
DBMS 2
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
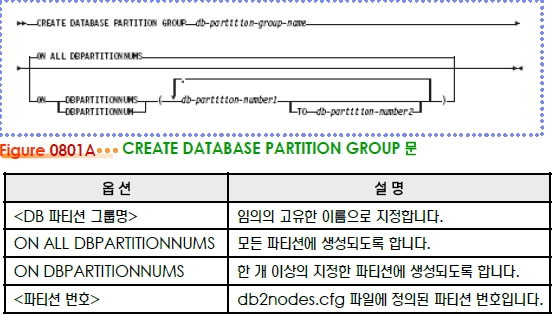
①데이터베이스를 생성하면 3개의 데이터베이스 파티션 그룹이 기본적으로 생성됩니다. ②create database partition group 문의 형식은 다음과 같습니다. ③create database partition group 명령어에서 한 개 이상의 데이터베이스 파티션 번호 를 이용하여 새로운 데이터베이스 파티션 그룹을 생성합니다. ④drop database partition group 명령어로 데이터베이스 파티션을 제거합니다. ⑤list database partition groups 명령어를 이용하여 정의된 데이터베이스 파티션 그룹의 정보를 확인합니다. list nodegroups 명령어를 사용해도 됩니다. ⑥SYSCAT.NODEGROUPS 뷰에서 연관된 정보를 확인합니다. ①데이터베이스를 생성하면 다음과 같이 4가지의 스키마가 기본적으로 생성됩니다. ②create schema 문의 형식은 다음과 같습니다. ③create schema 문을 이용하여 새로운 스키마를 생성합니다. ④create schema 문에서 AUTHORIZATION 옵션을 이용하여 스키마의 소유자를 지정할 수 있습니다. ⑤drop schema 문을 이용하여 기존의 스키마를 제거합니다. 반드시 RESTICT 옵션을 지정하 도록 합니다. ⑥list tables 명령어에서 FOR SCHEMA 옵션을 이용하면 동일한 스키마를 가지는 테이블과 뷰의 목록을 확인할 수 있습니다. ⑦생성된 스키마에 대한 정보는 SYSCAT.SCHEMA 뷰를 이용해서 확인합니다. ①SQL문에서 (스키마명) 없이 (테이블명)만 지정하면, (현재 세션의 로그온 사용자명)이 기 본 (스키마명)으로 인식됩니다. (테이블명)은 (사용자명1).(테이블명)으로 인식됩니다. ②데이터베이스에 접속하는 connect 문에서 USER 와 USING 옵션을 이용하면, (현 세션의 로그온 사용자명)에 관계 없이 (데이터베이스 접속 시에 사용된 사용자명)이 기본 (스키마명) 으로 인식됩니다. (테이블명)은 (사용자명2).(테이블명)으로 인식됩니다. ③CURRENT SCHEMA 특수 레지스터리 변수는 스키마명을 명시적으로 지정하지 않는 경우에 기본 스키마로 적용될 값을 저장하고 있습니다. values 문으로 현재값을 확인할 수 있습니다. set current schema 문으로 CURRENT SCHEMA 특수 레지스터리 변수를 변경하면, (데이터베이스 접속시 사용된 사용자명) 보다 우선적으로 적용됩니다. (테이블명)은 (스키마 명 1).(테이블명)으로 인식됩니다. ④데이터베이스의 오브젝트를 지정할 때는 개별적인 SQL문에서 (스키마명)을 명시적으로 지정 하는 것이 권장됩니다. (현재 세션의 로그온 사용자명), (데이터베이스 접속시에 사용된 사용 자명), (CURRENT SCHEMA 특수 레지스터리 변수의 현재값) 보다 SQL문에서 명시적으 로 지정한 (스키마명)이 가장 우선적으로 적용됩니다. (테이블명)은 (스키마명2).(테이블 명)로 인식됩니다. ①한 테이블스페이스에는 한 개 이상의 테이블이 저장됩니다. ②create table 문을 이용하여 테이블을 정의합니다. IMPLICIT_SCHEMA 특권이 있으면, 존재하지 않는 (스키마명)을 이용하여 테이블을 정의할 수 있습니다. ③alter table 문을 이용하여 컬럼 추가, 고유키 추가 및 제거, 기본키 추가 및 제거, 외부키 추 가 및 제거, 점검 제한 조건 추가 및 제거 등의 변경 작업이 가능합니다. ④drop table문으로 테이블을 제거합니다. ⑤list tables 명령어에서 테이블의 목록을 확인할 수 있습니다. ⑥테이블에 대한 정보는 SYSCAT.TABLES 뷰를 이용해서 확인합니다. ⑦describe table 문으로 테이블의 컬럼에 대한 정보를 확인합니다. ⑧db2look 명령어로 테이블에 대한 DDL문을 추출할 수 있습니다. ①create table 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①alter table 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①기본적으로 지원되는 데이터의 유형은 다음과 같습니다. ②대표적인 데이터 유형에 대한 설명은 다음과 같습니다. ①NULL 값은 알려지지 않은 값을 의미합니다. 테이블을 정의할 때, 컬럼에 NULL 값을 허용하지 않으려면 CREATE TABLE 문에서 NOT NULL 옵션을 이용합니다. ②CREATE TABLE 문에서 WITH DEFAULT 옵션만 지정하면 시스템 기본값이 제공됩니다. ③CREATE TABLE 문에서 WITH DEFAULT <기본값> 옵션을 지정하면 사용자가 지정한 값이 기본값으로 사용됩니다. ①CREATE TABLE 문에서 IN 옵션을 지정하지 않으면, 테이블은 기본 사용자 테이블스페이스에 저장됩니다. ②CREATE TABLE 문에서 IN 옵션으로 테이블이 저장될 테이블스페이스를 지정합니다. 테이블 의 모든 데이터와 인덱스 데이터는 동일한 테이블스페이스에 저장됩니다. ③CREATE TABLE 문에서 INDEX IN 키워드를 이용하여 인덱스를 위한 데이터를 별도의 테이 블스페이스에 저장할 수 있습니다. IN 옴션과 INDEX IN 옵션에서 지정한 테이블스페이스는 DMS 방식의 REGULAR 유형이어야 합니다. INDEX IN 옵션만 지정할 수는 없습니다. ④CREATE TABLE 문에서 LONG IN 키워드를 이용하여 LONG 데이터를 별도의 테이블스페 이스에 저장할 수 있습니다. IN 옴션에서 지정한 테이블스페이스는 DMS 방식의 REGULAR 유형이고, LONG IN 옵션에서 지정한 테이블스페이스는 DMS 방식의 LARGE 유형이어야 합니다. LONG IN 옵션만 지정할 수는 없습니다. ⑤CREATE TABLE 문에서 IN, INDEX IN, LONG 옵션을 모두 사용하? 