
전문가칼럼
DBMS, DB 구축 절차, 빅데이터 기술 칼럼, 사례연구 및 세미나 자료를 소개합니다.
월등한 데이터 처리, 속도의 혁신 - Data Partitioning 기술 DB2의 다양한 Data Partitioning 기술을 통해 대용량 데이터를 빠르게 처리한다. 필자는 수년간 여러 명의 데이터베이스관리자를 만나보았다. 대부분 그 데이터베이스 관리자들은 본인이 관리하고 있는 데이터베이스가 모두 대용량 데이터베이스이라고 생각한다. 그럼 과연 여기 말하는 대용량 데이터란 어느 정도의 데이터를 말하는 것일까 몇 백 기가 바이트(Giga Byte) 또는 몇 테러바이트(Terabyte)이상이면 대용량이다 아니다라는 정량적 기준은 없다. 단지 DBMS가 운영되는 시스템에 얼마 만큼의 데이터를 처리 가능한지에 따라 대용량인지 아닌 지로 구분되어 지는 것이 맞을 듯하다. TPF (Table Partitioning Feature) DPF (Data Partitioning Feature)월등한 데이터 처리, 속도의 혁신 Data Partitioning 기술
그래서, 기존의 데이터에서 테이블의 조합을 이용하여 데이터를 조회하기 보단 뷰(view)나 새로운 요약 테이블 등을 생성하여 보다 간편하고 빠르게 데이터를 조회하려고 한다. 업무의 부하가 많은 데이터베이스 시스템의 경우, 운영환경의 테이블을 직접 접속하여 조회하기보단 복제본의 테이블을 생성하여 두 배 이상의 데이터가 필요할 수 도 있다. 이와 같이 기업 내 데이터의 양은 폭증하고 있는 가운데 데이터의 보관 주기 역시 갈수록 늘어나고 있다. 이월 데이터에 대해서도 다양한 요구가 있기 때문에 현재의 데이터와 이월 데이터를 함께 운영하는 환경이 늘어나고 있다. 여기서 데이터의 양이 늘어남에 따라 더 많은 저장공간이 필요하다라는 것으로 끝나는 것이 아니다. 데이터의 양이 늘어 난다라는 것은 곧 관리 및 데이터의 처리 시간과 밀접한 관계를 가지고 있다. 데이터가 늘어난 만큼 관리자는 그만큼 더 많은 신경을 써야 하며 응용프로그램 측면에서도 신속한 데이터 처리를 지원해야 한다.
대용량 데이터를 처리하기 위해 저장공간의 절약 측면에 대해서 지난 칼럼에서 소개한바 있다. 이번 칼럼에서는 대용량 데이터를 어떻게 빠른 속도로 안정적으로 처리할 수 있는 지 몇 가지 방법을 소개할까 한다.
데이터관리프로그램(DBMS)에는 대용량 데이터의 관리 및 처리를 보다 쉽고 빠르게 하기 위해 데이터를 논리적으로 물리적으로 분리하여 저장하는 데이터 파티션 (Data Partitioning)이란 기술을 제공하고 있다. 이 기술은 하나의 데이터베이스 또는 테이블을 물리적으로 논리적으로 여러 개의 공간으로 나누어 저장하고 관리하는 것을 말한다. 이렇게 데이터 파티션을 사용하여 데이터를 관리했을 경우, 독립적인 데이터 입출력으로 대용량 데이터 처리에 대한 병목 제거할 수 있고, 복잡한 질의에 대해 병렬 처리로 빠른 성능을 보장해 준다. 또한, 대용량의 데이터 관리작업에 있어서 관리자의 노력을 상당부분 줄여 줄 수 있다. 앞으로의 내용에서 대용량 데이터 파티션닝 기술이 사용하여 현장 업무에 어떻게 적용되는 지 살펴 보도록 하자.
DB2 v9에서 제공하는 데이터 파티셔닝 기술은 데이터 내용에 따라 데이터를 여러 테이블 저장공간으로 분산하는 테이블레벨의 파티셔닝 기능-TPF(Table Partitioning Feature)과 하나의 데이터베이스를 여러 시스템에 걸쳐 분산하는 데이터베이스시스템 레벨에서의 파티셔닝 기능- DPF(Data Partitioning Feature) 두 가지로 나눌 수 있다.
테이블내의 데이터들은 테이블 생성시 DDL(Data Define Language)구문 내에 “PARTITION BY RAGE”, “DISTRIBUTE BY HASH”를 이용해 다수의 Tablespace에 분산시킬 수 있다. 또한, 이미 생성된 테이블에 대해서도 “ATTACH PARTITION” 및 “DETACH PARTITION”을 통해서 데이터의 범위를 쉽게 조정할 수 있다. 이때 데이터 분포의 변경이 발생하게 되는 데, 데이터 범위의 추가 및 삭제에 따른 데이터 이동은 모두 온라인으로 상태로 진행된다.
하나의 대용량 테이블을 다양한 범위로 쪼개어 여러 테이블로 나누어 데이터를 저장할 수 있다. 다양한 조건의 데이터 검색 및 갱신에 있어서 특정 범위의 데이터가 집중되어있기 때문에 그만큼 데이터 조회의 시간을 단축할 수 있어 질의의 성능을 극대화할 수 있다. 또한, 데이터를 분리하면 DPF와 마찬가지로 무관한 데이터를 조회하지 않고 데이터를 처리하여 불필요한 입출력을 하지 않으므로 질의 처리 성능을 향상 시킬 수 있다.
