
DBMS 1
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
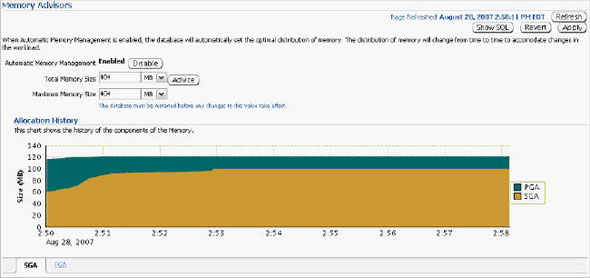
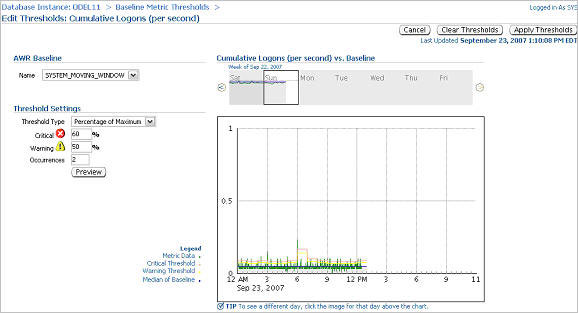
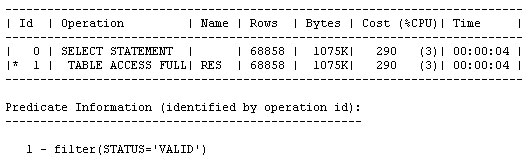
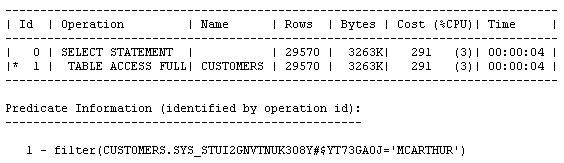
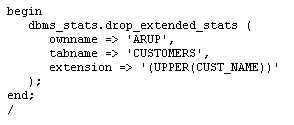
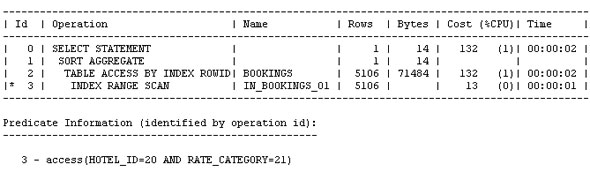
오라클이 전체 메모리를 자동 관리하도록 설정하고, 실제 사용 중인 기능에 관련된 패치만을 자동으로 적용하고, 수집된 옵티마이저 통계를 적용 전에 미리 확인하고, 옵티마이저에서 컬럼들 간의 상관 관계를 파악하도록 설정하는 기능이 새로이 제공됩니다. 오라클 데이터베이스 인스턴스는 PMON, SMON과 같은 일련의 프로세스와 System Global Area(SGA), Program Global Area(PGA) 등의 메모리 영역으로 구성되어 있습니다. 또 SGA는 내부적으로 데이터베이스 캐시, 공유 풀과 같은 여러 영역으로 나뉘어집니다. 각 영역의 크기를 어떻게 설정하고 계신가요 호스트의 메모리 용량에는 한계가 있으며, 그 중 일부는 운영 체제에 할당되어야 합니다. 따라서 영역별로 할당되는 메모리 크기를 설정하는 작업은 결코 쉽지 않습니다. Oracle Database 10g는 전체 SGA 메모리 영역의 크기 설정을 위한 SGA_TARGET 매개변수를 통해 이러한 문제를 상당 부분 해결하였습니다. 이때 캐시, 공유 풀과 같은 하부 영역은 자동으로 튜닝됩니다. 하지만 10g에서도 db_cache_keep_size와 같은 일부 구성 요소들은 여전히 수작업 튜닝이 필요했습니다. PGA 메모리 영역은 SGA와는 완전히 별개로 존재하며, 따라서 Automatic SGA Management 기능에 의해 관리될 수 없습니다. 따라서 SGA, PGA의 크기를 각각 결정하는 작업은 여전히 관리자의 몫입니다. PGA에 너무 많은 용량을 배정하는 바람에 SGA의 용량이 부족해졌다면 성능 저하가 불가피할 것입니다. 그렇다면 PGA와 SGA의 영역 설정이 한층 유연해져 서로 간에 할당된 메모리를 자유롭게 이전할 수 있다면 좋지 않을까요 Oracle Database 11g에서는 바로 이러한 기능이 제공됩니다. SGA_TARGET과 PGA_AGGREGATE_TARGET을 설정하는 대신 MEMORY_TARGET을 설정하면 됩니다. Enterprise Manager Database 홈페이지에서 Advisor Central > Memory Advisor를 선택합니다: Enable을 클릭하여 Automatic Memory Management를 활성화합니다: OK를 클릭합니다. Max Memory Target은 정적 매개변수이므로 데이터베이스를 재시작해야 합니다. 커맨드라인을 통해서도 동일한 작업을 수행할 수 있습니다: SQL> alter system set memory_max_target = 1G scope=spfile; System altered. SQL> alter system set memory_target = 1G scope = spfile; System altered. UNIX 기반 시스템에서 max memory는 /dev/shm 공유 메모리 파일 시스템의 크기보다 작게 설정되어야 합니다. 이 기능은 Linux, Solaris, HPUX, AIX, Windows 등의 운영 체제에 구현되어 있습니다. 위 예에서는 여유 용량이 500MB에 불과하므로 404MB를 MEMORY_TARGET으로 설정하였습니다. 