
전문가칼럼
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
엔코아 정보 컨설팅 SELECT D.부서명, E.성명, E.주소 SELECT D.부서명, E.성명, E.주소 SELECT D.부서명, E.성명, E.주소 SELECT D.부서명, E.성명, E.주소 관계형 데이터베이스 분석/설계 기본으로 돌아가자! 관계형 이론을 근간으로(4)
장희식
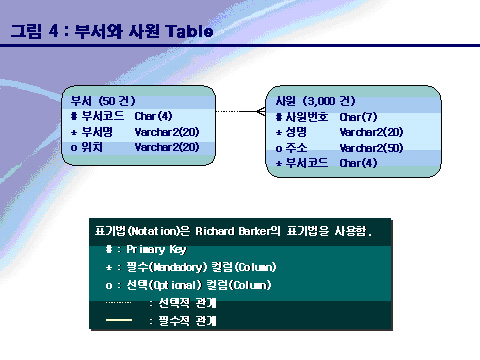
옵티마이져(Optimizer)의 간단한 원리를 설명하며 논리를 전개해 나가겠다. Oracle의 경우 부서와 사원의 테이블을 가지고 다음과 같은 SQL을 수행 시켰다고 가정 해보자.
FROM 부서 D, 사원 E
WHERE D.부서코드 = E.부서코드
첫 번째 부서 테이블을 먼저 읽는 경우를 보자. 부서 테이블의 정보를 한 건 읽고, 그 읽은 “부서코드”를 가지고 사원 테이블을 읽으러 간다. 사원 테이블의 “부서코드”에는 인덱스(Index)가 달려있지 않으므로 Full Table Scan을 한다. 이런 식으로 데이터를 읽어 간다면 부서 테이블의 50건에 대하여 50번 사원 테이블을 Full Table Scan 할 것이다.
두 번째 사원 테이블을 먼저 읽는 경우를 보자. 사원 테이블의 정보를 한 건 읽고, 그 읽은 사원의 “부서코드”를 가지고 부서 테이블을 읽으러 간다. 부서 테이블의 “부서코드”는 Primary Key로 Unique Index가 달려 있으므로 Unique Index Scan을 한 건 만 수행하고 정보를 제공할 것이다.
물론 데이터의 건수가 적은 경우는 Full Table Scan이 빠르겠지만 여기서는 Nested Loop조인의 원리를 설명하는 것이므로 실지로 테스트를 해보고 별 차이가 없네요 한다면 좀 곤란하다. 만약에 은행의 고객 테이블이나 계좌 테이블처럼 엄청난 양의 데이터를 가진 테이블을 대상으로 테스트를 해 본다면 확연히 속도의 차이가 나타날 것이다.
상식적으로 생각을 하더라도 첫 번째 방식은 Full Table Scan을 50번 반복하므로 문제가 많다. SQL문장 내에서 Join의 조건이 되는 컬럼 즉, 논리적으로 PK와 FK의 관계에 있는 컬럼(여기서 논리적이라는 얘기는 물리적으로 데이터베이스 내에 FK Constraint를 설정하지 않았다는 말이다)에 한 쪽에만 Index가 걸려 있는 경우를 “연결 고리 이상”이라고 한다. 이런 경우 옵티마이져는 무조건 Index가 걸려있지 않은 테이블을 먼저 읽는다. 하지만 다음과 같은 경우는 인덱스가 없다 하더라도 “연결 고리 이상”이라고 할 수 없다.
FROM 부서 D, 사원 E
WHERE D.부서코드 = E.부서코드
AND E.직급 = “부장” (직급 컬럼에 인덱스가 있슴)
FROM 부서 D, 사원 E
WHERE D.부서코드 = E.부서코드
AND D.위치 = “부산” (위치 컬럼에 인덱스가 있슴)
자 이제 부서 테이블의 “부서코드”와 사원 테이블의 “부서코드”의 Data Type이 틀린 경우를 보자.

FROM 부서 D, 사원 E
WHERE D.부서코드 = E.부서코드
AND E.직급 = “부장” (직급 컬럼에 인덱스가 있슴)
중요한 것은 동일 성격의 데이터가 데이터 타입이 틀리면 위와 같이 인덱스 스캔을 못하고 Full Table Scan을 하여 수행 속도에 엄청난 폐를 끼칠 수도 있다는 것이다.
실체 무결성
데이터 구조의 세 번째 특성을 알아보자. 세 번째 특성은 각 행(Row)은 유일(Unique)하다라는 것인데 달리 표현하면 각 행(Row)은 하나 이상의 열(Column)의 값(Value)에 의하여 유일(Unique)하게 식별(Identify)될 수 있어야 한다. Primary Key에 대한 것을 규정하고 있다. 즉, Primary Key를 가지지 않으면 이는 테이블로 간주하지 않는다. 왜 이러한 특성을 가져야만 하는지를 실체 무결성(Entity Integrity)과 함께 설명을 하겠다.
