
기술자료
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
C++ 프로그래밍 동적 메모리 할당과 소멸자의 관계 C/C++를 비롯해 자바 프로그래밍의 경우 필수적으로 동적 메모리 할당을 해야만 한다. 할당된 메모리를 처리할 때는 차이가 발생한다. 자바의 경우 할당 받은 메모리 해제를 가비지 컬렉터가 알아서 수행하지만, C/C++의 경우 개발자가 직접 메모리 해제를 해야 한다. 직접 메모리 해제를 해야 하는 것이 무척 부담스러운 일인데, 해제도 꽤 많은 신경을 써야한다는 점에서 어려운 점이 있다. 메모리 해제를 엉성하게 했다가는 어느 순간 프로그램이 죽어버리는 불상사가 생기기도 한다. 이번 글의 목적은 C/C++의 동적 메모리 할당과 해제의 원리에 대해서 심층적으로 파악하고, 잘못된 메모리 해제로 인한 불상사를 겪지 않는 것이다. C/C++ 프로그래밍을 조금이라도 해봤다면 기본적으로 동적 메 모리 할당을 위하여 malloc, new, new [ ] 등을 사용해야만 하는 것을 알고 있다. 또한 해제를 위해서는 free, delete, delete [ ]를 사 용해야 한다는 것도 알고 있다. 중요한 철칙이 있는데, 할당과 해 제는 짝을 맞추어야 한다는 점이다. 즉, malloc으로 할당된 메모리 는 free로 해제하고, new는 delete로, new [ ]의 경우 반드시 delete [ ]로 해제해야 한다는 점이다. C++가 나오기 전 C에서는 메모리 할당과 해제를 위해 malloc과 free를 사용했다(메모리 할당 함수는 calloc 및 realloc과 같은 형제 함수들도 있으나, 일반적으로 대표적인 메모리 할당 함수는 malloc이다).
<리스트 1> malloc & free 원형void * malloc(size_t size); <리스트 1>에서 확인할 수 있듯이, malloc은 요청한 size만큼의 메모리를 할당해 할당된 메모리 블록의 주소를 반환한다. 할당받 은 메모리를 해제하기 위해서는 메모리 블록의 주소를 free에 인자 로 넘기기만 하면 된다. 여기서 주의할 점이 있는데, free에 넘기는 인자는 오직 malloc(calloc, realloc 포함)으로 이미 할당받은 메모 리 블록의 주소여야 한다는 것이다. 만일 유효하지 않은 주소를 free에 넘기게 될 경우 어떤 에러가 발생할지 알 수 없다(즉각적으 로 에러가 발생하지 않는 경우도 많다. 이런 경우 디버깅은 더욱 어려워질 수밖에 없다). malloc과 free만 있던 시절에는 나름 메모리 할당과 해제가 명확 했다. 필요에 따라서 malloc(calloc, realloc)으로 메모리를 할당받 고, 해제할 때는 오직 free만 호출하면 큰 문제가 없기 때문이다. 그러나 C++로 발전되면서 new와 delete가 추가된다. new와 delete는 확실히 malloc과 free에 비해 사용하기가 쉬운 면이 있다.
<리스트 2> malloc & free / new & deletevoid main() <리스트 2>는 (malloc, free)와 (new, delete)의 사용법 비교를 보여준다. 각각 int 단일 객체와 int 배열 객체를 할당 받아서 값을 채우고, 할당된 메모리를 해제하는 과정을 보여준다.