값을 설정하고 데이터베이스를 재시작하면 화면이 아래와 같이 변경됨을 확인할 수 있습니다: 아래 화면은 시간의 흐름에 따른 SGA, PGA 영역 구분을 보여 주고 있습니다. 화면의 나머지 부분에서는 SGA의 서브-풀이 어떻게 할당되었고, 시간에 따라 그 용량이 어떻게 변화되었는지 확인할 수 있습니다. 이러한 할당 내역은 데이터베이스에 대한 애플리케이션의 요구 사항에 따라 자동으로 변경됩니다. 따라서 관리자는 추측에 의존하지 않고 메모리 관리에 드는 수고를 덜 수 있습니다. SGA 컴포넌트의 경우와 마찬가지로, 메모리 컴포넌트는 개별 구성 요소의 최소 크기를 기준으로 정의됩니다. 아래와 같은 예를 생각해 봅시다: memory_target = 10G 여기서 memory_target은 10GB로 설정되었습니다. 다른 두 개의 매개변수는 최소값으로서 정의됩니다. 따라서 SGA, PGA의 최소값은 각각 2GB, 1GB로 정의됩니다. 메모리 요구가 증가 또는 감소하면서 메모리 영역은 확장/축소됩니다. 현재의 할당 현황은 V$MEMORY_DYNAMIC_COMPONENT에서 확인할 수 있습니다. 실행 결과가 아래와 같습니다. 크게보기 v$memory_resize_ops 뷰도 유용합니다. 이 뷰는 지금까지 발생한 resize 작업에 대한 정보를 저장하고 있습니다. 이런 경우를 생각해 봅시다: 현재 운영 중인 데이터베이스의 parse-to-hit ratio가 x인 수준을 유지하고 있었습니다. 그런데 갑자기 이 비율이 50퍼센트 증가하여 1.5x가 되었습고 있으며 이것이 parse-to-hit ratio 증가의 원인이 되었음이 밝혀졌습니다. 또 이러한 (야간에 DSS 타입 쿼리를 실행하는) 패턴이 지극히 정상적인 것임을 확인하였습니다. 따라서는 2x까지 증가할 수도 있습니다. 이러한 상황이라면 시간에 따라 임계치를 다르게 적용하는 것이 도움이 될 것입니다. 예를 들어 OLTP 작업이 주로 수행되는 주간에는 1.2x로, 야간에는 2x로 설정할 수 있을 것입니다. 이럴게 설정하는 것이 과연 가능할까요 이러한 목적을 위해 Oracle Database 11g에 추가된 기능이 바로 Adaptive Thresholds입니다. 임계치는 과거의 운영 패턴과 AWR 스냅샷에서 계산된 결과를 기반으로 각 시간대별로 유연하게 적용됩니다. Oracle Database 11g의 다른 기능들과 마찬가지로 이 작업 또한 커맨드 라인과 Oracle Enterprise Manager의 두 가지 방법으로 수행 가능합니다. 그럼 GUI를 이용해 작업하는 방법을 알아 봅시다. 먼저 AWR Baseline을 정의합니다. AWR Baseline은 Oracle Database 10g의 Preserved Snapshot과 유사하며 성능 메트릭의 결정을 위한 시작점으로서 활용됩니다. 이 베이스라인을 이용하여 성능 메트릭이 시간대별로 어떻게 변화하는지 비교할 수 있습니다. 메인 데이터베이스 홈 페이지에서 Performance 탭을 선택하고 Additional Monitoring Links로 이동합니다: 이 페이지에서 세 번째 컬럼의 AWR Baselines를 클릭하면 아래와 같은 스크린이 표시됩니다: 이 화면은 이미 베이스라인 SYSTEM_MOVING_WINDOW를 포함하고 있습니다. 이 베이스라인은 Oracle Database 11g에서 기본적으로 활성화됩니다. Edit을 클릭하여 베이스라인과 관련한 임계치의 변화를 확인합니다. 아래와 같은 화면이 표시됩니다: 이 화면은 메트릭 Cumulative Logons per second에 대해 정의된 임계치를 보여 주고 있습니다. 사용자는 베이스라인에 특정 임계치를 정의할 수 있습니다(여기에서는 60%로 정의되었습니다). 이렇게 임계치가 설정되고 나면, 초당 누적 로그온 횟수가 동일한 날짜 및 시간에 대한 최대치의 60% 이상을 최소 2회 이상 초과하는 경우 "critical alert"가 발생합니다. (60퍼센트는 매우 낮은 수치입니다. 