
DBMS 1
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
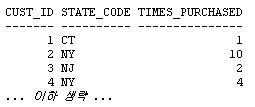
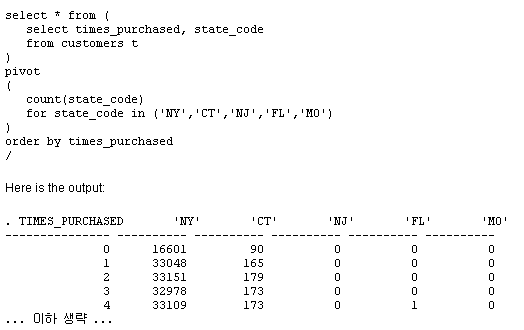
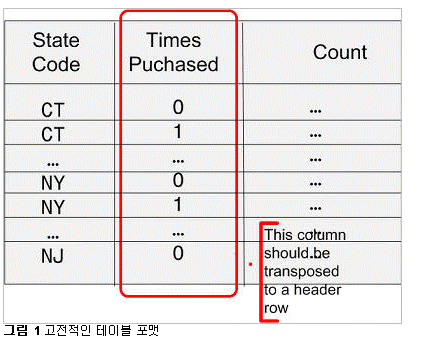
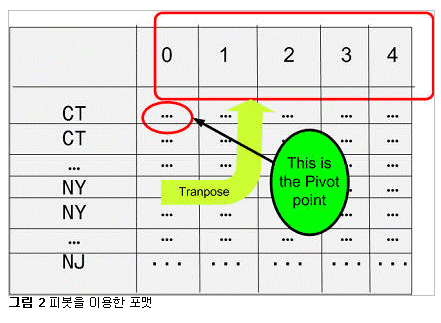
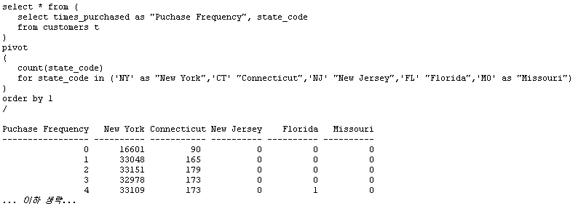
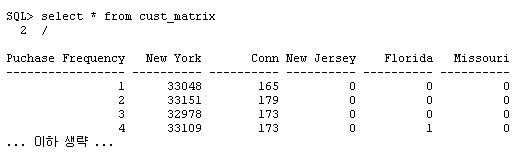
간단한 SQL 구문을 이용하여 임의의 관계형 테이블로부터 스프레드시트 스타일의 크로스탭 리포트를 생성하고, 크로스탭 테이블의 데이터를 관계형 테이블에 저장할 수 있습니다. 관계형 테이블은 행과 열로 구성됩니다. CUSTOMERS 테이블의 예가 아래와 같습니다. 이 테이블에 대해 쿼리를 실행해 봅시다: 그 결과가 아래와 같습니다: 데이터가 여러 로우의 값으로 표시되고 있음을 확인할 수 있습니다. 각각의 고객에 대해, 고객이 거주하는 주(state) 정보와 고객이 매장에서 얼마나 자주 상품을 구입했는지에 대한 정보가 표시됩니다. 고객이 새로운 상품을 구입할 때마다 times_purchased 컬럼이 업데이트 됩니다. 이제 각 주별 구입 횟수 통계에 대한 보고서를 작성해야 한다고 가정해 봅시다. 보고서에는 각 주별로 상품을 1회, 2회, 3회, 또는 그 이상 구입한 고객 수에 대한 정보가 포함됩니다. 이를 SQL로 작성하면 아래와 같습니다: 필요한 정보는 다 들어 있지만 읽기 어렵다는 것이 문제입니다. 크로스탭(crosstab) 리포트를 이용하면 같은 데이터를 좀 더 알아보기 쉽게 스프레드시트 스타일로 표시할 수 있습니다: Oracle Database 11g 이전 버전에서는 각각의 값에 대해 decode 함수를 적용하고 일일이 별도의 컬럼에 기록해야만 했습니다. 하지만 이러한 방법은 전혀 직관적이지도, 효율적이지도 않습니다. Oracle Database 11g에 새로 추가된 PIVOT 기능을 이용하면 'pivot' 연산자를 기반으로 크로스탭 포맷에 쿼리 결과를 표시하는 것이 가능합니다. 쿼리의 작성 예가 아래와 같습니다: 위 결과를 통해 pivot 연산자의 강력한 기능을 확인할 수 있습니다. state_codes는 컬럼이 아닌 헤더 로우에 표시되고 있습니다. 고전적인 형태의 테이블 포맷은 아래와 같은 형태로 표시됩니다: 크로스탭 리포트에서 Times Purchased 컬럼을 그림 2와 같이 헤더로 이동시키고자 합니다. 이는 결국 컬럼이 로우로 변환되는 효과를 가지며, 컬럼은 반시계 방향으로 90도 회전하여 헤더 로우가 됩니다. 이처럼 회전이 가능하려면 중심점(pivot point)가 필요합니다. 여기서 중심점 역할을 하는 것이 바로 count(state_code) 표현식입니다. 이 표현식은 쿼리의 신택스 내에서 사용되어야 합니다: 두 번째 라인("for state_code ...,")은 쿼리를 정의된 값으로만 한정하고 있습니다. 따라서 가능한 결과 값을 미리 알고 있어야 합니다. 하지만 이러한 제약은 XML 포맷에서는 완화됩니다(본 문서의 뒷부분에서 설명). 