
DBMS 1
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
OLAP 큐브의 강력함과 SQL의 단순함을 특별한 도구 없이 결합하는 데이터베이스 상주형 큐브 구성 구체화 뷰, 파티션 변경 추적을 통한 간편한 새로 고침 확인, 새로운 Analytic Workspace Manager, 하위 쿼리와 원격 테이블로 확장된 Query Rewrite 및 기타 여러 새로운 기능을 통해 Oracle Database는 더욱 막강한 데이터 웨어하우징 플랫폼으로 재탄생했습니다 1970년대부터 퍼졌던 OLAP(Online Analytic Processing)의 개념은 1992년 Ted Codd가 만든 OLAP란 용어와 함께 1990년대 중반 주류로 부상했습니다. 어떤 면에서 난해한 OLAP는 당시 대부분의 기업이 적절하게 활용하는 방법을 알지 못했었습니다 수년 후 대용량 데이터 웨어하우스에 OLAP를 구현할 만큼 충분한 기술이 개발되어 진정한 비즈니스 인텔리전스가 탄생할 수 있었습니다. 기존의 관계형 설계와 사뭇 다른 OLAP는 가장 효율적인 방식의 데이터 저장 및 액세스를 제공하므로 최종 사용자가 여러 차원의 관념적 "큐브" 가장자리를 관통할 수 있도록 합니다 (이러한 데이터 큐브의 예는 아래 참조). 이 큐브의 차원은 팩트("측정"이라고도 함)와 연결됩니다. 관계형 설계식으로 말하자면 팩트는 차원과 1대 다수의 관계가 있습니다. 예를 들어 Acme Computer Supplies에는 판매에 대한 데이터베이스가 있을 수 있습니다. 일반적으로 차원은 고객(Customer), 제품(Product) 및 시간(Time) 요소(월, 분기 등)가 됩니다. 특정 기간(2008년 8월) 동안 특정 고객(Oracle Corp.)에 대한 특정 제품(Cat5e 케이블)의 판매 수치는 하나의 측정값입니다. 차원은 개별 테이블에 저장되며 팩트, 즉 판매 수치도 마찬가지입니다. 따라서 관계형 설계식으로 말해 팩트 테이블이 차원 테이블의 하위 테이블입니다. 그러나 두 설계의 유사한 부분은 여기까지입니다. 관계형 설계에서는 측정값에 대한 액세스가 팩트 테이블의 고객, 제품 또는 시간 열에 생성된 인덱스를 통해 수행됩니다. OLAP 접근에서는 큐브 관통을 통해 특정 셀(측정값)에 액세스합니다. 이 예에서는 시간(2008년 8월)을 포함하는 슬라이스로 이동한 다음 제품 Cat5e 슬라이스로 이동하고 마지막으로 고객인 Oracle 슬라이스로 이동합니다. 오라클은 테이블이 아닌 배열로 대상을 계산하여 이러한 슬라이스로 이동하는 방법을 알고 있습니다. 예를 들어 차원을 아래와 같이 구성한다고 가정합니다. Oracle + Aug + Cat5e에 대한 측정값을 찾으려면 OLAP 엔진이 다음과 유사한 탐색을 수행합니다. 1. Aug 08은 Time이라는 배열의 4번째 요소이므로 큐브의 시간 차원을 따라 4번째 셀로 이동합니다 이렇게 원하는 측정값에 이를 수 있습니다. 차원 값이 배열 포인터 역할을 하므로 인덱스 없이 이 작업이 수행됩니다. 이와 유사하게 2008년 8월의 모든 고객에 대한 총 판매를 계산하고자 한다면 3단계를 제외한 위의 작업을 똑같이 수행하여 특정 셀로 이동하지 않고 배열 요소의 측정값에 대한 총계를 냅니다. 다음에서는 이 접근을 기존의 스타 스키마에 저장된 순수 관계형 데이터 양식에서의 관계형 액세스와 비교해 보겠습니다 관계형 데이터베이스 접근에서는 이 "팩트" 테이블을 모든 차원과 연결해야 합니다. 데이터가 필요할 때마다 인덱스 등을 통해 팩트 테이블에서 적합한 데이터를 선택하고 이를 다시 인덱스를 통해 각 차원과 하나씩 연결합니다. 이러한 접근이 기술적으로 가능하다 하더라도 대용량 데이터베이스에서는 실현 가능성이 낮습니다. 이에 대한 대안으로 모든 선택에 대해 구체화된 뷰(MV)를 생성하면 어떨까요 사용자는 다음과 같이 차원 내 요소의 모든 결합을 사용할 수 있습니다. * 모든 고객에 대한 8월의 Cat5e 매출 기타. 하지만 몇 개의 MV를 생성해야 합니까 이론적으로 각 조합마다 하나가 필요합니다((4 x 4 x 4 = 64개 MV) 공간 외에도 데이터 변경 시 MV를 새로 고치기 위한 시간과 데이터베이스 리소스가 필요하며 여기에는 수천 개의 요소가 관련될 것입니다. 따라서 생성 및 관리 대상 MV의 수가 엄청나게 증가합니다. 반대로 큐브는 모든 유형의 쿼리를 똑같이 간단하게 제공하는 단일 세그먼트입니다. 더 신속한 요약 데이터 처리를 위해 데이터 웨어하우스 설계에서 두 방식으로 모두 사용하고 있지만(OLTP와 반대로) 근본적으로 상당히 다릅니다. 