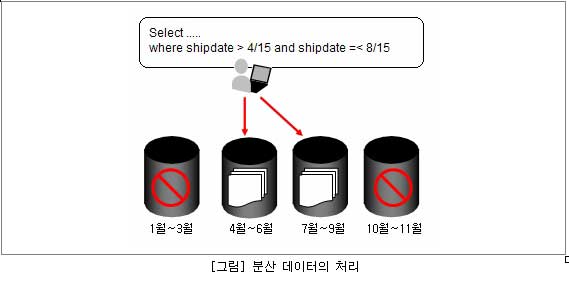
관리측면에서도 보다 유연한 관리 성능을 제공한다. 대용량 테이블의 경우 오래 걸리는 유지보수 작업을 더 작은 당위의 여러 작업으로 나누어 개별 Tablespace에서 관리 태스크를 수행할 수 있다. 예를 들어 데이터 재배치(Reorg), 인덱스 재생성 등의 작업 시간을 단축 시킬 수 있다.
위에서 본 바와 같이 DB2 v9의 TPF와 DPF를 사용하여 대용량 데이터 처리에 있어 보다 확실한 데이터 처리 속도를 보장할 것이며, 아울러 대용량 테이블 관리에 획기적인 변화를 제공할 것이다.
TPF에 대한 자세한 내용은 아래의 웹사이트에 추가적인 정보를 찾을 수 있다.
http://www-128.ibm.com/developerworks/db2/library/techarticle/dm-0605ahuja2/index.html
DB2의 DPF기능은 쉽게 얘기한다면 여러 대의 시스템을 데이터베이스 레벨의 MPP(Massive Parallel Processing)서버로 구성하는 것이다. 여러 대의 시스템들을 각각의 독립적인 노드로 파티션을 정의하고, 이러한 노드들을 여러 개를 연결하여 하나의 논리적인 데이터 베이스를 구성하는 것이다.
이러한 환경에선 데이터베이스에 필요한 시스템 자원을 분산하여 효율적으로 자원을 사용할 수 있게하고 데이터베이스 시스템 자원이 부족하면 언제든지 노드를 추가할 수 있는 유연한 구조를 제공한다. 이때 클라이언트 사용자들은 데이터가 여러 노드로 분산되어 있더라도 별도의 여러 데이터베이스 시스템으로 보는 것이 아닌 하나의 논리적인 데이터베이스로 인식하게 된다. 클라이언트는 어떠한 노드에 접속하여 데이터를 요청하더라를 가져오는 효과를 볼 수 있다. 각 노드들은 논리적으로 하나의 데이터베이스로 묶여있기 때문에 어떠한 노드에 접속하여 질의를 해도 하나의 데이터베이스에 접속하는 효과를 볼 수 있어 응용프로그램 구현에 있어서 그 복잡도를 획기적으로 줄일 수 있다.
예를 들어, 대용량 테이블의 경우, 하나의 노드 혹은 두 개 이상의 노드로 걸쳐 분산하여 저장할 수 있습니다. 하나의 테이블을 여러 노드로 분산하였을 경우, 데이터는 자동으로 라운드로빈 방식으로 분산되어 저장된다. 클라이언트로부터 요청되는 질의는 자동으로 분할하여 적용 가능한 파티션에 병렬로 데이터 처리 작업을 수행함으로써 시스템의 자원을 극대화하여 빠른 처리 속도를 낼 수 있다.
특정 하나의 노드에만 테이블을 저장하는 경우, 그 노드에 데이터 처리 요청이 오면 CPU, 메모리, 디스크를 독립적으로 사용하게 됨으로 데이터가 있지 않는 노드를 건너뜀으로써 데이터 처리의 부하를 다른 노드에 전혀 영향을 미치지 않게 한다.
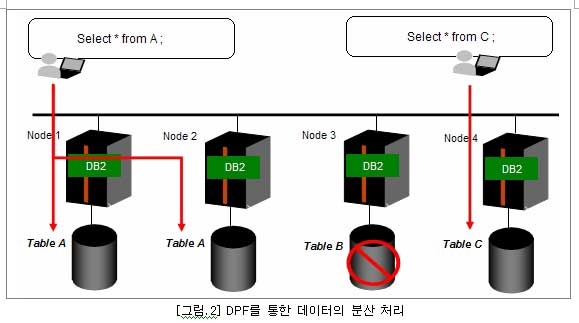
관리작업에 있어서 DPF로 구성된 데이터베이스는 하나의 논리적 단위지만 각 노드로 보았을 경우, 각각 단일 시스템이 되므로 데이터의 백업 등 관리 작업을 파티션별로 수행함으로써 유지보수의 노력을 줄일 수 있다.
궁극적으로 데이터 파티셔닝 기술을 이용하면 데이터의 효율측면에서 상당히 이득을 볼 수 가 있다. 데이터의 조회 및 갱신에 있어서 다양한 데이터 분산을 통해 병렬처리를 통한 신속한 결과 반환을 할 수 있으며, 또한 비슷한 부류의 데이터를 모아 둠으로써 데이터의 처리를 집중화할 수 있다. 또한, 디스크 장애에 대해서도 분리된 입출력을 보장함으로써 좀더 안정적인 운영환경을 지원해 준다.
추가적인 정보는 아래의 웹사이트에 추가적인 정보를 찾을 수 있다.