
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
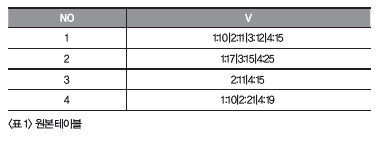
◎ 연재기사 ◎ 퀴즈로 배우는 SQL 구분자로 나누어 행,열 바꾸기 이번 퀴즈로 배워보는 SQL 시간에는 구분자로 데이터를 분할하고, 행과 열을 바꾸어 출력하는 SQL 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다. 진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결한 다음 정답과 해설을 참조하길 바란다. 공부를 잘하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 기억하자. <리스트 1> 의 원본테이블에서 <리스트 2>의 결과를 출력하는 SQL을 작성하세요.
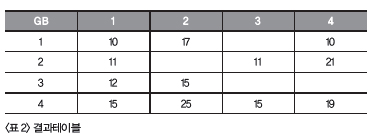
<리스트 1> 원본리스트WITH t AS <리스트 1>은 행번호(NO)별 데이터(V) 값을 관리하는 테이블입니다. 이 테이블에 저장되는 값은 정규화가 돼 있지 않아 하나의 컬럼에 여러 개의 값을 한꺼번에 저장합니다. 저장형식은 ‘구분(GB):값’ 형태의 여러 개의 값이 구분자 ‘|’ 으로 구분돼 연결된 형식으로 저장됩니다. 이 때, 행번호(NO)와 구분번호(GB)의 값은 4가지 값(1, 2, 3, 4) 고정입니다. 행번호(NO)에 해당하는 구분 값은 4가지 값이 모두 있지 않을 수도 있습니다. <리스트2>는 구분번호(GB)가 앞으로 오고 행번호가 옆으로 가는 형태로 표현됩니다. 문제를 스스로 해결했나요 이제 정답을 알아보겠습니다.
<리스트 2> 정답 리스트SELECT * 어떤가요 여러분이 만들어본 리스트와 같은가요 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다. 이번 문제는 다가 속성을 가진 비정규화 컬럼의 값을 분리해 내고, 분리한 결과 값을 행과 열을 전환해 출력하는 문제입니다. 차근차근 단계별로 접근해 보도록 하겠습니다. 첫 번째 단계는 구분자를 이용한 데이터 분할입니다. 구분자의 위치를 파악하는데는 INSTR 함수를 이용할 수 있습니다. 문자를 잘라내는 함수는 SUBSTR입니다. 두 가지 함수를 이용해 문자열을 분리하겠습니다.
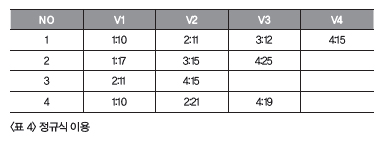
<리스트 3> INSTR 을 이용한 문자열 분리 시도SELECT no <리스트 3>의 쿼리를 통해 <표 3>의 결과를 얻었습니다. 그런데 결과가 이상합니다. 네 개 구분이 모두 있는 1번 자료를 제외한 나머지 자료의 결과가 틀렸습니다. 쿼리도 상당히 복잡하고 이해하기도 어렵습니다. 이렇게 반복되는 문자 패턴을 잘라낼 때 유용한 것이 바로 정규식 이용입니다. 정규식을 이용해 보도록 하겠습니다.
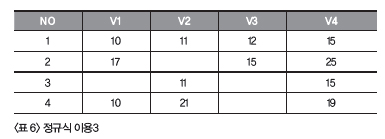
<리스트 4> 정규식 이용SELECT no <리스트 4>에서는 정규식 함수인 REGEXP_SUBSTR 을 이용해 데이터를 분리했습니다. ‘[^|]+’는 |가 아닌 문자열이 여러개 반복되는 형태를 표현합니다. 다르게 표현하면 구분자인 | 사이의 값을 의미합니다. (1, 1)은 첫 번째 자리부터 검색해 첫 번째 값을 찾으라는 의미입니다. 마지막 숫자를 바꿔가면서 네 개의 값을 구한 것입니다.
<리스트 5> 정규식 이용2SELECT no <표 5>에서는 구분별로 컬럼이 나뉘었습니다. 구분별로 컬럼이 나뉘었으므로 콜론(:) 앞의 구분은 없애도 의미가 손상되지 않습니다.
