
DBMS 1
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
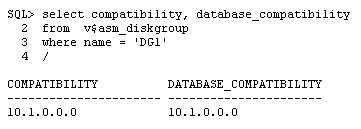
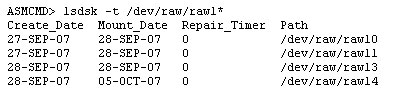
새로운 SYSASM 역할을 이용한 ASM 인스턴스의 관리, 가변 익스텐트 크기를 이용한 공유 풀 사용량의 절감, 디스크그룹의 특정 디스크에 대한 읽기 설정 등 Oracle Database 11g ASM에 추가된 혁신적인 신기능을 소개합니다. Automatic Storage Management(ASM)가 Oracle Database 10g에서 처음 소개되었을 때, 스토리지 할당 업무를 DBA와 시스템 운영자 중 어느 쪽에서 담당해야 하는지의 문제를 놓고 다소 혼선을 초래하기도 했습니다. ASM 인스턴스는 (SYSDBA 역할로 연결되는 다른 DBA 작업들과 마찬가지로) DBA에 의해 관리됩니다. 하지만 시간이 흐르고 IT 조직의 역할 분담이 보다 명확해지기 시작하면서 ASM 운영 업무 중 일부는 시스템 운영자에게 이관되는 경향이 나타나고 있습니다. 또 어떤 기업에서는 "ASM 운영자"라는 별도의 직군이 ASM 운영을 전담하는 경우도 볼 수 있습니다. 하지만 이러한 새로운 역할의 등장으로 인해 충돌이 발생하기도 합니다. ASM 인스턴스의 관리를 위해서는 SYSDBA 역할이 필요합니다. 하지만 운영 데이터베이스의 관리를 책임지는 DBA들 상당수가 이 역할을 다른 운영자와 공유하는 것을 탐탁지 않게 생각하고 있습니다. Oracle Database 11g에서는 이러한 문제가 완전히 해결되었습니다. ASM 인스턴스의 관리를 전담하는 SYSASM이라는 새로운 역할(role)이 구현된 것입니다. SYSASM은 ASM 인스턴스에 대한 SYSDBA 역할로 유추하여 이해할 수 있습니다. ASM 인스턴스에 연결하는 방법이 아래와 같습니다: $ sqlplus / as sysasmSQL*Plus: Release 11.1.0.6.0 - Production on Fri Sep 28 20:37:39 2007Copyright (c) 1982, 2007, Oracle. All rights reserved.Connected to: "as sysasm" 구문을 주목하시기 바랍니다. Oracle Database 11g Release 1에서 SYSASM 역할은 SYSDBA 역할을 가진 운영 체제 그룹(이들의 대부분은 "dba"일 것입니다)에 할당됩니다. 다시 말해, Unix 운영 체제에서 dba 그룹에 포함된 사용자라면 SYSASM으로 연결하는 것이 가능합니다. (이러한 설정은 향후 버전에서는 변경되어 sysdba, sysasm 역할이 별도의 OS 그룹으로 구분될 것입니다.) 일단 ASM 인스턴스에 연결된 후에는 SYS 사용자의 패스워드를 업데이트할 수 있습니다. SQL> alter user sys identified by oracle 역할 할당이 완료되면, 사용자는 SYS를 대신해서 모든 ASM 관리 기능을 실행할 수 있습니다. 사용자는 "as sysasm" 구문을 사용하여 ASM 인스턴스에 접속합니다. $ sqlplus asmoper/dumboper as sysasm 이처럼 SYSASM 역할을 이용하여 ASM과 DBA의 업무를 보다 명확하게 구분하는 것이 가능합니다. ASM 스토리지의 가장 작은 구성 단위는 할당 유닛(AU, allocation unit)입니다. AU는 개념적으로 오라클 데이터베이스 블록과 유사합니다. 테이블, 인덱스와 같은 데이터베이스 세그먼트를 생성하면, 블록이 아닌 익스텐트 단위로 공간이 할당됩니다. 여기서 익스텐트는 여러 개의 블록으로 구성됩니다. 관리자는 세그먼트의 익스텐트 크기를 변경할 수 있습니다. ASM에서도 이와 매우 유사한 개념이 적용됩니다. ASM 디스크 그룹에 파일이 생성될 때, 공간은 AU가 아닌 익스텐트 단위로 할당됩니다. Oracle Database 10g에서는 AU와 익스텐트가 같은 개념처럼 사용되었으며, 하나의 익스텐트에 하나의 AU만이 할당되었습니다. 10g와 호환하는 디스크그룹은 모든 익스텐트에 대해 공유 풀의 메모리를 요구합니다. 따라서 데이터베이스의 용량이 큰 경우라면 매우 많은 양의 메모리가 필요하게 됩니다. AU의 사이즈가 1MB(디폴트)라면, 1TB 데이터베이스는 공유 풀에서 100만 개 이상의 익스텐트를 관리해야 합니다. Oracle Database 11g에서는 익스텐트의 크기와 AU의 크기를 갖게 해야 한다는 요구 조건이 없어졌습니다. 