<리스트 3> 생성자, 소멸자 호출class CTest <리스트 3>은 클래스의 생성자와 소멸자가 언제 호출되는지 살 펴보기 위한 예제코드다. ①~③과 같이 CTest 객체는 각각 전역 객체, 지역 객체, 그리고 동적 할당된 객체로 테스트를 했다. ①, ②와 같이 클래스 객체가 전역 객체거나 함수의 지역 객체일 경우 컴파일러는 어떤 클래스 타입의 객체가 생성되는지 알 수 있다. 따 라서 ①, ②의 경우 생성자가 제대로 호출된다. 그러나 ③처럼 클 래스 객체를 malloc을 사용해 생성할 경우 생성자를 호출할 수가 없다. 앞에서 살펴보았듯이 malloc은 오직 인자로 받은 크기만큼 메모리를 할당하고, 해당 메모리 블록을 가리키는 주소만을 반환 하는 함수이기 때문이다. 즉, malloc이 호출되는 순간에는 어떤 클 래스 타입의 객체가 생성되는지를 알 수 없다. 알 수 없는 클래스 의 생성자를 호출할 수는 없지 않겠는가 따라서 위의 예제에서 생성자는 오직 단 두 번만 호출된다.
<리스트 4> delete와 소멸자 <리스트 4>는 delete의 동작 방식을 보여주기 위한 코드다. 다음 은 출력 결과다. new와 delete가 생성자와 소멸자를 호출하기 위하여 도입되었 다는 것을 충분히 이해했을 것이다. 마찬가지로 new [ ]와 delete [ ]도 배열의 모습을 보이고 있을 뿐, 목적은 같을 것이라고 충분히 예상할 수 있다.
<리스트 5> new [] & delete []class CTest <리스트 5>의 ①을 살펴보자! CTest 배열을 동적으로 할당 받는 다. 배열 요소는 2개이다. 그리고 ②에서 할당 받은 메모리를 해제 한다. 결과를 확인해보면 생성자 메시지 2번, 소멸자 메시지가 2번 출력된다. 너무나 당연한 것이라고 생각하지만 그 과정은 꽤 복잡 하다. 바로 new [ ]와 delete [ ]가 배열 요소의 개수만큼 생성자와 소멸자를 호출하는 과정이 간단하지만은 않기 때문이다. <그림 2>를 통해서 CTest의 단일 객체 할당을 위한 new의 처리 과정을 살펴보자! new를 호출할 경우 내부적으로는 malloc이 호 출된다. malloc은 힙 관리자에게 메모리 할당을 요청하며, 힙 관리 자는 관리하고 있는 힙에서 적절히 4바이트(CTest의 크기) 만큼의 메모리 블록을 찾은 뒤에 해당 블록의 주소를 반환한다. 동시에 힙 관리자는 해당 블록의 주소를 할당 내역에 추가한다. malloc을 통 해서 할당 받은 메모리 블록의 주소를 new는 그대로 다시 반환한 다. 그래서 CTest* pT는 힙 관리자가 할당해준 메모리 블록 주소 인 Address를 가지게 된다. <그림 3>은 정말 중요하다. 바로 클래스 타입의 배열 객체를 new [ ]를 통해서 할당하는 과정을 보여주기 때문이다(참고로 CTest에는 명시적으로 소멸자가 정의되어 있음을 주의하자). pT는 new [ ]를 통해서 CTest 객체 2개를 요소로 가지는 배열을 가리키게 된다. new [ ]를 호출하면 내부에서 malloc을 호출하는 것은 같지만, malloc으로 넘기는 인자에 변화를 준다. CTest의 크 기가 4이고, 배열 요소가 두 개라서 필요한 메모리 공간은 2 * sizeof(CTest) = 8이 된다. 그런데 new [ ]의 경우 실제 필요한 메모 리 크기 8에 추가로 4를 더해서 12 바이트를 malloc에 요청한다. 힙 관리자는 요청 받은 12바이트만큼 메모리 블록을 반환하게 된 다. 그러나 반환 또한 변형이 일어난다. 힙 관리자가 반환해준 주 소인 Address에 4를 더한 주소를 new [ ]가 반환하는 것이다. 즉, pT가 나타내는 주소는 Address + 4가 된다. 그렇다면 추가적으로 요청된 4바이트 영역에는 어떤 정보가 저장되는 것일까 바로 배 열의 요소 개수인 2가 저장되는 것이다.
