
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
실시간 스트리밍 데이터 처리의 이해 빅데이터 분산 처리 기술의 이해 빅데이터라는 단어가 왜 일반인들에게 익숙해졌을까. 10년 전, 20년 전 아니 그보다 훨씬 이 전에도 우린 빅데이터 속에 살고 있었다. 그런데 지금에서야 이 단어가 모든 산업에서 큰 이슈로 자리잡은 건 하드웨어, 소프트웨어 기술이 발전해서다. 관념으로만 존재하던 빅데이터를 머리로 가늠하고 활용할 수 있는 시대가 온 것이다. 그리고 빅데이터 시대의 핵심은 데이터 분산 처리 기술이다. 1회에서는 실시간 이벤트 처리 기술을 설명했다. 이번 호에서는 데이터 분산 처리 방식의 기본 개념을 소개한다. 분산 처리의 기초적인 아이디어를 제공하는 병렬 처리 개념부터 이후 분산 처리의 목적과 종류, 세부사항을 설명하고자 한다. 데이터 분산 처리 기술을 이해하는 첫 번째 발걸음은 ‘Divide and Conquer’ 알고리즘이다. 정렬이나 검색에 흔히 사용하는 용어다. 이 알고리즘은 복잡하고 큰 문제를 여러 개로 나눠 각각을 하나의 단순한 문제로 만들어 해결하는 문제 해결 방식이다. 큰 문제를 작은 문제 여럿으로 나눠 단순화한 뒤 큰 문제의 답을 찾도록 돕는다. 병렬 처리가 하나의 컴퓨터 안에서 여러 개의 프로세서를 이용해 문제를 해결하는 것에 그치는 방식이라면 수십 개의 코어를 가진 슈퍼컴퓨터로만 빅데이터를 분석할 수 있다. 물론 슈퍼컴퓨터는 유용한 툴이지만 문제는 비용이다. 빅데이터 분석은 쉽지 않은 작업이다. 사업 도메인마다 빅데이터 분석 대상과 방법이 다르다. 즉 시행착오를 통해 데이터를 일일이 분석해보고 적합한 대상과 방법을 찾아야한다. 이 비용을 최소화하기 위해, 효율성을 높이기 위해 슈퍼컴퓨터 대신 분산 처리 기술을 활용하는 것이다. 투명성의 특징● 위치(Location) 분산 처리를 할 수 있는 시스템을 ‘분산 처리 시스템’이라고 부른다. 하나의 컴퓨터 또는 서버에서 처리하는 방식을 넘어 네트워크에서 원격 컴퓨터와 통신하면서 하나의 목적을 위해 여러 서버에서 연산을 처리하도록 만든 시스템이다. 그렇게 여러 서버에서 연산하는 것을 ‘분산 처리’라고 한다. 분산 처리를 위해서는 다수의 컴퓨터와 네트워크가 필요하다. 이를 클러스터라고 한다. 클러스터의 기본 구성은 컴퓨터, 고속 네트워크(LAN), 클러스터를 구현할 수 있는 소프트웨어다. 슈퍼컴퓨터가 하나의 컴퓨터 안에서 CPU, 메모리를 이용해 서로 통신했다면, 클러스터는 여러 컴퓨터가 LAN으로 통신해 데이터를 처리한다. MapReduce는 구글의 웹 데이터 분석 모델이다. 페타바이트 이상의 대용량 데이터를 저사양 컴퓨터로 구성된 클러스터에서 처리하는 것이 목표였다. 구글은 2004년 MapReduce 프레임워크와 구글의 분산 파일 시스템 논문을 함께 발표했다. MapReduce는 LISP와 같은 함수형 프로그래밍에서 일반적으로 사용하는 Map 함수와 Reduce 함수를 기반으로 한다. Map()과 Reduce()를 구현함으로써 처리해야할 데이터를 병렬화하는 것이 목적이다. 병렬화된 데이터는 클러스터의 각 노드로 보내져서 동시에 처리할 수 있게 된다. 따라서 개발자는 Map()과 Reduce()만 구현하면 뒷단의 복잡한 분산 처리 과정은 프레임워크가 처리한다. 개발자는 데이터 분석에만 집중할 수 있게 되는 것이다.
