
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
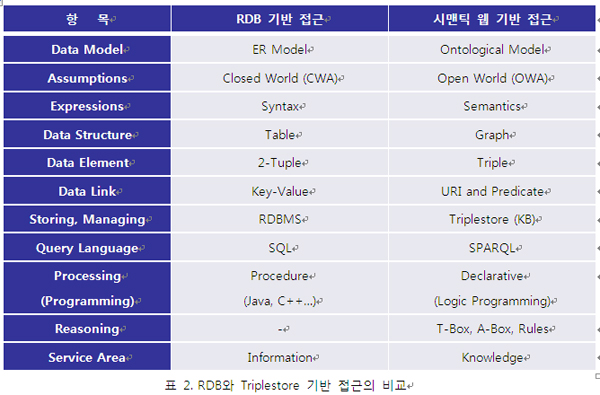
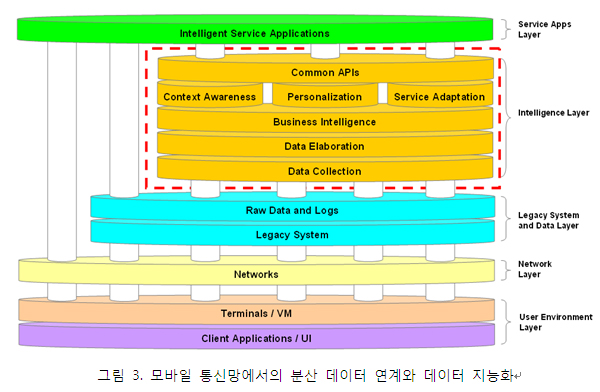
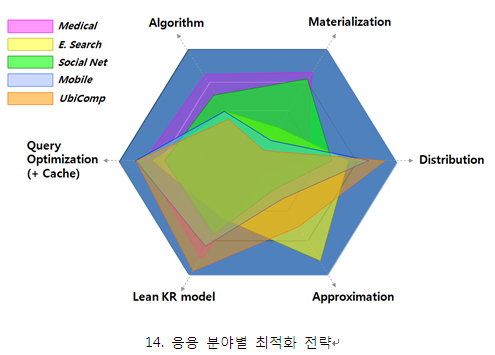
◎ 연재기사 ◎ 다시 보는 시맨틱 웹 그리고 시맨틱 기술 Ⅲ 지난 10년간 시맨틱 웹 혹은 시맨틱 기술이 적용된 다양한 응용 시스템 개발이 추진되었다. 수많은 기초 연구 개발 프로젝트가 있었으며, 몇 년 전부터는 일반사용자들이 직접 경험할 수 있는 상용 서비스들을 수가 크게 증가되고 있다. 표 1에 대표적인 응용 사례들을 정리해 보았다. 물론 이 외에도 다양한 사례가 있겠지만, 각 응용들은 대부분 몇몇 비슷한 목적에서 시맨틱 기술을 사용하고 있다. 바로 (1)데이터의 연계, 통합과 상호운영, (2)검색과 분석 그리고 (3)상황인지와 같은 데이터 지능화 부분이다. 모든 사례들은 URI 기반의 RDF를 사용하고 있으며, 서로 다른 표현 수준의 OWL 혹은 RDFS 스키마가 적용되고 있다. 일부는 웹과 상관없이 단지 지식 베이스 구축과 활용을 목적으로 하고 있으나, URI, XML, RDF 등이 사용되고 있다면, 시맨틱 웹 기술이 응용되었다 볼 수 있을 것이다. W3.org에서는 이러한 다양한 응용 중에서 28개의 시맨틱 웹 사례 연구와 13개의 응용 사례들[1]을 선정해 제시하고 있다. 간단한 통계 자료도 제시되고 있는데, 데이터 통합과 정보 검색이 대표적 응용 영역임을 확인해 볼 수 있다. 미국과 유럽에 비해 적은 수의 사례가 등록되어 있으나 한국도 3개의 대표 사례가 등록되어 있으며, 그 중 2개가 솔트룩스의 사례이고, 1개가 연구기관인 KISTI의 사례이다. 여전히 많은 사람들이 근본적인 질문을 하고 있다. 온톨로지를 포함해서 시맨틱 웹 혹은 시맨틱 기술이 기존의 ER(Entity Relationship) 모델과 어떻게 차별화 되는가 하는 것이다. 최근 LOD와 시맨틱 소셜네트워크 등의 부문에서 큰 진보를 보이고 있지만, 여전히 확연한 차이를 이해하기란 좀처럼 어렵다. 특히, 기존에 불가능하던 것이 시맨틱 기술로 해결 가능하리라는 기대는 종종 좌절을 맛보게 한다. 언제나 그렇듯이 ‘다른 것’을 ‘틀린 것’으로 이해하지 말아야 한다. ER 모델과 온톨로지 모델은 서로 다른 특징과 장점을 가지고 있는 상호 보완적 대상이지, 경쟁 상대나 상호 배타적인 관계가 아닌 것이다. 실제로 최근 대부분의 프로젝트들은 RDB에 기반한 기존 시스템과 시맨틱 시스템을 통합, 연동하고 있으며, 이를 통해 성능 향상뿐 아니라, 비용도 크게 절약하고 있다. 표 2는 기존의 RDB 기반한 접근과 Triplestore 기반의 접근을 비교해 보이고 있다. 사실, 이 둘은 서로 닮아가고 있고, 그 경계도 점점 모호해 질 것이다. 참고로 오라클 10g부터는 온톨로지 모델과 triple 저장, SPARQL을 모두 지원하고 있다. 또한, Extended ER 혹은 UML이 온톨로지 표현 언어로 사용하기도 한다. 앞에서 얘기한 것처럼, 차이를 이해하고, 이를 상호 보완적으로 사용하는 것이 매우 중요하겠다. 기존의 RDB만 사용하던 접근보다 RDB와 시맨틱 기술을 통합해 사용할 때 다양한 장점을 확보하게 된다. 가장 큰 장점으로는 데이터 모델 자체가 의미적 데이터 상호 운영 및 데이터 연계성을 지원하게 된다는 것과, 계승을 통한 스키마의 변화 관리가 유연하다는 점이다. 특히, 소셜네트워크와 같은 그래프 구조의 데이터 처리에 있어서는 놀라운 성능 향상을 기대할 수 있다. 곡물, 석탄 등을 저장하기 위해 만든 사일로스(silos)가 기업 내에서는 부서간 장벽을 의미하는 단어로 쓰인다. 보통 기업이 성장함에 따라 조직이 커지고 세분화되며, 이는 때로 관료주의적이거나 부서 이기주의, 더 정확히 말하면 서로 다른 관점을 가진 상호 이질적 집단을 양산하게 된다. 소통의 부재는 비용을 증가시키고, 부서의 장벽은 조직 내 갈등 양산과 사업 실패의 주요 원인이 되기도 한다. 기업 혹은 서비스 데이터 또한 마찬가지이다. 