즉 MV가 결합 및 집계를 지양하기 위해 사전 산출된 결과를 저장하는 반면 큐브는 원시합니다. 일부는 요약 큐브가 어떤 집계가 유용한지 결정하고 해당 집계만을 생성합니다. 그 밖의 모든 경우에서 즉시 요약이 계산됩니다. 액세스 경로가 배열 기반 산술을 통과하므로 MV와 같은 관계형 테이블에 비해 큐브에서의 데이터 검색이 훨씬 빠릅니다. 큐브와 같은 OLAP 개체는 AW(Analytic Workspace)라고 하는 데이터베이스의 특수 영역에 저장됩니다. 데이터베이스에는 하나 이상의 AW가 있을 수 있으며 이러한 AW는 접두어 AW$가 붙은 특수 명명 테이블에 BLOB로 저장됩니다. Oracle Database에서 데이터 큐브는 새로운 개념이 아니지만 Oracle Database 11g 이전 버전에서는 액세스 방법이 약간 다릅니다. 따지고 보면 Oracle도 근본적으로는 관계형 데이터베이스 엔진입니다. 이 버전에서 데이터의 큐브 표시는 고유하지 않은 개념이었는데 특히 MV가 관여하는 위치가 그렇습니다 MV는 즉 사용자 쿼리가 자동으로 재작성되는 자동 쿼리 재작성, 일부 MV만 새로 고치는 증분식 새로 고침 등과 같은 몇 가지 매우 흥미로운 기능을 제공합니다입니다 이제 이 두 가지의 가장 강력한 점인 MV의 재작성 기능과 OLAP 큐브의 성능 이점을 결합한다고 상상해 보십시오. 바로 Oracle Database 11g에서 이러한 결합된 기능을 제공합니다. 아마도 이 영역에서 가장 중요한 새 기능은 큐브 구성 구체화 뷰라고 하는 새로운 기능을 통해 OLAP 큐브를 MV로 표시하는 기능일 것입니다. 새 함수인 CUBE_TABLE은 일반 SQL의 큐브를 통해 검색을 수행합니다. MV는 사실 OLAP 큐브이므로 쿼리 재작성 기능은 사용자가 알지 못하는 새 큐브를 사용하도록 쿼리를 재작성합니다. 이를 통해 SQL을 지원하는 모든 도구에서 큐브 성능을 활용할 수 있습니다. Oracle Business Intelligence Enterprise Edition, Cognos, Business Objects, Oracle Apex, SQL*Plus 또는 사용자 지정 Java 프로그램 등 무수한 프로그램이 이에 해당합니다. 사실 특수한 구문을 알 필요조차 없습니다. 큐브 구성 MV의 이름에는 간편한 식별을 위해 CB$라는 접두어가 붙습니다. 오라클의 공식 샘플 스키마를 통해 이러한 새 기능을 설명해 보겠습니다 다운로드 한 후 zip 파일의 압축을 푸십시오 SQL*Plus나 SQL Developer에서 이 스크립트를 실행하여 글로벌 스키마를 설치합니다. SYSTEM 사용자의 암호를 알아야 합니다. exit global_11g_readme.html 파일은 이 스키마에 대한 자세한 정보를 포함합니다. 또한 테스트 종료 후 스키마를 삭제하기 위한 스크립트도 들어 있습니다. 이 파일은 덤프 파일로옵니다. 예를 통해 살펴보면 큐브 구성 MV 개념을 가장 쉽게 설명할 수 있습니다. 덤프 파일에는 두 큐브가 있는데 이중 하나가 PRICE_CUBE입니다. 일반 SQL을 사용하여 해당 큐브를 쿼리하는 방법에 대해 살펴봅시다. 또한 오라클에서 따르는 액세스 경로도 살펴보기 위해 쿼리 실행에 앞서 autotrace 명령을 사용했습니다. 이러한 CUBE_TABLE 함수는 Oracle Database 11g에서 새로 제공되는 함수이며, 이 함수를 통해 AW에 저장된 큐브를 관계형 개체로 쿼리할 수 있습니L을 사용하는 경우에도 해당 큐브가 큐브로 스캔되었다는 것을 의미합니다. 이 예에서는 가장 기본적인 도구를 사용했습니다. SQL*Plus는 OLAP나 분석적 변환과는 전혀 관련이 없으나 어쨌든 분석적인 방식으로 데이터를 가져올 수 있습니다. CUBE_TABLE 함수는 테이블과 차원에 모두 사용할 수 있습니다. 일반적인 형태는 다음과 같습니다 계층 구조 부분은 선택적이므로 생략이 가능합니다. 이전에 설치한 GLOBAL 스키마 샘플을 사용합니다. 여기서는 PRODUCT라는 차원에서 PRIMARY 계층 구조를 선택하려 합니다. select * from table(cube_table('GLOBAL.PRODUCT;PRIMARY')) 각 큐브와 차원에 대해 뷰가 자동으로 생성됩니다. 에를 들어 PRICE_CUBE 큐브에 대해 PRICE_CUBE_VIEW라는 뷰가 있습니다. 뷰 정의를 살펴보면 다음과 같은 것을 확인할 수 있습니다. 뷰는 GUI 도구가 CUBE 함수에 대해 알지 못하고 일반적으로 뷰인 개체 유형을 선택하라는 메시지가 표시될 때 유용합니다. 