<리스트 1> 문서에서 글자 수 세는 의사코드에서 사용된 Map 함수 각각의 문서에서 띄어쓰기로 단어(w)를 구별해낸다. 그리고 단어(w)를 map 함수 안에서 세는 것이다. 그리고 단어(w)를 key값으로 개수는 value값으로하여 로컬에 저장한다. Reduce()는 Map()를 통해 출력된 값들을 새 키 단어(w)를 기준으로 그룹화(grouping) 하고, 그룹화한 값을 집계하는 역할을 한다.
<리스트 2> 문서에서 글자 수 세는 의사코드에서 사용된 Reduce 함수 단어를 key값으로 하여 그 개수인 value를 누적, 집계하여 전체 데이터 처리 결과값을 얻을 수 있다. 이때 Map, Reduce 함수와 상관없이 프레임워크에서는 Shuffle이라는 과정을 통해 같은 key 값끼리는 같은 reduce 함수가 호출되도록 한다. 이와 같은 과정을 도식화하면 다음과 같다.
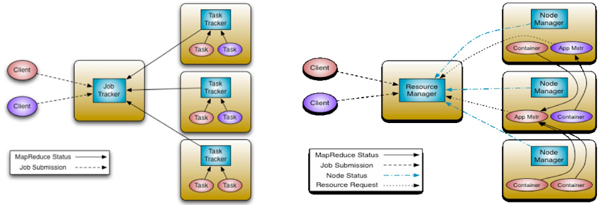
<리스트 3> Hadoop을 이용해 계산할 때 실행 로그 Hadoop을 통해 데이터를 클러스터 환경에 나눠 처리하는 기본 개념을 이해했다. 그러나 Hadoop에는 병목현상과 클러스터 내 자원의 비효율적 사용이라는 문제점이 있었다. <그림 8>을 보면 Job Tracker가 다른 Task Tracker를 관리하는 구조임을 알 수 있다. Job Tracker가 자원과 Job을 모두 관리한다는 의미다. Job Tracker에서 지연이 생기면 모든 클러스터 노드가 지연될 것임을 암시한다. 여기서 병목현상이 생긴다. 또한 하나의 노드에서 실행될 수 있는 MapReduce 작업의 개수가 제한됐다. 이 때문에 클러스터 내 자원의 비효율적 사용이라는 문제점이 초래된다. 하나의 노드에서 작업을 완료해도 아직 처리되지 않은 노드의 작업을 나눠가질 수 없는 구조다. 이러한 문제들 때문에 기존의 MapReduce 방식을 고전적인 방식으로 정의하고 이를 Hadoop 1.0, 새로운 버전을 Hadoop 2.0이라 부르게 됐다. 새 버전은 YARN(Yet Another Resource Negotiator) 아키텍처로 이뤄졌다. YARN은 1.0 버전의 한계와 문제점을 해결했다.빅데이터 분산 처리 기술의 이해
<그림1> 분산 처리의 기본
병렬 처리
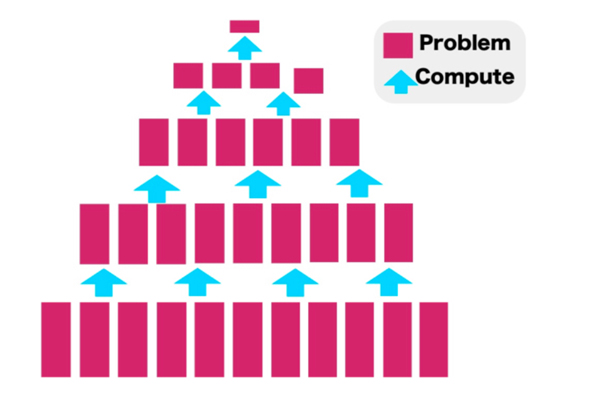
<그림 2> ‘Divede and Conquer’ 알고리즘
‘Divide and Conquer’의 가장 큰 장점은 병렬성(Parallelism)이다. 작은 문제들은 각각 독립적이어서, 같은 수준의 문제를 해결하는 과정은 서로 영향을 주지 않는다. 이는 동시에 여러 문제를 해결해 시간을 단축할 수 있다는 의미다. 예를 들면 10개의 문제가 있다. 한 사람이 하나의 문제를 풀기 위해선 평균 1분이 걸린다. 이 경우 한 명이 10개의 문제를 풀기 위해선 총 10분이 걸리지만, 10명이 투입되면 1분 안에 문제를 해결할 수 있다.