전산 시스템의 확대와 웹 상에 다양한 연관 서비스들이 개별적으로 발전함에 따라 데이터가 더 깊게 이질화되고, 데이터 연계, 통합을 불가능하게 한다. 최근에는 올바른 의사 결정과 융합 서비스 개발을 위해 기존에 개별 구축된 데이터들을 어떻게 비용 효과적으로 통합할 수 있느냐가 중요한 관건이 되고 있다. 웬만한 규모의 기업들은 EP, ERP, CRM, SCM, KMS 등 다양한 전산 체계를 단계적으로 구축, 활용해 오고 있다. 이러한 시스템들은 개별적으로 비용 절감과 노동 생산성을 향상시켜 왔으며, 기업 경쟁력을 유지시켜 줬다. EAI(Enterprise Application Integration)라던지, 데이터웨어하우스 및 데이터마트 등을 통해 분산된 기업 내 데이터를 통합하려는 수많은 시도가 있었으며, 상당부분 성과를 확인하기도 했다. 그러나, 글로벌 경영 환경의 변화가 더욱 가속화되고, 올바른 의사 결정을 위해 내부뿐 아니라 외부 데이터의 의미적 통합이 더욱 중요해 짐에 따라 기존의 통합 스키마에 기반한 물리적 데이터 통합 방식이 그 한계를 보이고 있다. 서비스 기업에게 효율적 데이터 활용은 수익성과 직결된다. 예를 들어 유무선 통신기업의 네트워크는 데이터에 의해 운영되고 유지된다 해도 과언이 아니다. 최근에는 사용자 로그를 포함한 통신 데이터를 기존의 레거시 데이터와 통합해, 보다 지능적인 서비스를 구현하고자 하고 있다. 이를 위해서는 통신 데이터의 상호 운용성 확보가 또한 관건이 되고 있다. 여러 이유에서 통화 정보, 단말 정보, 위치 정보, 가입자 정보, 과금 정보, 인터넷 접속 로그 등이 각각의 사일로에 분리되어 있는데, 워낙 이질적이기도 하고, 실시간 대용량 처리가 필수적이기 때문에 이들을 모두 통합한다는 것은 쉬운 과제가 아니다. 그림 3처럼 모바일 인프라에 intelligence layer를 추가해서 RDF 기반의 데이터 연계와 데이터 지능화를 수행할 수 있다. 실시간 대용량 처리 등 여러 도전과제가 있으나, 국내 일부 통신회사를 포함해 해외의 여러 모바일 사업자들이 이러한 시스템 구조를 확보하기 위한 대규모 투자를 진행하고 있다. 웹 데이터의 상호운용은 더욱 복잡하다. 기업 데이터는 기업 내에서 통제 가능하고, 강력한 의지가 있다면 어떤 식으로든 통합할 방안을 찾을 수 있다. 그러나, 웹은 통제 불가능하며, 하나의 서비스 사업자가 다른 사업자의 데이터를 활용하거나, 융합 서비스를 위해 데이터를 상호 운용한다는 것은 상상하기 조차 매우 어렵다. 사실 기존 웹의 정신에 위반되는 웹 데이터의 사일로 문제가 바로 팀 버너스-리가 시맨틱 웹을 제안하게 된 계기라 할 수 있다. 시맨틱 웹은 데이터의 개방과 공유, 유통을 목적으로 하고 있으며, 언젠가는 웹을 상호운용 가능한 데이터의 웹으로, 거대한 의미기반 데이터베이스로 만들어 주게 될 것이다. 웹 데이터 사일로 문제 해결을 위해 가장 먼저 손을 든 그룹은 시맨틱 웹 부문의 세계적 연구 그룹인 아일랜드의 DERI였다. DERI의 John G. Breslin와 Uldis Bojars는 2004년 블로그, 커뮤니티, 소셜네트워크 등의 데이터 사일로 문제 해결을 목표로 SIOC(Semantically-Interlinked Online Communities) Project를 시작하였다[5]. SIOC(쇽이라고 읽는다)은 RDF와 RDFS에 기반하고 있으며, SIOC 온톨로지와 메타데이터, 그리고 이들을 활용할 수 있는 데이터 수집기, 저장소, 브라우저, 검색기 등으로 구성되어 있다. SIOC 온톨로지는 DC(Dublin Core)와 FOAF(Friend Of A Friend)를 재활용하고 있으며, 뒤에서 설명할 시맨틱 소셜네트워크, 시맨틱 소셜미디어 서비스 구축을 위해 포괄적으로 사용되고 있다. 이제 시맨틱 검색에 대해 살펴보자. 조금 혼란스러운데, 시맨틱 검색을 시맨틱 웹 검색과 의미기반 검색의 두 가지 다른 관점으로 나누어 볼 수 있다. 시맨틱 웹 검색은 웹 상에 존재하는 RDF와 그 스키마를 수집하고 그래프 구조로 인덱싱, 검색할 수 있도록 한다. 1부에서 잠깐 살펴본 syndice.com을 그 대표적 예로 들 수 있다. 또한, 야후의 서치몽키(Search Monkey)처럼 메타데이터를 수집하고, 기존 키워드 검색 결과와 함께 트리플 데이터를 출력하는 서비스도 넓은 의미에서 시맨틱 웹 검색이라 얘기할 수 있을 것이다. 