다음은 Oracle SQL Developer를 사용하여 뷰에서 데이터를 선택하는 예입니다. SQL Developer에 뷰가 표시되며 다른 뷰와 마찬가지로 데이터 탭을 선택하고 필터링할 수 있습니다. 데이터 형식은 다차원이나 CUBE_TABLE 테이블 함수를 통해 관계형 개체로 액세스할 수 있습니다. 뒤에서 데이터베이스의 다차원 엔진은 사용자가 알지 못하게 필요한 계산(예: 집계 또는 측정값 계산)을 수행합니다. 이렇게 두 방식의 장점만 가지고 올 수 있습니다. Oracle Database에 포함된 OLAP의 강력한 기능을 활용하는 동시에 아주 간단한 SQL*Plus를 포함하여 친숙한 애플리케이션을 간편하게 활용할 수 있습니다. 일반 SQL로 큐브를 관리할 수 있으나 가장 간단한 방법은 Analytic Workspace Manager 도구를 사용하는 것입니다(향후 설명). DBA_CUBES 뷰에는 큐브에 대한 정보가 표시됩니다. 이제 큐브 구성 MV의 장점을 살펴보겠습니다. 먼저 큐브(및 큐브 구성 MV)는 큐브에 대한 분석적 액세스를 통해 요약 데이터를 요구하는 쿼리의 성능을 대폭 높일 수 있습니다. 둘째로 신속한 증분식 새로 고침을 통해 큐브 효율이 매우 높아집니다. 마지막으로 단일 큐브가 여러 MV를 대체할 수 있으므로 관리 및 설정이 훨씬 간편해집니다. 큐브 구성 MV는 간단한 메타데이터 개체입니다. 요약 데이터는 큐브에서 관리하며 큐브 구성 MV는 자동 쿼리 재작성과 자동 큐브 새로 고침을 지원합니다. 데이터는 큐브 구성 MV 내부가 아닌 큐브에 저장되므로 복제 전략이 아닙니다. 큐브와 종류가 같은 사전 구성 테이블의 MV와 유사한 것으로 생각하면 됩니다. Oracle Database의 전전 릴리스에서 소개된 쿼리 재작성 기능에 대해서는 이미 잘 알고 있을 것입니다. 요약해 보면 사용자는 MV의 정의 쿼리와 일치하는 쿼리를 작성하고 Oracle은 데이터베이스에서 쿼리를 실행하는 대신 MV로부터 선택하는 것입니다. "일치"라는 말은 저장된 MV가 쿼리의 부분적 결과 세트를 만족할 수 있거나 MV의 기존 데이터를 사용하여 쿼리 속도를 높일 수 있음을 뜻합니다니다. 이렇게 하면 데이터베이스가 기준 테이블에 액세스하는 작업과 계산 작업을 수행하지 않고 더 빠르게 사용자에게 결과를 반환할 수 있습니다. 이 모든 작업은 MV가 존재하며 쿼리를 재작성한다는 사실을 사용자가 알 필요도 없게 자동으로 발생합니다. 물론 사용자가 쿼리 내 대체와 같은 것을 허용하도록 선택해야 합니다. 세션 매개변수 query_rewrite_enabled를 TRUE로, MV의 실효에 따라 query_rewrite_integrity를 trusted나 stale_tolerated로 설정해야 합니다(이 매개변수는 커널이 제공한 데이터 무결성 실행 수준을 제어함). MV 자체도 쿼리 재작성이 가능해야 합니다. 사용자 쿼리가 MV의 정의 쿼리와 유사할 때 쿼리가 작성됩니다. 과거 버전에서는 쿼리가 유사하지 않으면 쿼리가 재작성되지 않았습니다. 그러나 Oracle Database 11 g 에서는 이 규칙이 완화되었습니다. 다음 MV를 살펴보겠습니다 여기서는 행 소스가 사실상 또 다른 쿼리인 인라인 쿼리를 사용합니다. FROM의 구문은 사실상 인라인 쿼리입니다. 동일한 인라인 뷰를 사용하여 MV의 정의 쿼리와 유사한 쿼리를 작성할 경우 쿼리가 재작성되는 것을 확인할 수 있습니다. AUTOTRACE를 사용하여 실행 경로를 확인합니다. 위에서 Id=1을 확인하십시오. 이전에 생성한 구체화된 뷰 MV4를 통해 쿼리가 재작성되었습니다. MV와 쿼리에서 인라인 뷰(또는 하위 쿼리)를 사용하는 경우에도 쿼리가 재작성됩니다 Oracle Database 11 g 의 원격 테이블에 대해서도 쿼리가 재작성됩니다 MV를 생성한 파티션된 상세 테이블이 있는 경우 PCT(Partition Change Tracking, Oracle Database 10 g 에서 도입)를 활용하여 전체 테이블이 아닌 특정 파티션에 대해서만 새로 고칠 수 있습니다. PCT 기능을 사용하면 상세 테이블에 MV 로그가 없는 경우에도 FAST 옵션으로 새로 고칠 수 있습니다. 그러있을까요 Oracle Database 11 g 에서는 DBA_MVIEW_DETAIL_PARTITION이라는 굉장한 새 뷰를 제공합니다. 이 뷰에는 업데이트된 파티션이 표시되며 향후 PCT 새로 고침에 사용됩니다. FRESHNESS 열은 해당 MV에 대해 파티션이 새로운 것인지 여부를 보여 줍니다. 다른 뷰처럼 USER_*와 ALL_* 버전이 있습니다. Oracle Database 11 g 와 함께 제공되는 CD에 있는 SH 스키마를 사용하겠습니다. 