
데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
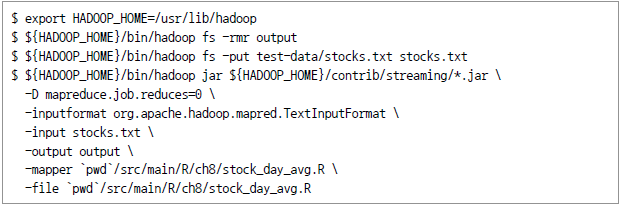
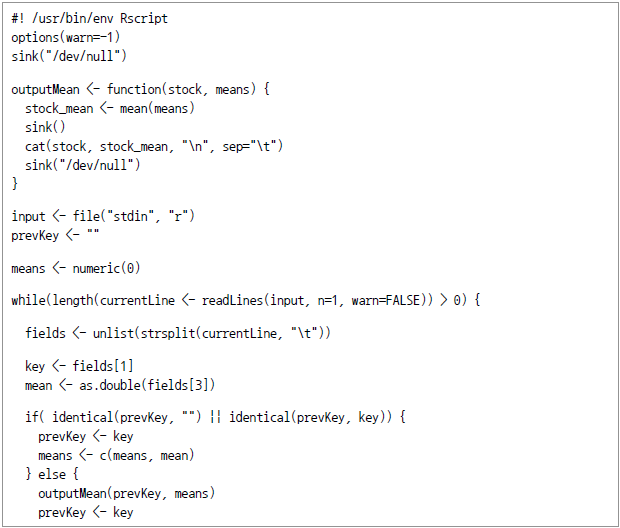
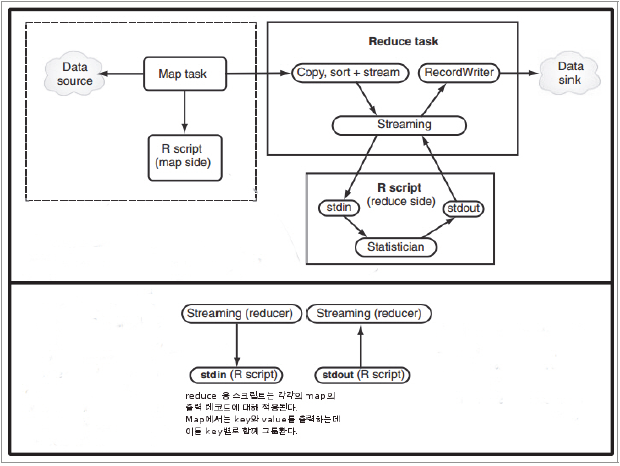
아파치 하둡은 대용량 데이터20)의 효율적 분산처리를 위한 프레임워크다. 메인메모리를 최대한 활용하는 방식으로 수행되는 분석도구인 R과 하둡은 어떻게 관련되며 R의 입장에서 하둡의 파워를 어떻게 효과적으로 활용할 수 있는가에 관심이 모아진다. 실제로 빅데이터 분석이라는 측면에서는 R과 하둡이 기능상 상호보완적이므로 다양한 방식으로 이용되고 있다.21) 이를 구체적으로 살펴보면 다음과 같다. 일반 Unix나 Linux에서 제시하는 스트리밍 방법을 통해 자바 이외의 언어를 map과 reduce 작업에 적용할 수 있다. 다음 페이지에서 자세히 살펴본다. HadoopStreaming22)은 데이비드 로젠버그(David Rosenberg)가 개발한 R 패키지다. 이름이 위의 하둡 스트리밍과 같은 Hadoop streaming이지만, 일반적인 프로그래밍 기법으로서의 스트리밍과는 구별돼야 한다. 이 패키지에서는 하둡의 스트리밍에 이용할 수 있도록 R의 map/reduce 스크립트 프로그램을 만들어서 제공하고 있다. Oracle R Connector for Hadoop(ORCH)를 통해 R에서 하둡 클러스터를 액세스해 HDFS에 저장된 데이터에 대해 맵리듀스 작업을 수행할 수 있다. 개념적으로는 맵리듀스는 R의 apply 명령과 유사하다. 즉 list 또는 테이블의 지정된 그룹 또는 개별 항목에 대해 필요한 변형작업을 수행한다. RHIPE(R and Hadoop Integrated Programming Environment)는 R 사용자에게 맵리듀스 작업을 만들도록 도와주는 소프트웨어 패키지다. 원래 RHIPE는 D&R(divide and recombine)이라는 분석기법으로 복잡한 데이터를 부분(subset)으로 나눠 각각에 대해 수치(numeric) 내지 시각화 방식을 적용하고, 나중에 결과를 재조합(recombine)하는 방식으로 맵리듀스(MR) 작업을 한다. 그런데 이때의 맵리듀스 작업은 R 수식을 사용함과 동시에 완벽하게 R 환경 내에서 수행된다는 점에서 맵리듀스에 대한 중요한 변경요인이 되고 있다. Map과 Reduce 함수로 기능구분을 신속하게 하면서도 인터프리터 언어인 R의 대화식 환경을 유지하고 R의 강력한 분석기능을 그대로 이용할 수 있기 때문이다. RHadoop은 본격적으로 하둡 플랫폼 위에서 R 프로그램을 수행시키는 것으로서 미국의 Revolution Analytics사가 개발한 제품이다. 대표적으로 많이 사용되는 streaming 방식과 RHadoop에 대해 좀 더 자세히 살펴 보자. 여기서는 많은 주식종목 중에서 특정 종목의 일 평균가격을 계산하는 작업을 Hadoop streaming을 통해 R 스크립트로 실행하는 것을 살펴 본다.23) 우선 이 예제에서는 다음과 같은 형식의 텍스트 데이터를 이용하기로 한다. 실제 데이터의 모습은 다음과 같다. 우선 단순 평균집계이므로 Map 함수만 적용하면 되는데 이에 대한 R 스크립트는 다음과 같다. 그리고 이 스크립트의 수행결과는 다음과 같다. 이제 다음 작업을 통해 입출력을 지정하고 하둡 작업을 수행시킨다. 주식에 대해 이동평균가를 계산해 한 종목씩 출력을 하는 R 스크립트는 다음과 같다. 당초 map용 R 스크립트에서는 구분자를 탭으로 하는 다음의 세 개 필드를 출력했다. 맵리듀스는 이들을 정렬하고 map 스크립트의 출력키(주식 부호)별로 그룹화하였다. 고유한 부호(symbol)마다 맵리듀스는 reduce용 R 프로그램을 적용해 해당되는 map 출력값을 만들어 낸다. 이후 R 스크립트에서는 평균값을 모두 합해 누적이동평균(CMA, cumulative moving average)에 대한 출력을 발생시켰다. 