
DBMS 2
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
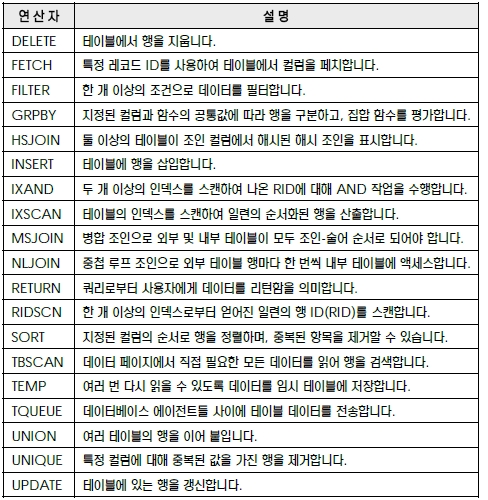
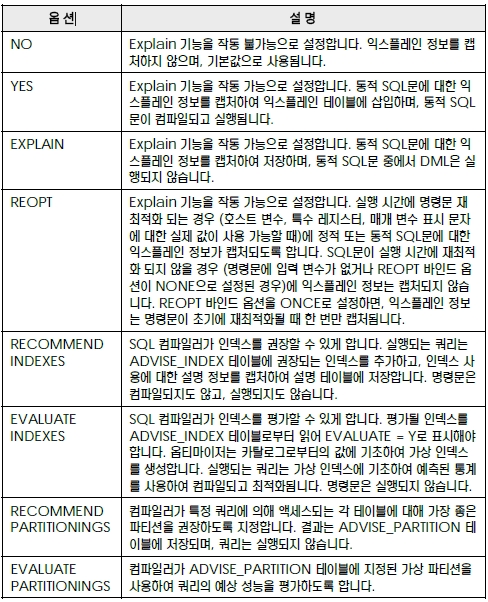
SQL 컴파일러는 여러 단계를 수행하여 입력된 SQL문을 컴파일하고, 실행할 수 있는 액세스 플랜을 생성합니다. 비용 기반의 옵티마이저를 이용하여 최적의 액세스 플랜을 결정하게 됩니다. SQL 컴파일러가 실행하는 각 과정에 대한 설명은 다음과 같습니다 패키지가 실행되면 데이터베이스 관리 프로그램은 시스템 카탈로그 테이블 또는 패키지 캐시에 저장된 정보를 사용하여 데이터에 액세스할 방법을 결정하고 쿼리를 실행하여 실행 결과를 반환 합니다. 호스트 변수, 특수 레지스터, 매개 변수 표시 문자를 가지는 정적 SQL문과 동적 SQL문에 대한 액세스 플랜은 SQL 컴파일러가 선택한 기본 예상치 (Default Filtering Factor)를 이용합 니다. 실행시 실제로 입력된 값을 이용한 액세스 플랜을 생성하려면, 바인드시 REOPT 옵션을 사용합니다. 사용자는 SQL문이 컴파일될 때 적당한 최적화 클래스를 지정하여 옵티마이저가 가장 효율적인 액세스 플랜을 선택하도록 조절할 수 있습니다. 최적화 클래스를 개별적으로 지정하여 쿼리에 대한 런타임 성능을 향상시킬 수 있으나, 높은 최적화 클래스를 지정할수록 더 많은 컴파일 시간 과 시스템 자원을 필요로 하게 됩니다. 최적화 클래스는 다음과 같이 7가지로 구분됩니다. 쿼리 최적화 클래스 1, 2, 3, 5, 7은 모두 일반적인 목적으로 사용하는 데 적합합니다. 쿼리 컴 파일 시간을 더 줄여야 하거나, SQL문이 아주 단순한 경우에만 클래스 0을 고려합니다. 대부분의 SQL문은 기본 쿼리 최적화 클래스인 최적화 클래스 5를 사용하여 적합하게 최적화될 수 있습니다. 주어진 최적화 클래스에서 쿼리 컴파일 시간과 자원 소비는 쿼리의 복잡도, 특히 조 인 및 서브쿼리 수에 의해 주로 영향을 받습니다. 그러나, 컴파일 시간과 자원의 사용은 수행된 최적화의 양에 의해서도 영향을 받습니다. 소규모의 데이터베이스, 간단한 동적 쿼리, 컴파일시 사용하는 메모리의 양을 제한, 컴파일 시간의 단축 등이 필요하다면, 최적화 클래스를 조절할 수 있습니다. 최적화 클래스를 선택하는 경우에는 일반적으로 다음과 같은 순서를 고려합니다. 결정 지원 쿼리 또는 월말 보고 쿼리 등의 복합 쿼리는 기본값인 클래스 5 이상을 적용합니다. 최적화 클래스는 dft_queryopt 데이터베이스 구성 변수로 조절합니다. get db cfg 명령 어로 확인하고, update db cfg 명령어로 변경합니다. 기본값은 5 로 설정되어 있습니다. 정적 SQL문에 대한 컴파일은 한 번만 실행되므로, 컴파일 시간과 자원은 한 번만 소요됩니다. 생성된 액세스 플랜은 시스템 카탈로그에 저장되어 여러 번 사용될 수 있습니다. 일반적으로, 정 적 SQL은 기본 쿼리 최적화 클래스를 사용합니다. 정적 SQL문에 대한 최적화 클래스는 프리컴파일이나 바인드 과정에서 QUERYOPT 라는 옵션 을 이용하여 패키지 단위로 변경할 수 있습니다. 옵션을 지정하지 않으면, dft_queryopt 데 이터베이스 구성 변수에 지정된 값을 사용합니다. 정적 SQL문에 대해 적용된 최적화 클래스는 SYSCAT.PACKAGES 카탈로그 테이블의 QUERYOPT 컬럼에서 확인할 수 있습니다. 동적 SQL문은 실행시에 액세스 플랜이 생성되어 실행되므로, 동적 SQL문에 대한 컴파일 시간 과 자원은 실행시마다 소요될 수도 있습니다. 동적 SQL문에 대한 액세스 플랜은 시스템 카탈로 그에 저장되지 않고, 패키지 캐시에 저장됩니다. 액세스 플랜이 캐시된 이후에 환경이 변경되지 않았다면, 이후의 PREPARE문에 포함된 동일한 동적 SQL문은 패키지 캐시의 액세스 플랜을 재사용하기 때문에 동일한 동적 SQL문은 재컴파일할 필요가 없습니다. 만약, 환경적인 변경이 발생하면, 동적 SQL문은 재컴파일되어 패키지 캐시에 다시 저장됩니다. 패키지 캐시의 크기는 PCKCACHESZ 데이터베이스 구성 변수로 조절합니다. get db cfg 명령어로 확인하고, update db cfg 명령어로 변경합니다. 기본값은 -1로 설정되어 있으므 로 maxappls 데이터베이스 구성 변수에 지정된 값의 8배가 할당됩니다. 동적 SQL문은 최적화 클래스는 SET CURRENT QUERY OPTIMIZATION 이라는 특수 레 지스터리를 이용하여 변경합니다. 레지스터리의 값을 지정하지 않으면, dft_queryopt 데이 터베이스 구성 변수에 지정된 값이 사용됩니다. 주요한 쿼리 재작성의 유형은 다음과 같습니다. 조작 병합의 예는 다음과 같습니다. 조작 이동의 예는 다음과 같습니다. 술어 이동의 예는 다음과 같습니다. 