<리스트 6> delete & delete []class CTest <리스트 6>의 ①, ② 부분을 주의해서 살펴보자. 아마 초급 개발 자가 저런 코드를 구사한다면, 선임 개발자에게 크게 한 소리 들을 것이다. 그러나 아직까진 VC++이나 GCC 컴파일러에서 해당 코 드는 아무 문제없이 잘 돌아간다(이번에는 CTest에 소멸자가 정의 되지 않았다). C/C++의 동적 메모리 할당에 대한 상세한 구조와 원리를 파악 할 수 있었다. 아마도 왜 그렇게 수많은 C/C++ 책에서 (new, delete), (new [ ], delete [ ])를 짝 맞춰 사용하라고 강조하는지 충 분히 이해하게 됐을 것이다.C++ 프로그래밍 : 동적 메모리 할당과 소멸자의 관계
1. 메모리 할당과 해제
이런 철칙을 잘 지키는 프로그래머는 훌륭한 자질을 가지고 있 다고 할 수 있다. 왜 철칙이겠는가 반드시 지켜야만하기 때문에 철칙인 것이다. 다른 말로 하면 철칙을 지키지 않으면 그만한 대가 를 치르게 된다는 것을 의미한다.
그러나 필자 같은 삐딱한 프로그래머는 왜 그것이 철칙이어야 하는지 도통 이해하기가 어려웠다. ‘그냥 free나 delete로 통일하면 얼마나 좋아!’라며 늘 의문을 가졌다. 지금부터 필자가 품은 의문을 풀어보자!
2. malloc & free
void free(void* memblock);
malloc과 free의 동작을 통해 추측할 수 있는 것이 있는데, 바로 C 내부적으로 malloc으로 할당받은 메모리 블록의 주소와 크기를 관리하고 있다는 점이다. 실제로 CRT(C Runtime Library)의 힙 매니저는 malloc으로 할당된 메모리 내역을 관리하며, free의 요청 에 대응한다.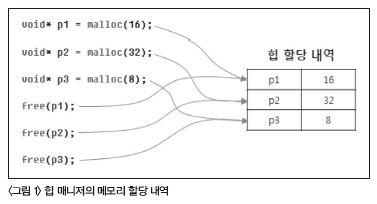
<그림 1>처럼 힙 관리자는 메모리 블록을 할당할 때마다 메모리 할당 내역을 저장하게 된다. 그림의 할당 내역 테이블에는 p1, p2, p3처럼 이름이 들어가 있지만, 실제로는 p1, p2, p3의 메모리 주소 가 들어가게 된다. free를 호출하게 될 경우 힙 관리자는 인자로 넘 어온 메모리 주소를 할당 내역에서 검색해 존재할 경우 할당된 크 기만큼 해당 메모리 블록을 해제하고, 할당 내역에서 삭제한다.
3. new & delete
{
int* p1 = (int*)malloc(sizeof(int)); // ①
*p1 = 1;
int* p2 = new int; // ②
*p2 = 2;
int* pArr1 = (int*)malloc(sizeof(int) * 2); // ③
pArr1[0] = 0;
pArr1[1] = 1;
int* pArr2 = new int[2]; // ④
pArr2[0] = 2;
pArr2[0] = 3;free(p1); // ⑤
delete p2; // ⑥
free(pArr1); // ⑦
delete [] pArr2; // ⑧
}
①만 봐도 알 수 있듯이, malloc은 사용하기에 불편한 점이 있 다. 인자로 할당할 메모리 크기를 알려주기 위해서 sizeof(int)를 사 용해야 한다(혹시라도 sizeof(int) 대신 타이핑이 귀찮다고 4를 쓰 는 경우도 있는데, 정말 좋지 않은 코딩 습관이라고 할 수 있다. 혹 시 아는가 지금 작성한 코드가 먼 훗날에도 재활용되는데, 그때는 int가 8바이트가 될 수도 있기 때문이다. 그 외에 클래스 타입의 경 우 클래스의 크기는 여러 요인으로 인해서 눈으로 보이는 멤버들 의 크기 합보다 큰 경우가 많다). 또한 mallc에 의해서 반환된 포인 터는 void*로서 메모리 덩어리를 가리키는 주소일 뿐이다. 따라서 의미있는 포인터로 사용되기 위해서는 반드시 (int*)와 같이 타입 변환을 해줘야한다. 그에 비해서 ②의 new를 살펴보면 천지개벽이 일어난 것 같다. malloc의 단점을 한 번에 해소해주고 있다.