현재, RDF 데이터가 텍스트만큼 폭 넓게 유통되고 있지 못하기 때문에 많은 시맨틱 검색 엔진들은 텍스트로부터 트리플 정보를 자동 추출하고, 시맨틱 네트워크를 자동 구축, 인덱싱하는 시도를 하고 있다. 이론적 관점에서 정보검색(IR, Information Retrieval) 기술은 상호 반비례 관계에 있는 정확률(precision)과 재현율(recall)을 동시에 높이려는 치열한 싸움이다. 그림 6처럼 구글의 페이지 랭크는 재현율을 유지하며 상위 랭크의 정확률을 높여 큰 성공을 하였으며, 네이버의 지식인은 집단지성과 손맛을 통해 정확률을 높여 성공한 사례라 하겠다. 그러나 웹 정보량이 더욱 폭발적으로 증가함으로 기존 방법으로는 원하는 정보를 찾고 이해하기가 더욱 어려워졌다. 대안으로 제시되는 시맨틱 검색은 시맨틱 웹의 비전과 유사하게, 기계가 방대한 검색 결과를 인간 대신 읽고 분석하여 정리해 주기를 바라는, 그리고 보다 정확한 답 혹은 가장 관련성 깊은 정보를 빠르게 찾게 하겠다는 목표를 가지고 있다. 의미기반 검색은 목적과 구현 방식에 따라 다음의 몇몇 가지 유형으로 나누어 볼 수 있다. 데이터와 정보가 쌓여가면서 우리는 그 안에 있는 뭔가의 가치 있는 지식을 발견하고 싶은 욕구를 느끼게 된다. 특히, RDB와 통계, 규칙에 기반한 다양한 데이터 마이닝 기법들이 발전해 왔다. 데이터 마이닝은 DB에 저장된 구조 데이터에 대해 SQL 질의와 통계처리를 통해 의미 있는 정보를 발견해 낸다. 대표적인 비구조 데이터에 대한 분석인 텍스트 마이닝 기술도 정보추출, 군집, 분류 등의 부문에서 매우 높은 기술 수준에 이르렀다. 텍스트 마이닝에 기반한 상당히 많은 응용 서비스들이 상용화 되었으며, 최근에는 시맨틱 검색과 깊게 연계되어 발전하고 있다. 그림 9는 실제 솔트룩스 직원들의 이메일을 분석한 화면이다. 특정 주제에 대한 조직 내의 지식 소통 구조를 한 눈에 파악할 수 있으며, 누가 핵심 인물인지를 정량적으로 바로 확인할 수 있다. 또한 친밀도 연산을 통해 해당 주제에 대해 특정인물과 친밀도가 가장 높은 사람이 누구인지도 정확히 분석해 낼 수 있다. 두 가지 이상의 이질적 주제에 대한 분석을 수행하면, 이 두 주제를 모두 연결할 수 있는 지식 브로커를 찾아낼 수 있고, 업무 협력 체계에 어떤 문제가 있는지, 누구를 통해 의사소통과 의사 결정을 내려야 할지 명확히 이해할 수 있게 된다. 또한, 각 사용자가 해당 주제와 관련해 어떤 연관 주제로 업무 메일을 주고 받았는지, 정량적 지식 활동 분석 또한 수행할 수 있다. 2) 전문가 지식 네트워크 분석 RDF, OWL을 포함한 시맨틱 웹 기술이 어김없이 사용되는 영역이 있는데, 바로 상황인지(Context Awareness) 분야이다. 웹과는 좀 동떨어진 느낌이 없지 않지만, 유비쿼터스 컴퓨팅을 필두로, u-City와 Urban 컴퓨팅 등 여러 연관 분야에서 OWL기반의 상황인지 관련한 이론적 연구가 진행되어왔다. 서로 다른 센서들로부터 유입되는 대량의 실시간 분산 데이터에서 특정 상황을 인지해 내고, 맞춤형 지능 서비스를 제공하겠다는 것이 대부분의 서비스 시나리오 유형이다. 상황인지 분야에서 시맨틱 기술, 특히 온톨로지 활용이 적극 고려되는 것은 센서네트워크 자체가 분산되어 있으며, 데이터가 상황의 일부분만 설명한다는 점, 그리고 기계가 스스로 읽고 처리할 수 있다는 이유 때문이다. 서비스 지능화, 서비스 개인화를 위해서 시맨틱 웹 기술 활용이 적극 검토 되고 있다. 상황인지 서비스와 일맥상통 하다고 볼 수 있는데, 서비스 개인화는 서비스 및 컨텐트 추천 기능의 구현에 보다 집중되어 있다. 서비스 개인화를 위해서는 사용자 모델링이 매우 중요하다. 온톨로지는 사용자 모델을 개념적으로 구성하고, 정보 및 서비스 개체, 타인과의 관계를 설정, 분석해 감으로 사용자의 선호와 맞춤형 추천 모델을 구현하게 된다. 현재 모바일 서비스 추천, 음악 추천, 영화 추천, 광고 추천 등 다양한 부문에 시맨틱 기술이 활용되고 있다[8,9,10,11]. 3개월, 3부에 걸쳐서 시맨틱 웹과 시맨틱 기술에 대해 폭넓게 살펴보았다. 