뷰를 병합하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 KES.EMPL입니다 KES.EMPL 테이블에서 NAME 컬럼의 값이 'K' 로 시작되는 정보만 표시하는 뷰를 생성합니다. KES.EMPL 테이블에서 SALARY 컬럼의 값이 200 이상인 정보만 표시하는 뷰를 생성합니다. KES.EMPL 테이블에서 NAME 컬럼의 값이 'K' 로 시작되고, SALARY 컬럼의 값이 200 이 상인 사원의 정보만 표시하기 위하여 다음과 같은 쿼리를 실행합니다. 쿼리 재작성 과정에서 두 개의 뷰는 병합되어 다음과 같이 재작성될 수 있습니다. 서브쿼리에서 조인으로 변환하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이터베이스에서 제공되는 EMPLOYEE와 DEPARTMENT 입니다. 서브쿼리를 포함한 다음과 같은 쿼리를 실행합니다 서브쿼리는 다음과 같이 조인으로 변환될 수 있습니다. 서브쿼리에서 조인으로 변환하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이터베이스에서 제공되는 EMPLOYEE와 DEPARTMENT 입니다. 다음의 쿼리 는 EMPLOYEE 테이블에 대한 불필요한 중복 조인을 포함하고 있습니다. EMPLOYEE 테이블에 대한 중복 조인을 제거하여 다음과 같이 단순화될 수 있습니다. 또 다른 예를 위해 다음과 같이 뷰를 작성합니다. EMPLOYEE와 DEPARTMENT 테이블에는 WORKDEPT와 DEPTNO 컬럼을 통해 참조 제한 조건이 설정되어 있다고 가정합니다. 위에서 정의한 뷰를 이용하여 다음과 같은 쿼리를 실행합니다 VPEOPLE 뷰에서 사용되었던 EMPLOYEE와 DEPARTMENT 테이블에 대한 조인이 제거 되고 아래와 같이 재작성될 수 있습니다. 쿼리에 사용되는 함수의 종류가 많으면 쿼리의 실행 속도는 당연히 떨어집니다. 쿼리에 이미 사 용된 다른 함수를 이용하여 필요한 함수의 기능을 대체할 수 있는 있다면, 쿼리 내에서 수행될 계 산의 개수를 줄이면서 더 개선된 액세스 플랜을 생성할 수 있습니다. 공유 총계를 이용하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이 터베이스에서 제공되는 EMPLOYEE입니다. SUM, AVG, COUNT 함수를 사용하는 다음과 같은 쿼리를 실행합니다. SUM과 AVG 함수의 대상으로 사용되는 계산식인 SALARY+BONUS+COMM 이 동일하 므로 AVG 함수는 SUM 함수와 COUNT 함수를 이용하여 SUM/COUNT 형식으로 재작성 할 수 있습니다. AVG 함수의 대상으로 사용되었던 계산식이 제거되어 실행해야할 계산식의 개 수를 줄였으므로 쿼리의 실행 비용을 줄일 수 있습니다. DISTINCT를 제거하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데 이터베이스에서 제공되는 EMPLOYEE입니다. EMPNO 컬럼은 EMPLOYEE 테이블의 기본키로 정의되어 있다고 가정합니다. 기본키를 생 성하면, 자동적으로 고유한 인덱스가 생성됩니다. 다음과 같이 불필요한 DISTINCT 키워드가 포함된 쿼리를 실행합니다. EMPNO 컬럼이 EMPLOYEE 테이블의 기본 키로 정의되었고, 쿼리의 SELECT 절에 기본키 인 EMPNO가 선택되기 때문에 리턴되는 각 행이 고유할 것이라는 것을 이미 알고 있습니다. 이러한 경우에는, DISTINCT 키워드를 사용한 경우와 사용하지 않은 경우의 실행 결과가 동일 하다는 것이 보장되므로 위의 쿼리는 DISTINCT절을 제거하여 다음과 같이 재작성됩니다. 일반 술어를 푸시다운하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이터베이스에서 제공되는 EMPLOYEE 입니다. 푸쉬다운이란 쿼리에서 표현된 여러 개의 술 어 중에서 순서적으로 나중에 적용될 술어를 먼저 적용될 수 있도록 해당 술어의 적용 순서 레벨 을 낮추는 방법입니다. 즉, WHERE 절의 AND 또는 OR로 연결된 여러 개의 술어 중에서 데 이터 필터링의 정도가 높은 술어를 더 앞쪽으로 배치하여 술어의 적용 순서를 변경합니다. EMPLOYEE 테이블에서 WORKDEPT 컬럼의 값이 'D11' 인 부서에 속한 모든 사원의 목록 을 제공하는 다음과 같은 뷰를 생성합니다. 뷰를 이용하여 다음과 같은 쿼리를 실행합니다. D11_EMPL 뷰에 대한 쿼리는 단순히 EMPLOYEE 테이블에 대한 쿼리로 재작성될 수도 있습 니다. WORKDEPT = 'D11' 이라는 술어를 먼저 적용하는 것이 쿼리를 더 빠르게 실행할 수 있다고 판단되는 경우에는 일반 술어의 푸쉬다운이 발생하지 않습니다. 푸시다운이 유리하다고 판단되면, 뷰 D11_EMPLOYEE의 조건문에 원래의 쿼리에서 지정된 LASTNAME = 'BROWN' 이라는 술어가 먼저 적용될 수 있도록 푸시다운하여 다음과 같이 재작성될 수 있습니다. 파티션된 데이터베이스 환경에서 PROJECT 테이블의 PROJNAME 컬럼과 EMPLOYEE 테이블의 SALARY, BONUS, COMM 컬럼을 이용하여 '%PROGRAMMING%' 프로젝 트에서 작업 중이면서 총급여가 평균보다 적은 사원을 조회하는 쿼리를 실행합니다. 