먼저 최신인지 확인해 보겠습니다. 이제 테이블에 행을 삽입합니다 이제 동일한 쿼리를 실행하여 최신 여부를 확인합니다. 행이 이동하는 파티션 SALES_Q1_1998이 이제 STALE로 나열됩니다. 이 MV를 고속으로 새로 고치면 PCT를 사용하여 전체 테이블이 아닌 해당 파티션에서만 새로 고치게 됩니다. 또한 테이블에 MV 로그가 없는 경우에도 고속 새로 고침이 수행됩니다. 이제 다음과 같이 FAST 옵션으로 MV를 새로 고칩니다. 이제 다시 최신 여부를 확인ng=10 width=550 bgColor=#ffffcc> And check the freshness again: 파티션이 FRESH라고 표시되며 이후의 고속 새로 고침에서 해당 파티션을 선택하지 않게 됩니다. 이 뷰를 사용하면 간편하게 PCT 새로 고침에서 새로 고칠 대상 파티션을 파악하고 관련 작업을 추정할 수 있습니다. 이 기능은 큐브 구성 MV에도 적용됩니다. 앞서 언급한 것처럼 OLAP 개체가 저장되는 특수 영역을 Analytic Workspace라고 합니다. OLAP 개체는 AWM(Analytic Workspace Manager)이라고 하는 특수 도구를 통해 조작하며 이 도구는 OTN의 Oracle OLAP 옵션 홈 페이지 에서 다운로드할 수 있습니다 AWM은 독립형 버전과 DBClient 등의 두 종류로 제공됩니다. 독립형 버전은 java 명령줄에서 실행할 수 있는 완전 JAR 파일입니다. DBClient에는 Oracle 홈의 적합한 디렉토리에 복사해야 하는 몇 가지 DLL이 있습니다. 이 섹션에서는 이 도구의 독립형 버전 ( 11.1.0.7A )을 살펴보겠습니다. 파일의 압축을 푼 후 압축을 푼 디렉토리로 이동하고 다음 명령을 실행하여 AWM을 시작합니다. GUI가 열리면 File -> Connect Database 를 클릭하고 연결 대상 데이터베이스를 선택합니다. 사용자 이름을 GLOBAL 로 선택합니다. 데이터베이스에 연결되면 Schemas 앞의 더하기(+) 기호를 클릭하고 모든 요소를 펼칩니다. 결과 화면은 다음과 같습니다. 일반 작업인 큐브 새로 고침을 수행해 보겠습니다. 왼쪽 패널의 PRICE_CUBE 를 마우스 오른쪽 버튼으로 클릭합니다. 다음과 같이 팝업 메뉴가 표시됩니다. 메뉴에서 Maintain Cube PRICE_CUBE 를 선택합니다. 그러면 다음과 같이 작은 창이 열립니다. Next 를 몇 번 클릭하면 다음과 유사한 화면이 표시될 것입니다. 여기서 작업을 즉시 실행할지 또는 나중으로 예약할지 결정할 수 있습니다. Finish 를 눌러 작업을 완료합니다. 그러면 다음과 같은 확인 화면이 표시됩니다. SQL 문을 표시하는 OUTPUT이라는 이름의 열을 확인합니다. 이 열을 두 번 클릭하면 전체 출력이 표시됩니다. PRICE_CUBE에 대한 출력은 다음과 같습니다 다른 중요 작업은 큐브에서 MV를 만드는 것입니다. UNITS_CUBE 큐브에 대해 이 작업을 어떻게 수행하는지 살펴보겠습니다. UNITS_CUBE 를 클릭합니다. 그러면 오른쪽 패널에 해당 큐브의 상세내역이 표시됩니다. 상세 패널에는 몇 가지 탭이 있습니다. 다음과 같이 Materialized Views 탭을 클릭합니다. 이 패널은 큐브를 MV로 저장하기 위해 필요한 다양한 확인 항목을 표시합니다. 예를 들어 첫 번째 줄은 "User must have create Materialized View Privilege"인데 말 그대로입니다. 즉 사용자가 MV를 생성하려면 MV 생성 권한이 필요하다는 뜻입니다. 이 확인을 수행했고 사용자에게 권한이 있음을 확인했습니다. 상태가 녹색 막대 표시로 나타나 이 조건이 충족되었음을 표시합니다. 패널의 왼쪽 위 가장자리에서 다음을 확인하십시오. 큐브의 MV 스타일 새로 고침을 사용하려면 이 상자를 선택합니다. 그런 다음 아래쪽의 Enable Query Rewrite 확인란을 선택합니다. 다음으로 Apply 버튼을 누릅니다. 이제 큐브가 큐브 구성 MV로 준비되었습니다 큐브가 정규 MV가 되었으므로 MV로 새로 고칠 수 있습니다. 또한 큐브 재구성 접근도 사용할 수 있습니다: 앞서 언급한 것처럼 AW는 데이터베이스에 BLOB로 저장됩니다. 다음 예를 살펴봅시다 여기서 BLOB 열에는 큐브에 대한 데이터가 있습니다. 따라서 큐브는 다른 테이블과 마찬가지로 테이블 스페이스의 관계형 테이블에 저장됩니다. 이 스페이스는 다른 테이블 스페이스와 마찬가지로 테이블 스페이스에서 관리되므로 DBA가 초기 AW 생성 후 아무 작업도 수행할 필요가 없습니다. 