③과 ④는 malloc과 new를 이용한 배열 할당 비교다. 첫눈에 봐 도 알 수 있듯이 malloc보다는 new를 사용하는 편이 훨씬 간결하 고 쉬워 보인다는 것을 알 수 있다.
이제 할당된 메모리를 해제해보자! ⑤, ⑥은 int 단일 객체의 메 모리를 해제한다. 사실 별 차이가 없다. 그러나 ⑦, ⑧과 같이 배열 객체의 메모리 해제에서는 큰 차이가 발생하는데, 바로 delete 뒤 에 [] 기호가 사용되고 있다는 사실이다.
예제만 봤을 때는 new와 delete가 단지 malloc과 free를 좀 더 쓰기 편하도록 대체하기 위해서 만든 것으로 생각할 수 있다. 분명 좋은 방향의 개선은 맞다. 하지만 delete를 살펴볼 때 절대 사용 편 의성 개선이 목적은 아닌 듯하다. 만일 단순 편의성만을 생각했더 라면 필자의 경우 delete 자체를 만들지 않고, 오직 free만 사용하 도록 했을 것이다.
사실 new와 delete에는 다른 목적이 숨어호출하고, delete도 역시 내부적으로 free를 호출한다. 결국 CRT에서 동적 메모리를 할당 해제하는 함 수는 오직 malloc과 free라고 할 수 있다. 즉, C++에서 새롭게 도 입된 new와 delete는 메모리 할당과 해제를 malloc과 free에게 맡 기고 나머지 추가적인 처리를 하는 연산자다. 결국 추가적인 처리 를 위해서 반드시 new와 delete를 사용해야 한다. 이것은 절대로 malloc과 free가 대신할 수 없다.
그렇다면 추가적인 처리란 무엇일까 바로 생성자와 소멸자의 호출이다. 생성자와 소멸자는 C++에 클래스가 도입되면서 나타 났다. 클래스 객체는 기본적으로 생성되면서 생성자가 호출되고, 사라지면서 소멸자가 호출되도록 만들어졌다.
{
public:
CTest() // ?
{
cout < < "Constructor!" < < endl;
}
~CTest() // ?
{
cout < < "Destructor!" < < endl;
}
};
CTest g_T; // ①
void main()
{
CTest t; // ②
CTest* pT = (CTest*)malloc(sizeof(CTest)); // ③
free(pT);
}
이제 소멸자를 살펴보자. ①의 전역 객체 g_T는 프로그램이 끝 나는 시점에, ②의 지역 객체 t는 main이 끝나는 시점에 각각 소멸 자가 호출된다. 컴파일러가 t와 g_T가 CTest 타입이란 것을 알고 있기 때문에 가능한 일이다. 그러나 free를 이용해 동적으로 할당 된 객체 pT를 해제할 때는 소멸자를 호출할 수 없다. 왜냐하면 free는 오직 인자로 받은 포인터의 주소를 가지고 힙 관리자에게 해당 포인터가 가리키는 메모리 블록을 해제하는 일만 하기 때문 이다.
결국 기존의 malloc과 free로는 동적 할당으로 생성되는 클래스 객체의 생성자와 소멸자를 호출할 방법이 없으며, 이를 해결하기 위해서 new와 delete를 만들게 된 것이다.