이 쿼리는 PROJECT 테이블에 대해 상관 관계가 있고, PROJECT와 EMPLOYEE 테이블의 데이터는 PROJNO 컬럼을 기준으로 동일한 파티션에 저장되어 있지 않으므로, PROJECT 테이블의 데이터를 다른 데이터베이스 파티션으로 브로드캐스트하게 될 수도 있습니다. 또한, 서 브쿼리가 여러 번 평가되어야 하므로 실행 비용이 높습니다. EMPLOYEE와 PROJECT 테이 블을 조인하여 PROJNO 컬럼별로 총급여를 계산하는 AVG_PROJ 라는 공통 테이블을 생 성하여 AVG_COMP 컬럼에 PROJNO 컬럼의 값별로 평균 총급여를 저장하도록 합니다. 공통 테이블을 이용하여 재작성된 쿼리에서 AVG_PROJ 공통 테이블로 PROJNO 컬럼별 평균 총급여인 AVG_COMP를 먼저 계산하고, 그 결과를 EMPLOYEE 테이블이 포함된 모 든 데이터베이스 파티션으로 브로드캐스트할 수 있습니다. 암시적 술어를 추가하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데 이터베이스에서 제공되는 DEPARTMENT, EMPLOYEE, PROJECT 입니다. 다음의 쿼리는 DEPARTMENT 테이블의 ADMRDEPT 컬럼을 이용하여 'E01' 부서에게 보고하는 부서의 관 리자들에 대한 정보와 해당 관리자가 담당하는 프로젝트의 목록을 표시합니다. WHERE 절의 D.MGRNO = E.EMPNO 술어와 E.EMPNO = P.RESPEMP 술어로부터 DEPARTMENT 테이블과 PROJECT 테이블에 대해 MGRNO 컬럼과 RESPEMP 컬럼을 이용하여 DEPT.MGRNO = PROJ.RESPEMP 라는 암시적인 술어를 유추할 수 있습니다. 다음과 같은 암시적 술어를 추가하면, DEPARTMENT 테이블과 PROJECT 테이블에 대해 추 가적으로 조인을 고려할 수 있습니다. 또 다른 예를 위해 EMPLOYEE 테이블의 WORKDEPT 컬럼과 DEPARTMENT 테이블의 DEPTNO 컬럼을 이용하여 부서 번호가 'E00' 보다 큰 부서와 이 부서에서 일하는 사원의 이름 을 표시하는 다음과 같은 쿼리를 실행합니다 원래의 쿼리에 표현된 EMP.WORKDEPT = DEPT.DEPTNO 술어에 의하면 EMPLOYEE 테이블의 WORKDEPT 컬럼과 DEPARTMENT 테이블의 DEPTNO 컬럼은 동일한 것을 보 장할 수 있으므로, DEPT.DEPTNO > 'E00' 술어로부터 유추된 EMP.WORKDEPT > 'E00' 이라는 암시적 술어를 추가하면, EMPLOYEE 테이블에서 조인되는 행의 수를 줄일 수 있으므 로 쿼리의 WHERE 절에는 다음과 같은 술어가 추가됩니다. OR 술어를 IN 술어로 변환하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이터베이스에서 제공되는 EMPLOYEE 입니다. 동일한 컬럼으로 OR 절을 이용 하여 표현한 조건식은 IN 술어로 변환되어 쿼리의 실행 비용을 줄일 수 있습니다. OR 술어를 IN 술어로 변환하는 쿼리 재작성의 예는 다음과 같습니다. 사용되는 테이블은 SAMPLE 데이터베이스에서 제공되는 EMPLOYEE 입니다. 다음의 쿼리는 EMPLOYEE 테 이블의 WORKDEPT 라는 동일한 컬럼으로 OR절을 이용하여 'D11', 'D21', 'E21' 부서에 속 한 사원들의 정보를 표시LECT * WORKDEPT 컬럼에 대한 인덱스가 없는 경우에 OR절을 다음과 같이 IN 술어로 재작성되어 쿼리를 보다 효율적으로 처리할 수 있습니다. 데이터베이스에 저장된 패키지 정보는 list packages 명령어를 이용하여 확인합니다. list packages 명령어의 옵션은 다음과 같습니다. list packages 명령어의 '유효' 컬럼에 표시되는 패키지의 상태는 다음 3가지로 구분됩니다. SQL 컴파일러는 정적 또는 동적 SQL문의 액세스 플랜 및 환경에 대한 정보를 수집할 수 있습 니다. 수집된 익스플레인 정보는 쿼리 처리를 위한 조작 시퀀스, 비용 정보, 각 술어에 대한 술어 및 선택성 추정치, SQL문에서 참조된 모든 오브젝트에 대한 통계 정보 등을 포함하므로, 개별 SQL 명령문의 실행 방법을 파악과 성능 향상을 위한 SQL문의 변경 또는 실행 환경 조절에 도 움을 줄 수 있습니다. 지원되는 익스플레인 도구와 특성은 다음과 같습니다. 익스플레인 테이블은 익스플레인 과정에서 생성되는 각종 정보를 보관하기 위한 테이블들입니다. 생성 스크립트는 인스턴스 사용자의 홈디렉토리에 있는 sqllib/misc/EXPLAIN.DDL 입니다. Visual Explain 또는 db2exfmt 유틸리티를 사용하려면, 익스플레인 테이블을 미리 생성하 여야 합니다. 제어 센터에서 실행되는 Visual Explain은 GUI 방식으로 익스플레인 정보를 제공합니다. db2exfmt 명령어는 익스플레인 테이블의 내용을 정해진 형식의 텍스트로 생성하는 도구입니 다. 액세스 플랜 정보와 옵티마이저에 대한 정보를 확인하는데 사용됩니다. db2expln 명령어는 간단한 액세스 플랜과 쿼리의 실행 비용을 확인하는 데 주로 사용됩니다. 