큐브 구성 MV는 다른 MV와 같으므로 새로 고침 프로세스도 대부분의 DBA에게 익숙한 것입니다. Oracle Database 11g에는 데이터 웨어하우스의 효율적인 설계와 운용을 지원하는 몇 가지 다른 새로운 기능이 있습니다. 이에 대해서는 이 시리즈의 기타 부분에서 이미 다루었습니다. 따라서 여기에서는 이를 반복하지 않고 간략하게 개요만 설명합니다. 자세한 내용은 해당 글을 참조하시기 바랍니다. 파티셔닝 . Oracle Database 11 g 에서는 Interval Partitioning이라고 하는 새로운 유형의 범위 파티셔닝을 제공합니다. 이 기능을 사용하면 값을 간격으로 정의하기만 하면 됩니다. 예를 들어 Oracle은 삽입된 레코드를 기준으로 매월 필요에 따라 자동으로 파티션을 생성합니다. 다른 유형인 Reference Partitioning에서는 하위 테이블이 아니라 상위 테이블에만 있는 열을 기준으로 하위 테이블에 파티션을 생성합니다. 에를 들어 EMP 테이블이 아니라 상위 테이블(DEPT)에 있는 부서 위치를 기준으로 EMP 테이블을 파티셔닝할 수 있습니다. 또한 LIST-LIST, LIST-RANGE와 RANGE-RANGE 복합 파티셔닝 스키마를 생성할 수 있습니다. 가상 열 뿐만 아니라 열을 "가상화"할 수 있습니다. 즉 열이 테이블에 아직 저장되지 않았지만 사용자가 다른 열과 마찬가지로 액세스할 수 있게 됩니다. 이 열 값은 실시간으로 계산됩니다. 예를 들어 SALARY 열의 20% 커미션을 보여 주는 COMMISSION이라고 하는 가상 열을 테이블에 정의할 수 있습니다. 이 열에 대한 인덱스를 정의하고 나아가 이에 대해 파티셔닝할 수 있습니다. 데이터베이스도 일반 열에 하는 것과 마찬가지로 가상 열에 대한 통계 수집을 시작합니다. 데이터 웨어하우스에서는 가상 열을 사용하여 테이블을 파티셔닝함으로써 실제 열 대신 실제 상황을 반영하여 프로세스 중 상당한 공간을 절감할 수 있습니다. 파티션을 다른 테이블과 교환하면 교환한 테이블에는 가상 열이 필요하지 않습니다. 정말 멋진 기능이 아닐 수 없습니다. 고급 압축었던 압축 기능 외에도 다른 방식의 압축을 수행하는 새로운 고급 압축 옵션을 제공합니다. 행을 그대로 압축하는 대신 블록에서 특정 임계값에 도달하면 전체 블록을 압축합니다. 이렇게 하면 프로세스 효율성이 대폭 향상되고 상당한 공간 혜택을 누릴 수 있습니다. 피벗(및 피벗 해제) . 모든 보고 환경에서 교차탭 보고서가 상당히 널리 사용되고 있습니다. 무엇보다도 이 보고서 형식이 판독과 데이터 표현이 가장 간단하기 때문입니다. 이전 릴리스에서는 존재하는 열 수와 동일하게 테이블을 보고서 자체에 연결함으로써 교차탭 보고서를 만들 수 있었습니다. 이로 이해 다소 성능이 떨어지는 쿼리가 생성되었는데 특히 일반적으로 테이블이 큰 데이터 웨어하우스에서 그랬습니다. Oracle Database 11 g 에서는 PIVOT이라고 하는 새로운 연산자가 출력을 교차탭 형식으로 표시하도록 변환합니다. UNPIVOT은 이미 해당 형식으로 된 데이터를 다시 관계형 형식으로 재설정합니다. Partition Advisor . 파티셔닝에서 고려해야 할 핵심 사항 중 하나는 파티션 기반 열입니다. 경험 많은 전문가를 포함하여 많은 사람들이 이 점에서 당황합니다. Oracle Database 11g에서는 Partition Advisor라는 새 도구를 통해 이 프로세스를 간편하게 했습니다. 이 도구는 부하 패턴을 분석하고 파티션 스키마에 대해 성능 기반 제안을 제공합니다. 100% 완벽한 것은 아니지만 이 프로세스를 전혀 알지 못하는 사용자에게는 큰 혜택을 제공합니다. 또한 전문가에게도 최소한 출발점은 될 수 있습니다. 데이터 캐싱 . 데이터가 자주 변경되지 않는다면 왜 디스크에서 계속 데이터를 새로 고쳐야 할까요 Oracle Database 11g에서는 Result Cache라고 하는 특수 메모리 풀에 쿼리 결과(테이블 아님)를 캐시할 수 있습니다. 테이블 데이터가 변경되면 캐시가 자동으로 업데이트됩니다. 메모리 내의 자체적으로 새로 고쳐지는 구체화된 뷰와 유사합니다. 또한 이 결과 캐시에 PL/SQL 함수의 결과를 캐시할 수 있습니다. 디스크가 아닌 메모리에서 결과가 나오므로 응답 시간이 획기적으로 빨라집니다. 상당한 조회 쿼리의 대상 테이블이 크게 변경되지 않는 데이터 웨어하우스 같은 대용량 데이터베이스에서는 쿼리와 함수 호출을 캐시하여 성능을 향상시킬 수 있습니다. 보이지 않는 인덱스 . 인덱스를 보이지 않게 할 수 있습니다. 즉 특수 세션 매개변수를 설정하지 않는 한 액세스 경로에 사용되지 않게 할 수 있습니다. 그러나 인덱스가 일반 인덱스처럼 유지 관리되므로 DML 성능에는 영향이 있습니다. 이는 인덱스를 실행하지 않고 인덱스의 영향을 조사하는 완벽한 방법입니다. 성능이 많이 떨어지는 경우 인덱스를 삭제할 수 있습니다.데이터 웨어하우징 및 OLAP
