
DBMS 1
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
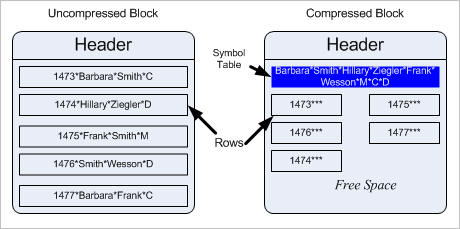
마지막으로 여러분들께 도움이 될 만한 Oracle Database 11 g 의 다른 여러 기능에 대해 소개하겠습니다. Oracle Database의 새로운 각 버전에서는 새 프로세스에 사용되는 새로운 약어 모음이 사용됩니다. Oracle Database 11 g Release 1에 사용되는 약어 목록은 다음과 같습니다. 새로운 이 기능은 SQL 문을 색상으로 표시하는 대신 "important"라는 표시를 남깁니다. 특정 SQL 문으로 인해 발생된 것으로 추정되는 성능 문제를 해결하는 경우를 가정해 보겠습니다. 모든 AWR(Automatic Workload Repository) 스냅샷에 SQL 문을 캡처하고자 하나 AWR 스냅샷이 모든 SQL 문이 아닌 상위 몇 개 문만 캡처합니다. 상위 SQL 문 포함 여부에 관계없이 특정 SQL 문을 캡처하려면 어떻게 해야 할까요 해당 SQL이 상위 SQL에 있는지 여부와 관계없이 모든 AWR 스냅샷에 캡처될 수 있도록 dbms_workload_repository 패키지의 add_colored_sql() 프로시저가 해당 SQL을 "colored" 또는 "important"라고 표시합니다. 먼저 SQL 문을 파악한 다음 해당 SQL_ID를 구합니다. 이를 색칠하려면 다음을 사용합니다. 어떤 SQL을 색칠했는지 확인하기 위해 다음과 같이 AWR 테이블 WRM$_COLORED_SQL을 쿼리할 수 있습니다 그러면 ID가 ff15115dvgukr인 SQL 문은 상위 SQL 문에 없더라도 모든 스냅샷에 캡처됩니다. 물론 해당 SQL이 AWR 스냅샷에 캡처되려면 라이브러리 캐시에 있어야 합니다. 그러나 SQL이 색상 표시를 하지 않는다면, 즉 캡처할 만큼 중요하지 않다면 어떻게 해야 할까요 반대 프로시저를 실행하여 색상 표시를 해제할 수 있습니다. 이 기능은 튜닝 연습에서 특정 SQL에 중점을 두려는 경우 특히 유용합니다 Oracle Database에서는 오랜 기간 동안 한 가지 또는 다른 형태로 압축 기능을 제공하고 있습니다. 압축은 언제나 CPU를 많이 사용하며 시간이 많이 소요됩니다. 데이터를 압축하면 보통은 압축을 풀어야 데이터를 활용할 수 있습니다. 일반적으로 대규모 행에서 SQL이 작동되고 긴 응답 시간이 대체로 용인되는 데이터 웨어하우스 환경의 경우에는 이러한 요구 사항을 받아들일 수 있지만 OLTP 환경에서는 그렇지 못할 수 있습니다. 이제 Oracle Database 11g에서는 다음을 통해 이러한 문제를 해결할 수 있습니다. : "compress for all operations" 구문을 사용하면 INSERT, UPDATE 등과 같은 모든 DML 활동에서의 압축이 가능합니다. 이전 버전에서처럼 직접 경로 삽입뿐 아니라 모든 DML 활동에서 압축이 수행됩니다. 이렇게 하면 DML이 느려질까요 꼭 그런 것은 아닙니다. 여기서 새로운 기능의 이점을 만나볼 수 있습니다. 행이 테이블에 삽입될 때 압축이 실행되지 않습니다. 그 대신 행이 압축되지 않은 상태로 일정한 방식에 따라 삽입됩니다. 특정 수의 행이 압축되지 않은 방식으로 삽입되거나 업데이트되면 압축 알고리즘이 작동하여 압축되지 않은 모든 행이 블록으로 압축됩니다. 즉 행이 아닌 블록이 압축됩니다. 압축 발생 임계값은 RDBMS 코드에서 내부적으로 정의됩니다. 다음과 같이 레코드가 있는 ACCOUNTS라는 테이블을 예로 들어 봅니다: 데이터베이스에는 위 모든 행을 포함하는 하나의 데이터베이스 블록이 있습니다. 압축되지 않은 블록은 바로 이렇게 보입니다. 즉 모든 필드(열)에 모든 데이터가 있는 레코드가 있습니다. 이 블록이 압축되면 먼저 데이터베이스는 모든 행의 반복 값을 산출하여 행 밖으로 이동한 다음 블록 헤더 인근에 배치합니다. 행에서 이러한 반복 값은 각 값을 나타내는 기호로 대체됩니다. 개념상 이것은 아래 그림과 같으며 압축 전후에 블록을 확인할 수 있습니다. 행에서 값을 가지고 와서 "기호 테이블(Symbol Table)"이라는 상위의 특수 영역에 배치하는 방법을 확인하십시오. 