비즈니스에서 분산처리의 필요성
분산 처리를 통해 기업은 각종 시스템 자원의 투명성(Transparency)을 보장한다. 투명성이란 다수의 컴퓨터로 구성된 시스템을 가상화해 마치 한 대의 컴퓨터 시스템인 것처럼 만드는 특성이다.
파일, 입출력 장치, 프로그램, 데이터베이스 시스템 등의 자원이 어떤 컴퓨터에 있는지
알 필요 없이 이용할 수 있게 한다.● 이동(Migration)
자원을 한 컴퓨터에서 다른 컴퓨터로 이동시켜도 사용자가 이를 의식하지 않고
자원을 이용할 수 있게 한다. ● 중복(Replication)
동일한 자원이 다수의 컴퓨터에 존재하고 있더라도 사용자에게는 하나의 자원으로
보이게 하는 것이다.● 이기종(Heterogeneity)
분산 시스템이 다른 종류의 하드웨어와 소프트웨어로 구성돼 있더라도 사용자는 이들의
상이함을 의식하지 않고 이용한다.● 장애(Fault)
분산 시스템의 구성 요소(하드웨어, 소프트웨어)가 장애를 일으켜도 서비스를 제공할 수 있게 한다.● 규모(Scale)
분산 시스템의 구성 요소를 추가하거나 제거하는 등 규모 변화에 대해서도 사용자는
이것을 의식하지 않고 시스템을 이용할 수 있게 한다.
분산 처리의 종류
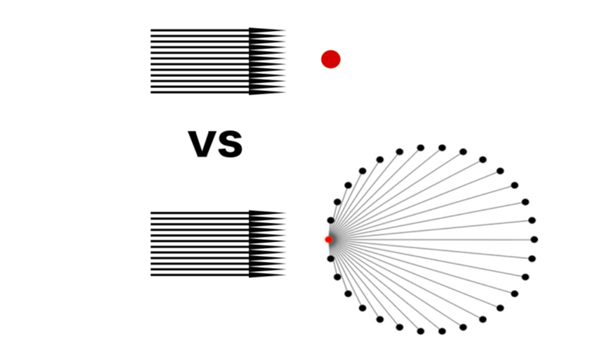
<그림 3> 기존 중앙 처리 방식 vs 분산 처리 방식
분산 처리의 종류에는 부하 분산, 처리 분산, 기능 분산, 위험 분산, 관리 분산, 확장 분산의 여섯 가지 종류가 있다. 처리 방식과 목적은 <표 1>을 참고하면 된다. 
<표 1> 분산 처리의 종류와 방식, 목적
분산 처리의 구성, 클러스터
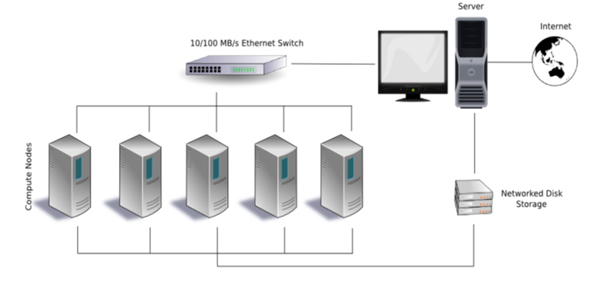
<그림 4> 클러스터의 기본 구성
클러스터의 가치는 저렴한 저성능 컴퓨터를 이용해 슈퍼컴퓨터 같은 컴퓨터 파워를 얻을 수 있다는 데 있다. 처리해야 할 작업량이 과다한 경우 로드 밸런싱을 통해 클러스터로 구성한 여러 대의 컴퓨터에 나눠 처리해 생산성을 높인다. 웹서버 클러스터링은 가장 흔한 형태의 클러스터다. 다수의 클라이언트가 접속할 경우 하나의 웹서버로는 모든 리퀘스트를 처리하기 힘들다. 웹서버 클러스터로 다수의 서버를 사용하면 웹 로드가 많아지더라도 안정적인 서비스가 가능하다. 데이터 과학 분야에도 클러스터 활용이 늘었다. 빅데이터 분석을 위해 데이터를 나누고 나뉘어진 데이터를 클러스터링된 각 컴퓨터에 보내 처리한다. 그리고 처리된 데이터의 결과를 수집해 원하는 분석데이터를 얻는다.