데이터 웨어하우징 및 OLAP
간략한 개요
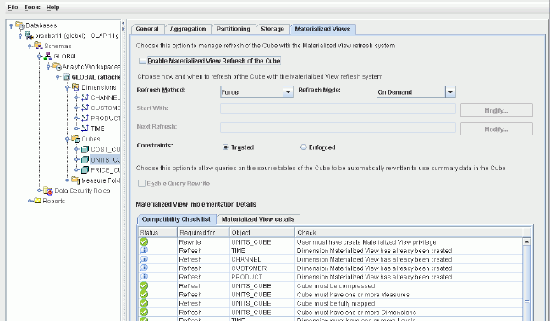
큐브 구성 구체화 뷰
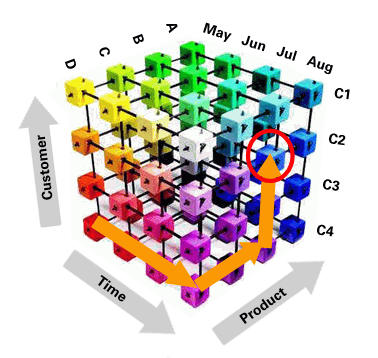
Dimension Customer := {'Microsoft','IBM','Oracle','HP'}
Dimension Product := {'Fiber','Cat6e','Cat5e','Serial'}
2. Cat5e는 Product 배열의 3번째 요소이므로 3번째 요소로 이동합니다.
3. Oracle은 Customer 배열의 3번째 요소이므로 3번째 요소로 이동합니다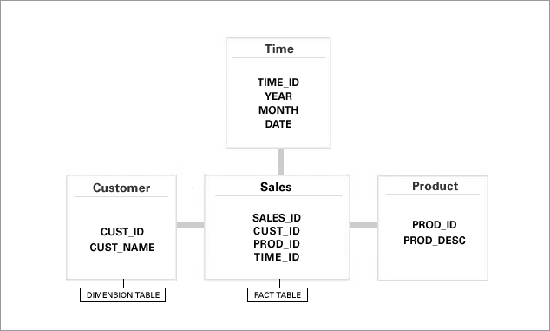
* 같은 제품 및 월에서, 8월 직렬 케이블에 대해 오라클 매출 대비 IBM 매출
* HP의 섬유 케이블 매출 대비 Microsoft의 직렬 케이블 매출
Archive: global_11g_schema.zip
inflating: global_11g_remove.sql
inflating: global_11g_source.dmp
inflating: Templates/CHANNEL.XML
inflating: Templates/CUSTOMER.XML
inflating: Templates/GLOBAL.XML
inflating: Templates/GLOBAL_MV.XML
inflating: Templates/PRICE_CUBE.XML
inflating: Templates/PRODUCT.XML
inflating: Templates/TIME.XML
inflating: Templates/UNITS_CUBE.XML
inflating: global_11g_install.sql
inflating: global_11g_readme.html
Enter the password for the user GLOBAL:
Enter the password for the user SYSTEM:
Connected.User created.
Grant succeeded.Connected.Import: Release 11.1.0.6.0 - Production on Sat Jun 28 17:08:22 2008Copyright (c) 1982, 2007, Oracle. All rights reserved.Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production
With the Partitioning, Oracle Label Security, OLAP, Data Mining,
Oracle Database Vault and Real Application Testing optionsExport file created by EXPORT:V11.01.00 via conventional path
import done in US7ASCII character set and AL16UTF16 NCHAR character set
import server uses WE8MSWIN1252 character set (possible charset conversion)
export client uses WE8MSWIN1252 character set (possible charset conversion)
. importing GLOBAL's objects into GLOBAL
. . importing table "ACCOUNT" 24 rows imported
. . importing table "CHANNEL_DIM" 3 rows imported
. . importing table "CUSTOMER_DIM" 61 rows imported
. . importing table "PRICE_FACT" 2523 rows imported
. . importing table "PRODUCT_CHILD_PARENT" 48 rows imported
. . importing table "PRODUCT_DIM" 36 rows imported
. . importing table "TIME_DIM" 120 rows imported
. . importing table "UNITS_FACT" 299446 rows imported
About to enable constraints...