열의 각 값에는 행 내부의 실제 값을 대신하는 기호가 할당됩니다. 기호는 실제 값보다 작으므로 레코드 크기도 원래 값보다 상당히 줄어듭니다. 행에 반복 데이터가 많으면 많을수록 기호 테이블과 그에 따른 블록이 더 꽉 차게 됩니다. 압축은 행이 삽입되는 시점에 수행되는 것이 아니라 트리거된 이벤트로 발생하므로 정상 DML 프로세스 중 압축으로 인해 성능에 영향을 미치지 않습니다. 물론 압축 트리거 시 CPU 수요가 높아지나 그 밖의 모든 경우 CPU 영향이 없으므로 OLTP 애플리케이션에도 압축이 적합하게 됩니다. 바로 이것이 Oracle Database 11 g 압축의 장점입니다. 공간 사용량이 줄어드는 것 외에도 압축된 데이터가 네트워크를 통해 이동하는 시간이 단축되고 백업에 더 적은 공간을 사용하며 QA 및 테스트에서 운영 데이터베이스의 전체 사본을 유지 관리하는 것이 가능하게 됩니다. 들리는 바와 달리 COPY 명령이 여전히 필요합니다. LONG 데이터 형식을 복사하는 유일한 방법이 이 명령이기도 합니다. 하지만 지원이 중지되었으므로 Oracle Database에서의 최신 개발에는 부합하지 않습니다. 예를 들어 새로운 데이터 형식인 BFILE의 존재를 인식하지 못합니다. 다음 예에서는 앞서 예에서 나온 BFILE 열을 갖는 DOCS 테이블을 복사합니다. : 오류 메시지에 COPY 명령으로 BFILE 데이터 형식을 복사할 수 없다고 표시됩니다. 그러나 LONG 열이 있는 테이블의 경우 INSERT /*+ APPEND */ and CREATE TABLE ... NOLOGGING AS SELECT ... 문을 사용합니다. 다음 예에서는 한 테이블의 일부 행을 LONG으로 정의된 열이 있는 다른 테이블로 복사합니다. 따라서 undo 세그먼트를 채우지 않고 대규모 데이터를 복사하기 위한 유일하고 간편한 옵션은 COPY 명령입니다. Oracle Database 10 g 에 Data Pump가 도입되었을 때 그에 따라 기존의 내보내기 및 가져오기 도구가 없어질 것이라 예상했습니다. 그렇지만 Oracle Database 11 g 에서도 이러한 기존 도구가 많이 사용됩니다. 지원이 중지되어 더 이상의 기능 향상은 없으나 그렇다고 무용한 것은 아닙니다 . 기능면에서 보면 Data Pump가 Regular Export/Import보다 훨씬 뛰어나지만 서버가 아닌 클라이언트에 덤프 파일을 생성해야 하는 경우와 같은 간단한 예에서는 여전히 Regular Export/Import가 상당히 유용합니다. 이 작업을 수행하기 전에 디렉토리를 생성할 필요가 없으므로 많은 경우에서 간단한 데이터 내보내기에는 Regular Export/Import를 사용하는 것이 더 쉬울 것입니다 재차 말하지만 이 도구는 지원이 중지되었으므로 이를 사용하는 데는 다음과 같은 3가지 위험 요소가 있습니다 * 오라클에서는 이 도구에 어떤 기능도 추가하지 않을 것이므로 향후 데이터 형식 등이 지원되지 않을 수 있습니다 따라서 기존 코드를 Data Pump로 변환하는 것이 좋으며 특히 새로운 개발에서는 더욱 그렇습니다. 파티션된 테이블에서는 각 파티션에 옵티마이저 통계가 있습니다. 또한 파티션에 종속되지 않는 전체 테이블에 대한 글로벌 통계도 있습니다(예: 테이블 전체의 고유한 값 수). 이 글로벌 통계는 기본적인 것이 아니라 dbms_stats.gather_*_stats 프로시저에서 지시한 경우에만 수집됩니다. 글로벌 통계 매개변수를 지정하지 않은 경우 이를터 도출합니다. 물론 언제나 산출된 글로벌 통계가 도출된 통계보다 정확하므로 항상 통계를 수집하는 것이 좋습니다. 그러나 이전에는 약간의 문제가 있었습니다. 한 파티션의 데이터가 변경되었으나 다른 파티션은 그렇지 않은 경우 글로벌 통계가 최신 통계가 아닐 수 있습니다. 따라서 한 파티션에만 변경이 있는 경우에도 통계 수집 프로그램이 전체 테이블을 거치며 글로벌 통계를 수집해야 했습니다. 이제는 더 이상 그렇지 않습니다. Oracle Database 11 g 에서는 옵티마이저가 또 다른 전체 테이블 스캔 없이 변경된 파티션으로부터만 글로벌 통계를 점진적으로 수집하도록 할 수 있습니다. 즉 다음과 같이 통계 수집을 위한 테이블 매개변수 INCREMENTAL을 TRUE로 설정하면 됩니다. 