하나 이상의 패키지에 사용 가능한 액세스 플랜 정보를 표시하며, 옵티마이저에 대한 정보는 표 시하지 않습니다. 제어 센터에서 원하는 데이터베이스를 선택한 후 SQL Explain 메뉴를 클릭합니다. 동적 SQL문을 직접 입력하거나 가져오기를 눌러 동적 SQL문이 포함된 파일을 읽어옵니다. 확 인 버튼을 클릭하면 익스플레인 정보가 생성됩니다. 접속한 사용자가 Visual Explain 을 최초 로 실행할 때는 익스플레인 테이블이 자동적으로 생성됩니다. 생성된 액세스 플랜을 확인합니다. 각 다이어그램에서 마우스의 오른쪽 버튼으로 조작별 세부 사항 정보를 확인할 수 있습니다 액세스 플랜 그래프는 액세스 플랜을 트리 구조로 표시합니다. 트리의 각 노드에 표시되는 다이 어그램의 의미는 다음과 같습니다. 주요 연산자에 대한 설명은 다음과 같습니다 제어 센터에서 원하는 데이터베이스를 선택한 후, Explain된 명령문 실행 기록 표시 메뉴를 선 택하면 지금까지 실행했던 익스플레인 정보를 확인할 수 있습니다. 원하는 실행 기록 항목을 선택하여 해당하는 SQL 텍스트를 확인하거나, 기존의 액세스 플랜을 다시 표시할 수 있습니다. 쿼리 태그를 변경하거나, 실행 기록을 제거할 수 있습니다. db2expln 명령어를 이용하여 옵티마이저가 선택한 액세스 플랜을 표시합니다. db2expln 명령어의 옵션에 대한 설명은 다음과 같습니다. db2expln 명령어에서 ?q 옵션을 이용하여 동적 SQL문을 직접 입력하면, 해당하는 동적 SQL문에 대한 익스플레인 정보를 확인할 수 있습니다. db2expln 명령어에서 ?f 옵션을 이용하여 동적 SQL문이 저장된 파일명을 입력하면, 해당하 는 동적 SQL문에 대한 익스플레인 정보를 확인할 수 있습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 정적 SQL문은 이미 컴파일되어 시스템 카탈로그에 패키지로 저장되어 있습니다. db2expln 명령어에서 ?p와 ?s옵션을 이용하여 정적 SQL문이 포함된 패키지명과 섹션 번호를 입력하면, 해당하는 정적 SQL문에 대한 익스플레인 정보를 확인할 수 있습니다. 정적 SQL문에 대한 익스플레인을 확인하기 위해 ESQL 소스 파일을 작성합니다. 소스 파일명 은 select64.sqc 로 하겠습니다 PREP 명령어를 이용하여 패키지를 생성합니다. 패키지를 생성하는 사용자명이 post01 이라면, 패키지명은 POST01.SELECT64 이 됩니다. list packages 명령어로 패키지에 관련된 정보를 확인합니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다 필요시 인스턴스 사용자의 홈디렉토리>/sqllib/misc/EXPLAIN.DDL 을 실행하여 익스플 레인 테이블을 생성합니다. db2exfmt 명령어를 이용하여 익스플레인 테이블에 저장된 정보를 파일로 저장합니다. db2exfmt 명령어의 옵션에 대한 설명은 다음과 같습니다. 동적 SQL문에 대한 익스플레인 정보를 확인하려면, SQL문을 실행하기 전에 특수 레지스터인 CURRENT EXPLAIN MODE를 YES 또는 EXPLAIN 으로 설정합니다. CURRENT EXPLAIN MODE에 사용될 수 있는 특수 레지스터리의 값은 다음과 같습니다. CURRENT EXPLAIN MODE 의 값을 EXPLAIN 으로 설정하여 동적 SQL문을 실제로 실행 하지 않고, 익스플레인 정보만 확인할 수 있습니다. 익스플레인을 원하는 동적 SQL문을 실행합니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다. 정적 SQL문에 대한 익스플레인 정보를 익스플레인 테이블에 저장하려면, PREP 또는 BIND 명 령어로 패키지를 생성할 때, EXPLAIN 옵션을 YES 또는 ALL 으로 설정합니다. PREP 또는 BIND 명령어의 EXPLAIN 옵션의 세부 옵션은 다음과 같습니다. PREP 명령어에서 EXPLAIN 옵션을 YES 로 설정하여 패키지를 생성하면, 정적 SQL문에 대 한 익스플레인 정보가 익스플레인 테이블에 저장됩니다. 실제 익스플레인 정보의 출력 예는 다음과 같습니다.SQL 컴파일러
SQL 컴파일러
SQL 컴파일러

SQL 컴파일러

최적화 클래스

최적화 클래스

? 기본값인 클래스 5로 시작하고, 다른 클래스를 사용하려면 클래스 1, 2, 3부터 시도합니다.
? 같은 컬럼에서 많은 Join 술어를 가진 테이블이 있거나 컴파일 시간이 중요하다면, 클래스
1 또는 2를 사용합니다.
? 하나 또는 적은 테이블만 액세스, 단일 또는 적은 행만 페치, 왼전하고 고유한 인덱스를 사
용하는 1 초 이하의 OLTP 쿼리에 대해서는 클래스 0 또는 1을 사용합니다.
? 30초를 초과하여 장시간 실행되는 쿼리에 대해서는 클래스 3, 5, 7 을 사용합니다.
? 클래스 3 이상은 동적 프로그래밍 조인 열거 알고리즘을 사용하여 많은 액세스 플랜을 고
려하므로, 테이블 수가 증가하면 클래스 0, 1, 2보다 컴파일 시간이 많이 소요됩니다.