빅데이터 분석이 일반화 될 수 있도록 클러스터를 쉽게 활용할 수 있는 프레임워크가 공개돼 있다. Hadoop이 그 중 하나다. Hadoop이 개발자에게 제공하는 기능은 데이터를 나눠 클러스터로 보내고 그 결과를 수집하는 일련의 과정이다. MapReduce는 이를 지원하는 프로그래밍 모델이다.
MapReduce
Hadoop은 논문이 공개된 뒤 그 구조에 대응하는 체계로 개발됐다. Hadoop은 다시 아파치 재단으로 넘어가 현재의 ‘Apache Hadoop(아파치 하둡)’이 됐다.
Map()는 임의 키-값 쌍을 읽어서 이를 필터링하거나, 다른 값으로 변환하는 작업을 담당한다. 다음은 ‘MapReduce: Simplified Data Processing on Large Clusters’에 나온 Map 함수 예제이다. 문서에서 글자 수를 세는 의사코드(pseudo-code)다.
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values): // key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
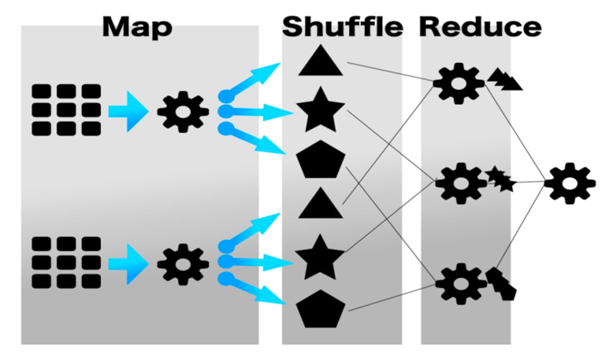
<그림 5> MapReduce 데이터 처리 과정
<리스트 3>은 실제 하둡을 이용하여 계산할 때의 실행 로그이다. <그림 7>과 같은 MapReduce 과정을 통해 데이터를 처리하고 있음을 확인해볼 수 있다.
$ hadoop jar hadoop-examples.jar wordcount /user/tester/input/input_wordcount*
/user/tester/output/wordcount
15/02/01 18:13:54 INFO input.FileInputFormat: Total input paths to process : 2
15/02/01 18:13:54 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform...