이제 이 테이블에 대한 통계를 수집해야 하며 특히 SALES_1995 파티션에서 AUTO 세분화 수준을 적용합니다. 이 통계 수집 메소드에서는 데이터베이스가 새 파티션으로부터 수집한 글로벌 통계를 점진적으로 업데이트하도록 합니다. 앞서 언급한 것처럼 Data Pump는 이전 릴리스 이래 대용량의 데이터를 이동하거나 효율적으로 데이터의 "논리적" 백업을 만들기 위한 최상의 도구였습니다. Export/Import와 마찬가지로 플랫폼에 구애되지 않습니다. 예를 들어 Linux에서 내보내 Solaris로 가져올 수 있습니다. Oracle Database 11 g 에서는 이 도구의 몇 가지 기능이 향상되었습니다. Data Pump의 주요 문제 중 하나는 덤프 파일을 생성하는 중 압축할 수 없는 것이었습니다. 이 작업은 이전의 Export/Import 유틸리티에서는 간단하게 할 수 있었습니다. Oracle Database 11 g 에서는 Data Pump가 덤프 파일을 생성하는 중에 압축할 수 있습니다. 이는 expdp 명령줄의 COMPRESSION 매개변수를 통해 가능합니다. 이 매개변수에는 3가지 옵션이 있습니다. * METDATA_ONLY - 메타데이터만 압축하고 데이터는 그대로 둡니다(Oracle Database 10.2에서도 가능). 다음은 UNITS_FACT 테이블의 내보내기를 압축하는 방법입니다 다음은 비교를 위해 압축 없이 내보냅니다. 이제 생성된 파일을 확인합니다 압축률은 100*(15728640-2576384)/15728640 또는 약 83.61%로 매우 놀라운 수치입니다. 압축되지 않은 덤프 파일은 15MB이나 압축된 파일은 1.5MB입니다. gzip을 사용하여 덤프 파일을 압축할 경우 압축 파일은 3.2MB로, Data Pump에서의 압축 파일 크기보다 두 배나 큽니다. 따라서 압축뿐 아니라 압축을 해제할 때에도 효율성이 높아집니다. 덤프 파일을 가져올 때 가져오기에서 먼저 파일의 압축을 해제할 필요가 없습니다. 즉 읽는 시점에 압축을 해제하기 때문에 프로세스가 훨씬 빨라집니다. 이 밖에도 Data Pump에는 다음과 같은 두 가지 향상 기능이 있습니다. 암호화: 덤프 파일을 생성하는 중에 암호화할 수 있습니다. 암호화에서는 TDE(Transparent Data Encryption)와 같은 기술을 사용하며 월렛(Wallet)으로 마스터 키를 저장합니다. Oracle Database 10 g 에서와 마찬가지로 이러한 암호화는 암호화된 열뿐 아니라 전체 덤프 파일에서 발생합니다 보안 편 에서 이 두 기능에 대해 확인할 수 있습니다. 인덱스 재구성 중의 ONLINE 구문을 기억하십니까 alter index in_tab_01 rebuild online; 이 구문은 인덱스에 액세스하는 DML에 영향을 미치지 않고 해당 인덱스를 재구성합니다. 즉 액세스되는 블록을 추적하고 마지막에 해당 블록을 새로 구성한 인덱스에 병합하는 방식으로 이를 수행합니다. 이 작업을 수행하려면 작업에서 프로세스 마지막에 배타적 잠금이 있어야 했습니다. 길이는 짧더라도 어쨌든 잠금이며 DML이 대기해야 했습니다. Oracle Database 11 g 에서는 온라인 재구성이 말 그대로 온라인입니다. 즉 배타적 잠금이 없으며 DML에 영향이 없습니다. 글로벌 임시 테이블을 생성할 때 점유 공간은 어디로부터 할당을 받았습니까 바로 사용자의 임시 테이블스페이스였습니다. 보통 이것은 문제가 되지 않지만 문제가 되는 일부 특수한 경우가 있습니다. 특정 용도(대부분의 경우 정렬)를 위해 임시 테이블스페이스를 확보하고자 할 수 있습니다. 때때로 디스크 효율을 높여 데이터 액세스 속도를 높이기 위해 다른 임시 테이블스페이스를 사용하는 임시 테이블을 생성하고자 할 수 있습니다. 이러한 경우에는 해당 테이블스페이스를 사용자의 임시 테이블스페이스로 하는 것 외에는 방법이 없었습니다. Oracle Database 11 g 에서는 글로벌 임시 테이블에 다른 임시 테이블스페이스를 사용할 수 있습니다. 그 방법을 살펴보겠습니다. 먼저 다음과 같이 다른 임시 테이블스페이스를 생성합니다. 그런 다음 다음과 같이 새로운 테이블스페이스 구문으로 GTT를 생성합니다. 