Import terminated successfully without warnings.SQL> exit
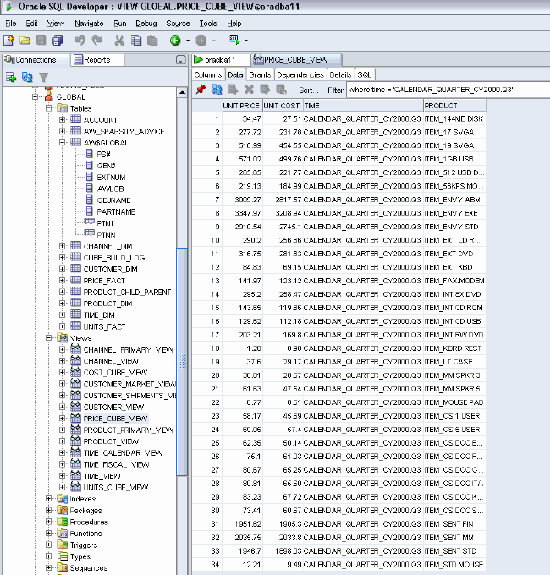
SQL> select * from table(cube_table('GLOBAL.PRICE_CUBE'))
2> /...
... the data comes here ...
... Execution Plan
----------------------------------------------------------
Plan hash value: 3184667476--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2000 | 195K| 29 (0)| 00:00:01 |
| 1 | CUBE SCAN PARTIAL OUTER| PRICE_CUBE | 2000 | 195K| 29 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
SELECT
"UNIT_PRICE",
"UNIT_COST",
"TIME",
"PRODUCT"
FROM TABLE(CUBE_TABLE('GLOBAL.PRICE_CUBE') )
쿼리 재작성 빈도 증가
enable query rewrite
as
select prod_id, cust_id, avg (rate) tot_qty
from (select s.prod_id, cust_id, amount_sold / quantity_sold rate
from sales s, products p
where s.prod_id = p.prod_id) sq
group by prod_id, cust_id/
SQL> set autotrace traceonly explain
SQL> select pid, cid, avg(item_rate) avg_item_rate
2 from (select s.prod_id pid, cust_id cid, amount_sold/quantity_sold item_rate
3 from sales s, products p
4 where p.prod_id = s.prod_id)
5 group by cid, pid;Execution Plan
----------------------------------------------------------
Plan hash value: 3944983699-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 287K| 10M| 226 (2)| 00:00:03 |
| 1 | MAT_VIEW REWRITE ACCESS FULL| MV4 | 287K| 10M| 226 (2)| 00:00:03 |
-------------------------------------------------------------------------------------Note
-----
- dynamic sampling used for this statement
파티션에서의 실효 확인
2> from user_mview_detail_partition
3> where MVIEW_NAME = 'MV1';DETAILOBJ_NAME DETAIL_PARTITION_NAME DETAIL_PARTITION_POSITION FRESH
------------------------------ ------------------------------ ------------------------- -----
SALES SALES_1995 1 FRESH
SALES SALES_1996 2 FRESH
SALES SALES_H1_1997 3 FRESH
SALES SALES_H2_1997 4 FRESH
SALES SALES_Q1_1998 5 FRESH
SALES SALES_Q2_1998 6 FRESH
SALES SALES_Q3_1998 7 FRESH
SALES SALES_Q4_1998 8 FRESH
SALES SALES_Q1_1999 9 FRESH
SALES SALES_Q2_1999 10 FRESH
SALES SALES_Q3_1999 11 FRESH
SALES SALES_Q4_1999 12 FRESH
SALES SALES_Q1_2000 13 FRESH
SALES SALES_Q2_2000 14 FRESH
SALES SALES_Q3_2000 15 FRESH
SALES SALES_Q4_2000 16 FRESH
SALES SALES_Q1_2001 17 FRESH
SALES SALES_Q2_2001 18 FRESH
SALES SALES_Q3_2001 19 FRESH
SALES SALES_Q4_2001 20 FRESH
SALES SALES_Q1_2002 21 FRESH
SALES SALES_Q2_2002 22 FRESH
SALES SALES_Q3_2002 23 FRESH
SALES SALES_Q4_2002 24 FRESH
SALES SALES_Q1_2003 25 FRESH
SALES SALES_Q2_2003 26 FRESH
SALES SALES_Q3_2003 27 FRESH
SALES SALES_Q4_2003 28 FRESH
------------------------------ ------------------------------ ------------------------- -----
SALES SALES_1995 1 FRESH
SALES SALES_1996 2 FRESH
SALES SALES_H1_1997 3 FRESH
SALES SALES_H2_1997 4 FRESH SALES
SALES_Q1_1998 5 STALE
SALES SALES_Q2_1998 6 FRESH
... and so on ...