출력 결과의 헤더 로우를 주목하십시오: 컬럼 헤더는 테이블의 states codes 데이터를 인용하고 있습니다. 각 주의 이름이 약자로 표시되는 것이 불만이라면, 쿼리의 FOR 절을 아래와 같이 변경해 주는 방법도 있습니다: 값을 대체하는 앨리어스(alias)가 컬럼 헤더를 위해 정의되고 있습니다. 물질이 있으면 '반물질'이 있듯, Pivot이 있으면 'Unpivot'도 있어야 합니다.실제로도 Unpivot은 그 필요성을 가집니다. 아래와 같은 크로스탭 리포트를 포함하는 스프레드시트를 가정해 봅시다: 이제 이 데이터를 CUSTOMERS라는 이름의 관계형 테이블에 로드하고자 합니다: 여기서 스프레드시트를 관계형 포맷으로 역정규화(de-normalize)하는 작업이 필요합니다. 물론 복잡한 SQL*:Loader 또는 DECODE를 이용한 스크립트를 통해 데이터를 CUSTOMER 테이블에 로드할 수도 있을 것입니다. 또는 Oracle Database 11g 환경에서 Pivot의 역작업을 담당하는 Unpivot을 이용하여 컬럼을 분할할 수도 있습니다. 이제 테이블에 데이터가 어떻게 저장되어 있는지 확인해 봅니다: 위 포맷은 스프레드시트에 저장된 방식과 동일합니다. 각 주는 테이블의 컬럼으로 사용되고 있습니다. 이제 테이블을 분할하여 로우에 state code와 count만이 표시되도록 해야 합니다. 이를 위해 아래와 같이 unpivot 연산자를 사용할 수 있습니다: 각 컬럼 명이 STATE_CODE 컬럼의 값으로 변환되었음을 주목하십시오. 오라클은 state_code가 컬럼 명으로 사용되었다는 사실을 어떻게 알았을까요 바로 아래의 쿼리 구문 덕분입니다: 이 구문은 "New York", "Conn 등이 unpivot을 통해 생성되는 새로운 컬럼의 값으로 사용됨을 정의하고 있습니다. 기존 데이터의 일부를 다시 참고해 봅시다: "New York" 컬럼이 로우의 값으로 변환되어 버렸습니다. 그렇다면 33048이라는 값은 어느 컬럼 밑에 표시해야 할까요 위 쿼리의 unpivot 연산자가 사용된 구문의 바로 위쪽을 보면 그 해답이 있습니다. 바로 state_counts가 새로운 컬럼으로 사용되고 있습니다. Unpivot은 pivot의 역작업을 담당합니다. 하지만 unpivot으로 pivot 결과를 뒤집을 수 있을 것이라 기대해서는 곤란합니다. 위의 예에서는 CUSTOMERS 테이블에 대해 pivot 연산자를 사용하여 CUST_MATRIX이라는 새로운 테이블을 생성하였습니다. 나중에 CUST_MATRIX 테이블에 unpivot을 적용할 수는 있지만 그 결과로 항상 기존의 CUSTOMERS 테이블이 그대로 생성되는 것은 아닙니다. 그대신 크로스탭 리포트는 관계형 테이블에 로드 가능한 다른 형태로 표현될 수 있습니다. 다시 말해, unpivot은 pivot의 수행 결과를 다시 원상 복구하기 위한 대안은 아니며, 따라서 원본 테이블은 어떤 경우에도 그대로 유지되어야 합니다. 앞에서 예로 든 것 이외에도, unpivot은 매우 강력한 데이터 처리 도구로 활용됩니다. 오라클 ACE 디렉터인 루카스 젤레마(Lucas Jellema)는 테스트 목적으로 특정 데이터의 로우를 생성하는 방법에 대해 설명한 바 있습니다. 