이제 이 임시 테이블이 사용자의 기본 임시 테이블스페이스인 TEMP가 아닌 etl_temp 테이블스페이스에 생성되었습니다. 다음과 같이 myscript.sql이라고 하는 SQL 스크립트가 있다고 가정합니다. 이 스크립트에는 몇 가지 오류가 있습니다. 첫 번째 행에서는 "pause", 두 번째 행에서는 "trimspool"의 철자가 잘못되었고 마지막 세 번째 행에는 존재하지도 않는 테이블에 대한 Select 문이 있습니다. SQL*Plus 프롬프트에서 이 스크립트를 실행할 경우 출력을 스풀하지 않는 한 향후의 오류를 확인할 수 없습니다. 스풀을 하더라도 스풀 파일을 조사하기 위해서는 물리적 서버에 대한 액세스 권한이 필요한데 이것이 불가능할 수도 있습니다. Oracle Database 11 g 에는 완벽한 해결책이 있습니다. 이제는 SQL*Plus로부터 발생하는 오류를 특정 테이블에 로깅할 수 있습니다. 먼저 다음과 같은 명령을 실행해야 합니다. 이제 스크립트를 실행합니다: SQL*Plus 프롬프트의 포그라운드 또는 백그라운드에서의 스크립트 호출 등, 스크립트 실행 방법에 따라 표시되거나 표시되지 않을 수 있습니다. 스크립트 완료 후 데이터베이스에 로그인하여 이름이 SPERRORLOG인 테이블에서 오류를 확인할 수 있습니다. 이는 스크립트를 실행한 세션이 아닌 다른 세션에서 오류를 확인한 것입니다. 사실은 어쨌든 스크립트가 완료되었고 세션이 종료된 것입니다. 이러한 방법은 다른 방식으로는 추적이 불가능하거나 어려웠던 SQL*Plus 세션에서 발생한 오류를 확인할 수 있는 강력한 기능이 됩니다. SPERRORLOG 테이블은 이 용도만을 위해 생성된 특수 테이블입니다. 고유의 테이블을 생성하여 SQL*Plus의 오류를 입력할 수도 있습니다. 이 테이블은 다음과 같이 생성합니다. 이제 기본 테이블 대신 이 테이블을 오류 로깅에 사용할 수 있습니다. 이제 SPERRORLOG가 아닌 MY_ERROR_LOG가 오류 로그를 보관합니다. 다음 구문을 통해 테이블 내 모든 행을 분리할 수 있습니다. 선택적으로 IDENTIFIER 구문을 사용하여 특정 세션에서의 오류에 태그를 달 수 있습니다. 다음 명령을 실행한다고 가정합니다. 이제 스크립트를 실행하면 값 MYSESSION1이 입력된 IDENTIFIER라는 열을 통해 레코드가 생성됩니다. 다음 쿼리만 실행하면 해당 레코드를 추출할 수 있습니다 해당 세션의 레코드만 보입니다. 이러한 기능은 여러 스크립트와 세션에서 오류를 격리하고자 할 때 매우 유용합니다. 임시 테이블스페이스가 특별하다는 점은 이미 알고 계실 것입니다. 즉 일반적인 공간 관리 규칙이 적용되지 않을 수 있습니다. 임시 세그먼트는 할당되면 할당 취소할 수 없습니다. 사실 임시 세그먼트(임시 테이블스페이스의 대상)는 스키마의 일부도 아니고 데이터베이스 재사용 시 저장되지 않으므로 이 점은 문제가 되지 않습니다. 이 공간은 다른 사용자나 다른 쿼리에서 재활용합니다. 어쨌든 이 공간을 할당 취소할 수 없으므로 임시 테이블스페이스는 지속적으로 커지게 됩니다. 그러나 다른 테이블스페이스를 위한 공간을 확보하기 위해 이를 조절하고자 한다면 어떻게 될까요 지금까지는 해당 테이블스페이스를 삭제한 후 재생성하는 방법뿐이었습니다. 이 작업은 거의 항상 온라인으로 수행할 수 있는 다소 사소한 것이나 그렇지 않은 경우도 간혹 있습니다. 그러면 가동 시간을 100% 달성해야 하는 경우 어떻게 해야 할까요 Oracle Database 11 g 에서는 임시 테이블스페이스를 축소함으로써 간단하게 이를 구현할 수 있습니다. TEMP1 테이블스페이스를 축소하는 방법은 다음과 같습니다. 이렇게 하면 테이블스페이스에서 사용하지 않은 모든 세그먼트가 할당 취소되고 축소됩니다. 위 작업 후 DBA_TEMP_FREE_SPACE 뷰에서 할당된 공간과 현재 여유 공간의 크기를 확인할 수 있습니다. 상대적으로 작업이 적은 데이터베이스에서는 축소 작업이 임시 테이블스페이스를 거의 빈 상태가 되게 축소할 수 있으나 이는 인위적인 것에 불과합니다. 이후의 활동에서 테이블스페이스를 확장할 것이므로 일정 공간을 남기고자 할 수 있습니다. 여기서는 100MB라고 가정하며 이 작업은 다음과 같이 수행합니다 100MB를 제외한 모든 공간이 해제되었습니다. 