? 대형 테이블에 대한 액세스
? 많은 수의 술어
? 많은 서브쿼리
? 많은 조인
? UNION 및 INTERSECT와 같은 많은 집합 연산자
? 많은 규정 행
? GROUP BY 및 HAVING 조작
? 중첩 테이블 표현식
? 많은 수의 뷰
최적화 클래스 지정 방법
$ db2 update db cfg for DB명> using PCKCACHESZ 최적화클래스>
쿼리 재작성

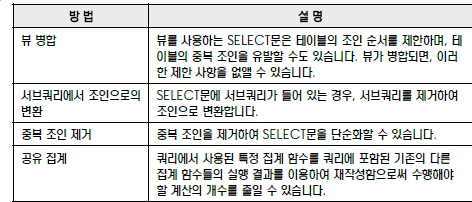
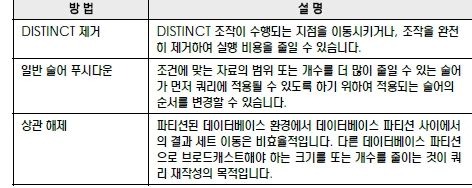

뷰 병합
ID NAME SALARY
----------------------------------------------------------------
1 KES 100
2 KHY 250
3 JHS 300
4 JJY 280
CREATE VIEW kes.vname AS
SELECT * FROM kes.empl WHERE name LIKE 'K%';
$ db2 ?tf view.sql
CREATE VIEW kes.vsalary AS
SELECT * FROM kes.empl WHERE salary >= 200;
$ db2 ?tf view.sql
SELECT v1.id, v1.name, v2.salary
FROM kes.vname v1, kes.vsalary v2
WHERE v1.id = v2.id;
$ db2 ?tf query.sql
FROM kes.empl v1, kes.empl v2
WHERE v1.id = v2.id
AND v1.name LIKE 'K%'
AND v2.salary >= 200
서브쿼리에서 조인으로의 변환
EMPNO LASTNAME WORKDEPT
-----------------------------------------------------
000010 HAAS A00
000020 THOMPSON B01
000030 KWAN C01
000050 GEYER E01
000060 STERN D11
$ db2 "SELECT deptno, deptname FROM department"
DEPTNO DEPTNAME
-----------------------------------------------------
A00 SPIFFY COMPUTER SERVICE DIV.
B01 PLANNING
C01 INFORMATION CENTER
D01 DEVELOPMENT CENTER
D11 MANUFACTURING SYSTEMS
SELECT empno, lastname
FROM employee
WHERE workdept IN
(SELECT deptno
FROM department
WHERE deptname = 'PLANNING');
$ db2 ?tf query.sql
FROM employee emp,
department dept
WHERE emp.workdept = dept.deptno
AND dept.deptname = 'PLANNING
중복 조인 제거
SELECT e1.empno, e1.firstnme, e1.lastname, e1.edlevel
FROM employee e1, employee e2
WHERE e1.empno = e2.empno
AND e1.edlevel > 17
AND e2.salary > 35000 ;
$ db2 ?tf query.sql
FROM employee
WHERE edlevel > 17
AND salary > 35000
CREATE VIEW vpeople AS
SELECT lastname, salary, deptno, deptname, mgrno
FROM employee e, department d
WHERE e.workdept = d.deptno ;
$ db2 ?tf view.sql
SELECT lastname, salary FROM vpeople;
$ db2 ?tf query.sql
FROM employee
WHERE workdept IS NOT NULL
공유 총계
SELECT SUM(salary+bonus+comm) AS osum,
AVG(salary+bonus+comm) AS oavg,
COUNT(*) AS ocount
FROM employee;
$ db2 ?tf query.sql
osum / ocount
ocount
FROM (SELECT sum(salary+bonus+comm) as osum,
count(*) as ocount
FROM employee
) AS shared_agg;
DISTINCT 제거
인덱스 인덱스 고유한 컬럼 컬럼
스키마 이름 규칙 수 이름
------------------------------------------------------------------------------------------------
SYSIBM SQL060511155131630 P 1 +EMPNO
SELECT DISTINCT empno, firstnme, lastname
FROM employee;
$ db2 -tf query.sql
FROM employee
일반 술어 푸시다운
CREATE VIEW d11_empl (empno, firstnme, lastname, phoneno) AS
SELECT empno, firstnme, lastname, phoneno
FROM employee
WHERE workdept = 'D11';
$ db2 ?tf view.sql
SELECT firstnme, phoneno
FROM d11_empl
WHERE lastname = 'BROWN';
$ db2 ?tf query.sql
FROM employee
WHERE workdept = 'D11'
AND lastname = 'BROWN'
FROM employee
WHERE lastname = 'BROWN'
AND workdept = 'D11'
상관 해제
e.salary+e.bonus+e.comm AS pay
FROM employee e, project p
WHERE p.respemp = e.empno
AND p.projname like '%PROGRAMMING%'
AND e.salary+e.bonus+e.comm
(SELECT avg(e1.salary+e1.bonus+e1.comm)
FROM employee e1, project p1
WHERE p1.projname like '%PROGRAMMING%'
AND p1.projno = p.projno
AND e1.empno = p1.respemp)
(SELECT p2.projno, avg(e1.salary+e1.bonus+e1.comm)
FROM employee e1, project p2