별도의 DMS 테이블스페이스를 저장할 수 있습니다. ①고유키 제한 조건을 정의하는 구문은 다음과 같습니다. 고유키를 구성하는 각 컬럼은 NOT NULL 속성을 지정해야 합니다. ②create table 문에서 CONSTRAINT ~ UNIQUE 라는 옵션으로 지정합니다. <제한조건 명>과 동일한 이름을 가진 고유 인덱스가 자동으로 생성됩니다. 고유키는 한 테이블에 여러 개 정의할 수 있습니다. CONSTRAINT 옵션을 지정하지 않으면, 제한조건명과인덱스의 이름은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다. ③alter table 문을 이용하여 고유키를 추가할 수 있습니다. ④alter table 문을 이용하여 고유키를 제거할 수 있습니다. 기본키 제한 조건을 정의하는 구문은 다음과 같습니다. 기본키를 구성하는 각 컬럼은 NOT NULL 속성을 지정해야 합니다. create table 문에서 CONSTRAINT ~ PRIMARY KEY 라는 옵션으로 지정합니다. <제 한조건명>과 동일한 이름을 가진 고유 인덱스가 자동으로 생성됩니다. 기본키는 한 테이블에 한 개만 정의할 수 있습니다. CONSTRAINT 옵션을 지정하지 않으면, 제한조건명과 인덱스의 이 름은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다. alter table 문을 이용하여 기본키를 추가할 수 있습니다. alter table 문을 이용하여 기본키를 제거할 수 있습니다. ①외부키 제한 조건을 정의하는 구문은 다음과 같습니다. ②create table 문에서 CONSTRAINT ~ FOREIGN KEY 라는 옵션으로 지정합니다. 외부 키는 한 테이블에 여러 개 정의할 수 있습니다. CONSTRAINT 옵션을 지정하지 않으면, 제한 조건명은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다. ③alter table 문을 이용하여 외부키를 추가할 수 있습니다. ④alter table 문을 이용하여 외부키를 제거할 수 있습니다. ①외부키 제한 조건에서 UPDATE 규칙과 DELETE 규칙을 정의하는 옵션은 다음과 같습니다. ②외부키를 가진 자손 테이블에 INSERT 문으로 데이터를 추가할 때, 제공된 외부키가 부모 테이 블의 고유키에 존재하는 값인지 점검합니다. 존재하지 않는 값인 경우에는 SQL0530N 오류 코 드가 반환되고, INSERT 문은 실패합니다. 자손 테이블에 외부키에 입력된 데이터는 부모 테이 블의 고유키에 존재하는 값이므로 항상 참조가 가능합니다. 이러한 기능을 '참조 무결성 (RI, Refrential Integrity)' 라고 합니다. ③고유키를 가진 부모 테이블에서 UPDATE 문을 실행할 때는 다음과 같이 2 가지의 UPDATE 규칙을 적용받게 할 수 있습니다. CREATE TABLE 문에서 외부키를 정의할 때 ON UPDATE 옵션을 이용하여 지정합니다. ④고유키를 가진 부모 테이블에서 DELETE 문을 실행할 때는 다음과 같이 4 가지의 DELETE 규 칙을 적용받게 할 수 있습니다. CREATE TABLE 문에서 외부키를 정의할 때 ON DELETE 옵 션을 이용하여 지정합니다. ①점검 제한 조건을 정의하는 구문은 다음과 같습니다. ②create table 문에서 CONSTRAINT ~ CHECK 라는 옵션으로 지정합니다. 점검 제한 조 건은 한 테이블에 여러 개 정의할 수 있습니다. CONSTRAINT 옵션을 지정하지 않으면, 제한 조건명은 'SQLyymmddhhmmssxxx' 형식으로 엔진이 부여합니다. ③alter table 문을 이용하여 점검 제한 조건을 추가할 수 있습니다. ④alter table 문을 이용하여 점검 제한 조건을 제거할 수 있습니다. ①create table 문에서 GENERATED 라는 옵션으로 지정합니다. ②주요한 옵션은 다음과 같습니다. ①create table 문에서 NOT LOGGED INITIALLY 라는 옵션으로 지정해야 합니다. ②NOT LOGGED INITIALLY 옵션은 기본적으로 비활성화 상태이므로 테이블의 변경 내역은 데이터베이스 로그 파일에 기록됩니다. alter table 문으로 NOT LOGGED INITIALLY 옵 션을 활성화시키면, COMMIT 또는 ROLLBACK 문이 실행될 때까지 해당 테이블에 대한 데 이터베이스 로깅이 중지됩니다. ③NOT LOGGED 옵션은 UOW가 성공적으로 종료되면 자동으로 비활성화되고, 테이블에 대 한 데이터베이스 로깅은 다시 시작됩니다. ④UOW가 실패하면 해당 테이블은 재생성해야 합니다. ①create view 문으로 생성하며, SELECT문으로 액세스가 허용되는 데이터를 제한합니다. ②WITH CHECK OPTION을 이용하면, 뷰의 정의에 맞지 않는 데이터를 추가, 삭제, 변경할 수 없습니다. INSERT 또는 UPDATE를 실행할 때 뷰의 정의에 맞는지를 확인합니다. ③VIEW를 통한 액세스가 가능합니다. ④drop view 문을 이용하여 제거합니다. ⑤list tables 명령어에서 뷰의 목록을 확인할 수 있습니다. ⑥뷰에 대한 정보는 SYSCAT.VIEWS, SYSCAT.VIEWDEP, SYSCAT.TABLES 뷰를 이용해 서 확인합니다. SYSCAT.TABLES 뷰에서 TYPE 컬럼의 값이 'V' 입니다. ⑦db2look 명령어를 이용하여 뷰에 대한 DDL을 추출합니다. ①create view 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①Meterialized Query Table의 약자입니다. create table 문에서 REFRESH 옵션으로 생성합니다. ②사용하기 전에 REFRESH TABLE 문을 이용하여 최초의 결과 집합을 생성해야 합니다. ③SELECT문에서 직접 MQT를 이용할 수 있습니다. ④베이스 테이블을 대상으로 하는 SELECT문에서 명시한 조건문이 MQT의 정의 부분과 일치하 면, MQT를 이용한 SELECT문으로 자동으로 변환됩니다. ⑤drop table 문을 이용하여 제거합니다. ①create index 문으로 컬럼명과 컬럼별 정렬 순서를 지정합니다. 