이러한 접근 방식은 다양한 테이블스페이스의 공간 관리에 도움이 됩니다. 이제 정말로 임시 테이블스페이스 내부의 공간을 빌어 다른 테이블스페이스에 임시 할당할 수 있습니다. 이후 해당 공간이 더 이상 필요하지 않게 되면 다시 임시 테이블스페이스로 되돌릴 수 있습니다. 이 기능을 글로벌 임시 테이블용 테이블스페이스와 결합하면 임시 테이블스페이스에서의 여러 까다로운 공간 관리 문제를 해결할 수 있습니다. Oracle Database의 BFILE 데이터 형식은 외부 파일 자체의 내용이 아니라 해당 파일에 대한 포인터를 저장합니다. 이 데이터 형식에는 특정한 용도가 있습니다. 즉 사용자가 파일 내 데이터에 대한 액세스 권한을 갖고 있는 동안 데이터베이스 공간을 유지하는 것입니다. 컨텐츠와 멀티미디어가 많은 데이터베이스를 사용하는 것과 같은 일부 애플리케이션에서는 확장됩니다. 테이블에 BFILE이 있는 열이 있고 SQL*Plus에서 이 테이블의 행을 선택하려 하면 오류가 발생했습니다. Oracle Database 11 g 에서는 SQL*Plus가 열의 값으로 파일의 위치를 표시합니다. 예를 살펴보겠습니다. 먼저 BFILE을 저장할 디렉토리를 생성해야 합니다. 이제 테이블을 생성합니다. 행을 생성합니다. SQL*Plus에서 다음과 같이 이 행을 선택할 경우 BFILE가 있는 DOC_FILE 열 아래의 출력에 오류 대신 파일 위치가 표시됩니다 메모리의 매개변수 파일 다음 시나리오를 가정해 보겠습니다. 일부 데이터베이스 문제 진단 과정 중에 모두 메모리에 있는 많은 매개변수를 수정했으며, 나중에 어떤 매개변수를 변경했는지 기억이 나지 않습니다. 해당 매개변수를 초기화 매개변수 파일(pfile 또는 spfile)에 넣지 않았다면 이러한 변경은 모두 손실될 것입니다. 값을 시험하고 있었고 어떤 특정 값을 사용할지 확신하지 못했기 때문에 이를 매개변수 파일에 넣지 않았을 가능성이 높습니다. 물론 알림 로그를 살펴보고 모든 변경 사항을 골라낼 수도 있으나 이 절차는 수고스러울 뿐 아니라 오류 가능성도 높습니다. Oracle Database 11 g 에서는 매우 간단한 명령을 사용하여 메모리의 매개변수 값으로부터 pfile 또는 spfile을 생성할 수 있습니다. 이렇게 하면 메모리의 값으로 pfile 또는 spfile이 생성됩니다. pfile에는 파일 맨 위에 다음과 유사한 항목이 있습니다 이 항목은 메모리에서 변경된 매개변수를 수집할 때의 많은 수고와 위험을 덜어줍니다. 또한 다른 이름으로 pfile을 생성한 다음 현재 pfile을 생성된 것과 비교하여 변경된 매개변수를 파악할 수 있습니다. 이 문은 /tmp/a라는 pfile을 생성합니다. 이제 UNIX에서 간단한 diff 명령을 사용하여 이 두 파일의 차이를 확인할 수 있습니다. 성능 튜닝 프로세스 중에 spfile에서 직접 여러 동적 초기화 매개변수 변경의 영향을 조사하고 있으며 문득 변경 사항을 추적할 수 없게 되었다는 사실을 우려하게 되었습니다. 이러한 내용은 spfile에서 변경되었으므로 spfile을 통해 어떠한 값을 변경했는지 확인할 수는 없습니다. 여기에 방법이 있습니다. ALTER SYSTEM RESET 명령은 이 값을 기본값으로 재설정하여 spfile을 덮어씁니다 이 명령은 이전 릴리스에서도 제공되었던 것이나 이전 릴리스의 경우 RAC 데이터베이스에서 초기에 SID 문이 필요했다는 점이 근본적으로 다릅니다. 모든 인스턴스에서 재설정하려면 SID='*' 구문을 지정해야 했습니다. Oracle Database 11g에서는 SID 구문이 선택 사항이며 기본값은 모든 인스턴스입니다. 이 구문을 생략하면 조기에 오류가 발생했으나 이제는 그렇지 않습니다. 하지만 결과는 바라는 것과 다를 수 있으므로 주의가 필요합니다. 이 기능을 통해 성능 진단이 획기적으로 향상되었습니다. 다음과 같은 상황을 가정해 보겠습니다. 누군가 여러 SQL을 실행하고 있습니다(아마도 PL/SQL 코드 내부에서). 각 액세스 경로 단계에서 필요한 리소스(CPU, I/O 등) 규모를 어떻게 알 수 있을까요 Trace Analyzer나 일반 tkprof를 사용하여 추적 파일을 분석하거나 세션을 추적할 수 있지만 이것은 상황이 종료된 후의 일입니다. 