파일 생성 시 익스텐트의 크기는 1MB부터 시작합니다. 파일의 크기가 일정한 임계치에 도달하면 익스텐트 사이즈는 4MB, 16MB, 그리고 마지막으로 64MB로 증가합니다. 관리자는 사이즈 설정 문제를 고민할 필요가 없습니다. ASM 인스턴스가 자동으로 적절한 익스텐트 크기를 결정하기 때문입니다. 보다 적은 수의 익스텐트로 많은 양의 데이터를 저장할 수 있게 되면서, 공유 풀에서 관리되는 익스텐트의 수가 줄어들고 따라서 성능을 몇 배로 개선하는 것이 가능해졌습니다. 하지만 가변 익스텐트 크기 설정으로 인해 파일의 용량이 급격하게 증가/감소하는 상황에서 조각(fragmentation) 현상이 발생할 수 있습니다. ASM은 필요한 경우 조각 모음을 자동으로 수행합니다. AU 사이즈의 설정 앞에서 설명한 것처럼 AU의 디폴트 사이즈는 1MB입니다. 대부분의 경우 이 크기는 적절합니다. 하지만 용량이 10TB가 넘는 대용량 데이터베이스를 생각해 봅시다. 오브젝트들은 1MB보다 큰 사이즈로 설정되었을 가능성이 높으며, 따라서 AU 사이즈를 증가시킴으로써 AU의 수를 줄이는 것이 바람직할 것입니다. Oracle Database 10g에서는 AU 크기를 변경하기 위해 underscore 매개변수를 설정해야 했습니다. 하지만 이 매개변수는 이후 생성되는 모든 디스크그룹에 영향을 미치며, 매개변수 설정 후 ASM 인스턴스를 재시작해야 하는 번거로움이 있습니다. Oracle Database 11g에서는 DG 생성 과정에서 디스크그룹 속성인 au_size를 설정함으로써 간단하게 작업을 완료할 수 있습니다. create diskgroup dg6 AU_SIZE는 1M, 2M, 4M, 8M, 16M, 32M, 64M 중 하나이어야 합니다(여기서 M은 MB를 의미합니다). 또는 바이트 단위로 절대값을 설정할 수도 있습니다: attribute 'au_size' = ' 2097152' 디스크그룹이 생성된 후에는 아래 쿼리를 통해 AU 사이즈를 점검합니다: 위에서 디스크 그룹별로 AU 사이즈가 다르게 설정되어 있는 것을 주목하시기 바랍니다. 이제 디스크 그룹을 생성하면서 각 애플리케이션별로 적절한 AU 사이즈를 설정할 수 있습니다. ASM은 10g 버전 이후부터 오라클 데이터베이스에 사용되는 스토리지 플랫폼입니다. 11g 기반 ASM 인스턴스는 10g Release 1, 10g Release 2, 11g Release 1 및 이후 버전의 데이터베이스를 지원합니다. 다시 말해, ASM 버전이 데이터베이스 버전과 같거나 더 크다면, 해당 ASM 버전에서 데이터베이스를 생성하는 것이 가능합니다. 그렇다면 서로 다른 버전의 ASM과 RDBMS 인스턴스는 어떻게 커뮤니케이션하는 것일 까요 간단합니다. ASM은 RDBMS 버전에 맞도록 메시지를 변환해 줍니다. 디폴트 설정에서 ASM 인스턴스는 10g 데이터베이스를 기본적으로 지원합니다. 하지만 ASM 인스턴스에서 11g RDBMS만을 지원하고자 하는 경우에는 어떻게 해야 할까요 이러한 경우라면 버전 호환성을 위해 메시지를 변환할 필요가 없습니다. 따라서 ASM 인스턴스에 11g Release 1 버전의 데이터베이스만이 사용된다는 사실을 알려 줄 수 있다면 메시지 변환 작업으로 인한 오버헤드를 제거할 수 있을 것입니다. Oracle Database 11g는 이를 위해 ASM Compatibility, RDBMS Compatibility 디스크 그룹 속성을 지원합니다. 먼저 디스크그룹에 현재 설정된 속성을 점검해 봅시다: 위에서 볼 수 있듯, ASM Compatibility(위 출력 결과의 COMPATIBILITY 컬럼)는 10.1.0.0.0으로 설정되어 있습니다. 이는 디스크 그룹이 10.1 버전의 ASM 구조까지 지원할 수 있음을 의미합니다. 또 RDBMS Compatibility(위의 DATABASE_COMPATIBILITY 컬럼)는 10.1로 설정되어 있습니다. 이는 ASM 디스크그룹 DG1은 10.1 버전 이후의 모든 RDBMS를 지원함을 의미합니다. 11g 버전의 ASM, RDBMS만을 사용하려는 경우라면 10g 버전을 지원하도록 설정할 필요가 없을 것입니다. 