무엇보다도 짧은 지면에 많은 얘기를 담으려 욕심을 내다 보니, 깊이가 없어진 것 같아 못내 아쉬움이 남는다. 10년 전, 초기의 기대에 비해 시맨틱 웹의 대중화가 더딘 것은 사실이다. 그럼에도 굵은 변화의 흐름은 되돌릴 수 없다 믿는다. 시맨틱 웹과 그 표준에 기반한 다양한 파생 기술들이 R&D 단계를 넘어서 이미 빠르게 상용화 단계로 접어들고 있음을 생생히 경험하고 있다. 실용화, 상용화 과정에서 우리는 이론을 넘어 기술을 각 응용에 따라 최적화 해야 함을 배우게 된다. 그림 13은 다양한 시스템 최적화 방안을 보이고 있다. 다른 방법보다 분산 컴퓨팅과 근사화 그리고 질의 최적화 기술이 시스템 성능 최적화를 위해 보다 효율적임을 잘 보이고 있다. 저자가 참여하는 EU FP7 프로젝트인 LarKC에서는 분산 컴퓨팅 기술과 materialization을 통해 100억 트리플에 대한 DL 추론이 가능함을 성공적으로 보였다[12]. 이제 더 이상 추론에서 대용량 처리는 큰 문제가 되지 않을 것이다. 그림 14는 각 응용 분야에 따른 최적화 전략을 도식화 하였다. 예를 들어 시맨틱 모바일 컴퓨팅을 위해서는 분산처리와 질의 최적화가 가장 적합한 적용 방안이 되며, 시맨틱 검색을 위해서는 근사화가 추천된다. 이미 2부에서 설명된 바와 같이 OWL 2의 표준화는 응용에 따른 온톨로지 구축 최적화와 추론 기술의 상용화를 가속시키고 있다. 특히, 대용량 트리플에 대해 다항시간 내에 추론이 가능하도록 보장함으로 온톨로지 시스템의 성능에 대한 우려를 불식 시키게 될 것이다. 요즘 국내외적으로 공공 데이터의 공개 압력이 커지면서, 일부 선진국에서는 정부가 쥐고 있던 데이터를 웹에 공개하기 시작했다. 미국과 영국이 앞장을 섰으며, 오스트리아와 한국이 그 뒤를 이을 것으로 보인다. 한국의 경우 XML 파일을 직접 다운로드 하거나, open API 형태로 데이터를 개방할 예정인 것 같은데, 데이터 공개의 효과가 크게 줄 것 같아 안타깝다. LOD를 중심으로 SPARQL endpoint가 일반화 되면서, 데이터의 웹이라는 비전이 현실로 다가오고 있다. 이제는 기술의 문제가 아니라 기술의 적절한 응용과 비용 효과(ROI)가 중의 특성 상, 다양한 단말에 다양한 응용 어플리케이션들이 상호작용 해야 하며, 위치를 포함한 다양한 상황정보(context)가 서비스에 적극 활용되기 시작했기 때문이다. 얼마 전 애플이 시맨틱 기반의 모바일 기술 기업인 SIRI를 매입한 것은 이러한 전망을 뒷받침 하고 있다. [3탄] 다시 보는 시맨틱 웹 그리고 시맨틱 기술
▷ 시맨틱 웹 : 기술을 넘어 서비스 플랫폼으로
▷ 검색의 진화, 시맨틱 검색
▷ [1탄] 다시 보는 시맨틱 웹 그리고 시맨틱 기술
▷ [2탄] 다시 보는 시맨틱 웹 그리고 시맨틱 기술
▶ [3탄] 다시 보는 시맨틱 웹 그리고 시맨틱 기술
1. 시맨틱 기술 응용
1.1 시맨틱 기술의 응용 분야
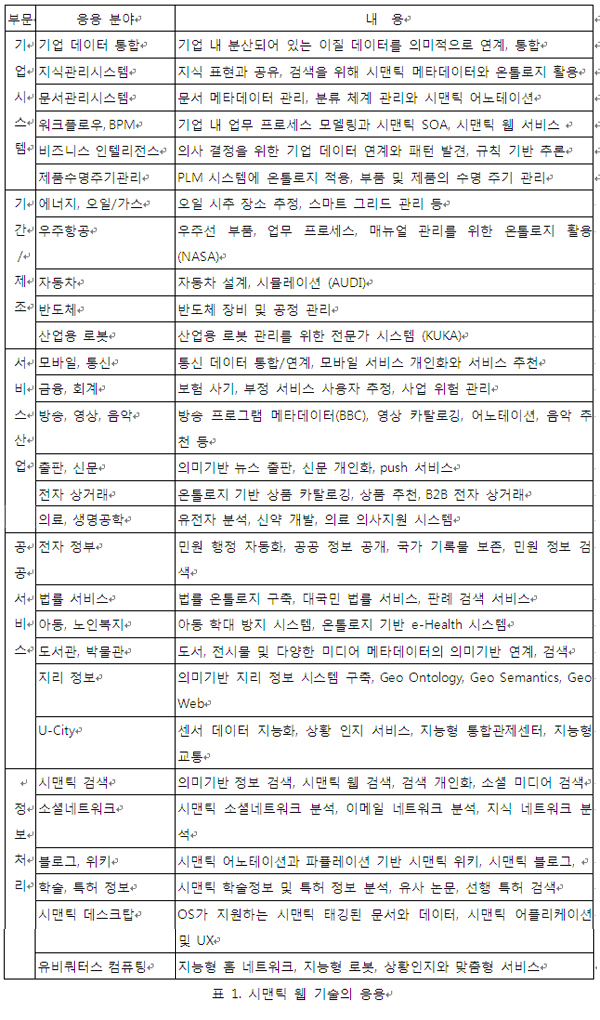
1.2 시맨틱 기술 적용의 장점
2. 데이터 상호운용 (Data Interoperability)
2.1 데이터 사일로스
그림 1은 시맨틱 레이어(Semantic Layer)를 통해 의미적으로 데이터를 상호 연계하고, 다양한 서비스 시스템이 단일한 접근 경로로 이질적 데이터들에 통합 접근 가능함을 개념적으로 설명하고 있다. 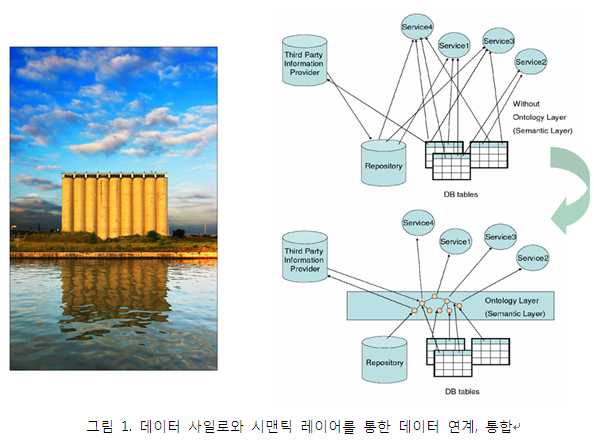
2.2 기업 데이터 상호운용
SOA(Service Oriented Architecture)와 같은 접근은 웹 서비스에 기반해 프로세스와 서비스 관점에서 이러한 문제를 해결하고자 한다. 그리고 최근에는 SOA에 시맨틱 기술을 적용함으로 데이터와 단위 서비스를 의미적으로 발견하고 연계하고자 시도하고 있다. 이는 보다 유연한 거버넌스를 확보하도록 도울 것이다. 오라클은 11g에서 시맨틱 기능을 강화시키면서, 기업 데이터의 의미적 통합 사업을 강화하고 있다[2]. 기업 데이터는 보안이 유지된 상태로 내부 개방되고 상호 연결될 것이다. 웹의 LOD(Linking Open Data)와 마찬가지로, 모든 데이터 개체는 URI에 기반한 RDF로 변환될 것이고 SPARQL endpoint로 질의 가능한 체계를 갖추게 될 것으로 보인다.
