
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
빅데이터 분석에 기반한 데이터 미학의 두 번째 걸음 국내 최초 빅데이터 분석 지난 시간에 빅데이터와 데이터 마이닝의 상관관계에 대해 알아봤다. 이번에는 국내 최초 빅데이터 분석을 위한 데이터 마이닝 & 기계학습 오픈소스 프로젝트에 대해 소개한다. 빅데이터의 가장 큰 목적은 데이터 분석을 통해 미래 가치를 창출하는 것에 있다. 최근 빅데이터가 급부상하면서 함께 지적되고 있는 문제는 ‘빅데이터를 도입하면 과연 효과를 얻을 수 있을까’라는 것이다. 빅데이터를 통해 얻을 수 있는 경제적 효과가 크다는 것은 언론 및 정부기관으로부터 자주 언급되고 있다. 하지만 막상 실무에 적용시키려면 어디서부터 어떻게 무엇을 시작해야 할지 막막하다. 그러나 국내외 정부와 기업에서의 다양한 빅데이터 적용 성공사례들은 그 효과를 직간접적으로 증명하고 있다. 성공사례 중 가장 큰 예로, 2012년 미국대통령 버락 오바마의 재선을 가능하게 했던 선거 전략은 데이터 마이닝(data mining)이었다. 오바마 캠프는 철저한 보안 아래 데이터 마이닝팀을 만들어 운영했다. 실제로 오바마는 보고캠프 내부 비판보다 데이터 분석팀 전략을 더 수용했던 것으로 알려져 있다. 오바마 대변인은 ‘데이터 마이닝은 우리의 핵무기 코드’라고 밝히기까지 했다. 이러한 빅데이터의 효율적 활용을 위해서는 데이터 현황 위주의 분석(descriptive analysis)과 더불어 데이터 마이닝과 기계학습(machine learning)을 기반으로 해 의사 결정 지원 및 서비스에 즉시 응용할 수 있는 고급 분석 기법들이 필요하다. 데이터 마이닝 기법 중 하나인 분류(supervised learning) 기법은 데이터들을 미리 지정된 부류나 등급으로 나누는 분석이다. 예를 들어 신용 등급에 따라 고객을 분류하는 모델을 구축하고 신규 고객의 정보에 따라 신용 등급을 예측한다. 스팸 메일 자동 분류와 문서의 카테고리 자동 분류, 인터넷 중독 진단 시스템 등에 쓰인다. 앞서 말한 데이터 마이닝 분석 기법을 현업에서 사용하기 위해 전통적으로 SAS Enterprise Miner, IBM SPSS Modeler, KXEN, Weka, R 등의 도구들이 많이 사용돼 왔다. 우리나라 기술로 만들어진 ECMiner 등도 있다. 하지만 이러한 데이터 마이닝·기계학습 분석 도구들은 분산 빅데이터 환경을 고려하지 않은 단일 머신 시스템 수행에 맞춤 설계·개발돼 있다. 이는 빅데이터 환경에서는 운용이 불가능한 단점을 갖는다. 하둡은 HDFS(Hadoop Distributed File System)를 사용한 파일시스템과 분석을 위한 맵리듀스 기능을 제공한다. 맵리듀스의 기원은 많이 알려져 있는대로 2004년 제프리딘(Jeffrey Dean)과 산제이 게마와트(Sanjay Ghemawat)의 ‘맵리듀스 : 대형 클러스터에서의 단순 처리 데이터 처리(MapReduce : Simplifed Data Processing on Lare Clusters)다. 이 논문은 구글이 대용량의 데이터를 어떻게 쪼개고 처리하고 모으는지를 설명하고 있다. 