디스크그룹의 ASM Compatibility 속성을 11.1로 설정하는 방법이 아래와 같습니다: SQL> alter diskgroup dg1 set attribute 'compatible.asm'='11.1'; 이제 디스크 그룹의 속성을 다시 확인해 봅시다: ASM Compatibility는 11.1로 설정되어 있지만 RDBMS Compatibility는 여전히 10.1로 설정되어 있습니다. 이 값을 11.1로 바꾸어 주는 방법은 아래와 같습니다: SQL> alter diskgroup dg1 set attribute 'compatible.rdbms'='11.1'; 여기서 한 가지 중요한 사실을 참고하시기 바랍니다. 호환성은 전체 ASM 인스턴스가 아닌 개별 디스크그룹 단위로 설정됩니다. 디스크 그룹이 사용하는 버전에 따라 속성을 적절하게 설정하고 버전 간의 호환성 보장에 수반되는 오버헤드를 절감할 수 있습니다. Preferred Mirror Read Oracle RAC 데이터베이스 환경에서는 하나의 ASM 인스턴스를 여러 개의 노드가 공유합니다. ASM 디스크 그룹에 일반적인 방식의 미러링을 적용하는 경우, 디스크 접근 방식이 사용자가 기대하는 바와는 다를 수 있습니다. 각각 다른 디스크로 구성된 두 개의 페일그룹(failgroup, DG2_0000과 DG2_0001)을 갖는 DG3 디스크그룹이 아래와 같이 구성되었다고 가정해 봅시다: 디스크그룹 DG2에 데이터가 기록되는 경우, 익스텐트는 라운드 로빈 방식으로 씌어집니다. 다시 말해, 첫 번째 익스텐트의 경우 원본은 DG2_0000에, 사본은 DG2_0001에 기록되며, 두 번째 익스텐트는 원본은 DG2_2001에, 사본은 DG2_2000에 기록됩니다. ASM은 이러한 방식으로 미러링을 관리합니다. 하지만 익스텐트를 읽어 오는 경우에는 언제나 2차 페일그룹(DG2_0001)이 아닌 1차 페일그룹(DG2_000)으로부터 읽기가 발생합니다. 2차 페일그룹은 1차 페일그룹의 접근이 불가한 경우에만 읽기가 수행됩니다. 이러한 방식은 대부분의 경우에 정상적으로 동작하지만 경우에 따라서는 바람직하지 못한 결과를 낳을 수도 있습니다. Oracle Database 11g에는 특정 페일그룹으로부터 데이터를 읽어 오도록 노드를 설정할 수 있는 기능이 추가되었습니다. 예를 들어, 디스크 그룹에 대한 preferred read group 설정을 통해 인스턴스 1은 페일그룹 DG2_0000으로부터, 그리고 인스턴스 2는 DG2_0001로부터 읽어 오도록 설정할 수 있습니다. 인스턴스 1에서 아래 명령을 실행하면, 인스턴스 1에서 DG2와 DG3의 DG2_0000, DG3_0000 페일그룹에 대한 preferred read가 설정됩니다. SQL> alter system set asm_preferred_read_failure_groups = 'DG2.DG2_0000','DG3.DG3_0000' 마찬가지로, 다른 인스턴스에서 아래와 같이 페일그룹에 대한 preferred read group 설정을 할 수 있습니다. SQL> alter system set asm_preferred_read_failure_groups = 'DG2.DG2_0001','DG3.DG3_0001' 위 명령을 실행하고 나면, 인스턴스 1은 DG2 디스크그룹에 대한 읽기를 수행할 때 디스크 DG2_0000으로부터 데이터를 가져 옵니다. DG2_0000이 접근 불가한 경우에만 DG2_0001에 대한 읽기가 수행됩니다. 마찬가지로 인스턴스 2에 연결된 세션은 DG2_0001로부터 데이터를 읽어 옵니다. 디스크그룹에 대한 읽기 설정이 어떻게 되어 있는지 확인하려면, 새로 추가된 딕셔너리 뷰 V$ASM_DISK_IOSTAT를 참고하면 됩니다. 이 뷰는 UNIX 시스템의 IOSTAT 유틸리티와 유사한 방식으로 동작합니다. 조회 결과의 예가 아래와 같습니다: 위 출력 결과에서 인스턴스 PRONE31, PRONE32의 preferred failgroup이 각각 DG2_0000, DG2_0001로 설정되어 있음을 확인할 수 있습니다. WRITES 컬럼의 값은 910으로 동일합니다.이는 쓰기 작업의 경우 양쪽 디스크에서 동일한 방식으로 수행됨을 의미합니다. 이제 READS 컬럼을 주목하시기 바랍니다. PRONE31, PRONE32 인스턴스에 대해 각각 4450, 2256으로 설정되었음을 확인할 수 있습니다. 