Dion Hinchcliffe는 ZDNet의 기고에서 미국 정부, 영국 정부의 공공 데이터 개방을 예로 들면서, 기업 2.0 환경과 미래 기업의 데이터 개방 필요에 대해 거론하고 있다[3]. 그는 기업 데이터 개방과 공유를 위한 세가지 방안을 제시하고 있다. 그림 2와 같이 REST 형태의 Web-Oriented Architecture (WOA), 매우 가벼운 SOA와 open API 그리고 시맨틱 웹과 Linked Data 활용이 매우 유용할 것이라 주장하고 있다. 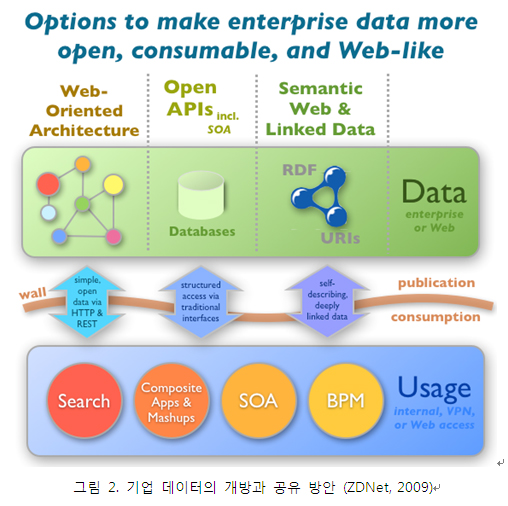
2.3 웹 데이터 상호운용
본 기고를 쓰고 있는 동안 페이스북에서 RDFa 기반의 Open Graph를 통해 페이스북 data를 개방, 공유하겠다고 밝혔다. 서양에서는 프라이버시 문제가 발생할 것을 우려하며, 큰 파장이 일고 있으나, 이는 다분히 과장된 바가 있다 생각한다. Open Graph는 html 형태로 이미 공개되어 있는 페이스북 내의 다양한 데이터를 RDFa 형태로 기계가 읽을 수 있도록 퍼블리싱한다. 이는 다른 소셜네트워크 서비스들과 데이터를 상호 운영할 수 있는 기반을 제시하며, 더 큰 네트워크를 형성하게 해 준다. 역시 과장된 바가 없지 않으나, 페이스북이 구글의 대항마로 제시되고 있기에, Open Graph도 더욱 큰 주목을 받게 되었다.
아래의 Open Graph 샘플을 살펴보자. RDFa 표준 문법을 따르고 있다. Opengraphprotocol.org와 facebook.com을 XML name space로 하여,
태그의 property와 content를 사용해 RDFa 시맨틱 태깅을 하고 있다. 매우 단순한 구조로 사람과 기계 모두가 잘 읽고 이해할 수 있는 형태를 가진다. OG를 통해서 개인 사용자 프로파일뿐 아니라, 미디어 타입, GIS를 포함한 위치 정보 등 오브젝트에 대한 자세한 정보를 기술할 수 있다. 보다 상세한 내용은 페이스북의 디벨로퍼스 페이지[4]를 참조하기 바란다. 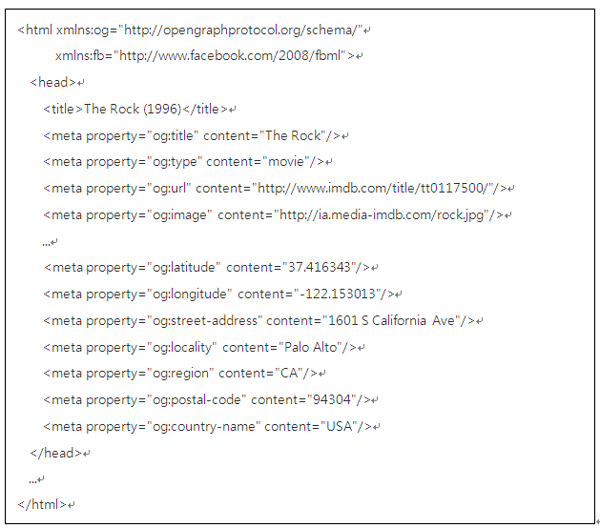
그림 4는 SIOC을 통한 소셜 데이터 모델링 예를 보이고 있다. 사람 사이의 관계는 FOAF에 기반하며, 각 실 사용자의 서비스 계정은 sioc:User를 통해 모델링 된다. 각 포스트는 sioc:Container와 sioc:Post등을 통해 사용자 계정과 연결될 수 있으며, sioc:has_reply, sioc:Comment 등을 통해 다른 사용자와 연결된다. SIOC의 활성화를 위해 다양한 exporter가 개발되어 있다. Exporter는 블로그, 포럼 및 소셜네트워크 서비스와 연결(플러그인)되어서 SIOC 메타데이터를 생성한다. 현재 WordPress, Drupal, Twitter 등을 지원하고 있다. 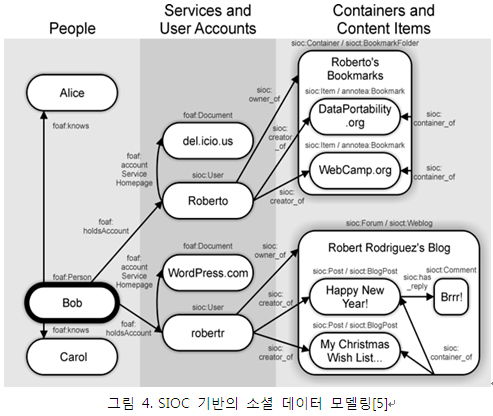
3. 시맨틱 검색과 분석
3.1 시맨틱 검색