기본적으로 인덱스는 중복된 값을 허용하므로 중복된 행을 허용하지 않는 인덱스를 생성하려면 UNIQUE 옵션을 이용합니다. ②CLUSTER 옵션을 이용하면, 해당 인덱스의 정렬 순서를 기준으로 테이블의 데이터가 물리적으 로 배치되므로 효율적인 액세스가 가능합니다. ③INCLUDE 옵션으로 추가된 컬럼들은 인덱스의 데이터 페이지에 RID 와 함께 저장되어, 인덱 스 전용 액세스를 가능하게 합니다. 반드시 UNIQUE 옵션을 함께 지정해야 합니다. ④ALLOW REVERSE SCANS 옵션으로 생성된 인덱스는 양방향 액세스를 허용합니다. ⑤drop index 문으로 제거하며, 테이블이 제거되면 자동으로 제거됩니다. ⑥인덱스에 대한 정보는 SYSCAT.INDEXES 뷰 또는 describe indexes 명령어를 이용하여 확인합니다. ⑦db2look 명령어를 이용하여 테이블과 함께 인덱스에 대한 DDL을 추출합니다. ① create index 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①create sequence 문의 형식은 다음과 같습니다. ②주요한 옵션은 다음과 같습니다. ①한 데이터베이스의 특정 테이블에 대한 변경 작업이 다른 테이블에 영향을 미칠 수 있습니다. 응 용프로그램의 로직에서 이러한 비즈니스 규칙을 구현하면, 비즈니스 규칙이 변경될 때마다 응용 프로그램의 로직을 수정해야 합니다. 트리거는 특정 테이블 또는 뷰에 대한 변경 작업이 요청될 때마다 자동으로 실행되어야 하는 일련의 작업들을 데이터베이스 수준에서 정의합니다. 비즈니 스 규칙이 변경되되어도?하면 되므로, 모든 응용 프로그램은 추가적인 로직의 변경 없이 새로운 비즈니스 규칙을 적용할 수 있습니다. ②트리거에 정의된 비즈니스 로직을 실행하는 시점에 의해 3가지 유형으로 분류됩니다. ③ 트리거는 발생시키는 SQL문의 유형에 의해 3가지 유형으로 분류됩니다. ④트리거의 기준이 되는 대상은 2 가지로 분류됩니다. create trigger 문의 형식은 다음과 같습니다. 옵션에 대한 설명은 다음과 같습니다. ①create trigger 문에서 NO CASCADE BEFORE 옵션으로 생성합니다. ①AFTER 트리거를 생성하는 예는 다음과 같습니다. ①create trigger 문에서 INSTEAD OF 옵션으로 생성합니다. ①단위가 서로 다른 의미를 가지는 두 개의 값을 단순히 값으로만 비교하는 것은 잘못된 결과를 만 들게 됩니다. ②단위가 다른 두 값을 직접 비교하는 것을 방지하기 위해 사용자가 create distinct type 문 으로 새로운 데이터 유형을 생성할 수 있습니다. 유형이 다른 두 데이터는 서로 직접 비교될 수 없습니다. ①DB2에서 사용하는 함수는 생성 주체에 따라 2 가지 유형으로 구분됩니다. ②적용되는 대상과 반환하는 값의 유형에 따라 함수는 4 가지 유형으로 구분됩니다. ③사용자 정의 함수의 유형은 작성하는 언어와 반환하는 결과의 유형에 따라 7 가지로 분류됩니다. ④사용자 정의 함수는 SQL/PL, C, Java, OLE 등을 이용하여 생성합니다. ⑤사용자 정의 함수에 대한 정보는 SYSCAT.ROUTINES 뷰를 이용해서 확인합니다. ⑥db2look 명령어로 SQL 사용자 정의 함수에 대한 DDL문을 추출할 수 있습니다 ①create function 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①SQL 사용자 정의 함수를 위한 로직을 작성하여 임의의 <파일명>으로 저장합니다. ②create function 문을 이용하여 SQL 사용자 정의 함수를 생성하고, 등록합니다. ③SQL문에서 기존의 내장 함수와 동일한 방법으로 사용자 정의 함수를 참조합니다. ①저장 프로시저는 클라이언트 머신의 응용프로그램에서 실행해야 하는 로직을 서버의 데이터베이 스에 저장하여 서버 머신에서 직접 실행함으로써 클라언트와 서버 간의 데이터 전송량을 줄이고, 성능을 향상시킵니다. ②공용 로직을 저장 프로시저로 만들어서 사용하면 관리가 용이합니다. 클라이언트 응용프로그램 의 개별적인 코딩으로 인한 오류와 소스를 반복적으로 작성해야 하는 부담을 줄일 수 있습니다. 프로시저의 로직이 변경되면, 서버의 저장 프로시저만 재생성하면 됩니다. ③저장 프로시저는 실행시에 서버의 자원을 사용하여 실행됩니다. 일반적으로 클라이언트 머신보 다 서버 머신의 사양이 좋으므로, 동일한 로직을 실행할 때 실행 시간이 단축될 수 있습니다. ④서버 머신의 OS 에 의존적인 로직의 구현이 가능합니다. 클라이언트가 Windows 이고, 서버 가 UNIX인 경우에 UNIX 에서만 지원되는 기능을 프로시저의 로직에 포함시킬 수 있습니다. ⑤저장 프로시저의 유형은 작성하는 언어에 의해 2 가지로 분류됩니다. ⑥저장 프로시저는 SQL/PL, PL/SQL, ESQL, C, Java 등의 언어를 이용하여 생성합니다. ⑦저장 프로시저에 대한 정보는 SYSCAT.ROUTINES 뷰를 이용해서 확인합니다. ⑧db2look 명령어로 SQL 저장 프로시저에 대한 DDL문을 추출할 수 있습니다. ①create procedure 문의 형식은 다음과 같습니다. ②옵션에 대한 설명은 다음과 같습니다. ①SQL 저장 프로시저를 위한 로직을 작성하여 임의의 (파일명>으로 저장합니다. ②create procedure 문을 이용하여 SQL 저장 프로시저를 생성하고, 등록합니다. ③CALL 문을 이용하여 저장 프로시저를 호출합니다. ①PL/SQL을 이용하여 저장 프로시저를 생성하고자 하는 경우에는 Registry 변수에 compatibility vector를 ‘800’로 설정한 후, 데이터베이스를 생성합니다. ②create procedure 문을 이용하여 SQL 저장 프로시저를 개발합니다. ③DB2CLP 창에서 컴파일 및 생성합니다. ④CLP창에서 프로시저를 호출할 때에는 CALL을 사용합니다.데이터베이스 오브젝트
데이터베이스 오브젝트
데이터베이스 파티션 그룹