여기에서는 단순히 예시를 위해 사용되었습니다.) 이제 시간이 흘러 사용자가 증가하면 할 수록, 임계치는 그에 맞추어 자동으로 변경됩니다. 최대값에 대한 퍼센티지로 설정하는 대신 특정 값을 임계치로 설정할 수도 있습니다. 또 다른 매개변수인 Occurrences를 이용하면 임계치를 여러 차례 초과한 경우에만 경고가 발생하도록 할 수 있습니다. 오른쪽의 그림에서 일정 기간 동안의 메트릭이 표시되고 있음을 확인할 수 있습니다. 작은 사각형 상자는 줌(zoom) 도구입니다. 그림의 임의 영역에 사각형을 가져가면 상세한 정보가 표시됩니다. 이번에는 이런 경우를 생각해 봅시다. 모든 테이블, 인덱스 등에 대한 통계를 면밀하게 수집하고 모든 쿼리가 완벽한 실행 계획을 갖도록 정비하였습니다. 그런데 누군가가 통계 수집 작업을 다시 실행하였고 이로 인해 실행 계획이 모두 변경되어 버렸습니다. 물론 그 결과로 성능이 더 개선될 수도 있지만 (가능성은 좀 더 낮지만) 성능이 악화되었을 수도 있습니다. 이러한 상황을 방지하기 위한 한 가지 방법이 SQL Plan Management입니다. 이 기능을 이용하면 SQL 구문의 실행 계획에 최적화된 SQL 플랜 베이스라인을 생성할 수 있습니다. 하지만 이것도 범용적인 솔루션은 되지 못합니다. 이전에 실행되지 않은 SQL 구문은 SQL 플랜 베이스라인에 포함되지 않으며 따라서 SQL Plan Management의 관리 범위에 포함될 수 없기 때문입니다. 또 다른 문제로 성능 통계의 수집을 들 수 있습니다. 성능 통계 수집 작업은 매우 많은 CPU와 I/O를 요구하며, 작업량이 많지 않은 야간 시간대에 수행되는 것이 일반적입니다. 하지만 통계가 수집되는 즉시 실행 계획에 그 영향을 미칩니다. 관리자의 입장에서는 한밤 중에 실행 계획이 변경되는 것을 원하지 않을 수도 있습니다. 다시 말해, 통계는 수집하되 그 적용은 나중에 하는 것이 바람직할 수 있습니다. 이처럼 복잡한 목표도 Oracle Database 11g에서는 지원이 가능합니다. 특정 테이블 또는 인덱스의 통계를 "pending" 상태로 지정하면, 새로 수집된 통계는 배포되거나 옵티마이저에 의해 사용되지 않습니다. 따라서 새로운 통계를 배포하기 전에 통계를 테스트할 수 있는 여유를 가질 수 있습니다. 이 기능을 사용하려면 dbms_stats 패키지의 set_table_prefs 프로시저를 이용하여 테이블의 publish 속성을 FALSE로 설정해야 합니다. AURP 스키마의 SALGRADE 테이블에서 통계를 "unpublished" 상태로 지정하는 방법이 아래와 같습니다: begin "publish" 속성을 false로 지정하고 나면 수집된 통계는 "pending" 상태가 됩니다. 이 테이블의 통계를 조회한 결과가 아래와 같습니다: 오늘 날짜가 9/21/07이므로 이 통계는 한참 전에 수집된 것으로 보입니다. 다시 통계를 수집해 봅시다: begin 다시 통계를 조회해 보면: 로우의 숫자가 이전과 동일하고 last_analyzed에 여전히 이전의 값이 적용되어 있음을 확인할 수 있습니다. 그렇다면 지금 수집한 통계는 어떻게 된 것일까요 이 통계는 pending으로 마킹되었습니다. USER_TAB_PENDING_STATS를 통해 "pending" 상태를 확인할 수 있습니다: select num_rows, to_char(last_analyzed,'mm/dd/yy hh24:mi:ss') 실행 결과가 아래와 같습니다: 테이블의 9개 로우가 pending 상태로 표시되고 있습니다. 수집된 시간 역시 함께 표시됩니다. "pending" 상태의 통계를 옵티마이저로 전달하고자 하는 경우 아래와 같은 방법ublish_pending_stats('ARUP', 'SALGRADE'); 이제 user_tab_pending_stats 뷰를 조회하면 뷰에 아무런 데이터도 존재하지 않음을 확인할 수 있습니다. 