이 논문이 발표된 후 더그 커팅(Doug Cutting)은 오픈소스 검색 엔진인 너치(Nutch) 프로젝트의 확장성 문제를 해결하고자 맵리듀스 구현 작업을 시작했다. 이후 야후의 투자가 더해서 개발된 것이 하둡이다. 하둡은 지금도 릴리즈되고 있으며 새로운 기능이 더해지고 지속적인 성능 향상이 이뤄지고 있다. 분산 시스템 환경에서의 데이터 분석을 위해 머하웃을 사용해본 이들이 꽤 있을 것이다. 소셜커머스나 방송통신 등의 다양한 마켓에서 머하웃이 국내에 많이 사용되고 있다고 알려져 있다. 머하웃은 2008년부터 개발돼 다양한 알고리즘과 안정된 버전을 제공하고, 시퀀스 파일을 이용해 빠른 수행의 속도를 지원하고 있다. 하지만 머하웃을 사용해 본 사람들은 실제 데이터 분석 업무에 적용하는 데 많은 불편함이 있는 것을 느낀 적이 있을 것이다. 특히 머하웃은 데이터 분석을 하기 위해 사용자가 시퀀스 파일로 데이터 전처리를 해야 한다. 또한 분석을 할 때 속성별로 기능을 제어할 수 없다. 더구나 머하웃은 라이브러리 형태로 제공되기 때문에 CLI(Command Line Interface) 환경에서 실행해야 한다. 이로 인해 단순한 기능을 사용하더라도 머하웃의 소스 코드 레벨까지 파악한 후 커스터마이징해야 한다.국내 최초 빅데이터 분석 오픈소스 솔루션 Ankus
오픈소스 솔루션 Ankus
빅데이터 성공사례
두 번째로, 온라인 비디오 대여 업체로 시작한 넷플릭스(Netflix)는 데이터 마이닝을 사용해 자체 개발한 추천 시스템인 ‘Cinematch’를 통해 커다란 수익을 얻었다. 이뿐만이 아니다. 넷플릭스는 어려운 경영난을 겪었던 시기가 있었는데, 그 시기에 경영진들은 자사 고객의 동영상 시청 선호도를 파악한 후 1990년 BBC사의 미스터리물을 리메이크하기로 결정했다. 넷플릭스가 수집한 고객 데이터를 통해 BBC에서 제작한 드라마를 좋아하는 경우 케빈 스페이시(Kevin Spacey)가 주연한 드라마나 데이비드 핀처(David Fincher) 감독이 제작한 드라마를 직접 찾아본다는 사실을 알았기 때문이다. 따라서 이 두 사람을 리메이크 제작 과정에 참여시켰고 각각 13개의 에피소드로 이뤄진 시즌 2개를 제작하는 일에 1억 달러(한화 1000억 원)를 투자했다. 대량의 데이터 분석을 통해 선호도가 가장 높은 항목들만 적용해 드라마를 만들었던 것이다. 그 드라마가 바로 ‘하우스 오브 카드(House of Cards)’이다. 드라마는 ‘대박’을 터트렸고, 경영난에 힘들었던 넷플릭스는 제 2의 전성기를 맞이했다고 평가받는다.
또한 2011년 개봉한 브래드 피트 주연의 영화 ‘머니볼’은 경기를 분석한 데이터를 기반으로 선수들을 배치해 승률을 높이는 머니볼 이론을 사용한 실화를 바탕으로 하고 있다. 실제로 오클랜드 팀 단장 빌리 빈은 선수 스카우트를 위해 선수들을 만나서 파악을 하는 전통적인 방식에서 벗어나 선수들의 성적 데이터를 분석해 그들의 장점을 파악하고 팀을 꾸렸다. 데이터 분석으로 꾸려진 팀은 메이저리그 최초로 20연승이라는 신기록을 세웠다.
데이터 마이닝과 기계학습
데이터 마이닝은 데이터 속의 잠재적인 유용한 의미를 가진 정보를 추출하는 것이다. 또한 KDD(knowledge-discovery in databases) 과정 중의 한 단계이기도 하다. 데이터 마이닝은 다양한 관점에서 다음과 같이 정의할 수 있다.