<리스트 6> 정규식 이용3SELECT no <리스트 6>의 쿼리를 통해 데이터 분할이 완성됐습니다. 이번에는 행과 열이 서로 뒤바뀌어야 합니다. 열을 행으로 바꾸고, 다시 또 행을 열로 바꾸어야 합니다.
<리스트 7> 열을 행으로SELECT no <리스트 7> 에서는 CONNECT BY LEVEL < = 4를 이용해 네 개의 GB를 만들어내고
<리스트 8> UNPIVOT SELECT * <리스트 8> 에서 UNPIVOT 구문이 사용됐습니다.
<리스트 9> 행을 열로SELECT gb <리스트 9>에서는 <리스트 8>의 UNPIVOT 결과에 GROUP BY 와 MIN(DECODE()) 구문을 이용해서 <표 9>의 결과를 도출했습니다. 이것이 바로 행을 열로 전환하는 전통적인 방법이며 11G 부터는 PIVOT 구문 사용이 가능합니다. 여기서 눈여겨볼 것이 하나 있는데요. 그것은 UNPIVOT 결과를 인라인뷰로 사용해 결과를 얻어낸 것이 아니라 인라인뷰 없이 UNPIVOT 결과를 바로 사용했다는 점입니다. UNPIVOT 구문은 FROM 절에서 동작해 FROM 절에서 동작이 끝나며, 이미 FROM 절 안에서 결과집합이 완성돼 나오는 것입니다.
<리스트 10> PIVOTSELECT * <리스트 10> 에서는 PIVOT 을 사용해 정답쿼리를 완성했습니다.퀴즈로 배우는 SQL : 구분자로 나누어 행,열 바꾸기
▷ 퀴즈로 배우는 SQL : 전기 요금 계산
▷ 퀴즈로 배우는 SQL : 달력 만들기(MS SQL)
▷ 퀴즈로 배우는 SQL : 파이프 연결하기
▷ 퀴즈로 배우는 SQL : 공통점이 가장 많은 친구 찾기
▷ 퀴즈로 배우는 SQL : 일별 누적 접속자 통계 구하기
▶ 퀴즈로 배우는 SQL : 구분자로 나누어 행,열 바꾸기
[문제]
(
SELECT 1 no, '1:10|2:11|3:12|4:15' v FROM dual
UNION ALL SELECT 2, '1:17|3:15|4:25' FROM dual
UNION ALL SELECT 3, '2:11|4:15' FROM dual
UNION ALL SELECT 4, '1:10|2:21|4:19' FROM dual
)
SELECT * FROM t;
[문제설명]
[정답]
FROM (SELECT no
, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) "1"
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) "2"
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) "3"
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) "4"
FROM t
)
UNPIVOT (v FOR gb IN ("1", "2", "3", "4"))
PIVOT (MIN(v) FOR no IN (1, 2, 3, 4))
;
[해설]
, SUBSTR(v, 1, INSTR(v, '|') - 1) v1
, SUBSTR(v, INSTR(v, '|', 1, 1) + 1
, INSTR(v, '|', 1, 2)
- INSTR(v, '|', 1, 1) - 1
) v2
, SUBSTR(v, INSTR(v, '|', 1, 2) + 1
, INSTR(v, '|', 1, 3)
- INSTR(v, '|', 1, 2) - 1
) v3
, SUBSTR(v, INSTR(v, '|', 1, 3) + 1) v4
FROM t
;