왜 이렇게 되어 있는 것일까요 PRONE31 인스턴스는 preferred failgroup인 DG2_0000으로부터 더 많은 읽기 작업을 수행하였습니다. DG3 디스크 그룹의 경우, PRONE32 인스턴스는 preferred failgroup인 DG3_0001로부터 더 많은 읽기 작업을 수행했습니다. Preferred Read는 "스트레치(stretch)" 클러스터, 다시 말해 노드 간의 거리가 매우 먼 클러스터 환경에서 특히 유용합니다. 이 설정을 이용하여 읽기 작업을 특정 특정 디스크로 한정함으로써 성능을 개선할 수 있습니다. 디스크가 더 이상 존재하지 않는 경우, 다시 말해 디스크가 복구 불가능한 수준으로 손상되었을 때에는 어떻게 해야 할까요 이 디스크그룹을 영구적으로 드롭 처리하고 디스크그룹을 재생성하거나 다른 디스크그룹의 디스크를 추가해야 할 것입니다. 하지만 드롭 처리 해야 하는 디스크그룹은 현재 마운트되지 않은 상태입니다. 디스크 중 하나가 누락된 상태이기 때문에 마운트 작업 자체가 불가능합니다. 디스크그룹을 드롭 처리하려면 마운트가 필요하지만 디스크가 손상되었기 때문에 마운트가 불가능한, 이도저도 못하는 상태가 된 것입니다. 이런 경우에는 어떻게 해야 할까요 Oracle Database 10g에서는 dd 커맨드를 이용하여 디스크의 헤더를 삭제하는 우회적 해결책이 사용되었습니다. $ dd if=/dev/zero of=/dev/raw/raw13 bs=1024 count=4 위 명령을 실행하면 /dev/raw/raw13 디스크의 헤더에 "0"의 값이 입력되고 모든 정보가 삭제됩니다. 이 방법은 효과적이긴 하지만 디스크 헤더의 정보를 완전히 삭제한다는 문제가 뒤따릅니다. Oracle Database 11g에서는 더 간단한 해결책을 사용할 수 있습니다. drop 명령을 실행하면서 force 옵션을 사용하면 됩니다. SQL> drop diskgroup dg7 force including contents; 이제 디스크가 마운트되지 않은 상태에서도 디스크그룹이 드롭 처리됩니다. 사용 가능한 디스크는 "FORMER"로 표시됩니다(이는 디스크가 다른 디스크그룹에 포함되어 있었음을 의미합니다.) (참고: "including contents" 구문은 반드시 사용해야 합니다.) 많은 이들이 ASM을 별도의 스토리지를 가진 하나의 데이터베이스로 이해하고 있습니다. 하지만 이것은 전혀 사실이 아닙니다. 데이터는 ASM이 아닌 데이터베이스에 저장됩니다. 하지만 ASM 인스턴스에는 디스크그룹, 디스크, 디렉토리 등에 관련한 메타데이터 정보가 저장되어 있습니다. 이 메타데이터는 디스크 헤더에 저장됩니다. 모든 디스크에 동시다발적으로 장애가 발생하여 헤더 정보가 손상되었다고 가정해 봅시다. 이런 경우에는 어떻게 해야 할까요 물론 RMAN을 사용하여 데이터베이스 백업본을 복구하면 됩니다. 하지만 복구 작업을 수행하기 전에 반드시 모든 디스크그룹과 디렉토리가 생성되어 있어야 합니다. 이 기록을 따로 관리해 왔다면 불가능한 일은 아니지만, 어쨌든 시간이 많이 걸리는 일은 분명합니다. 이 메타데이터를 따로 백업해 둔다면 편리하지 않을까요 Oracle Database 11g에서는 ASM 커맨드라인 옵션(ASMCMD)의 md_backup 명령을 사용하여 ASM 인스턴스의 메타데이터를 백업하는 기능이 추가되었습니다. $ asmcmd -pASMCMD [+] > md_backup 위 명령을 실행하면 ambr_backup_intermediate_file이라는 이름의 파일이 생성됩니다. 이 파일의 내용 중 가장 윗부분을 조회한 결과가 아래와 같습니다: 위에서 볼 수 있듯 모든 디스크그룹, 디스크, 디렉토리, 디스크 속성에 대한 정보가 기록되어 있습니다. 디폴트 환경에서 이 파일은 모든 디스크그룹의 기록을 저장하고 있습니다. 특정 디스크그룹의 메타데이터만을 백업하고 싶다면 -g 옵션을 사용하면 됩니다. 또 -b 옵션을 사용하여 백업 파일의 이름을 지정할 수도 있습니다. ASMCMD [+] > md_backup -g dg1 -b prolin3_asm.backup 위 명령은 디스크그룹 DG1의 메타데이터를 prolin3_asm.backup 파일에 백업하도록 지시하고 있습니다. 단 같은 이름의 파일이 존재하지 않아야 하며, 존재하는 경우 먼저 기존 파일을 삭제해야 합니다. 이제 복구 방법에 대해 살펴 보겠습니다. 복구 방법에는 여러 가지가 있습니다. 가장 쉬운 방법은 앞에서 드롭 처리된 디렉토리들과 함께 디스크그룹을 복구하는 것입니다. 