 때문에 의도하지 않는 결과를 발생시키지 않으므로(부작용이 없다) 결과를 예측할 수 있는 함수(순수 함수)가 된다. 이러한 예측 가능한 함수는 수학적으로 다를 수 있어 좀 더 많은 최적화 기회와 정확성을 얻는다.