$ db2 "create database partition group (DB 파티션 그룹명) on dbpartitionnum ((파티션 번호 1), (파티션 번호 2))"
db2 "drop database partition group (DB 파티션 그룹명)"
$ db2 "drop nodegroup (DB 파티션 그룹명)"
$ db2 list database partition groups show detail
$ db2 list database partition groups show detail
스키마

$ db2 "create schema (스키마명)"
$ db2 "create schema (스키마명) AUTHORIZATION (스키마의 소유자명)"
$ db2 "drop schema (스키마명) restrict"
$ db2 list tables for schema (스키마명)
$ db2 "select * from syscat.schemata"
스키마 지정 방법
$ login (사용자명1)
$ db2 connect to (데이터베이스명)
$ db2 "select * from (테이블명)"
$ login (사용자명1)
$ db2 connect to (데이터베이스명) user (사용자명2) using (암호명2)
$ db2 "select * from <테이블명>"
$ login (사용자명1)
$ db2 connect to (데이터베이스명) user (사용자명2) using (암호명2)
$ db2 values(current schema)
$ db2 set current schema (스키마명1)
$ db2 values(current schema)
$ db2 "select * from (테이블명)"
$ login (사용자명1)
$ db2 connect to (데이터베이스명) user (사용자명2) using (암호명2)
$ db2 set current schema (스키마명1)
$ db2 "select * from (스키마명2).(테이블명)"테이블