먼저 디스크그룹에 디렉토리를 생성합니다: ASMCMD [+] > cd DG7 이 디스크그룹에는 TEST라는 디렉토리가 포함되어 있습니다. 이제 디스크그룹을 백업합니다: ASMCMD [+] > md_backup -g dg7 -b g7.backup 백업이 완료된 후 실수로 디스크그룹을 드롭 처리했다고 가정해 봅시다. SQL> drop diskgroup dg7; Diskgroup dropped. 이제 디스크그룹 DG7이 ASM 인스턴스에서 삭제되었으므로 이전 백업본으로부터 다시 복구해야 합니다. 복구를 위해 md_restore 명령을 사용합니다: $ asmcmd md_restore -b dg7.backup -t fullCurrent Diskgroup being restored: DG7 실행 결과를 주목하시기 바랍니다. 디스크그룹뿐 아니라 템플릿과 디렉토리가 함께 생성되었습니다. 물론 기존에 저장된 데이터는 모두 삭제된 상태입니다. md_backup은 데이터가 아닌 ASM 인스턴스의 메타데이터만 RMAN을 이용한 복구 작업을 수행할 수 있습니다. 또 다른 옵션인 -f를 사용하면 커맨드를 스크립트 파일 내에 저장할 수 있습니다. ASMCMD [+] > md_restore -b dg7.backup -t full -f cr_dg7.sql 위 명령은 디스크그룹 및 관련 오브젝트의 생성을 위한 cr_dg7.sql 스크립트를 생성합니다. 생성된 스크립트는 ASM 인스턴스 내에서 수동으로 실행할 수 있습니다. 스크립트의 내용이 아래와 같습니다: create diskgroup DG7 EXTERNAL redundancy disk '/dev/raw/raw14' name DG7_0000 size 100M ; 이 기능은 ASM 인스턴스의 메타데이터를 문서화하고자 하는 경우에도 유용하게 활용됩니다. 정기적으로 메타데이터의 백업을 수행하거나 또는 디스크그룹 추가, 디스크 추가/제거, 디렉토리 추가 등의 중요한 변경 사항이 발생되었을 때 메타데이터를 백업할 수 있습니다. 기존 볼륨 관리자의 기능에 익숙한 ASM 사용자들이 가장 많이 불평하는 것 중 하나로, 커맨드 라인을 이용한 점검 기능이 부족하다는 점을 들 수 있습니다. ASM 커맨드 라인 옵션(ASMCMD)은 이러한 측면에서 많은 기능적 보완을 이루었습니다. Oracle Database 11g에 추가된 ASMCMD 명령을 이용하면 ASM 인스턴스를 매우 쉽게 관리할 수 있습니다. 그 한 가지 예가 앞에서 소개 드린 메타데이터 백업 기능입니다. 또 주목할 만한 명령으로 인스턴스에 의해 관리되는 디스크에 대한 점검을 위한 lsdsk 커맨드가 있습니다. . ASMCMD> lsdsk 플래그가 전혀 설정되지 않은 상태에서, 이 커맨드는 인스턴스에서 사용 가능한 모든 디스크의 목록을 출력합니다. 출력 결과를 수정하기 위한 플래그에는 여러 가지가 있으며, 그 중 가장 많이 활용되는 것이 -k 옵션입니다: -s 플래그는 디스크의 I/O 관련 통계를 표시해 줍니다: 디스크의 상태를 빠르게 확인하고자 하는 경우에는 -p 플래그를 사용합니다: 마지막으로 -t 플래그는 repair 작업 관련 정보를 표시합니다(뒷부분에서 자세하게 설명합니다): 지금까지 소개한 ASMCMD 옵션은 ASM 인스턴스의 여러 가지 V$ 뷰에서 값을 추출하는 방법을 사용합니다. 하지만 메타데이터의 경우에는 디스크에 저장되어 있습니다. 따라서 인스턴스에 접근이 불가하다면 디스크로부터 이 정보를 추출해 낼 수 있는 방법이 없습니다. Oracle Database 11g의 lsdsk 커맨드에 추가된 "I" 플래그(소문자 "L"이 아닌 대문자 "I"입니다)는 V$ 뷰가 아닌 디스크 헤더로부터 정보를 추출합니다. -k 플래그를 이용한 명령에서 디스크 헤더의 정보를 추출하는 방법이 아래와 같습니다. 특정 디스크 그룹(예: DG1)의 디스크 목록을 확인하려면 아래와 같이 -d 플래그를 사용합니다: 와일드카드 문자를 사용할 수도 있습니다: 위에서는 와일드카드 문자에 의한 패턴과 매치되는 디스크만이 표시되고 있습니다. 이 옵션들을 모두 외우고 있을 필요는 없습니다. help 명령을 사용하면 사용 가능한 옵션을 확인할 수 있습니다. 이처럼 lsdsk 커맨드를 이용하면 ASM 환경을 한층 효과적으로 관리할 수 있습니다. Restricted Mount 디스크그룹에 디스크를 하나싱 작업을 즉각적으로 시작합니다. 