WHERE e1.empno = p2.respemp
AND p2.projname LIKE '%PROGRAMMING%'
GROUP BY p2.projno
e.salary+e.bonus+e.comm as compensation
FROM project p, employee e, avg_proj a
WHERE p.empno = e.empno
AND p.projname LIKE '%programming%'
AND p.projno = a.projno
AND e.salary+e.bonus+e.comm < a.avg_comp
암시적 술어
SELECT d.deptname d.mgrno, e.lastname, p.projname
FROM department d,
employee e,
project p
WHERE d.admrdept = 'E01'
AND d.mgrno = e.empno
AND e.empno = p.respemp;
$ db2 ?tf query.sql
SELECT empno, lastname, firstname, deptno, deptname
FROM employee emp,
department dept
WHERE emp.workdept = dept.deptno
AND dept.deptno > 'E00';
$ db2 ?tf query.sql
OR에서 IN으로의 변환
FROM employee
WHERE workdept = 'D11'
OR workdept = 'D21'
OR workdept = 'E21';
$ db2 ?tf query.sql
FROM employee
WHERE workdept IN ('D11', 'D21', 'E21')
패키지



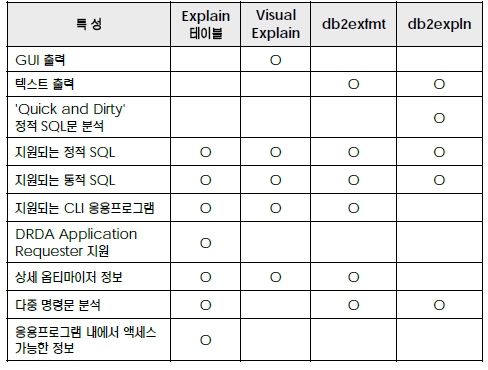
익스플레인 도구
$ db2 -tvf $HOME/sqllib/misc/EXPLAIN.DDL
$ db2 list tables for all | grep EXPLAIN
Visual Explain
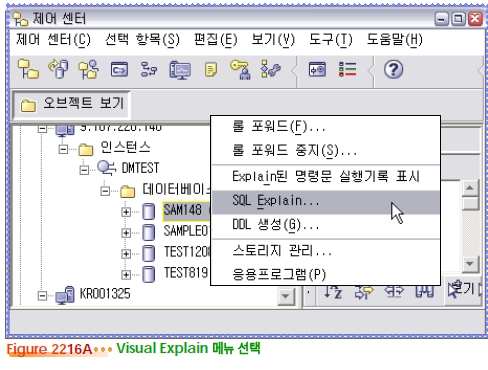
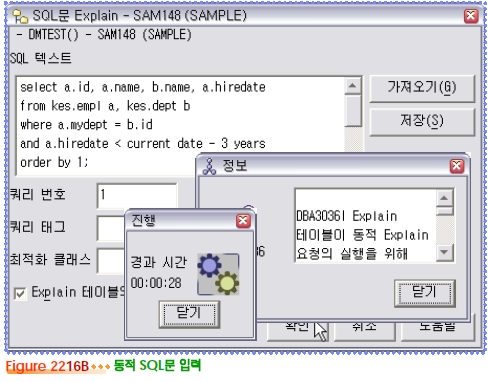
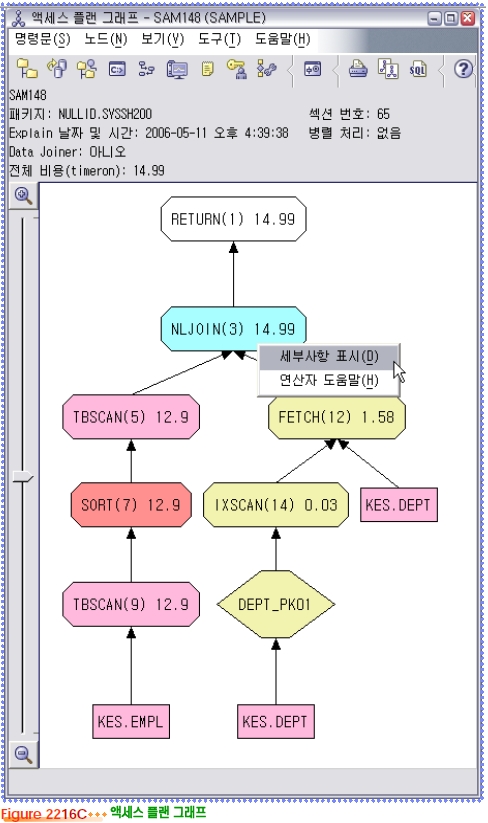
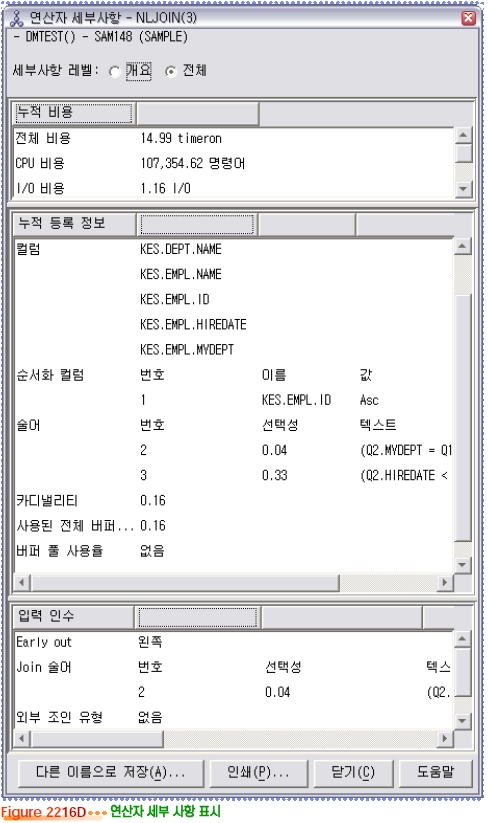
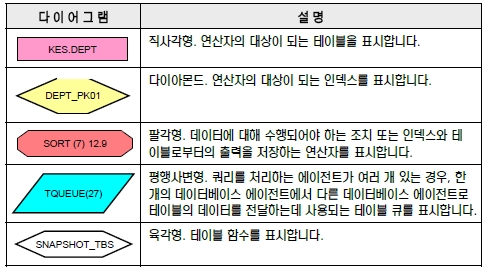


db2expln 유틸리티
동적 SQL문에 대한 db2expln 출력
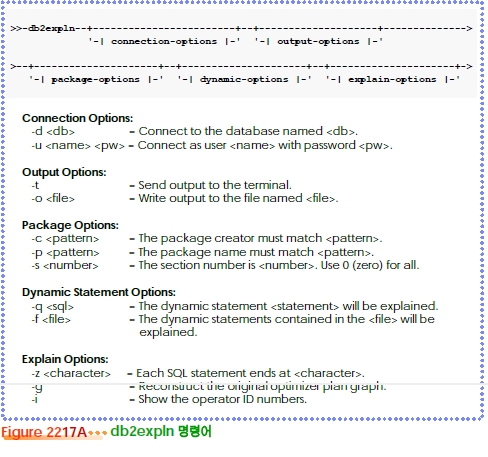
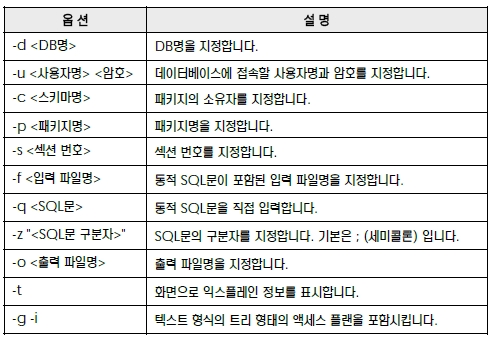
$ db2expln ?d 데이터베이스명> -q 동적 SQL문> -o 출력 파일명> -g -i
$ db2expln ?d 데이터베이스명> -f 입력 파일명> -z ";" -o 출력 파일명> -g -i
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM
Corp. 1991, 2002
Licensed Material - Program Property of IBM
IBM DB2 Universal Database SQL Explain Tool
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM
Corp. 1991, 2002
Licensed Material - Program Property of IBM
IBM DB2 Universal Database SQL Explain Tool
******************** DYNAMIC ***************************************
============== STATEMENT ===========================
Isolation Level = Cursor Stability
Blocking = Block Unambiguous Cursors
Query Optimization Class = 5
Partition Parallel = No
Intra-Partition Parallel = No
SQL Path = "SYSIBM", "SYSFUN", "SYSPROC", "POST01"
SQL Statement:
select name
from kes.empl
where id =1
다음 페이지에 계속됨>
Estimated Cost = 12.869981
Estimated Cardinality = 1.000000
( 2) Access Table Name = KES.EMPL ID = 2,15
| Index Scan: Name = KES.EMPL_PK01 ID = 1
| | Regular Index (Not Clustered)
| | Index Columns:
| | | 1: ID (Ascending)
| #Columns = 7
| Single Record
| Fully Qualified Unique Key
| #Key Columns = 1
| | Start Key: Inclusive Value
| | | | 1: 1
| | Stop Key: Inclusive Value
| | | | 1: 1
| Data Prefetch: Eligible 0
| Index Prefetch: None
| Lock Intents
| | Table: Intent Share
| | Row : Next Key Share
| Sargable Predicate(s)
( 2) | | Return Data to Application
| | | #Columns = 7
( 1) Return Data Completion
End of section
Optimizer Plan:
RETURN
( 1)
|
FETCH
( 2)
/ \
IXSCAN Table:
( 2) KES
| EMPL
Index:
KES
EMPL_PK01
정적 SQL문에 대한 db2expln 출력
EXEC SQL BEGIN DECLARE SECTION;
char c2[30+1];
EXEC SQL END DECLARE SECTION;
int main()
{
EXEC SQL CONNECT TO sample;
EXEC SQL SELECT name
INTO :name
FROM kes.empl
WHERE id = 1;
printf("name = %s\n",name);
EXEC SQL CONNECT RESET;
exit(0);
}
$ db2 prep select64.sqc
바인드 총 분리
패키지 스키마 버전 방법 섹션 유효 형식 레벨 블로킹
---------------------------------------------------------------------------------------------------