또 USER_TABLES에는 가장 최근의 날짜가 반영되어 있습니다: 통계의 수집/배포 작업을 분리하는 이 방법은 파티셔닝된 테이블에도 적용할 수 있습니다. 파티션을 기준으로 테이블 파티션을 로드하는 경우를 가정해 봅시다. 파티셔닝된 환경에서는 옵티마이저에 각 파티션의 부분적인 정보만을 전달하는 대신, 전체 파티션의 통계를 동시에 옵티마이저에 전달하는 것이 바람직합니다. 하지만 동시에, 관리자는 파티션이 로드된 직후에 수집 작업을 수행하기를 원할 수 있습니다. 이런 경우라면 파티션이 로드된 직후에 통계를 수집하되 배포하지 않도록 설정할 수 있습니다. 그런 다음 모든 파티션의 분석을 마친 후 동시에 배포하면 됩니다. 배포 이전에 "Pending" 상태의 통계 점검하기 "pending" 상태의 통계는 배포 이전에 테스트가 가능하다는 매우 중요한 이점을 제공합니다. 옵티마이저에서 이미 배포된 통계 대신 pending 상태의 통계를 사용하도록 하려면 세션 매개변수 optimizer_use_pending_statistics를 true로 설정합니다. RES라는 이름의 테이블의 STATUS 컬럼에 인덱스가 적용되었다고 가정해 봅시다. SQL> create index in_res_status on res (status); cascade 옵션을 사용하여 테이블의 통계를 수집합니다. STATUS 컬럼의 값은 아래와 같은 분포를 갖습니다: "select res_type from res where status = 'VALID';"와 같은 쿼리를 실행한 뒤 실행 계획을 확인해 봅시다: 기대했던 대로 RES 테이블에 풀 테이블 스캔이 발생했습니다. 동일한 값을 가진 로우의 숫자가 매우 많기 때문입니다. 이번에는 데이터의 분포가 아래와 같이 변경되었다고 가정해 봅시다: "VALID" 값을 갖는 로우의 수가 1개로 줄었습니다. 이러한 경우라면 쿼리가 풀 테이블 스캔 대신 인덱스를 사용해야 합니다. 하지만 쿼리를 실행하고 실행 계획을 확인해 보면: 쿼리가 여전히 풀 테이블 스캔을 수행하고 있음을 확인할 수 있습니다. 이는 통계가 업데이트되지 않았기 때문에 발생한 문제입니다. 옵티마이저는 여전히 "VALID" 값을 갖는 로우의 수가 매우 많다고 생각하고 풀 테이블 스캔을 실행하는 것입니다. 통계를 다시 실행하면, 옵티마이저가 기존의 방식을 수정하여 인덱스를 사용하게 될 것입니다. 하지만 한 가지 중요한 문제가 있습니다. 그 결과로 다른 쿼리의 성능이 저하되지는 않을까요 그 결과를 이리저리 추측해 보는 대신 직접 확인해 보기로 합시다. dbms_stats 패키지의 set_table_prefs 프로시저를 사용하여 RES 테이블의 PUBLISH 속성을 false로 설정합니다. 그런 다음 이전과 같은 방법으로 통계를 수집합니다. 통계가 pending 상태로 설정되었으므로 옵티마이저는 새로운 통계를 사용하지 않을 것입니다. 하지만 옵티마이저에서 새로운 통계가 미칠 수 있는 영향을 테스트할 수는 있습니다. 옵티마이저를 위한 별도의 매개변수를 사용하여 "published" 상태의 통계 대신 "pending" 상태의 통계를 사용합니다. SQL> alter session set optimizer_use_pending_statistics = true; 이제 실행 계획을 점검해 봅시다: 새로운 통계가 적용되었음에도 불구하고 옵티마이저는 인덱스를 사용하고 있습니다. "pending" 상태의 통계는 성능 개선에 도움이 되었으면 되었지 악화시키지는 않는 것으로 보입니다. 같은 방법으로 "pending" 상태의 통계가 다른 쿼리에 미치는 영향을 분석할 수 있습니다. 