이 작업은 온라인에서 수행되며 따라서 ASM은 매우 복잡한 락킹 시스템을 이용하여 RDBMS 인스턴스에서 접근, 변경되는 블록을 통제해야 합니다. RAC 데이터베이스에서는 락을 하나의 데이터베이스가 아닌 여러 개의 인스턴스에 대해 관리해야 하므로 한층 문제가 복잡해집니다. 그렇다면 아무도 사용하고 있지 않은 디스크그룹에 디스크를 추가하는 경우는 어떨까요 ASM이 이 사실을 미리 알 수만 있다면, 복잡한 락킹 메커니즘을 사용하지 않고 작업을 신속하게 완료할 수 있을 것입니다. Oracle Database 11g는 디스크그룹 마운트 작업을 위한 새로운 옵션을 제공합니다. 디스크그룹은 아래와 같이 RESTRICT 옵션을 사용하여 마운트될 수 있습니다: alter diskgroup dg7 mount restricted; 디스크그룹이 이런 방법으로 마운트 된 경우, ASM 인스턴스는 디스크에 대한 다른 접근이 제한됨을 인지하고 락킹 메커니즘을 최소화합니다. 그 결과로 리밸런싱과 같은 디스크 작업이 한층 빠르게 수행될 수 있습니다. 신속한 장애 복구 디스크그룹 DG2에 각각 하나의 디스크를 포함하는 두 개의 페일그룹이 포함되어 있다고 가정해 봅시다. 디스크 중 하나의 특정 영역이 손상되더라도 디스크그룹에는 심각한 영향을 미치지 않습니다. 미러링 구성이므로 손상된 익스텐트에 해당되는 영역은 다른 디스크로부터 읽어올 수 있기 때문입니다. 그렇다면 손상된 디스크 영역은 어떻게 처리될까요 Oracle Database 10g에서는 손상된 디스크가 오프라인 처리되고 다른 디스크가 디스크그룹의 읽기/쓰기 작업에 사용됩니다. 새로운 디스크가 추가되면, 추가된 디스크에 다른 디스크의 데이터가 완전하게 복제되어야 합니다. 하지만 손상된 블록의 수는 얼마 되지 않는데 수십 기가바이트의 디스크 컨텐트를 복사하는 것은 효율적이지 못합니다. Oracle Database 11g에서는 전체 디스크를 복사하는 대신 디스크의 손상된 부분만을 복구하는 작업이 수행됩니다. 여기서 새로운 디스크그룹 속성인 disk_repair_time을 사용하여 ASM 인스턴스가 디스크 그룹에서 디스크를 드롭 처리하기 전에 얼마만큼의 에러를 허용하는지 결정하게 됩니다. 디스크그룹 DG2의 disk_repair_time 속성을 2시간으로 설정하는 방법이 아래와 같습니다: SQL> alter diskgroup dg2 set attribute 'disk_repair_time'='2H'; DG2에 DISK1, DISK2의 2개 디스크가 포함되어 있고, DISK2의 블록 중 몇 개가 갑자기 손상되었다고 가정해 봅시다. 복구 시간이 2시간으로 설정되었므로, ASM 인스턴스는 디스크를 즉각적으로 드롭 처리하지 않고 일단 대기합니다. DISK2의 문제를 해결하고 다시 온라인 처리하면, 손상된 블록은 정상 상태의 디스크로부터 복구됩니다. 예를 들어 설명해 보겠습니다. DG2에 2개의 페일그룹이 포함되어 있다고 가정해 봅시다. 먼저 디스크그룹 구성을 확인합니다: ASMCMD [+dg2] > lsdg dg2 du 커맨드를 이용하여 정보를 확인할 수도 있습니다: du 커맨드는 디스크그룹의 용량이 22MB이지만 그 중 11MB만이 사용 가능하다고 확인하고 있습니다. 이제 그룹 dg2의 디스크를 확인해 봅시다: 아래와 같은 쿼리를 이용하면 같은 내용에 더하여 디스크 네임까지 확인할 수 있습니다: 이처럼 디스크그룹에 포함된 2개의 디스크와 그 이름을 확인할 수 있습니다. 이제 블록 손상의 시뮬레이션을 위해 디바이스 중간에 몇 개의 문자를 넣습니다: $ dd if=/dev/zero of=/dev/raw/raw7 bs=1024 skip=10 count=1 이것으로 디스크그룹 중 하나의 디스크가 손상되었습니다. 이제 ALTER DISKGROUP ... CHECK 커맨드를 사용하여 강제로 디스크그룹 검사를 수행합니다. SQL> alter diskgroup dg2 check ASM 인스턴스의 경고 로그에서 아래와 같은 내용을 확인할 수 있을 것입니다: ... 마지막 라인에서 모든 상황을 파악할 수 있습니다. 손상된 디스크는 7200초 후에 디스크그룹으로부터 드롭 처리됩니다. 이는 앞에서 설정한 2시간의 repair timer와 일치합니다. 이 메시지는 시간이 경과함에 따라 반복적으로 경고 로그에 나타납니다: ... 디스크에 발생한 문제를 해결하고 fast failure repair 작업을 실행하지 못한 상태에서 카운트다운이 0에 도달하면 디스크는 드롭 처리됩니다. 