SELECT64 POST01 POST01 1 Y 0 CS U
1 레코드가 선택됨.
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM Corp.
1991, 2002
Licensed Material - Program Property of IBM
IBM DB2 Universal Database SQL Explain Tool
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM Corp.
1991, 2002
Licensed Material - Program Property of IBM
IBM DB2 Universal Database SQL Explain Tool
******************** PACKAGE ***************************************
Package Name = "POST01"."SELECT64" Version = ""
Prep Date = 2006/05/22
Prep Time = 14:05:46
Bind Timestamp = 2006-05-22-14.05.46.565000
Isolation Level = Cursor Stability
Blocking = Block Unambiguous Cursors
Query Optimization Class = 5
Partition Parallel = No
Intra-Partition Parallel = No
SQL Path = "SYSIBM", "SYSFUN", "SYSPROC", "POST01"
-------------------- SECTION ---------------------------------------
Section = 1
SQL Statement:
SELECT name INTO :H00002
FROM kes.empl
WHERE id =1
Section Code Page = 970
Estimated Cost = 12.869981
Estimated Cardinality = 1.000000
다음 페이지에 계속됨>
| Index Scan: Name = KES.EMPL_PK01 ID = 1
| | Regular Index (Not Clustered)
| | Index Columns:
| | | 1: ID (Ascending)
| #Columns = 1
| Single Record
| Fully Qualified Unique Key
| #Key Columns = 1
| | Start Key: Inclusive Value
| | | | 1: 1
| | Stop Key: Inclusive Value
| | | | 1: 1
| Data Prefetch: Eligible 0
| Index Prefetch: None
| Lock Intents
| | Table: Intent Share
| | Row : Next Key Share
| Sargable Predicate(s)
| | Return Data to Application
| | | #Columns = 1
Return Data Completion
End of section
Optimizer Plan:
RETURN
( 1)
|
FETCH
( 2)
/ \
IXSCAN Table:
( 2) KES
| EMPL
Index:
KES
EMPL_PK01
db2exfmt 유틸리티
$ db2 -tvf $HOME/sqllib/misc/EXPLAIN.DDL


동적 SQL문에 대한 db2exfmt 출력
$ db2 "SQL문"
SQL0217W Explain 정보 요청만 처리 중이므로 명령문이 실행되지 않았습니다.
SQLSTATE=01604
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM
Corp. 1991, 2002
Licensed Material - Program Property of IBM
IBM DATABASE 2 Explain Table Format Tool
******************** EXPLAIN INSTANCE ********************
DB2_VERSION: 08.02.3
SOURCE_NAME: SQLC2E06
SOURCE_SCHEMA: NULLID
SOURCE_VERSION:
EXPLAIN_TIME: 2006-05-22-16.29.01.594001
EXPLAIN_REQUESTER: KR001325
Database Context:
----------------
Parallelism: None
CPU Speed: 3.778754e-007
Comm Speed: 0
Buffer Pool size: 250
Sort Heap size: 256
Database Heap size: 600
Lock List size: 50
Maximum Lock List: 22
Average Applications: 1
Locks Available: 1122
Package Context
:
---------------
SQL Type: Dynamic
Optimization Level: 5
Blocking: Block All Cursors
Isolation Level: Cursor Stability
---------------- STATEMENT 1 SECTION 201 ----------------
QUERYNO: 33
다음 페이지에 계속됨>
Statement Type: Select
Updatable: No
Deletable: No
Query Degree: 1
Original Statement:
------------------
select name
from kes.empl
where id=1
Optimized Statement:
-------------------
SELECT Q1."NAME" AS "NAME"
FROM KES.EMPL AS Q1
WHERE (Q1."ID" = 1)
Access Plan:
-----------
Total Cost: 12.87
Query Degree: 1
Rows
RETURN
( 1)
Cost
I/O
|
1
FETCH
( 2)
12.87
1
/----+---\
1 4
IXSCAN TABLE: KES
( 3) EMPL
0.0155141
0
|
4
INDEX: KES
EMPL_PK01
다음 페이지에 계속됨>
--------------------------------
Diagnostic Identifier: 1
Diagnostic Details: EXP0022W Index has no statistics.