세션에서 발생하고 있는 상황을 실시간 창으로 보여 주는 기능이 있다면 편리할 것입니다. Oracle Database 11 g 의 새로운 기능인 Real-time SQL Monitoring은 이름 그대로 정확하게 실시간 SQL 모니터링 기능을 제공합니다. 실시간으로 실행 중인 SQL의 다양한 메트릭을 파악할 수 있게 해 줍니다. 이 상태는 초 단위로 새로 고쳐지는 동적 성능 뷰인 V$SQL_MONITOR를 통해 표시됩니다. 이를 입증하기 위해 대규모 쿼리를 실행하고 실시간 상태를 모니터링해 보겠습니다. 이 대규모 쿼리를 실행하는 세션의 SID는 103이라고 알고 있습니다. 뷰를 선택하는 동안 톰 카이트의 유명한 print_table 도구를 사용했습니다. 이 도구는 가독성을 높이기 위해 출력을 수직 형식으로 표시합니다. 대부분가 실행하는 SQL 문의 SQL ID, STATUS는 바로 현재 실행 중인 SQL의 상태, SQL_EXEC_START는 시작 시간 등으로 해석할 수 있습니다. CPU_TIME, DISK_READS 및 DIRECT_WRITES 등의 열은 그 이름 그대로의 메트릭을 보여 줍니다. 쿼리를 계속 실행하면 이러한 메트릭이 업데이트되는 것을 확인할 수 있습니다. 또 다른 뷰인 V$SQL_PLAN_MONITOR는 실시간으로 실행 및 업데이트되는 SQL 문의 옵티마이저 계획을 보여 줍니다. 다음과 같이 이 뷰를 사용하여 계획의 다양한 단계과 관련 상태를 실시간으로 확인할 수 있습니다 이전 뷰와 같이 쿼리를 재실행하면 메트릭이 업데이트되는 것을 확인할 수 있습니다. 이 두 뷰를 통해 실시간으로 해당 SQL의 처리를 엿볼 수 있습니다. 실시간 SQL 모니터링의 또 다른 유용한 부분은 SQL Monitor Report입니다. 이 보고서를 사용하면 SQL 및 계획 단계에 대한 다양한 메트릭의 시각적 보고서를 얻을 수 있습니다. 이 보고서는 DBMS_SQLTUNE 패키지에 있는 REPORT_SQL_MONITOR 함수의 CLOB 출력으로 생성됩니다. 이 함수는 다음과 같이 호출할 수 있습니다. rep1.html 파일에 출력을 스풀하고 SQL을 실행합니다. 잠시 후 이 SQL을 다시 실행하여 새 파일인 rep2.html에 스풀합니다. 마지막으로 쿼리가 rep3.html에 스풀링을 완료한 후 실행합니다. 각 보고서 파일은 해당 시점에서의 SQL 실시간 메트릭에 대한 스냅샷입니다. 서로 다른 세 시점에서 보고서를 가지고 왔으므로 진행 상황을 추적할 수 있습니다. 다음과 같이 웹 브라우저에서 이 파일 중 하나를 열어 봅니다. 여기서는 메트릭이 표시되는 SQL 문을 확인할 수 있습니다. 맨 위 왼쪽에는 시작 시간, 마지막으로 새로 고친 시간 등과 같은 SQL에 대한 메타데이터가 있으며 오른쪽에는 다양한 메트릭을 표시하는 여러 색상의 막대가 있습니다. 마우스를 이 막대 위에 놓으면 그에 대한 설명과 표시하는 값이 나타납니다. 화면의 아래쪽에는 쿼리에 대한 옵티마이저 계획, 각 단계의 소요 시간이 CPU activity, Waits 등과 같은 범주 아래 표시됩니다. 색상 막대는 각 메트릭의 상대값을 표시합니다. 마우스를 이러한 막대 위에 놓으면 각 메트릭의 값과 시간을 볼 수 있습니다. 이 보고서는 앞서 그래픽 형식으로 보았던 실시간 SQL 모니터 뷰의 스냅샷에 불과합니다. 그래픽으로 표시된 데이터를 통해 쿼리의 구성 요소를 이해하고 각 구성 요소에 대한 소요 시간을 측정하며 훨씬 간단하게 성능을 진단할 수 있습니다. 이것으로써 20주 동안 진행되었던 Oracle Database 11 g 의 새로운 기능에 대한 개략적인 설명을 마치겠습니다. 다른 저자들과 마찬가지로 저도 내용의 깊이와 범위 사이에서 조화를 이루고자 최선을 다했습니다. 그러나 이전의 Oracle Database 10 g Rel 1과 Rel 2 관련 시리즈에 대한 독자들의 의견은 아주 분명했습니다. 즉 예를 기준으로 한 설명 방식을 선호하셨기 때문에 이 시리즈에서도 이 형식을 유지했습니다. 이 시리즈를 확인해 주신 검토자 여러분께 진심으로 감사합니다. 이 프로젝트가 성공할 수 있도록 지지와 도움을 보내 주신 Justin Kestelyn에게도 감사의 말씀을 전합니다. 그리고 무엇보다 독자 여러분들께 감사합니다.기억해야 할 사항
기억해야 할 사항...