디스크가 복구 불가능하다고 판단하여 조속히 드롭 처리하고자 하는 경우에는 아diskgroup dg2 offline disks in failgroup dg2_0000 drop after 1m 이 명령은 1분 후에 페일그룹 dg2_0000을 드롭 처리하여, 물리적으로 디스크를 제거하거나 디스크그룹 내의 다른 디스크를 이동할 수 있게 합니다. 디스크를 강제로 드롭 처리하는 명령은 아래와 같습니다: SQL> alter diskgroup dg2 drop disks in failgroup dg2_0001 force; 디스크 장애가 해결되면, 아래 명령으로 fast repair 작업을 시작할 수 있습니다: SQL> alter diskgroup dg2 online disks in failgroup dg2_0001; 위 명령을 실행하면 페일그룹 DG2_0001의 다른 디스크들에 의해 손상, 변경된 블록의 동기화가 시작됩니다. 이 과정에서 전체 디스크가 아닌 몇 개의 블록만이 복제되므로, 작은 규모의 손상이 발생한 후의 동기화에 소요되는 시간을 극적으로 절감할 수 있습니다. Oracle Database 11g ASM은 한층 강력하고, 탄력적이고, 편리한 운영 환경을 제공합니다. 디스크그룹에 대한 읽기 작업이 RAC 데이터베이스의 전체 노드에 의해 수행됨을 보장하고, 디스크 드롭 작업을 보다 쉽게 처리하고, 장애를 신속하게 복구하고, 공유 풀에 할당되는 익스텐트의 수를 줄임으로써 대용량 스토리지를 효율적으로 관리할 수 있습니다.ASM 개선 사항
Automatic Storage Management
SYSASM 역할
Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining
and Real Application Testing optionsSQL>
2 /User altered.ASM 인스턴스에는 데이터베이스가 포함되어 있지 않지만 사용자를 생성하는 것은 가능합니다.SQL> create user asmoper identified by dumboper
2 /User created.이제 사용자에게 SYSASM 역할을 할당합니다:SQL> grant sysasm to asmoper;Grant succeeded.가변 익스텐트 크기
external redundancy
disk
'/dev/raw/raw13'
attribute 'au_size' = '2M'
디스크그룹 속성




Drop Diskgroup Force
메타데이터의 백업 및 복구

ASMCMD [+DG7] > mkdir TEST
ASMCMD [+DG7] > ls
TEST/
Diskgroup DG7 created!
System template TEMPFILE modified!
System template FLASHBACK modified!
System template ARCHIVELOG modified!
System template BACKUPSET modified!
System template XTRANSPORT modified!
System template DATAGUARDCONFIG modified!
System template CONTROLFILE modified!
System template AUTOBACKUP modified!
System template DUMPSET modified!
System template ONLINELOG modified!
System template PARAMETERFILE modified!
System template ASM_STALE modified!
System template CHANGETRACKING modified!
System template DATAFILE modified!
Directory +DG7/TEST re-created!