그림 5를 보자. 기존의 키워드 기반 검색과 시맨틱 검색의 차이를 보이고 있다. 키워드 기반 검색은 키워드(토큰)를 텍스트로부터 분리(형태소 분석)하여 이를 역파일 형태로 인덱스에 저장하게 된다. 즉, 사람에게 유리한 지식표현 체계를 파편화된 키워드 쪼가리로 분해하여 그 의미 이해 없이 코드 패턴으로 변환 단순 저장하고, 동일한 코드가 검색 질의로 입력 되었을 때, 빠르게 그 코드를 포함한 문서를 찾아주는 형태이다. 반면에 시맨틱 검색은 2부에서 상세히 살펴본 시맨틱 네트워크에 대한 질의를 수행하는 것으로, 개념들과 그들의 관계를 포함한 그래프 구조의 의미 메타데이터 전체를 온전히 색인, 질의하도록 한다. 어떤 의미에서 시맨틱 웹 검색은 웹 상에 이미 존재하는 RDF 메타데이터 그래프를 색인하는 것이고, 넓은 의미의 의미기반 검색은 텍스트, 이미지, 동영상 등의 다양한 형태의 문서에서 어떤 방법이던 의미 메타데이터를 자동 추출하여 시맨틱 그래프를 자동 구성하는 과정을 포함한다고 볼 수 있다. 결국 시맨틱 검색의 성능과 효용성은 “어떻게” 비구조 문서, 정보를 시맨틱 그래프 형태의 구조 데이터로 잘 변환할 수 있겠냐는 것이다. 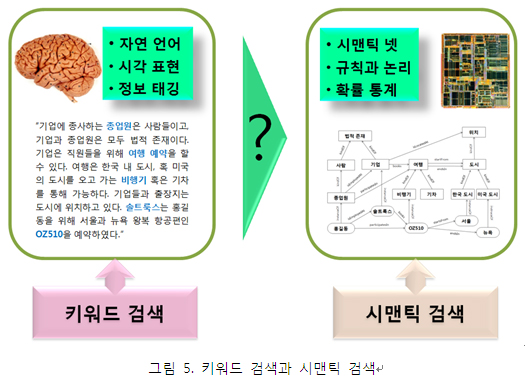
트리플 기반의 시맨틱 메타데이터와 시맨틱 어노테이션 기술을 기존 정보 검색 기술과 결합할 때, 정확률 향상 효과를 기대할 수 있다. 시맨틱 웹 기술과는 좀 거리가 있지만, 정보 추출 및 개체명 인식, 문서 군집과 자동 분류와 같은 텍스트 마이닝 기술도 정확률 향상에 큰 기여를 한다. 특히, 개체명 인식 기술은 시맨틱 검색에 있어 점점 더 중요한 요소 기술이 되어가고 있다. 온톨로지 기반의 포함관계 추론과 단어 군집(word clustering) 기술은 키워드를 확장함으로 재현률을 증가시킬 수 있다. 기존 정보검색과 다르게 시맨틱 검색에서는 그림 6 오른쪽 그림처럼 연결성과 분석성에 대한 새로운 품질 평가 척도를 필요로 한다. 즉, 시맨틱 검색의 결과는 기존 키워드 검색과 다르게 각 정보가 상호 연결되어 있고, 이질적 분산 정보에 대한 통합 분석 기능을 제공해야 한다. 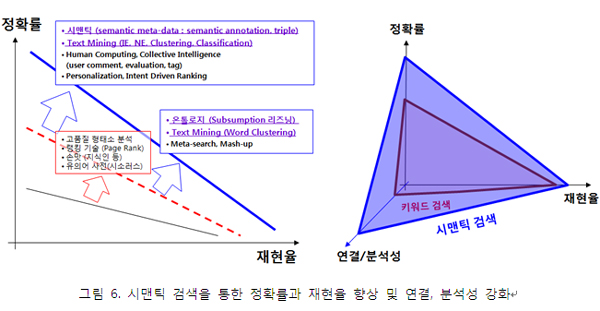
▶ 의미모호성 해소(WSD) 검색 : 시장(mayor, market, hunger), 말(speech, horse, checker, end) 등의 용어 의미를 구분해 색인, 검색 시 의미에 따른 분류 수행 - 개체명 인식, 시맨틱 어노테이션, 용어 군집, 온톨로지 기술 등 적용
▶ 어휘 개념 확장 검색 : 핸드폰=휴대폰=셀룰라폰, 과일⊃사과∋부사, 정치인⊃대통령∋이명박 등의 개념적 상하위 관계, 동의어/유의어 관계, 인스턴스 등을 확장하여 검색. 즉 정치인을 검색하면, 이명박이라는 키워드를 포함한 문서도 검색- 시소러스(워드넷) 및 온톨로지 활용, 질의 시 포함관계 추론 가능. 온톨로지 파퓰레이션 등 자동화 기술 통한 자동 구축 가능
▶개체 특징(property) 확장 검색 : 솔트룩스.대표이사, 솔트룩스.주소, 솔트룩스.제품 등과 같이 검색 대상 개체의 구체적 특징들에 대해 확장 검색할 수 있는 기능. 트리플 관점에서 보면 predicate를 통한 정보 네비게이션 형태를 취함 ? 구축된 온톨로지를 활용하거나, 텍스트로부터 부분 구문분석(partial parsing)을 통해 관련 정보를 자동 추출 가능(네이트 시맨틱 검색 유형). 한국어의 경우 의존 문법 기반한 분석 유리.