- 의미 있는 패턴과 규칙을 발견하기 위해서 자동화되거나 반자동화된 도구를 이용해 대량의 데이터를 탐색하고 분석하는 과정(Berry and Linoff, 1997, 2000)
- 통계 및 수학적 기술뿐만 아니라 패턴인식 기술들을 이용해 데이터 저장소에 저장된 대용량의 데이터를 조사함으로써 의미 있는 새로운 상관관계, 패턴, 추세 등을 발견하는 과정(The Gartner Group, 2004)
데이터 마이닝 기법에는 예측 모델링(Predictive modeling)과 기술 모델링(Descriptive modeling)이 있다. 여기에는 분류(Classification), 군집(Clustering), 연관성(Association) 등이 존재하는데 어떠한 목적으로 활용하느냐에 따라 해당 기법들을 선택해 분석할 수 있다.
데이터 마이닝의 기법
군집(unsupervised learning) 기법은 데이터들을 유사한 성격을 가지는 임의의 그룹으로 분할하는 분석이다. 예를 들어 특징이 유사한 고객을 해당 그룹으로 분할하고 임의의 그룹별 특징을 분석한다. 학업 성취도나 능력에 따른 학생 특징 분석, 구매패턴 유사고객 특징 분석 등에 쓰인다. 연관 기법은 구매 데이터에서 반복적으로 함께 판매되는 상품들 간의 연관성에 대한 규칙을 찾아내는 분석으로, 현재 가장 많이 사용되고 있다. 장바구니 분석(마트 등의 구매상품 목록), 금융상품 구매 분석, 영화·VOD 등 디지털 콘텐츠 구매 분석 등에 쓰인다.
주요 의미 도출이 데이터 분석의 핵심

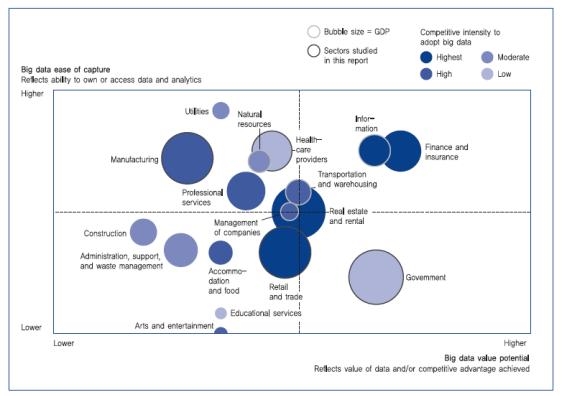
왜냐하면 빅데이터는 이전에 쉽게 접근할 수 없었던 대용량 데이터를 처리하는 데 의의를 두고 있어서 이 부분을 해결하지 않은 분석 도구는 현재 중요한 의미를 갖기 힘들기 때문이다. 사람들이 많이 사용하고 있는 트위터에서는 하루 평균 3억5000만 건의 트윗(tweet)이 발생하고 페이스북 콘텐츠도 25억 개 이상 게시되고 있다. 동영상 콘텐츠도 30초마다 한 개씩 유튜브에 올라오며, 카카오톡에서는 하루에 약 40억 개 이상의 메시지가 오고간다. 2011년만 해도 전 세계에서 약 2조GB의 데이터가 생산된 것으로 집계됐다. 우리나라도 2011년 한 해 동안 약 280억GB의 데이터가 생산·소비됐다.
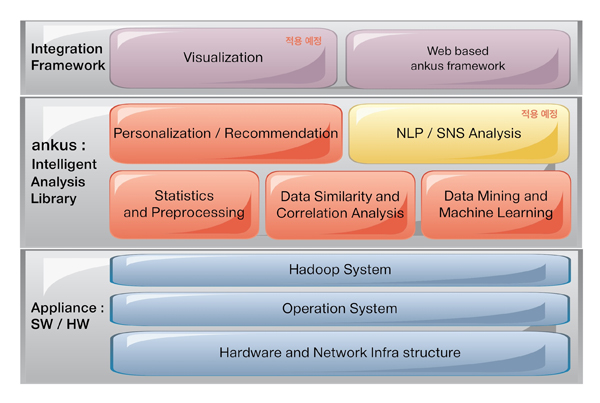
이러한 엄청난 데이터를 수용하려면 기존의 단일 머신 시스템으로는 데이터 분석이 불가능하다. 이번 시간에 소개할 하둡 기반의 빅데이터 분석 오픈소스인 Ankus(앵커스) 프레임워크를 사용한다면, 분산 처리 시스템에서 데이터 마이닝·기계학습을 사용해 데이터 분석을 효과적으로 활용할 수 있다. 또한 이전에 쉽게 접근할 수 없었던 비정형/반정형/정형의 대용량 데이터를 처리하고 분석할 수도 있다. Ankus는 하둡 기반에서 데educe)로 재설계해 개발됐다.