alter diskgroup /*ASMCMD AMBR*/DG7 alter template TEMPFILE attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template FLASHBACK attributes (UNPROTECTED FINE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template ARCHIVELOG attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template BACKUPSET attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template XTRANSPORT attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template DATAGUARDCONFIG attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template CONTROLFILE attributes (UNPROTECTED FINE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template AUTOBACKUP attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template DUMPSET attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template ONLINELOG attributes (UNPROTECTED FINE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template PARAMETERFILE attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template ASM_STALE attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template CHANGETRACKING attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR*/DG7 alter template DATAFILE attributes (UNPROTECTED COARSE);
alter diskgroup /*ASMCMD AMBR */ DG7 add directory '+DG7/TEST';디스크 검사
Path
/dev/raw/raw10
/dev/raw/raw11
/dev/raw/raw13
... snipped ...





![]()
State Type Rebal Sector Block AU Total_MB Free_MB Req_mir_free_MB Usable_file_MB Offline_disks Name
MOUNTED NORMAL N 512 4096 1048576 206 78 0 39 0 DG2/


NOTE: starting check of diskgroup DG2
WARNING: cache read a corrupted block gn=2 fn=3 indblk=1 from disk 0
...
NOTE: cache successfully reads gn 2 fn 3 indblk 1 count 15 from one mirror side
kfdp_checkDsk(): 89
...
NOTE: cache initiating offline of disk 0 group 2
WARNING: initiating offline of disk 0.3915926170 (DG2_0000) with mask 0x7e
...
WARNING: Disk (DG2_0000) will be dropped in: (7200) secs on ASM inst: (1)
...
WARNING: Disk (DG2_0000) will be dropped in: (5550) secs on ASM inst: (1)
GMON SlaveB: Deferred DG Ops completed.
Sat Oct 06 00:25:52 2007
WARNING: Disk (DG2_0000) will be dropped in: (5366) secs on ASM inst: (1)
GMON SlaveB: Deferred DG Ops completed.
Sat Oct 06 00:28:55 2007
WARNING: Disk (DG2_0000) will be dropped in: (5183) secs on ASM inst: (1)
GMON SlaveB: Deferred DG Ops completed.
Sat Oct 06 00:31:59 2007
WARNING: Disk (DG2_0000) will be dropped in: (5000) secs on ASM inst: (1)
GMON SlaveB: Deferred DG Ops completed.
...결론