그렇다면 new와 delete는 어떻게 설계돼 있을까 눈치 빠른 독 자라면 예상할 수 있듯이 new는 malloc을 통해 메모리를 할당 받 고, 할당 받은 메모리 영역에 대해 생성자를 호출하는 역할을 수행 한다. 따라서 생성자 호출을 위해 반드시 타입을 알고 있어야만 하 기 때문에 new 뒤에는 생성하고자 하는 객체의 타입, 즉 클래스가 들어가게 된다. 당연히 내부적으로 malloc을 호출할 때는 타입의 크기를 알아내서 인자로 넘긴다.
delete 또한 마찬가지다. 뒤에 오는 포인터의 타입이 클래스일 경우 해당 클래스의 소멸자를 호출한 후에 free를 호출해 메모리를 해제하게 된다.
class CTestA
{
public:
CTestA() {}
~CTestA()
{
cout < < "CTestA::Destructor!" < < endl;
}
};
class CTestB
{
public:
CTestB() {}
~CTestB()
{
cout < < "CTestB::Destructor!" < < endl;
}
};
void main()
{
CTestA* pA = new CTestA;
CTestB* pB = (CTestB*)pA; // ①
delete pB; // ②
}
CTestA::Constructor!
CTestB::Destructor!
CTestA의 생성자가 호출되고, CTestB의 소멸자가 호출된다. 여 기서 delete의 동작 원리를 파악할 수 있다. 컴파일러는 delete의 해제 포인터의 타입을 체크해 해당 타입, 즉 클래스의 소멸자를 호 출한 뒤에, 메모리 영역을 해제하는 어셈블리를 작성하는 것이다. 따라서 ①의 pB가 실제로는 CTestA의 객체임에도 불구하고, CTestB의 소멸자가 호출된다.
C++에 new와 delete가 왜 도입될 수밖에 없는지 알아보았다. 결국 핵심은 동적 생성 클래스 객체를 위해서 생성자와 소멸자를 호출하기 위한 것이다. 그렇다면 new와 delete는 생성자와 소멸자 가 존재하는 클래스 타입에만 사용해야 하는 것일까 실제로는 기 본 타입인 int나 double에도 사용할 수 있다. 바로 범용성을 위해 서다. 타입에 따라서 new나 malloc이 섞여서 사용되는 것이 보기 에 좋지는 않다. 게다가 클래스에 항상 생성자와 소멸자가 반드시 존재하는 것도 아니다. 명시적으로 생성자와 소멸자가 존재하지 않을 경우에는 컴파일러가 암시적으로 기본 생성자와 소멸자를 추 가하기도 하지만, 정말 간단한 클래스의 경우 컴파일러가 아예 암 시적인 생성자와 소멸자를 생성하지 않기도 한다. 즉, 경우에 따라 서는 생성자와 소멸자가 아예 없을 수도 있는데, 이런 경우 오직 malloc만 사용해야 한다면 정말 프로그래밍 하기에 피곤해질 수 있다. 따라서 그런 구분은 오직 컴파일러에게 맡겨버리고 개발자 는 new와 delete를 자유롭게 사용하기만 하면 되는 것이다. 즉, new와 delete를 사용하면 알아서 생성자나 소멸자를 호출하고, 생 성자나 소멸자가 없을 경우 호출하지 않는다.
4. new [] & delete []
{
public:
CTest()
{
cout < < "CTest::Constructor!" < < endl;
}
~ CTest()
컴파일러는 어떻게 생성자와 소멸자를 2번씩 호출해야만 하는 것을 아는 것일까 생성자를 두 번 호출하는 것은 사실 쉽다. ①에 보면 친절하게 첨자로 [2]라고 써주었으니 컴파일러는 쉽게 생성 자를 2번 호출하는 코드를 작성할 수 있다. 문제는 소멸자를 두 번 호출하는 것이다. ②를 살펴보자! delete [ ]에 전달되는 정보는 오 직 CTest* TArray 뿐이다. TArray는 배열 객체를 가리키는 포인 터인데, 포인터는 말 그대로 메모리 블록을 가리키는 주소일 뿐이 지, 이것을 통해서 배열 요소의 개수를 알아낼 수는 없다. 즉, 소멸 자를 2번 부르기 위해서 컴파일러는 새로운 마법을 부려야만 하는 것이다. 이제부터 그 마법의 원리를 살펴보자!