하둡과 맵리듀스
맵리듀스는 <그림 4>와 같이 MR Job, 맵과 리듀스라는 두 개의 함수로 나눠 구현한다. Mapper는 key-value 쌍을 input으로 받고, 결과물로 key-value 쌍으로 출력한다. map 개수는 주로 input 데이터 크기에 따라 정해진다. Reducer는 map의 중간 결과물들 중 같은 key를 가지는 것들을 합쳐서 출력한다. 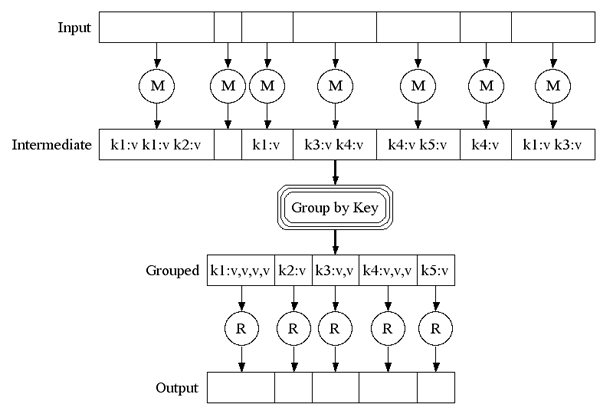
이제 데이터를 분석 처리하는 일이 남았다. 이를 위해서는 빅데이터를 활용해 분산 환경에서 운용 가능한 데이터 마이닝·기계학습 기반의 기술과 프레임워크가 필요하다. 현재 하둡 기반의 분산 빅데이터 환경에서 수행 가능한 데이터 마이닝·기계학습 분석 알고리즘을 제공하는 소프트웨어는 <표 1>과 같다.
머하웃, 그리고 Ankus
이러한 머하웃 사용의 단점들을 보완하기 위해 오픈소스 프로젝트인 Ankus가 개발됐다. 작년 2013년 9월에 0.0.1 버전이 최초 릴리즈됐고, 11월 29일에는 0.1 버전을 릴리즈한 Ankus가 탄생했다. Ankus는 사용자가 별도의 전처리 없이 입력 파일을 사용할 수 있도록 하고, 다양한 분석을 위해 속성(파라미터) 선택이 용이하도록 하는 기능을 제공한다. 또한 CLI 기반이 아닌 웹 기반(UI/UX)으로 빅데이터를 분석할 수 있다. 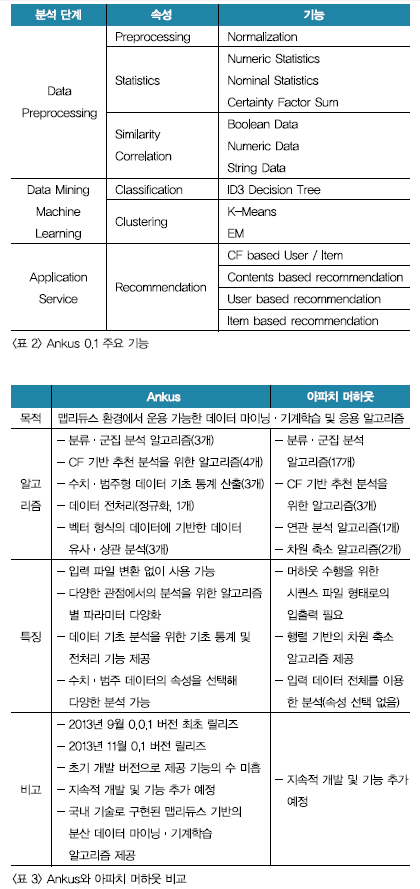
다음 시간에는 Ankus를 사용해 데이터를 분석할 수 있는 알고리즘을 알아보고, 실행해 본다.