더 나아가, SQL Plan Management에서 "pending" 통계를 활용한 SQL 플랜 베이스라인을 생성, 적용할 수도 있습니다. "pending" 상태의 통계를 삭제하고자 하는 경우 아래와 같이 실행할 수 있습니다: begin 위의 통계를 배포했는데 생각지 못한 문제가 발생했다고 가정해 봅시다. 뒤늦은 후회를 할 수도 있겠지만 걱정할 필요가 없습니다. 과거의 특정 시점으로 통계를 되돌릴 수 있습니다. Oracle Database 11g는 수집된 통계의 히스토리를 DBA_TAB_STATS_HISTORY 뷰에 기록합니다. 이 히스토리는 디폴트 설정에서 31일 간 유지됩니다. 위 쿼리는 지난 며칠 동안 수집된 통계를 보여 주고 있습니다. 마지막 수집된 통계에 문제가 있어 9월 14일에 수집된 통계로 되돌리고자 하는 경우를 가정해 봅시다. 위와 같이 실행하면 9월 14일 수집된 통계로 현재의 통계가 업데이트됩니다. Extended Statistics 고전적인 통계 수집 방식에서는 컬럼의 데이터 패턴을 수집, 저장하는 방법이 사용됩니다. 이번에는 조금 다른 경우를 생각해 봅시다. 컬럼 값에 대해 UPPER()와 같은 함수를 적용하면 어떨까요 CUST_NAME이라는 이름의 컬럼에 저장된 고객들의 이름이 일반적인 분포를 갖는다고 가정해 봅시다. 저장된 고객명의 샘플이 아래와 같습니다: McArthur 위 5가지는 모두 같은 이름이지만 대소문자 사용이 제각기 다릅니다. 오라클은 각각의 값을 유니크한 것으로 인식하며 따라서 이 컬럼의 카디널리티(cardinality)는 높습니다. 만약 쿼리에서 "like where upper(cust_name) = 'MCARTHUR'"와 같은 조건부를 사용하면 모든 값이 MCARTHUR라는 하나럼은 낮은 카디널리티를 갖게 됩니다. 테이블에 5개의 로우만이 존재한다면 각각의 값은 유니크하며 따라서 선택성(selectivity)은 1/5이 됩니다. 하지만 upper() 함수를 적용해서 컬럼을 같은 값으로 통일하면 선택성은 1로 변합니다. 선택성은 옵티마이저의 실행 계획에서 매우 중요한 고려 사항으로 작용합니다. 따라서 upper 함수는 옵티마이저의 실행 계획 선택에 분명한 영향을 미칠 것입니다. Oracle Database 11g는 컬럼이 아닌 표현식에 대해 확장형 통계(extended statistics)를 적용할 수 있는 기능이 새로 제공하고 있습니다. 그 예가 아래와 같습니다. 먼저 CUSTOMERS 테이블의 통계를 수집합니다. 다음으로 아래와 같은 쿼리를 고려해 봅시다: select * from customers where upper(cust_name) = 'MCARTHUR' 실행 계획이 아래와 같습니다: 쿼리에 의해 반환되는 로우 수의 추정치가 689로 계산되었습니다. 이제 실제로 반환되는 로우 수를 확인해 봅시다: 옵티마이저가 로우의 수를 너무 적게 계산한 것이 분명합니다. 29343과 686는 큰 차이를 보입니다. 테이블의 통계를 다시 수집하고 upper(cust_name) 표현식에 대해 확장형 통계를 수집합니다. 이것으로 CUSTOMER 테이블에 대한 확장형 통계가 생성되었습니다. 변경된 실행 계획이 아래와 같습니다: 이제 "Rows" 컬럼의 값(29570)이 실제 반환되는 로우 수에 매우 근접하였습니다. 옵티마이저는 이 숫자를 어떻게 얻은 것일까요 이 숫자는 UPPER(CUST_NAME) 표현식에 대해 수집된 확장형 통계로부터 얻어졌습니다. 위 출력 결과의 마지막 부분에 쿼리의 조건부에 대한 정보가 함께 기록되어 있음을 볼 수 있습니다. 여기에서 SYS_STUI2GNVTNUK3O8Y#$YT73GA0J 컬럼을 기준으로 한 필터를 확인할 수 있습니다. 이는 UPPER(CUST_NAME) 표현식에 대해 시스템이 생성한 이름입니다. 