▶연관 주제 확장 검색 : 천안함-침몰-어뢰, 장동건-고소영-결혼 등과 같이 연관된 주제들을 연결해 확장 검색할 수 있는 기능. 특정 주제를 둘러싼 컨텍스트와 트랜드 이해를 목적으로 함 - 공기어분석, LSA, 토픽랭크 등의 분석 기법 적용
▶의도 기반 검색 : 냉면-맛집/요리법/역사, 청담동-교통/식당/카페 등, 사용자의 검색 의도에 따른 목적 주제를 제시하는 검색 - 사용자 로그 등 검색 패턴 분석을 통해 주제에 따른 사용자 의도 발견과 주제별 인덱싱
각 시맨틱 검색 유형은 그 구현 방법과 목적이 상의하지만, 사용자 관점에서는 차이점을 인식하기 어려울 수 있다. 대부분의 시맨틱 검색 시스템은 1개 이상의 시맨틱 검색 유형이 결합되어 있다[6]. 시맨틱 검색의 궁극적 목표는 수많은 정보를 쉽게 분석하고, 숨겨진 지식을 발견하도록 함으로 올바른 의사결정을 지원하는 것이다. 그림 7은 시맨틱 통합 검색 시스템이 제공하는 정보의 지식화 프로세스를 설명하고 있다. 사용자는 이 과정을 통해 지식의 발견과 올바른 의사결정이 가능하게 된다. 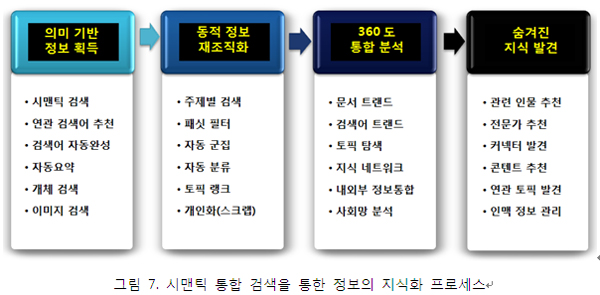
3.2 시맨틱 분석
시맨틱 분석, 혹은 시맨틱 마이닝은 테이블이 아닌 그래프 구조의 시맨틱 네트워크에 대한 논리적, 통계적, 규칙 기반의 분석을 수행한다. 기본적으로는 트리플로 구성된 대규모 시맨틱 네트워크 혹은 지식베이스에 질의함으로 분석 주제와 연관 있는 그래프 서브셋을 추출하고, 이에 대한 의미 분석을 수행한다. 질의 시 온톨로지 기반의 DL 기반 추론, 규칙 기반의 추론이 수반될 수 있으며, 추출된 시맨틱 네트워크에 대한 추가적 통계, 논리 분석을 수행하게 된다.
시맨틱 마이닝은 다양한 부문에서 활용되고 있다. 우선 저자가 참여하고 있는 EU의 LarKC 프로젝트 경우, 신약개발을 목적으로 수 많은 화합물의 결합과 유전자 분석을 시맨틱 마이닝을 통해 수행하고 있으며, 텍스트 마이닝과 시맨틱 마이닝을 결합하여 폐암 원인 인자 분석도 수행하고 있다. 무엇보다도 소셜네트워크 및 지식 네트워크와 같이 본질적으로 그래프 구조를 가지고 있는 지식 체계에 대해서는 시맨틱 마이닝은 매우 큰 효과를 발휘한다.
이제, 시맨틱 소셜네트워크 분석을 중심으로 시맨틱 분석에 대해 보다 구체적인 설명을 한다. 온라인 상에서 사람과 사람은 (때로는 사람과 기계가) 다양한 방식으로 소통을 하며 정보를 주고 받게 된다. 이러한 1:1 혹은 1:N 관계를 계속 확대하면, 거대한 네트워크를 구성하게 된다. 전통적인 소셜네트워크 분석이 방향과 강도, 거리 등에 기반해 물리 세계의 사람들 관계를 분석했다면, 최근 트위터나 페이스북 등의 온라인을 대상으로 한 소셜네트워크 분석에서는 그 네트워크 구조를 타고 흐르는 방대한 데이터에 기반해 보다 복잡하고 실시간적인 소셜네트워크 분석이 요구되고 있다. 온라인 소셜네트워크는 즉흥적으로 연결되고 연결이 임의로 제거 될 수도 있으며, 구전과 다르게 실제 정보의 흐름과 유통을 모니터링할 수 있으므로, 특정 주제에 대한 전문가 분석 등을 정량적으로 수행할 수가 있다. 특히, 각 노드(사람)에 프로퍼티 형태의 다양한 메타데이터가 부착되어 있음으로, 트리플 저장소와 SPARQL을 사용한다면, 목적에 맞게 서브 네트워크를 추출, 분석하는 것이 매우 용이해진다.
1) 이메일 소셜네트워크 분석
오랜 기간 동안 이메일은 온라인상에서 소통의 중심이었고, 현재도 조직 내, 조직 간 지식 소통의 대부분은 이메일을 통해 이루어지고 있다. 단위 이메일은 기본적으로 1:1 혹은 1:N 관계를 가지고 있으며 회신과 전달, 반복적 답장을 통해 지식은 구체화되고, 네트워크는 확장된다. 일반적 소셜네트워크 분석 이론과 마찬가지로, 나의 이메일 수진자들의 또다른 이메일 수진자들은 거대한 네트워크를 형성하게 되며, 이 네트워크를 통해 끊임없이 지식이 흐르게 된다. 이메일에 첨부된 문서들은 또한 네트워크 분석의 매우 중요한 정보를 제공한다. 그림 8은 솔트룩스의 이메일 소셜네트워크 분석 시스템인 “쌈지”의 개념 구조와 절차를 설명하고 있다. 메일 서버로부터 이메일을 수집하고, 각 메일의 메타정보 추출, 본문과 첨부 문서에서 특성과 개체명을 추출해 RDB에 저장하게 된다. RDB에 저장된 정보는 본문과 첨부로부터 추출된 주제별 토픽네트워크와 이메일 네트워크 정보를 결합해 트리플 저장소에 시맨틱 소셜네트워크 형태로 저장된다. 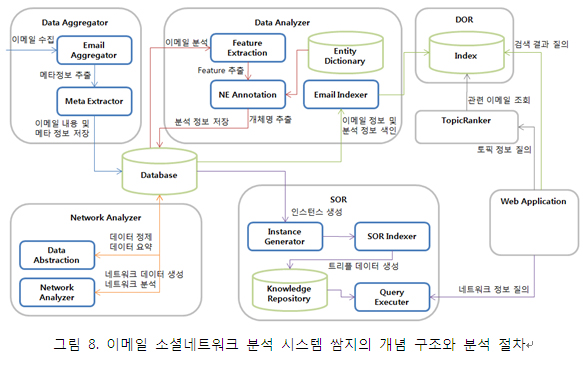
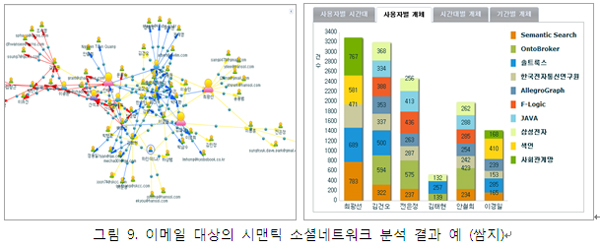
그림 10은 현재 부산시에서 추진하고 있는 BKMnet 서비스 시스템의 화면이다. BKMnet은 논문, 특허, 보고서, 뉴스 등을 분석해서 시맨틱 네트워크를 자동 추출한 후, 이를 인물 DB와 의미적으로 결합함으로 특정 분야의 전문가를 발견하고, 세부 분야별 전문가 네트워크를 분석할 수 있도록 돕는다. 이 시스템은 각 전문가의 인적 정보와 주제별 시맨틱 네트워크를 온톨로지 기반의 트리플 저장소로 통합함으로, SPARQL을 통해 매우 쉽게 전문가를 검색, 전문가 간의 연관성을 분석할 수 있도록 한다.