앞에서 살펴본 내용을 떠올려보자! 힙 관리자는 메모리 할당 내 역을 관리하고 있으며, malloc이 호출될 경우 할당 내역에 추가되 고, free가 호출되면 할당 내역에서 삭제된다. 여기서 할당 내역이 란 할당된 메모리 블록의 주소와 크기 정보다. 할당 내역을 관리하 는 자료구조는 당연히 컴파일러마다 다를 수 있지만 결국 할당 내 역을 통해서 검색, 추가, 삭제하는 과정은 동일하다고 할 수 있다. 또 하나 떠올려야 하는 내용은 new와 delete의 경우 내부적으로 malloc과 free를 호출한다는 것이다. 마찬가지로 배열 타입의 new [ ], delete [ ]도 내부적으로는 malloc과 free를 호출한다. 즉, 힙 관 리자의 할당 내역에 추가 삭제를 하는 것은 직접적으로 new와 delete가 아니라 내부에서 호출되는 malloc과 free일 뿐이다.
여기서 중요한 점이 있는데, 단일 객체 타입의 new와 delete는 malloc과 free를 그대로 호출하지만 배열 타입의 new [ ], delete [ ] 는 malloc과 free를 그대로 호출하지 않는다는 것이다. 당연히 배 열 타입이기 때문에 다른 면이 있겠지만, 가장 큰 차이점이라고 한 다면 할당 및 해제되는 메모리의 구조 자체가 다르다는 것이다. 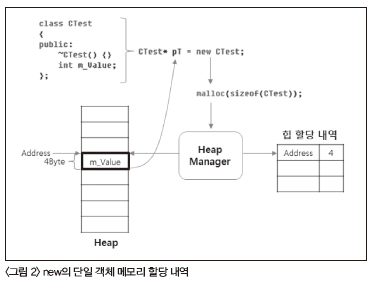
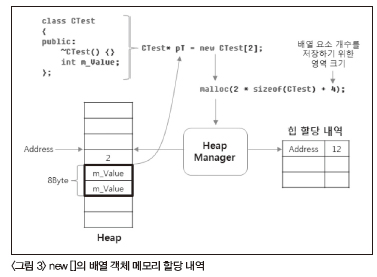
그렇다면 왜 이런 거추장스러운 구조를 가지게 되었을까 이것 이 바로 배열 타입 객체의 소멸자를 배열 요소 개수만큼 호출하기 위한 마법의 근원이기 때문이다. delete는 메모리를 해제해야 할 때, 이미 메모리에 저장된 배열 요소의 개수를 확인해 그만큼 소멸 자를 호출할 수 있는 것이다. 참고로 배열 요소 개수를 저장하는 공간은 x86이나 x64 모두 4바이트다. 왜냐하면 4바이트 정도면 개 수 정보는 충분히 저장할 수 있기 때문이다. 설마 배열 요소 개수 가 42억개를 넘겠는가
이제 pT를 해제한다고 생각해보자! 즉, delete [ ] pT;를 호출하 면 어떤 과정이 펼쳐질까 여기서 delete pT;가 아니라 delete [ ] pT;가 사용됨을 주의해야 한다. delete [ ]의 의미는 해당 포인터가 가리키는 메모리 블록이 배열 타입으로 할당됐음을 알려준다. delete [ ] pT;가 호출되면 컴파일러는 pT가 배열 타입이므로, pT 가 가리키는 메모리 주소에서 4를 빼고, 그 곳에서 바로 배열 요소 의 개수를 알아낼 수 있다. 배열 요소의 개수를 알아내면 당연히 그만큼 반복하면서 소멸자를 호출하면 된다. 동시에 메모리를 해 제하기 위해 내부적으로 free를 호출할 때도 pT가 가리키는 주소 에서 4를 뺀 값을 인자로 넘기게 된다. 당연히 힙 관리자는 할당 내역에서 할당 정보를 찾을 수 있고, 12바이트를 정확하게 해제할 수 있는 것이다.
만일 delete [ ] pT;가 아니라 delete pT;를 호출하면 어떤 일이 벌어질까 컴파일러는 delete pT;에 대해서 단일 객체라고 판단하 기 때문에 소멸자는 한 번만 호출하고, pT 주소를 그대로 free에 인자로 넘기게 된다. 그러나 힙 관리자는 할당 내역에서 pT의 주 소를 찾을 수 없기 때문에 메모리는 제대로 해제되지 않는다. 즉, free에 유효하지 못한 주소를 넘기게 되므로, 치명적인 오류로 이 어질 가능성이 크다.