옵티마이저는 표현식에 대해 통계를 수집하였고, 그 결과로 반환되는 로우의 수를 정확하게 예측할 수 있었습니다. 이 기능이 왜 중요한 것일까요 옵티마이저에 의해 생성되는 실행 계획의 효율성은 로우의 숫자를 정확하게 판단하는 능력에 좌우됩니다. 따라서 확장형 통계가 효율성 개선에 큰 도움로 상관 관계를 갖는 컬럼들을 포함하는 임의의 테이블로 확장할 수 있습니다. 데이터 패턴이 상호 연관성을 갖는 예로 그린랜드와 아프리카 지역의 설상화 판매량을 비교하는 경우를 들 수 있습니다. 또 어떤 패턴들은 좀 더 사실에 기반하는 경우가 있습니다. 코네티컷은 독일이 아닌 미국에 위치하고 있습니다. 따라서 옵티마이저는 "country='Germany' and state='Connecticut'의 조건이 어떠한 값도 반환하지 않을 것임을 알고 그에 따라 대처할 수 있습니다. 어떤 표현식에 대해 통계가 수집되었는지 확인하려면 DBA_STAT_EXTENSIONS 뷰를 조회하면 됩니다. 표현식에 대한 확장형 통계를 드롭 처리하려면 drop_extended_stats 프로시저를 사용합니다. 멀티-컬럼 통계 BOOKINGS라는 이름의 테이블에 객실 예약 정보를 저장하고 있는 한 호텔 예약 업체의 데이터베이스를 예로 들어 보겠습니다. 이 테이블의 컬럼 중 두 가지가 우리의 관심을 끕니다. 바로 호텔의 식별자로 사용되는 HOTEL_ID와 숙박 요율 코드인 RATE_CATEGORY입니다. 이 두 가지 컬럼에는 인덱스가 적용되어 있습니다. 두 컬럼의 데이터 분포를 살펴 봅시다: 데이터를 주의 깊게 살펴 보시기 바랍니다. hotel_id 10은 rate_category 컬럼의 11, 12, 13 값에 대해서만 연계되어 있는 반면 hotel_id 20은 21, 22, 23에 대해서만 연계되어 있습니다. 이유가 무엇일까요 아마도 호텔의 등급과 관련이 있어 보입니다. Hotel 20은 높은 등급의 호텔이므로 11, 12, 13과 같은 낮은 rate_category가 적용되지 않고 있는 것입니다. 마찬가지로 21, 22, 23 등의 높은 rate_category는 상대적으로 저렴한 호텔 10에 적용되지 않습니다. 호텔 10은 호텔 20에 비해 더 많은 예약 건수를 가집니다. 그리고 "hotel_id = 20 and RATE_CATEGORY = 21"의 조건을 만족하는 로우의 수가 5106. 으로 가장 가장 적게 나타나고 있습니다. 그럼 아래와 같은 쿼리를 실행하면 어떻게 될까요 select min(booking_dt) 이 쿼리는 풀 테이블 스캔이 아닌 인덱스를 통해 처리되어야 합니다. autotrace를 이용하면 그 과정을 테스트할 수 있습니다: 어떻게 되었을까요 인덱스를 무시하고 풀 테이블 스캔이 수행되었습니다. "Rows" 항목의 값(16667)은 옵티마이저가 테이블에서 확인할 것으로 기대하는 로우의 수를 의미합니다. 물론 이것은 잘못된 것입니다. 실제로 반환되는 로우의 수는 5106개에 불과하며, 이를 잘못 판단한 옵티마이저가 풀 테이블 스캔을 수행하였습니다. 이처럼 예상되는 로우의 수가 높게 나타난 것은 옵티마이저가 HOTEL_ID, RATE_CATEGORY 컬럼의 상관 관계를 이해하지 못한 상태에서 두 컬럼을 각각 따로 분석하여 예상되는 로우 수를 산정하였기 때문입니다. 예측 과정에서 두 컬럼을 함께 고려하였다면 정확한 패였을 것입니다. 이 문제를 어떻게 해결할 수 있을까요 Oracle Database 11g의 확장형 통계의 한 유형으로 멀티-컬럼 통계(multi-column statistics)라는 새로운 통계가 포함되었습니다. 이 기능을 이용하면 서로 다른 컬럼(컬럼 그룹) 간의 상관 관계 정보를 생성하여 옵티마이저에 전달할 수 있습니다. 이 기능의 실제 사용 방법을 살펴 보기로 합시다. 멀티-컬럼 통계는 두 가지 방법으로 정의됩니다: 먼저 어떤 컬럼이 컬럼 그룹에 포함될 것인지 정의합니다. 