간략한 개요
새 프로세스
프로세스
이름
설명
ACMS
Atomic Controlfile to Memory Server
RAC 인스턴스에서만 사용 가능합니다. 배포된 SGA 업데이트가 수행되면 ACMS는 모든 인스턴스에서 업데이트를 진행하며, 한 인스턴스에서 업데이트가 실패할 경우 모든 인스턴스에서 롤백을 수행합니다. ACMS는 RAC 클러스터에서의 SGA 업데이트를 위한 2단계 커밋 조정자 프로세스라고 할 수 있습니다.
DBRM
Database Resource Manager
리소스 계획 및 기타 리소스 관리자 관련 업무를 구현합니다.
DIA0
Diagnosibility process 0
정지 상태와 교착 상태를 감지합니다. 향후 여러 프로세스가 있을 수 있으므로 이름을 diag0으로 지정했으며, 이후는 프로세스 이름이 dia1, dia2 등으로 지정됩니다.
DIAG
Diagnosibility process
진단을 수행하고 추적 파일을 삭제하며 필요한 경우 글로벌 oradebug 명령을 수행합니다.
FBDA
Flashback Data Archiver
Oracle Database 11g에는 테이블에 대한 변경 사항을 기록하기 위한 새로운 "Flashback Archives"가 있습니다(이 시리즈의 “Transactions Management” 편 참조). 이 프로세스는 플래시백 아카이브를 작성합니다.
GTX0
Global Transaction Process 0
Oracle Database는 RAC 클러스터에서 향상된 XA 트랜잭션 처리를 제공하며, 이 프로세스는 XA 트랜잭션을 조절합니다. XA에서 데이터베이스 로드가 커지면 프로세스가 추가로 생성되며, 프로세스 이름은 GTX1, GTX2에서 GTXJ까지입니다.
KATE
Konductor (Conductor) of ASM Temporary Errands
가장 큰 범위의 모든 새 프로세스 이름으로, 데이터베이스가 아닌 ASM 인스턴스에서 확인할 수 있습니다. 새로운 기능인 Fast Disk Resync에 대한 내용은 이 시리즈의 ASM 편 을 참조하십시오. 디스크가 오프라인 상태가 되면 ASM 메타 파일을 대신하여 이 프로세스에서 프록시 I/O가 수행됩니다.
MARK
Mark AU for Resync Koordinator (coordinator)
ASM 디스크 그룹의 복원력에 대한 자세한 내용은 ASM 편 을 참조하십시오. 디스크에 장애가 발생하면 오프라인으로 전환되어 쓰기 작업이 중단됩니다. 이 경우 이 프로세스가 해당 ASM 할당 단위(AU)를 스테일(stale)로 표시합니다. 디스크가 다시 온라인으로 전환되면 스테일 세그먼트가 새로 고쳐집니다.
SMCO
Space Manager
SMCO는 공간을 동적으로 할당 및 할당 취소하는 마스터 공간 관리 프로세스로, 종속 프로세스인 Wnnn을 생성하여 이 작업을 구현합니다.
VKTM
Virtual Keeper of TiMe process
실제 실행 시간 상당값을 제공합니다(1초 업데이트). 더 높은 우선 순위에서 실
W000
Space Management Worker Processes
SMCO로부터 받은 지침을 구현하며, 필요에 따라 이름이 W000, W001 등인 새로운 프로세스를 생성합니다.
Colored SQL
dbms_workload_repository.add_colored_sql(
sql_id => 'ff15115dvgukr'
);
end;
DBID SQL_ID OWNER CREATE_TI
---------- ------------- ---------- ---------
2965581158 ff15115dvgukr 1 05-APR-08
dbms_workload_repository.remove_colored_sql(
sql_id => 'ff15115dvgukr'
);
end;
OLTP 테이블 압축
col1 number(20),
col2 varchar2(300),
...
)
compress for all operations
압축 메커니즘


여전히 사용되는 COPY 명령
> replace docs_may08 -
> using select * from docs
> where creation_dt between '1-may-08' and '31-may-08';
Enter TO password:Array fetch/bind size is 15. (arraysize is 15)
Will commit when done. (copycommit is 0)
Maximum long size is 80. (long is 80)CPY-0012: Datatype cannot be copied
*
ERROR at line 1:
ORA-00997: illegal use of LONG datatypeSQL> insert /*+ APPEND */ into mytab
2> select * from mytab where col1 = 'A';
select * from mytab
*
ERROR at line 2:
ORA-00997: illegal use of LONG datatype
Exports and Import: 지원 중단
* 향후 릴리스에서 사전 고지 없이 사라질 수 있으므로 나중에 코드를 다시 작성해야 할 수 있습니다.
* 버그 발생 시 Oracle Support에서 해당 코드 수정을 거부할 수 있습니다글로벌 통계의 점진적 업데이트
dbms_stats.set_table_prefs(
'SH','SALES','INCREMENTAL','TRUE');
end;
/
dbms_stats.gather_table_stats (
ownname => 'SH',
tabname => 'SALES',
partname => 'SALES_1995',
granularity => 'AUTO'
);
end;
Data Pump 기능 향상
* DATA_ONLY - 데이터만 압축하고 메타데이터는 그대로 둡니다.