$ db2 "create table (스키마명).(테이블명) ((컬럼정의))"
$ db2 "alter table (스키마명).(테이블명) ADD (제한조건)"
$ db2 "drop table (스키마명).(테이블명)"
$ db2 list tables
$ db2 list tables for schema (스키마명)
$ db2 list tables for system $ db2 list tables for all
$ db2 "select * from syscat.tables"
$ db2 "describe table (스키마명).(테이블명)"
$ db2look ?d (DB명) ?e ?z (스키마명) ?t (테이블명) -o (출력파일명)
CREATE TABLE 문


ALTER TABLE 문


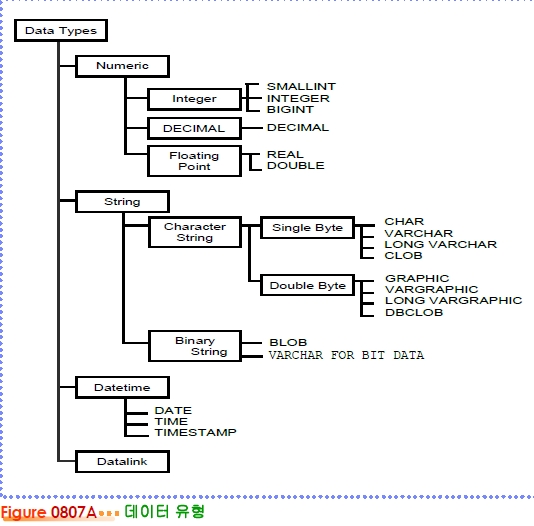
데이터 유형

NULL 값과 DEFAULT 값
$ db2 "create table (테이블명) ( (컬럼명) (데이터유형명) NOT NULL, ….)"
$ db2 "create table (테이블명) ( (컬럼명) (데이터유형명) WITH DEFAULT)"

$ db2 "create table (테이블명) ( (컬럼명) (데이터유형명) WITH DEFAULT (기본값))"

테이블스페이스 지정
$ db2 "create table (스키마명).(테이블명) ((컬럼 정의)) "
$ db2 "create table (스키마명).(테이블명) ((컬럼 정의)) IN (테이블스페이스 명)"
$ db2 "create table (스키마명).(테이블명) ((컬럼 정의)) IN (테이블스페이스 명) INDEX IN (테이블스페이스명) "
$ db2 "create table (스키마명).(테이블명) ((컬럼 정의)) IN (테이블스페이스 명) LONG IN (테이블스페이스명) "
$ db2 "create table (스키마명).(테이블명) ((컬럼 정의)) IN (테이블스페이스 명> INDEX IN (테이블스페이스명) LONG IN (테이블스페이스명) "