위의 예에서는 HOTEL_ID와 RATE_CATEGORY가 컬럼 그룹에 포함됩니다. 이를 위해 dbms_stats 패키지에 새로 추가된 create_extended_stats 함수가 사용됩니다. 이 함수는 실행 결과로 컬럼 그룹의 이블에 대한 통계를 수집하면, 자동으로 컬럼 그룹에 대한 멀티-컬럼 통계가 수집됩니다 SQL> var ret varchar2(2000) 또는 gather statistics 커맨드의 일부로 컬럼 그룹을 정의할 수도 있습니다. dbms_stats 패키지의 gather_table_stats 프로시저에서 method_opt 매개변수에 위의 컬럼들을 포함시키면 됩니다: 멀티-컬럼 통계의 수집이 완료되었다면 쿼리를 다시 실행한 후 autotrace 결과를 확인합니다: IN_BOOKINGS_01 인덱스가 사용된 것을 분명하게 확인할 수 있습니다. 무엇이 변한 것일까요 "Rows" 컬럼의 값(5106)을 주목하시기 바랍니다. 옵티마이저가 두 컬럼의 조합을 통해 로우의 수를 정확하게 예측하고 있습니다. 옵티마이저가 올바른 결정을 수행하고 있는지 재차 확인하기 위해 "hotel_id = 10 and rate_category = 12" 조건으로 쿼리를 실행해 봅시다. 이 쿼리에는 풀 테이블 스캔이 사용되어야 합니다: 위에서 확인할 수 있듯, 옵티마이저는 로우의 수를 정확하게 예측하고 풀 테이블 스캔을 선택하였습니다. 이 방식은 존재하지 않는 조합("hotel_id=10 and rate_category=21")을 사용하는 쿼리의 효율성 개선에도 크게 도움이 됩니다. DBA_STAT_EXTENSIONS 뷰에서 데이터베이스에 정의된 확장형 통계를 확인할 수 있습니다: 멀티-컬럼 통계를 드롭 처리하려면 앞의 확장형 통계에서 설명된 것과 같은 방법을 사용하면 됩니다. 최근 들어 관리자들은 IT 시스템의 유지보수를 위한 다운타임 스케줄 수립에 많은 어려움을 겪고 있습니다. 하지만 패치 적용, 애플리케이션 오브젝트 관리에 수반되는 다운타임을 더 줄일 수 있는 길이 열렸습니다. Oracle Database 10g가 제공하는 fine-grained dependency tracking 기능을 이용하면 대부분의 변경 작업을 온라인에서 수행할 수 있습니다. 하지만 패치만큼은 데이터베이스를 셧다운 한 상태에서 적용해야 했습니다. Oracle Database 11g는 진정으로 혁명적이라 할 수 있는 신기능을 제공하고 있습니다. 데이터베이스를 오프라인 처리하지 않고도 Oracle Database 11g의 일부 패치(특히 진단을 목적으로 한 패치)를 온라인 상태에서 적용할 수 있게 된 것입니다. 이 패치를 적용하면 호스트의 메모리에 로드된 코드가 온라인 상태에서 수정됩니다. 조만간 Oracle Database 11g를 위한 새로운 패치가 여러 종류 배포될 것입니다. 이러한 패치들은, 관련된 기능을 실제로 사용하고 있는 사용자에게는 중요하지만, 그렇지 않은 사용자들은 적용할 필요가 없습니다. (불필요하게 패치를 적용하는데 수반되는 다운타임으로 인해 많은 비용이 지출될 수도 있습니다. 단, 보안 패치만큼은 실제 사용 중인 기능에 관계없이 무조건적으로 적용되어야 함을 참고하시기 바랍니다.) 그렇다면 현재 사용 중인 기능과 패치가 어떤 상관 관계를 갖는지 어떻게 확인할 수 있을까요 또 더 나아가, 이러한 패치들을 선택적으로 다운로드하고 편리한 시간에 적용할 수 있는 방법이 있을까요 Oracle Database 11g의 Features-Based Patching이 바로 이러한 기능을 제공합니다. Enterprise Manager Database Control에서 Features-Based Patching 기능을 사용하는 방법에 대해 알아 봅시다. 