DETAILOBJ_NAME DETAIL_PARTITION_NAME DETAIL_PARTITION_POSITION FRESH
------------------------------ ------------------------------ ------------------------- -----
SALES SALES_1995 1 FRESH
SALES SALES_1996 2 FRESH
SALES SALES_H1_1997 3 FRESH
SALES SALES_H2_1997 4 FRESH
SALES SALES_Q1_1998 5 FRESH
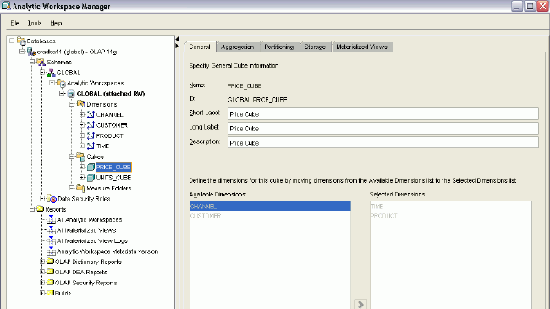
SALES SALES_Q2_1998 6 FRESHAnalytic Workspace Manager
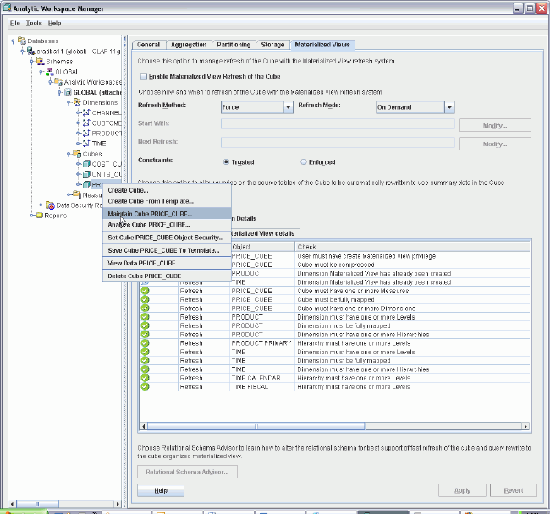
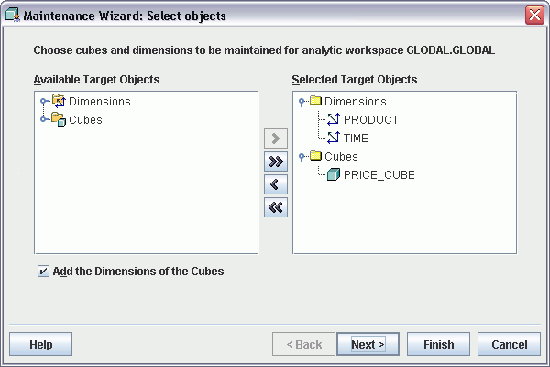
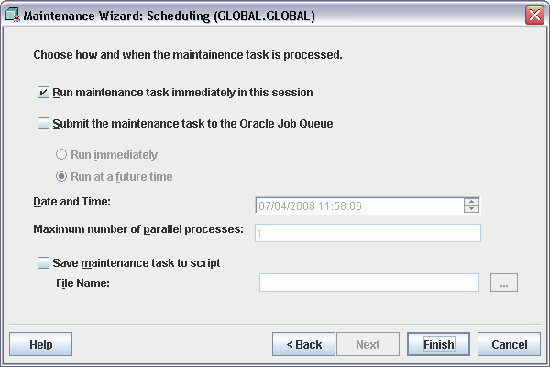
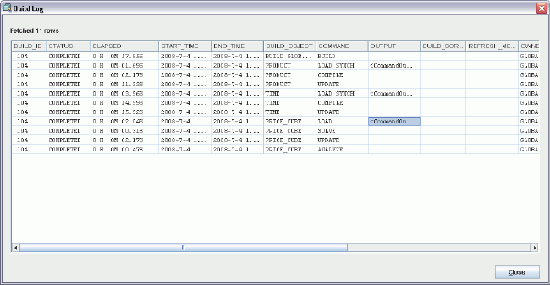
SQL="SELECT /*+ bypass_recursive_check cursor_sharing_exact no_expand */
T16_MONTH_ID ALIAS_114,
T13_ITEM_ID ALIAS_115,
SUM(T19_UNIT_PRICE) ALIAS_116,
SUM(T19_UNIT_COST) ALIAS_117
FROM
(
SELECT
T1.ITEM_ID T19_ITEM_ID,
T1.MONTH_ID T19_MONTH_ID,
T1.UNIT_PRICE T19_UNIT_PRICE,
T1.UNIT_COST T19_UNIT_COST
FROM
GLOBAL.PRICE_FACT T1 )
T19,
(
SELECT
T1.MONTH_ID T16_MONTH_ID
FROM
GLOBAL.TIME_DIM T1 )
T16,
(
SELECT
T1.ITEM_ID T13_ITEM_ID
FROM
GLOBAL.PRODUCT_DIM T1 )
T13
WHERE
((T16_MONTH_ID = T19_MONTH_ID)
AND (T13_ITEM_ID = T19_ITEM_ID)
AND (T16_MONTH_ID = T19_MONTH_ID)
AND (T13_ITEM_ID = T19_ITEM_ID) )
GROUP BY
(T13_ITEM_ID, T16_MONTH_ID)
ORDER BY
T13_ITEM_ID ASC NULLS LAST ,
T16_MONTH_ID ASC NULLS LAST "
LOADED="2523"
REJECTED="0"/>
![]()
dbms_mview.refresh (
list => 'CB$PRICE_CUBE',
method => 'c'
);
end;
dbms_cube.build('PRICE_CUBE');
end;After populating (or rebuilding), you should collect stats:begin
dbms_aw_stats.analyze (
'PRICE_CUBE'
)
end;
Name Null Type
----------------------------------------- -------- -----------------------
PS# NUMBER(10)
GEN# NUMBER(10)
EXTNUM NUMBER(8)
AWLOB BLOB
OBJNAME VARCHAR2(256)
PARTNAME VARCHAR2(256)
다른 글에서 다루는 기타 새로운 기능