3) 모바일 소셜네트워크 분석
최근 한국뿐 아니라 전 세계적으로 스마트폰 중심의 모바일 서비스 산업이 급성장 하고 있다. 이메일과 마찬가지로, 전화 통화는 근본적으로 사람간의 네트워크를 만들어 낸다. 하나의 유무선 통화 혹은 문자 전송은 CDR(Call Detail Record)이라는 데이터 하나를 네트워크에 떨군다. 모바일 소셜네트워크가 기존 소셜네트워크와 다른 점은 이 CDR에 통화 기록뿐 아니라, 기지국의 위치 정보가 포함되어 있다는 것이다. 이 정보는 모바일 소셜네트워크 분석을 더욱 풍성하고 강력하게 만든다. 더군다나 모바일 망 내에는 가입자 정보, 과금 정보, 모바일 인터넷 사용 로그 등 통합이 가능하다면 소셜네트워크를 더욱 가치 있게 만들 중요 데이터들이 존재한다.
국내 통신사인 SKT와 KT 뿐 아니라 일본 DOCOMO와 미국/유럽의 T-Mobile 등 거의 모든 통신 회사들이 소셜네트워크 분석에 큰 관심을 가지고 여러 연구 과제를 진행하였다. 저자의 회사도 모 통신기업과 함께 암호화된 통신데이터에 대한 시맨틱 소셜네트워크 분석을 수행하였다. 해당 과제에서 우리는 CDR을 중심으로 가입 정보와 인터넷 사용 로그 등을 의미적으로 통합하고, 온톨로지와 규칙 기반한 사회 관계 추론 시스템을 개발 하였다. 이 시스템을 통해 우리는 부부 관계, 부녀 관계, 친구 관계, 직장 동료 관계 등을 매우 높은 정확도로 추론해 낼 수 있었으며, 개인 선호 분석과 함께 서비스 추천 및 개인화 체계 구현이 가능하였다.
그림 11은 모바일 소셜네트워크 분석에 적용된 온톨로지와 규칙의 예를 보이고 있다. 향후, 모바일 소셜네트워크 분석은 모바일 광고, 맞춤형 서비스를 위한 킬러 서비스 기술이 될 것이 분명하다. 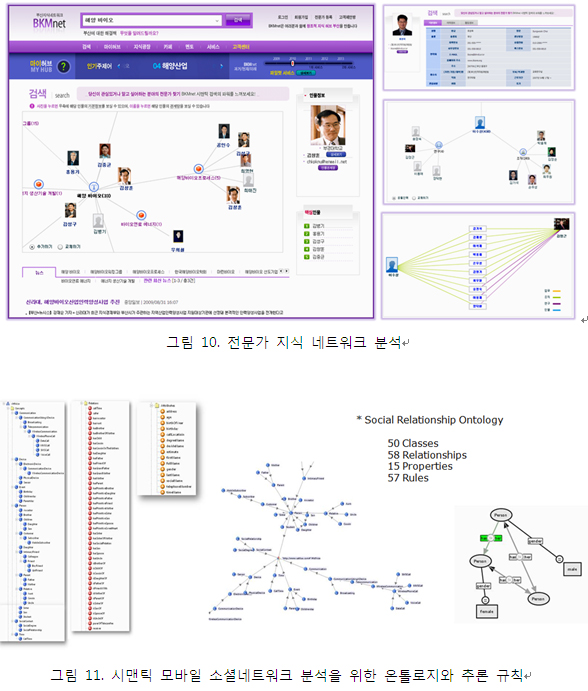
4. 상황인지와 서비스 개인화
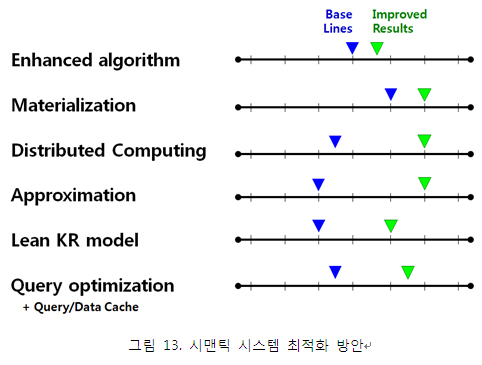
국내외에서 시맨틱 기반의 상황인지 기술은 매우 다양한 응용 분야에 사용되고 있다. 지능형 교통, 지하 매설물 관리, 산불 감시와 방재, u-Health, 홈네트워크 서비스와 시설물 관리 등이 있는데, 국내에서도 u-city 시범 사업에 적용되어 그 가능성을 확인하고 있다. 그림 12는 상황인지를 위한 컨텍스트 모델 평가 결과[7]와 상황인지 온톨로지의 일부를 보이고 있다. 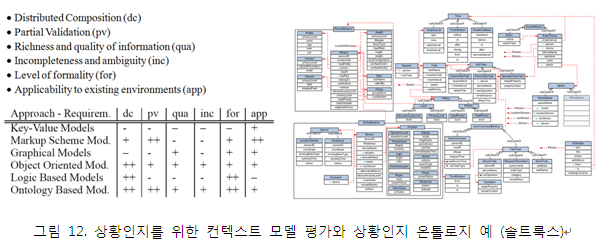
5. 실행 전략과 향후 전망
언제나 기술보다 중요한 것은 고객 만족이다. 조만간 세상에는 많은 수의 놀랍게 혁신적인 서비스들이 미래 고객을 만족시킬 것이다. 이들의 상당 수는 시맨틱 웹에 기반하게 될 것이다. 부디 본 기고가 작게나마 세상을 변화시키는데 도움이 되었으면 한다.