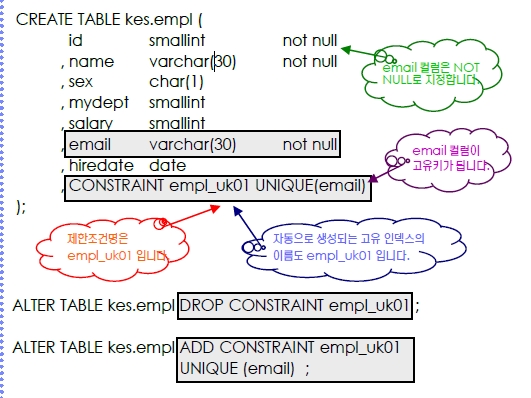
고유키

$ db2 "create table (스키마명).(테이블명) (…, (고유키 제한 조건절), …)"
$ db2 "alter table (스키마명).(테이블명) ADD (고유키 제한 조건절)"
$ db2 "alter table (스키마명).(테이블명) DROP CONSTRAINT (제한조건 명)"
기본키

$ db2 "create table <스키마명>.<테이블명> (…, <기본키 제한 조건절>, …)"
$ db2 "alter table <스키마명>.<테이블명> ADD <기본키 제한 조건절>"
$ db2 "alter table <스키마명>.<테이블명> DROP CONSTRAINT <제한조건 명>"

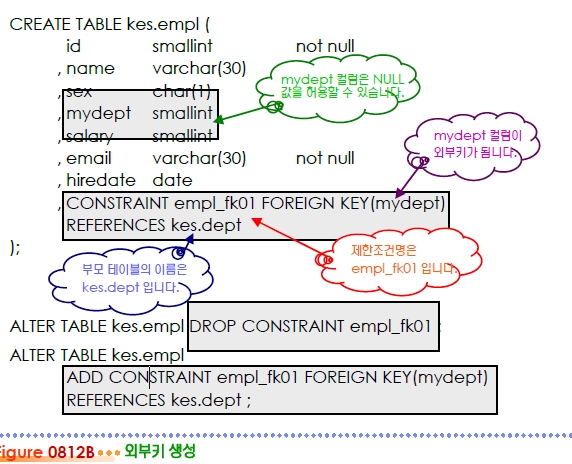
외부키
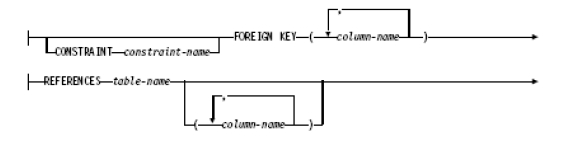
$ db2 "create table (스키마명).(테이블명) (…, (외부키 제한 조건절), …)"
$ db2 "alter table (스키마명).(테이블명) ADD (외부키 제한 조건절)"
$ db2 "alter table (스키마명).(테이블명) DROP CONSTRAINT (제한조건 명)"
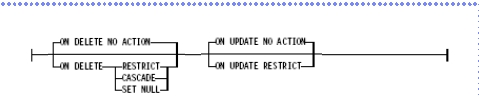
참조 무결성


점검 제한 조건

$ db2 "create table <스키마명>.<테이블명> (…, <점검 제한 조건절>, …)"
$ db2 "alter table <스키마명>.<테이블명> ADD <점검 제한 조건절>"
$ db2 "alter table <스키마명>.<테이블명> DROP CONSTRAINT <제한조건 명>"

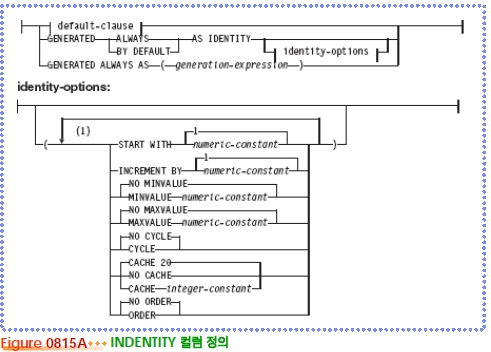
Identity 컬럼


NOT LOGGED INITIALLY 옵션
$ db2 "create table (테이블명) ((컬럼 정의)) NOT LOOGED INITIALLY"

$ vi (입력파일명)
ALTER TABLE (테이블명) ACTIVATE NOT LOGGED INITIALLY;
INSERT INTO ... SELECT FROM ... ;
COMMIT;
$ db2 +c ?svtf (입력파일명)
$ db2 drop table (테이블명)
$ db2look ?d (데이터베이스명) -z (스키마명) -t (테이블명) -e ?o (출력파일명)
db2 ?svtf (출력파일명)뷰
$ db2 "create view kes.t1_v1 as select * from kes.t1 where c2 > 200 "

$ db2 "insert into kes.t1_v1 values (1,300)"
$ db2 "select * from kes.t1_v1"
$ db2 drop view kes.t1_v1
$ db2 list tables
$ db2 list tables for schema (스키마명)
$ db2 list tables for system
$ db2 list tables for all
$ db2 "select * from syscat.tables"
$ db2look ?d (DB명) ?e ?z (스키마명) ?v (뷰명) -o (출력파일명)
CREATE VIEW 문


