
DBMS 2
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
이장은 DB2 UDB DPF의 파티션 환경에서 고려해야 할 SQL을 가이드 합니다. Cursor를 사용하여 fetch후 다중 파티션위에 생성된 Table에 insert를 반복적으로 하는 경우 단일 파티션에 insert하는 것 보다 성능이 저하됩니다. 이유는 data 한 건이 다중 파티션으로 구성된 table에 insert되기 위해서는 해당 row가 어느 파티션으로 insert 되어질 것인지를 db2 udb partition map(PMAP)에 의해 먼저 결정이 되어진 후 해당 파티션으로 data가 이동하여 insert가 일어나게 됩니다. 이에 대한 해결 방안은 다음과 같습니다. 다중 파티션 구성에서 table에서 table로 data 이동 시 가장 좋은 방안입니다. Select insert로 logic구현이 불가능한 경우 single partition에 생성된 temp table이나 global temp table을 사용하여 data insert를 row by row로 한 후 이 table로부터 다중 파티션으로 구성된 target table에 select insert를 합니다. Single partition으로 구성된 table에 대한 row by row insert는 단일 데이터베이스의 성능과 동일합니다. Application과 파티션간의 communication 경로를 줄이기 위해 single partition이 있는 파티션으로 직접 connection한 후 application을 수행합니다. 다음 예에서 134번이 single partition이라고 가정하고 connection 하는 것을 보여줍니다. 이런 성격의 단일 파티션 table에는 불필요한 index를 생성하지 않습니다. 두 table간의 join시 성능과 관련한 가장 중요한 요소는 join하는 두 table이 동일한 partitioning key를 가졌는지 동일한 partitioning key를 가지고 있다면 이 key column으로 join을 하는지의 유무입니다. 가능한 Join하는 두 table이 collocation이 되도록 하며 특히 중요 table에 대한 collocation은 필수입니다. 다음은 collocation이 되지 않아 data가 파티션간에 서로 이동하는 것을 보여줍니다. Partitioning key가 서로 틀린 table간의 join은 파티션간의 data 이동 및 target 파티션으로 data 이동을 위한 hash가 일어나면서 많은 CPU를 소모하게 됩니다. correlated update와 correlated delete의 경우 collocation join이 되도록 합니다. cursor내에서 다중 파티션에 생성된 table에 대해 row by row 단위로 select, update, delete를 해야 하는 경우 select, update, delete 문의 where절에 partitioning key에 대한 조건을 주도록 합니다. 조건을 주지 않는 경우 table이 속한 전 파티션으로 해당 DML를 copy되어 수행됨으로써 여러 파티션간의 communication workload로 인해 여러 건의 data 처리시 단일 파티션보다 성능이 저하됩니다. partitioning key를 사용할 수 없고 index를 생성하더라도 충분한 성능이 나오지 않으며 반복적으로 select해야 하는 temp성 table을 단일 파티션에> 대량의 data적재 후, reorg후, index 생성 후 해당 table의 통계 자료 반영을 위한 runstats utility를 수행합니다. 주의해 할 점은 다중 파티션에서 runstats를 수행할 경우 table이 속한 파티션에서 runstats를 수행해야 합니다. Table이 속하지 않은 파티션이나 data의 skew로 인해 data가 거의 없는 파티션에서의 runstats 수행은 거짓정보를 catalog에 update함으로써 효율적인 access path를 만들 수 없습니다.DB2 UDB Partition 환경을 위한 SQL 가이드
DB2 UDB Partition 환경을 위한 SQL 가이드
DB2 UDB Partition 환경을 위한 SQL 가이드
Row by row insert
Select insert 을 참조하세요.
Single Partition 을 참조하세요.
Buffered import, load와 같은 bulk data 처리를 위한 db2 udb utility를 활용하여 data를 table에 적재합니다.
Application precompile이나 binding 시 insert buf option을 사용합니다. 다만 이런 경우 제약사항이 있습니다. Cursor 처리 중간 중간에 update 혹은 commit을 하게 되면 buffered insert의 기능을 활용할 수가 없습니다.Select insert
db2 +c "Insert into itg.ar select * from stg.ar"
db2 commit
Single Partition
db2 terminate
db2 connect to edwid
Collocated join
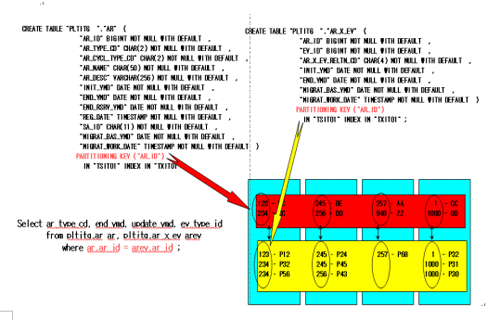
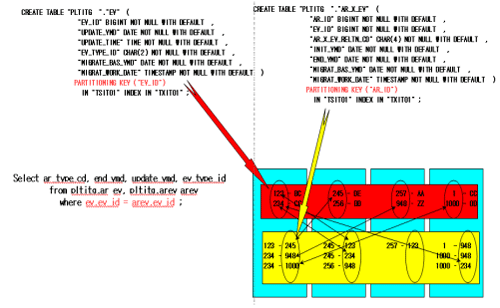
row by row select, update, delete
■ 아래 예문에서 department table의 emp_no가 partitioning key가 아닌 경우 department table이 속한 모든 파티에 index가 생성되어 있으면 B tree index구조에서 그 값이 있는지 없는지 빨리 확인이 가능합니다. emp_no가partitioning key인 경우 해당 파티션에 대해서만 SQL문이 수행됩니다.
Select emp_no into :emp_no
From employee Select dept_no, dept_name from department
Where emp_no = :emp_no
Fetch first row only
Runstats utility를 수행합니다.