, REGEXP_SUBSTR(v, '[^|]+', 1, 1) v1
, REGEXP_SUBSTR(v, '[^|]+', 1, 2) v2
, REGEXP_SUBSTR(v, '[^|]+', 1, 3) v3
, REGEXP_SUBSTR(v, '[^|]+', 1, 4) v4
FROM t
;
여기서 필자는 비어 있는 값을 건너 뛰어, 구분값에 따라 컬럼을 나누고 싶어졌습니다. 그렇다면 단순 구분자만 가지고 나눌 것이 아니라 콜론(:) 앞의 숫자를 토대로 데이터를 분할해야 할 것입니다.
, REGEXP_SUBSTR(v, '1:[^|]+') v1
, REGEXP_SUBSTR(v, '2:[^|]+') v2
, REGEXP_SUBSTR(v, '3:[^|]+') v3
, REGEXP_SUBSTR(v, '4:[^|]+') v4
FROM t
;

, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) v1
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) v2
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) v3
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) v4
FROM t
;
, gb
, DECODE(gb, 1, v1, 2, v2, 3, v3, 4, v4) v
FROM (SELECT no
, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) v1
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) v2
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) v3
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) v4
FROM t
)
, (SELECT LEVEL gb
FROM dual
CONNECT BY LEVEL < = 4
)
ORDER BY no, gb
;

(SELECT LEVEL gb FROM dual CONNECT BY LEVEL < = 4)
이를 조건 없이 조인해 데이터를 네 배로 늘리는 효과가 나타나게 됩니다. 이때 늘어난 데이터는 DECODE 구문을 이용해 구분값에 따라 다르게 표현합니다.
, DECODE(gb, 1, v1, 2, v2, 3, v3, 4, v4) v
이렇게 Cross Join 과 Decode 를 총해 열을 행으로 변환하는 과정을 UNPIVOT이라고 하는데요, 실제로 11G 에서는 UNPIVOT 전용 구문이 존재합니다.
FROM (SELECT no
, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) v1
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) v2
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) v3
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) v4
FROM t
)
UNPIVOT (v FOR gb IN (v1, v2, v3, v4))
;
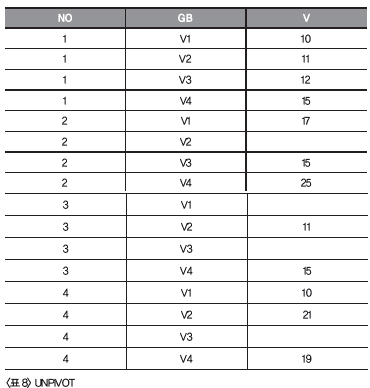
UNPIVOT (v FOR gb IN (v1, v2, v3, v4))
<리스트 7> 에서 복잡하게 구현했던 부분이 UNPIVOT 한줄 작성으로 구현됐습니다. 구문의 의미를 살펴보면 (v1, v2, v3, v4) 4개의 컬럼을 gb 로 구별해 하나의 v 로 표현하라는 의미입니다. 열을 행으로 바꾸었다면 이번에는 반대로 행을 열로 바꿀 차례입니다. UNPIVOT 구문이 있다면 PIVOT 구문도 존재하겠지요. PIVOT 구문을 살펴보기 전에 우선 예전 방식대로 구현하겠습니다.
, MIN(DECODE(no, 1, v)) "1"
, MIN(DECODE(no, 2, v)) "2"
, MIN(DECODE(no, 3, v)) "3"
, MIN(DECODE(no, 4, v)) "4"
FROM (SELECT no
, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) "1"
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) "2"
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) "3"
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) "4"
FROM t
)
UNPIVOT (v FOR gb IN ("1", "2", "3", "4"))
GROUP BY gb
ORDER BY gb
;

마지막으로 행을 열로 전환하는 전통적인 방법 대신 PIVOT 방식을 사용해 보도록 하겠습니다.
FROM (SELECT no
, SUBSTR(REGEXP_SUBSTR(v, '1:[^|]+'), 3) "1"
, SUBSTR(REGEXP_SUBSTR(v, '2:[^|]+'), 3) "2"
, SUBSTR(REGEXP_SUBSTR(v, '3:[^|]+'), 3) "3"
, SUBSTR(REGEXP_SUBSTR(v, '4:[^|]+'), 3) "4"
FROM t
)
UNPIVOT (v FOR gb IN ("1", "2", "3", "4"))
PIVOT (MIN(v) FOR no IN (1, 2, 3, 4))
;

PIVOT (MIN(v) FOR no IN (1, 2, 3, 4))
마찬가지로 UNPIVOT 결과를 인라인뷰로 사용하지 않고 바로 PIVOT했습니다. SELECT절에서도 일일이 컬럼을 나열하지 않고 간단하게 *를 사용했습니다. 간단하게 UNPIVOT 한줄과 PIVOT 한줄 작성으로 정답쿼리가 완성됐습니다. 이번 퀴즈로 배우는 SQL 시간에 다룬 내용을 정리해 볼까요
- 정규표현식(regular expression) 함수를 이용한 데이터 분할
- 열을 행으로 바꾸기 : UNPIVOT
- 행을 열로 바꾸기 : PIVOT