MQT

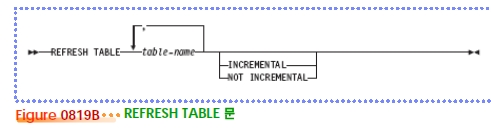
$ db2 "select * from (MQT명)"

$ db2 drop table (MQT명)
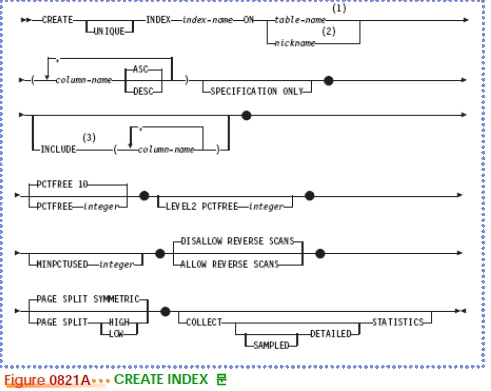
인덱스
$ db2 "create index (스키마명).(인덱스명> on (테이블명> ((컬럼명>)"
$ db2 "create UNIQUE index (인덱스명> on (테이블명> ((컬럼명>)"
$ db2 "create unique index (인덱스명> on (테이블명>((컬럼명>) CLUSTER"

$ db2 "create UNIQUE index (인덱스명> on (테이블명> ((컬럼명 1>) INCLUDE ((컬럼명 2>, (컬럼명 3>, …)"
$ db2 "create unique index (인덱스명> on (테이블명> ((컬럼명>) cluster ALLOW REVERS SCANS"
$ db2 "drop index (스키마명>.(인덱스명>"
$ db2 "select * from syscat.indexes"
$ db2 describe indexes for table (스키마명>.(테이블명> show detail
$ db2look ?d (DB명> ?e ?z (스키마명> ?v (테이블명> -o (출력파일명>
CREATE INDEX 문

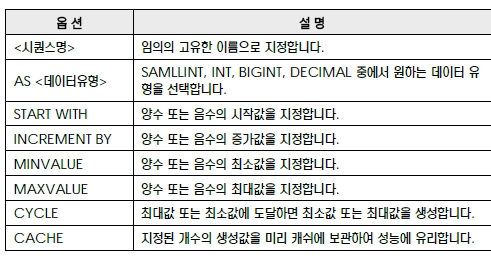
시퀀스


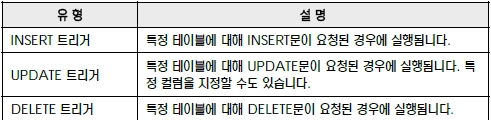
트리거


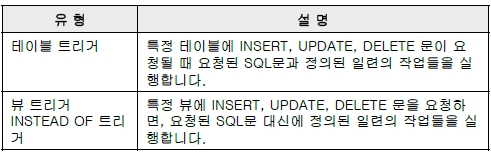
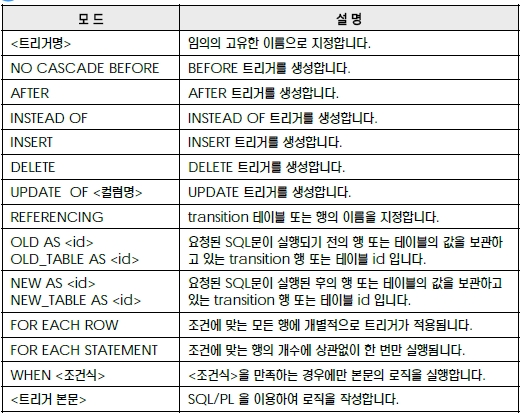
CREATE TRIGGER 문