여기서 잠깐! 위에서 CTest에 명시적으로 소멸자가 정의되었음 을 주의하라고 했다. 무슨 말일까 new [ ], delete [ ]의 마법은 오 직 소멸자가 존재하는 타입에 대해서만 적용된다. 즉, CTest에 소 멸자가 아예 존재하지 않는다면 new [ ], delete [ ]의 동작 방식은 기본 타입인 int 배열처럼 동작한다는 의미이다.
<그림 4>는 소멸자가 존재할 수 없는 기본 타입인 int의 배열 객 체에 대한 new [ ]의 처리 과정을 보여준다. 소멸자를 호출할 필요 가 전혀 없기 때문에, 배열 요소의 개수를 추가적으로 저장할 필요 가 전혀 없다. 이것의 정확한 의미는 무엇일까 바로 delete와 delete [ ]의 구분이 무의미해진다는 것이다. 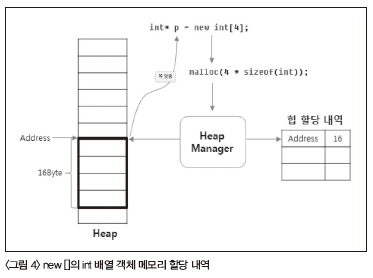
{
public:
int m_Value;
};
int main()
{
int* p = new int[2];
CTest* pT = new CTest[2];
delete p; // ①
delete pT; // ②
return
이미 살펴본 것처럼 소멸자가 존재하지 않는 int나 CTest의 경 우 delete나 delete [ ]의 구분이 무의미해진다. 컴파일러는 delete [ ]의 타입을 확인해 소멸자가 존재하지 않을 경우 해당 포인터가 가 리키는 주소를 그대로 free에 인자로 넘기기 때문이다. 결국 delete 와 똑같은 동작을 하기 때문에 해당 코드처럼 delete [ ] 대신 delete 를 써줘도 문제가 없다.
그러나 필자도 저런 코드를 본다면 분명히 초급 개발자에게 한 소리 할 것이다. 초급 개발자가 delete [ ]의 동작 원리를 이해해서 저렇게 사용할 리가 없기 때문이다. 설령 클래스에 소멸자가 없음 을 확실히 파악해서 일부러 delete를 썼다고 해보자! 나중에 유지 보수 하는 과정에서 클래스에 소멸자가 생길지는 아무도 알 수 없 는 일이다.
참고로 현재 버전의 컴파일러야 저런 경우가 문제되지 않는다고 해도 가까운 미래에 C++ 위원회와 컴파일러 제작사가 new [ ]를 사용하면 반드시 무조건 delete [ ]만 사용하도록 강제 사항을 추가 할 수도 있다. 결국 new [ ]를 사용했으면, 짝을 맞추어서 delete [ ] 를 사용하는 것이 가장 합리적인 선택이다.
마지막으로 주의할 점은 다음과 같다. CTest에는 소멸자가 존재 하지 않는다. 명시적으로 소멸자를 정의하지 않았기 때문에 소멸 자가 없는 것이 아니라, 컴파일러가 암시적으로 추가할 필요가 없 기 때문에 소멸자가 존재하지 않는 것이다. 명시적으로 소멸자가 정의되어 있지 않아도 컴파일러가 필요하다고 판단하면 암시적으 로 소멸자를 추가한다.
암시적 생성자와 소멸자가 어떤 기준으로 추가되는지를 이해하 기 위해서는 역시 많은 지식을 필요로 한다. 설명할 내용이 많기 때문에 생성자와 소멸자에 대한 설명은 다음 기회로 미루겠다.
정리
C++의 철칙을 제대로 지키려는 것은 무척 중요하다. 왜 철칙을 반드시 지켜야만 하는지를 정확히 이해하고 있다면 반드시 철칙을 따르게 될 것이다.