using builtin-java classes where applicable
15/02/01 18:13:54 WARN snappy.LoadSnappy: Snappy native library not loaded
15/02/01 18:13:54 INFO mapred.JobClient: Running job: job_201502010232_0001
15/02/01 18:13:55 INFO mapred.JobClient: map 0% reduce 0%
15/02/01 18:14:02 INFO mapred.JobClient: map 100% reduce 0%
15/02/01 18:14:10 INFO mapred.JobClient: map 100% reduce 100%
15/02/01 18:14:11 INFO mapred.JobClient: Job complete: job_201502010232_0001
15/02/01 18:14:11 INFO mapred.JobClient: Counters: 22
15/02/01 18:14:11 INFO mapred.JobClient: Job Counters
15/02/01 18:14:11 INFO mapred.JobClient: Launched reduce tasks=1
15/02/01 18:14:11 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=8976
15/02/01 18:14:11 INFO mapred.JobClient: Total time spent by all reduces
waiting after reserving slots (ms)=0
15/02/01 18:14:11 INFO mapred.JobClient: Total time spent by all maps
waiting after reserving slots (ms)=0
15/02/01 18:14:11 INFO mapred.JobClient: Launched map tasks=2
15/02/01 18:14:11 INFO mapred.JobClient: Data-local map tasks=2
15/02/01 18:14:11 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8752
15/02/01 18:14:11 INFO mapred.JobClient: FileSystemCounters
15/02/01 18:14:11 INFO mapred.JobClient: FILE_BYTES_READ=80
15/02/01 18:14:11 INFO mapred.JobClient: HDFS_BYTES_READ=282
15/02/01 18:14:11 INFO mapred.JobClient: FILE_BYTES_WRITTEN=153840
15/02/01 18:14:11 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=38
15/02/01 18:14:11 INFO mapred.JobClient: Map-Reduce Framework
15/02/01 18:14:11 INFO mapred.JobClient: Reduce input groups=7
15/02/01 18:14:11 INFO mapred.JobClient: Combine output records=8
15/02/01 18:14:11 INFO mapred.JobClient: Map input records=2
15/02/01 18:14:11 INFO mapred.JobClient: Reduce shuffle bytes=45
15/02/01 18:14:11 INFO mapred.JobClient: Reduce output records=7
15/02/01 18:14:11 INFO mapred.JobClient: Spilled Records=16
15/02/01 18:14:11 INFO mapred.JobClient: Map output bytes=58
15/02/01 18:14:11 INFO mapred.JobClient: Combine input records=8
15/02/01 18:14:11 INFO mapred.JobClient: Map output records=8
15/02/01 18:14:11 INFO mapred.JobClient: SPLIT_RAW_BYTES=256
15/02/01 18:14:11 INFO mapred.JobClient: Reduce input records=8
Hadoop의 진화와 YARN
<그림 6> Hadoop 1.0 아키텍처와 Hadoop 2.0 아키텍처
YARN의 경우, Hadoop 1.0의 첫번째 문제점인 병목현상을 제거하기 위해서 Job Tracker가 하던 관리 책임을 나누어 각각을 담당하는 컴포넌트를 만들었다. Resource Manager(자원 관리)는 애플리케이션에 자원을 할당하고, App Master(앱 관리자)를 관리한다. 자원 관리자는 기존처럼 클러스터에 1개만 존재한다. 그리고 클러스터의 각 노드마다 있는 Node Manager(노드 관리자)는 노드의 컨테이너를 관리해 할당된 자원 이상으로 사용하지 않도록 조절한다. App Master(앱 마스터)는 실행 중인 애플리케이션의 생명 주기를 관리하고, 상태값을 앱 마스터에 알린다. Container(컨테이너)는 실제 앱을 실행하고 상태값을 앱 마스터에 알린다. 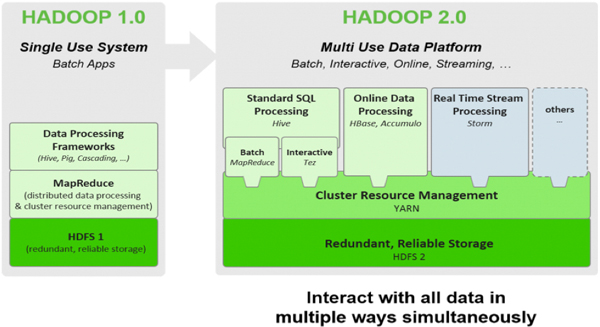
<그림 7> Hadoop 1.0과 Hadoop 2.0의 차이점
하둡 1.0의 경우는 MapReduce만을 처리할 수 있는 플랫폼인 반면 하둡 2.0의 경우는 <그림 9>처럼 YARN 위에 다양한 솔루션을 올릴 수 있는 구조다. MapReduce는 물론 Storm on YARN(실시간 스트리밍 처리), HOYA(HBase), Spark on YARN, Apache Giraph on YARN과 같이 다양한 시도가 가능해졌다는 의미다. MapReduce/YARN 개념을 이용하여 대용량의 데이터를 나누어 분배할 수 있게 됐다. 어떻게 분배할 것인가를 생각할 필요가 있다. 클러스터에는 데이터를 처리할 수 있는 여러 노드들이 있고, 해당 노드에 어떤 처리를 하도록 스케줄링을 할 필요가 생긴 것이다.