먼저 MetaLink 인증 정보 입력을 위해 홈 페이지의 우측 상단에 위치한 Setup 링크를 클릭하면 아래와 같은 화면이 표시됩니다: 왼쪽 창의 Patching Setup을 클릭합니다. 유저네임, 패스워드 등의 MetaLink 인증 정보를 입력합니다. 인증 정보가 셋업 되고 나면, 모든 패치가 패칭 세션 동안 자동으로 다운로드됩니다. 이제 오라클이 권장하는 필수 패치만을 적용하려면 어떻게 해야 할까요 Feature-Based Patching 기능이 빛을 발하는 이유가 바로 여기에 있습니다. Patch Advisor는 현재 사용 중인 기능에 대한 정보를 기반으로, 적용 가능한 패치 정보를 수집합니다. Software and Support 페이지에서 Patch Advisor 링크를 클릭합니다. "All"로 표시된 드롭다운 리스트를 주목하시기 바랍니다. 현재 사용 중인 기능에 관련된 패치만을 확인하고자 한다면, 드롭다운 리스트에서 Feature-Based Patches를 선택하고 Go를 누릅니다. 이제 관련된 패치가 확인되는 경우 목록에 표시됩니다. Patch Prerequisites를 눌러 패치를 어디에 다운로드하고 적용할 것인지 설정합니다. Add 버튼을 눌러 패치를 추가하면 아래와 같은 화면이 표시됩니다: 이 화면에서 사용 가능한 패치를 MetaLink에서 검색할 수 있습니다. 패치는 자동으로 다운로드 되어 Patch Cache에 저장됩니다. 필요한 경우 Patch Cache의 캐시를 수동으로 재적용할 수도 있습니다. Feature-Based Patching은 EM이 MetaLink에 연결되지 않은 상태에서도 사용할 수 있습니다. MetaLink에서 XML 메타데이터를 다운로드한 다음 위의 Patching Setup 스크린에서 적용하면 됩니다. 여기서 Offline Patching Setting 탭 대신에 MetaLink & Patching Setting 탭을 선택하도록 합니다.관리성 관련 기능
관리성 (Manageability)
메모리 관리




sga_target = 2G
pga_aggregate_target = 1G


Adaptive Thresholds


Pending Statistics
dbms_stats.set_table_prefs (
ownname => 'ARUP',
tabname => 'SALGRADE',
pname => 'PUBLISH',
pvalue => 'FALSE'
);
end;
dbms_stats.gather_table_stats (
ownname => 'ARUP',
tabname => 'SALGRADE',
estimate_percent=> 100
);
end;
/
from user_tab_pending_stats
where table_name = 'SALGRADE';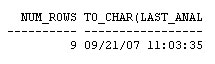
end;
/





dbms_stats.delete_pending_stats('ARUP','RES');
end;

함수 기반 통계
MCArthur
mcArthur
MCARTHUR
mcarthur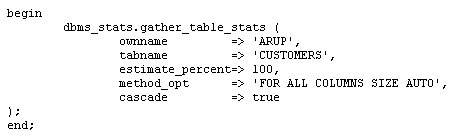

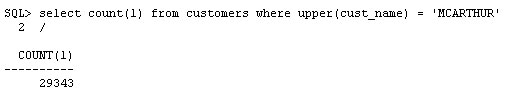


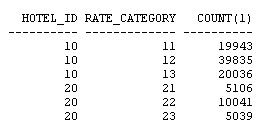
from bookings
where hotel_id = 20
and rate_category = 21;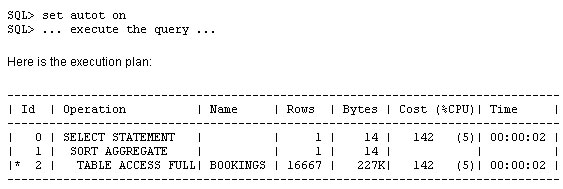
SQL> exec :ret := dbms_stats.create_extended_stats('ARUP', 'BOOKINGS','(HOTEL_ID, RATE_CATEGORY)');
SQL> print ret


온라인 패칭
Features-Based Patching