실체 무결성(Entity Integrity)의 정의는 위에서 말한 것 처럼 주식별자(특정 행을 유일하게 인식하는 하나 이상의 열)는 Null 값을 포함하지 않는다. ”이다. Null이라는 값은 논리적으로는 “모르는 값”이라는 의미를 가진다. 우리가 현실 세계에서 어떤 하나의 개체를 인식하고자 할 때 그 개체를 인식할 수 있는 어떤 값이 주어져 있지 않더라도 그 개체를 인식할 수 있는 무엇 인가가 우리 머리 속에 떠오른다. 이 떠오르는 그 무엇이 그 개체의 형상(Image)이든, 어떤 숫자이든 상관 없이 그것은 Null(모르는 것)이 아니라는 것이다. 이런 이유에서 테이블에서 하나의 개체(인스턴스)를 인식하려면 Null(모르는 것)이어서는 안 되는 것이다. 그런데 내가 베토벤이라는 것에 대해서 얘기하고 있다고 가정을 해보자. 여기에서 내가 말하는 베토벤을 어떤 사람은 음악가 베토벤으로 인식할 것이고, 어떤 사람은 영화에 나오는 개 베토벤이라고 인식할 수 있다. 인간은 전후 문맥이나, 전체적인 상황을 판단하면서 이것이 음악가를 얘기하는 것인지 영화에 나온 개를 얘기하는 것인지를 판단한다. 하지만 컴퓨터는 주식별자(Primary Key)를 선정 할 때는 무엇인가 값(Not Null)을 가지며, 항상 유일(Unique)한 값을 가져야만 하나의 개체(인스턴스)를 정확하게 찾아낼 수 있는 것이다.
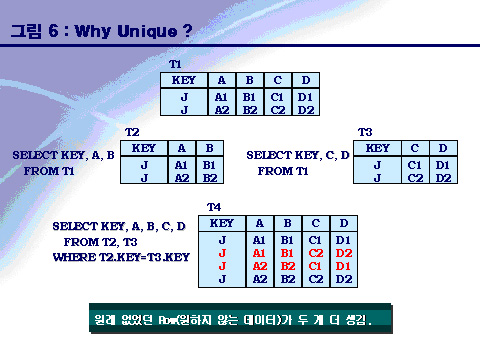
Primary Key가 유일하지 않으면 어떤 현상이 발생하는가 T1 테이블의 PK가 유일하게 구성되지 않았다고 가정을 해보자.
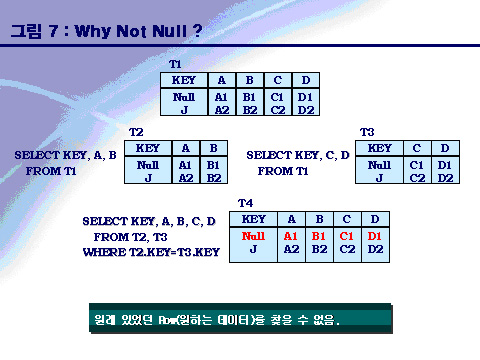
Primary Key가 Null값을 가지면 어떤 현상이 발생하는가 T1 테이블의 PK가 Null값을 갖는다고 가정을 해보자.
이러한 특성 외에 우리가 별도로 Primary Key의 선정 기준을 좀 더 살펴보면 Primary Key를 구성하는 각각의 컬럼수를 최소한의 집합(Minimal Set)으로 할 것과, 값의 수정이 없는 것, 업무적으로 활용도가 높은 것등을 들 수 있다. 최소한의 집합이 아니면 유일성(Unique)이 깨질 수 있으며, 값의 수정이 있는 것은 상기의 예에서 지점코드가 통폐합에 의해서 바뀐다던가 상품이 증가하여 자릿수가 늘어난다든가 하면, 자식 테이블에 미치는 영향이 많으므로 될 수 있으면 이런 컬럼들은 Primary Key 선정에서 제외한다.
다시 한번 강조하지만 관계형 데이터베이스 이전의 환경에서는 이렇게 값의 변화가 있는 컬럼 이라 해도 Key = Index이므로 즉 업무적으로 활용도가 크므로 이런 컬럼을 Primary Key로 잡았지만, 관계형 데이터베이스에서는 Primary Key는 값을 가지면서, 유일성만 보장해주면 되고, 업무적인 활용도는 인덱스(Index)를 설정하여 해결하면 된다. 관계형 데이터베이스에서 인덱스는 Key가 아닌 컬럼에도 언제든지 만들었다 제거했다 할 수 있으니 과거의 개념을 가지고 계신 분들은 이 점을 유의하기 바란다.
데이터 구조의 특성 중 나머지 세가지는 크게 고려를 안 해도 되는 사항으로 설명을 생략하겠다. 지금까지 데이터 구조의 특성 중에 세 가지와 데이터의 조작, 그리고 무결성 개념에서 실체 무결성과 영역무결성에 대해서 설명을 하였다. 이제 마지막으로 참조 무결성(Referential Integrity)에 대해서 알아보자.