The index "KES "."EMPL_PK01" has not had runstats run on it. This can
lead to poor cardinality and predicate filtering estimates.
Diagnostic Identifier: 2
Diagnostic Details: EXP0020W Table has no statistics. The table "KES
"."EMPL" has not had runstats run on it. This can lead to poor
cardinality and predicate filtering estimates.
Plan Details:
-------------
1) RETURN: (Return Result)
Cumulative Total Cost: 12.87
Cumulative CPU Cost: 52876
Cumulative I/O Cost: 1
Cumulative Re-Total Cost: 0.00280195
Cumulative Re-CPU Cost: 7415
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 12.8696
Estimated Bufferpool Buffers: 2
Arguments:
---------
BLDLEVEL: (Build level) DB2 v8.1.10.812 : s050811
STMTHEAP: (Statement heap size) 2048
Input Streams:
-------------
4) From Operator #2
Estimated number of rows: 1
Number of columns: 1
Subquery predicate ID: Not Applicable
Column Names:
------------
+Q2."NAME"
2) FETCH : (Fetch)
Cumulative Total Cost: 12.87
Cumulative CPU Cost: 52876
Cumulative I/O Cost: 1
Cumulative Re-Total Cost: 0.00280195
Cumulative Re-CPU Cost: 7415
다음 페이지에 계속됨>
Cumulative First Row Cost: 12.8696
Estimated Bufferpool Buffers: 2
Arguments:
---------
MAXPAGES: (Maximum pages for prefetch)
ALL
MAXPAGES: (Maximum pages for prefetch)
ALL
PREFETCH: (Type of Prefetch)
NONE
ROWLOCK : (Row Lock intent)
NEXT KEY SHARE
TABLOCK : (Table Lock intent)
INTENT SHARE
TBISOLVL: (Table access Isolation Level)
CURSOR STABILITY
Input Streams:
-------------
2) From Operator #3
Estimated number of rows: 1
Number of columns: 0
Subquery predicate ID:Not Applicable
3) From Object KES.EMPL
Estimated number of rows: 4
Number of columns: 1
Subquery predicate ID:Not Applicable
Column Names:
------------
+Q1."NAME"
Output Streams:
--------------
4) To Operator #1
Estimated number of rows: 1
Number of columns: 1
Subquery predicate ID: Not Applicable
Column Names:
------------
+Q2."NAME"
다음 페이지에 계속됨>
Cumulative Total Cost: 0.0155141
Cumulative CPU Cost: 41056
Cumulative I/O Cost: 0
Cumulative Re-Total Cost: 0.00211421
Cumulative Re-CPU Cost: 5595
Cumulative Re-I/O Cost: 0
Cumulative First Row Cost: 0.0155141
Estimated Bufferpool Buffers: 1
Arguments:
---------
MAXPAGES: (Maximum pages for prefetch)
ALL
PREFETCH: (Type of Prefetch)
NONE
ROWLOCK : (Row Lock intent)
NEXT KEY SHARE
SCANDIR : (Scan Direction)
FORWARD
TABLOCK : (Table Lock intent)
INTENT SHARE
Predicates:
----------
2) Start Key Predicate
Relational Operator: Equal (=)
Subquery Input Required: No
Filter Factor: 0.25
Predicate Text:
--------------
(Q1."ID" = 1)
2) Stop Key Predicate
Relational Operator: Equal (=)
Subquery Input Required: No
Filter Factor: 0.25
Predicate Text:
--------------
(Q1."ID" = 1)
다음 페이지에 계속됨>
-------------
1) From Object KES.EMPL_PK01
Estimated number of rows: 4
Number of columns: 2
Subquery predicate ID: Not Applicable
Column Names:
------------
+Q1.$RID$+Q1."ID"
Output Streams:
--------------
2) To Operator #2
Estimated number of rows: 1
Number of columns: 0
Subquery predicate ID: Not Applicable
Objects Used in Access Plan:
---------------------------
Schema: KES
Name: EMPL_PK01
Type: Index
Time of creation: 2006-05-22-14.02.58.864000
Last statistics update:
Number of columns: 1
Number of rows: 4
Width of rows: -1
Number of buffer pool pages: 1
Distinct row values: Yes
Tablespace name: USERSPACE1
Tablespace overhead: 12.670000
Tablespace transfer rate: 0.180000
Source for statistics: Single Node
Prefetch page count: 32
Container extent page count: 32
Index clustering statistic: 20.000000
Index leaf pages: 1
Index tree levels: 1
다음 페이지에 계속됨>
Index first key cardinality: 4
Index first 2 keys cardinality: -1
Index first 3 keys cardinality: -1
Index first 4 keys cardinality: -1
Index sequential pages: 1
Index page density: 100
Index avg sequential pages: -1
Index avg gap between sequences: -1
Index avg random pages: -1
Fetch avg sequential pages: -1
Fetch avg gap between sequences: -1
Fetch avg random pages: -1
Index RID count: 0
Index deleted RID count: 0
Index empty leaf pages: 0
Base Table Schema: KES
Base Table Name: EMPL
Columns in index: ID
Schema: KES
Name: EMPL
Type: Table
Time of creation: 2006-05-22-14.02.58.804001
Last statistics update:
Number of columns: 7
Number of rows: 4
Width of rows: 37
Number of buffer pool pages: 1
Distinct row values: No
Tablespace name: USERSPACE1
Tablespace overhead: 12.670000
Tablespace transfer rate: 0.180000
Source for statistics: Single Node
Prefetch page count: 32
Container extent page count: 32
Table overflow record count: 0
Table Active Blocks: -1
정적 SQL문에 대한 db2exfmt 출력
$ db2 bind 바인드 파일명> EXPLAIN YES 또는 ALL>

$ db2 prep select64.sqc EXPLAIN YES
DB2 Universal Database Version 8.1, 5622-044 (c) Copyright IBM Corp.
1991, 2002
Licensed Material - Program Property of IBM
IBM DATABASE 2 Explain Table Format Tool
******************** EXPLAIN INSTANCE ********************
DB2_VERSION: 08.02.3
SOURCE_NAME: SELECT64
SOURCE_SCHEMA: KR001325
SOURCE_VERSION:
EXPLAIN_TIME: 2006-05-22-17.13.15.731000
EXPLAIN_REQUESTER: KR001325
Database Context:
----------------
생략>