* ALL - 메타데이터와 데이터를 모두 압축합니다.
* NONE - 기본값으로, 압축을 수행하지 않습니다.
units_fact dumpfile=units_fact_comp.dmp compression=all
units_fact dumpfile=units_fact_uncomp.dmp
-rw-r----- 1 oracle dba 2576384 Jul 6 22:39 units_fact_comp.dmp
-rw-r----- 1 oracle dba 15728640 Jul 6 22:36 units_fact_uncomp.dmp
units_fact_uncomp.dmp.gz
* 마스킹: 운영에서 QA로 데이터를 가져올 때 주민등록번호와 같은 기밀 데이터를 식별 불가능한 방식으로 변경하여 판독하기 어렵게 만들고자 할 수 있습니다. Oracle Database 11 g 의 Data Pump에서는 마스킹 함수를다진정한 온라인 인덱스 재구성
임시 테이블을 위한 다양한 테이블스페이스
2> tempfile '+DG1/etl_temp_01.dbf'
3> size 1G;Tablespace created.
2> input_line varchar2 (2000)
3> )
4> on commit preserve rows
5> tablespace etl_temp;Table created.
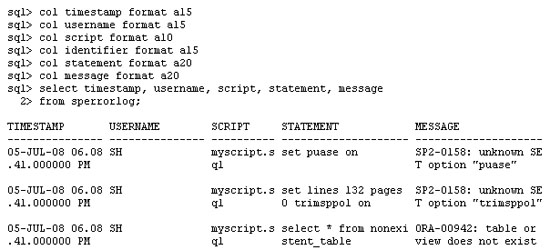
SQL*Plus 오류 로깅
set lines 132 pages 0 trimsppol on
select * from nonexistent_table
/
SP2-0158: unknown SET option "puase"
SP2-0158: unknown SET option "trimsppol"
select * from nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist

2 ( 3 username varchar2(256),
4 timestamp timestamp,
5 script varchar2(1024),
6 identifier varchar(256),
7 message clob,
8 statement clob
9 )
10 /Table created.
SQL> @myscript
from sperrorlog
where identifier = 'MYSESSION1';
임시 테이블스페이스 축소
------------------------------ --------------- --------------- ----------
TEMP 179306496 179306496 178257920
------------------------------ --------------- --------------- ----------
TEMP 105906176 1048576 104857600
SQL*Plus에서 BFILE 표시
2 (
3 doc_id number(20),
4 doc_file bfile,
5 doc_type varchar2(10)
6 );Table created.
2 ( 3 1,
4 bfilename('DOC_DIR','metric_daily_report.pdf'),
5 'PDF'
6 );1 row created.
SQL> select * from docs;DOC_ID DOC_FILE DOC_TYPE
---------- -------------------------------------------------- ----------
1 bfilename('DOC_DIR', 'metric_daily_report.pdf') PDF
ODEL11 on 08/28/2007 14:52:14
재설정 시 주의
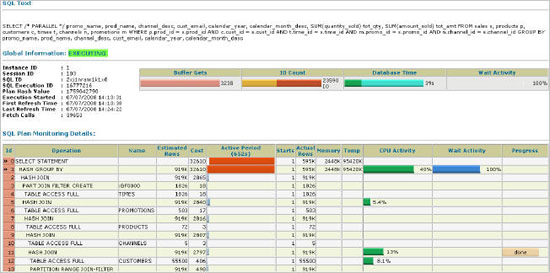
실시간 SQL 모니터링
STATUS : EXECUTING
FIRST_REFRESH_TIME : 07-jul-2008 14:13:38
LAST_REFRESH_TIME : 07-jul-2008 14:26:27
REFRESH_COUNT : 48043
SID : 103
PROCESS_NAME : ora
SQL_ID : 2xj1nram1k1x0
SQL_EXEC_START : 07-jul-2008 14:13:31
SQL_EXEC_ID : 16777216
SQL_PLAN_HASH_VALUE : 1759042790
SQL_CHILD_ADDRESS : 38837734
SESSION_SERIAL# : 32668
PX_SERVER# :
PX_SERVER_GROUP :
PX_SERVER_SET :
PX_QCINST_ID :
PX_QCSID :
ELAPSED_TIME : 42638722
CPU_TIME : 9199624
FETCHES : 48032
BUFFER_GETS : 3238
DISK_READS : 12096
DIRECT_WRITES : 13419
APPLICATION_WAIT_TIME : 0
CONCURRENCY_WAIT_TIME : 134534
CLUSTER_WAIT_TIME : 0
USER_IO_WAIT_TIME : 148436
PLSQL_EXEC_TIME : 0
JAVA_EXEC_TIME : 0
-----------------
SQL> select dbms_sqltune.report_sql_monitor (
2 event_detail => 'YES',
3 report_level => 'ALL',
4 type => 'HTML'
5 )
6 from dual;
맺는 말