BEFORE 트리거

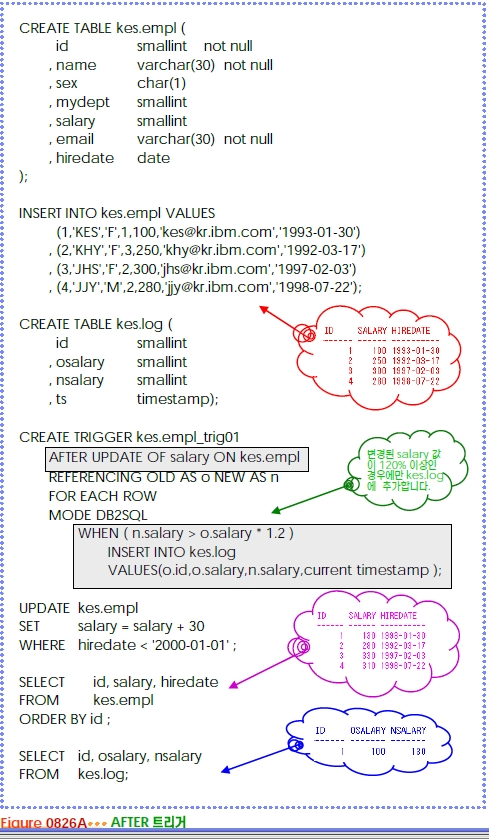
AFTER 트리거
INSTEAD OF 트리거

사용자 정의 데이터 유형

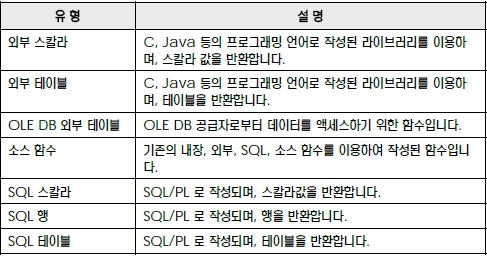
사용자 정의 함수


$ db2 "select * from syscat.routines"
$ db2look ?d (DB명) ?e -o (출력파일명)
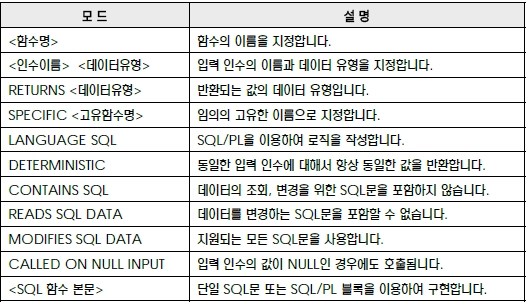
CREATE FUNCTION 문

SQL 사용자 정의 함수
$ cat (파일명)
CREATE FUNCTION todate (x varchar(8))
RETURNS date
SPECIFIC TODATE01
LANGUAGE SQL
CONTAINS SQL
NO EXTERNAL ACTION
DETERMINISTIC
RETURN date(SUBSTR(X,1,4)||'-'||SUBSTR(X,5,2)||'-'||SUBSTR(X,7,2))
@
CREATE FUNCTION tan (X DOUBLE)
RETURNS DOUBLE
LANGUAGE SQL
CONTAINS SQL
NO EXTERNAL ACTION
DETERMINISTIC
RETURN SIN(X)/COS(X) @
CREATE FUNCTION kes.percent(number int, rate int)
RETURNS decimal(6,2)
F1: BEGIN ATOMIC
RETURN (number * rate) / 100;
END@
$ db2 connect to (데이터베이스명)
$ db2 -td@ -svf (파일명)
$ db2 ?x " values(TODATE('20040101'))"
2004-01-01
$ db2 -x "SELECT id, salary, kes.percent(salary,5) FROM kes.empl"
1 130 6.00
2 280 14.00
3 330 16.00
4 310 15.00저장 프로시저


$ db2 "select * from syscat.routines"
$ db2look ?d (DB명> ?e -o (출력파일명>
CREATE PROCEDURE 문


SQL/PL 프로시저
$ cat (파일명>
CREATE PROCEDURE myproc (IN deptNumber CHAR(3),
OUT medianSalary DOUBLE)
LANGUAGE SQL
BEGIN
DECLARE SQLCODE INTEGER;
DECLARE SQLSTATE CHAR(5);
DECLARE v_numRecords INT DEFAULT 1;
DECLARE v_counter INT DEFAULT 0;
DECLARE c1 CURSOR FOR
SELECT CAST(salary AS DOUBLE) FROM employee
WHERE workdept = deptNumber
ORDER BY salary;
DECLARE EXIT HANDLER FOR NOT FOUND
SET medianSalary = 6666;
SET medianSalary = 0;
SELECT COUNT(*) INTO v_numRecords FROM employee
WHERE workdept = deptNumber;
OPEN c1;
WHILE v_counter < (v_numRecords / 2 + 1) DO
FETCH c1 INTO medianSalary;
SET v_counter = v_counter + 1;
END WHILE;
CLOSE c1;
END @
$ db2 connect to (데이터베이스명)
$ db2 -td@ -svf (파일명>
$ db2 "call myproc('A00',?)"
Value of output parameters
--------------------------
Parameter Name : MEDIANSALARY
Parameter Value : +4.65000000000000E+004
Return Status = 0PL/SQL 프로시저
$ db2set compatibility Vector = 800
$ cat script.db2
set sqlcompat plsql/
CREATE OR REPLACE FUNCTION emp_comp (
p_sal NUMBER,
p_comm NUMBER )
RETURN NUMBER
IS
BEGIN
RETURN (p_sal + NVL(p_comm, 0)) * 24;
END emp_comp
/
CREATE OR REPLACE PROCEDURE update_comp(p_name IN
VARCHAR) AS
BEGIN
UPDATE emp SET tot_comp = emp_comp(salary, comm)
WHERE name = p_name;
END update_comp
/
$ db2 ?td/ -vf script.db2
$ db2 call update_comp(‘Curly’)