루카스가 제공한 코드를 약간 수정하여 영어 알파벳의 모음을 생성하는 구문을 아래와 같이 작성해 보았습니다: 이 로우 생성기 모델은 어떤 형태로든 확장이 가능합니다. 루카스가 제공해 준 유용한 팁에 감사를 표합니다. 위의 예에서 state_code를 정의하기 위해 아래 구문이 사용되었습니다 결국 사용자는 state_code 컬럼에 어떤 값이 표시되는지 미리 알고 있어야 합니다. 컬럼 값을 미리 알고 있지 못한 경우라면 쿼리를 어떻게 구현할 수 있을까요 결과는 CLOB으로 반환됩니다. 그러므로 쿼리를 실행하기 전에 LONGSIZE를 충분히 큰 값으로 설정해 주어야 합니다. 위 구문은 앞서 예로 든 pivot 구문과 두 가지 중요한 차이점을 갖습니다(굵은 글꼴로 표시된 부분 참조). 먼저 pivot 대신 'pivot xml'이 사용되고 있습니다. 이 구문을 사용하면 결과가 XML 포맷으로 출력됩니다. 두 번째로 state_code 값을 일일이 입력하는 대신 "state_code in (any)" 구문이 사용되었습니다. XML 포맷에서는 ANY 키워드가 허용되므로 굳이 state_code 값을 입력할 필요가 없습니다. 실행 결과가 아래와 같습니다: 위에서 확인할 수 있듯, STATE_CODE_XML 컬럼은 XMLTYPE로 지정되었으며 루트 엘리먼트는 입니다. 각각의 값은 'name-value' 엘리먼트 쌍으로 표시됩니다. XML 파서를 이용하면 좀 더 유용한 형태로 출력 결과를 다듬을 수 있습니다. FOR 구문 내의 서브쿼리는 원하는 어떤 형태로든 정의할 수 있습니다. 예를 들어 CUSTOMERS 테이블에서 사용되는 모든 주 정보를 확인하고자 하는 경우라면 아래와 같이 작성하면 됩니다: 서브쿼리는 유니크한 값을 반환해야 합니다. 그렇지 않은 경우 쿼리는 실패합니다. 위에 DISTINCT 키워드를 넣은 것도 그 때문입니다. Pivot은 SQL 환경에서 매우 중요하고도 유용한 기능을 제공합니다. 많은 수의 decode 함수를 포함하는 복잡하고 비직관적인 코드를 작성하는 대신, pivot 함수를 이용하여 임의의 관계형 테이블에 대한 크로스탭 리포트를 생성할 수 있습니다. 마찬가지로, unpivot 연산자를 사용하면 임의의 크로스탭 리포트를 정규 관계형 테이블로 변환하는 것이 가능합니다. Pivot은 출력 결과를 일반 텍스트 또는 XML 포맷으로 반환합니다. XML을 이용하는 경우에는 pivot 연산에 사용되는 값 목록을 별도로 정의해 줄 필요가 없습니다.SQL 작업 : Pivot과 Unpivot
SQL 작업 : Pivot과 Unpivot
간략한 개요
Pivot





![]()
Unpivot


Unpivot의 실제 사용 예를 들어 설명해 보겠습니다. 먼저 pivot 연산자를 이용하여 크로스탭 테이블을 생성합니다:


![]()


XML Type
![]()
pivot 연산자와 함께 사용되는 XML 옵션은 피봇 처리된 결과를 XML 포맷으로 생성할 수 있게 합니다. 이 포맷에서는 실제 컬럼 값 대신 'ANY'를 사용할 수 있습니다. 그 예가 아래와 같습니다:
![]()

ANY 키워드를 사용하는 것과 별개로 서브쿼리를 작성하는 것도 가능합니다. 선호되는 주의 목록을 미리 정의하고 이 주에 대해서만 로우를 반환하기를 원하는 경우_states라는 이름의 새로운 테이블에 저장하기로 합니다:
![]()
결론