이상의 수행방식을 그림으로 표현하면 [그림 Ⅳ-2-18]과 같다. [그림 Ⅳ-2-18] Hadoop Streaming 방식으로 맵리듀스에 R을 적용하는 모습 RHadoop을 이용하기 위해서는 Linux를 이용할 것을 권한다. RHadoop을 이용해야 하기 때문인데 주로 Linux를 이용하는 것이 일반적이기 때문이다. RHadoop 패키지가 요구하는 몇 가지 패키지를 설치한다. dependency를 가진 것이므로 특정 사용자를 대상으로 하기보다 시스템 전체를 대상으로 설치해야 한다. 다시 말하면 특정 사용자의 폴더하에 두기보다는 공용 라이브러리에 설치돼야 한다 이처럼 특정 위치를 지정해 패키지 설치하는 방법은 RStudio에서의 GUI를 이용할 수도 있고 install.packages() 명령에서 lib이라는 argument를 이용하면 된다. 다음 명령어를 참고하자. 위 작업은 Linux에서의 일반적인 환경변수 export와 동일한 효과를 가진다. 즉 다음 명령어를 적용해도 위의 R 명령어 수행과 동일한 효과를 낼 수 있다. https://github.com/RevolutionAnalytics/RHadoop/wiki/Downloads로부터 rhdfs, rhbase, rmr2 및 plyrmr 등의 패키지를 다운로드하고 다음과 같이 설치한다. 앞에서와 마찬가지로 특정 사용자에 국한되지 않도록 시스템 디렉터리를 이용하도록 한다. rmr2 패키지를 이용하면 데이터 자체를 하둡으로 복제해 오거나 HDFS 내에 저장된 데이터를 R환경으로 옮길 수 있다. 뿐만 아니라 R 환경 내에서 맵리듀스 작업을 작성해 실행할 수도 있다. 이러한 작업 중 특히 맵리듀스 작업을 위해서 핵심이 되는 것이 “mapreduce” 함수다. 이 함수의 형태 (signature)는 다음과 같다. 여기서 input 및 output 인자는 HDFS 데이터의 입력 및 출력경로(path)를 의미한다. 즉 '/data/test/input.csv' 내지 '/data/test/output.csv'의 형태다. 한편 input.format과 output.format 인자는 파일의 확장자(예: csv)를 의미한다. 이하는 가장 기본적인 예제로서 단어빈도수를 알아보는 word count 예제를 R로 구현하는 예다. 텍스트파일은 wordcount/data에 있다고 가정하고 우선 텍스트 파일을 HDFS의 wordcount/data. 디렉토리로 복사해 놓는다. 다음 작업을 R 명령어로 수행한다. 결론적으로 rmr2 패키지의 장점은 하둡 프레임워크와 하둡 에코시스템에서 R 코드를 이용해 맵리듀스 프로그래밍이 가능하다는 것이다. 특히 R 환경과 잘 통합돼 R 이용이 매우 유연하며, 다양한 R 패키지도 함께 이용할 수 있게 된다.R에서의 맵리듀스 구현
개요
하둡 스트리밍
HadoopStreaming
ORCH
ORCH에서 맵리듀스 작업의 특징은 단일 프로세스를 멀티 코어, 멀티 프로세스, 노드, 클러스터간의 병렬 프로세스로 확장한다는 데 있다고 할 수 있다.
ORCH는 오라클사의 빅데이터 어플라이언스 또는 비오라클 계열의 하둡 클러스터에도 적용할 수 있다. R 사용자는 mapper 및 reducer 함수를 R로 작성한 후 R 내에서 high level의 인터페이스를 통해 맵리듀스 작업을 수행할 수 있다. 자바를 새로 배우지 않고도 또한 클러스터 구성환경에 대해 학습하지 않고도 고급(high level) 인터페이스를 활용할 수 있게 된 것이다. 게다가 R의 각종 기능을 mapper 함수 및 reducer 함수에 적용할 수도 있다. 즉 ORCH를 통해 R 사용자는 자신의 맵리듀스 프로그램을 로컬 환경에서 테스트한 후 그대로 하둡 클러스터에 적용할 수 있다.
RHIPE
RHadoop
R과 하둡을 스트리밍으로 연결해 사용하는 방법




RHadoop 이용
설치
우선 하둡은 아파치 사이트(http://hadoop.apache.org)에서 직접 다운로드해 설치하거나 클라우데라(Cloudera), 호튼웍스(Hortonworks) 등의 별도 배포판을 이용하게 된다. 일반 Windows PC에서도 VMware나 VirtualBox 등의 가상머신을 이용해 Linux를 충분히 설치가 가능하다(단, VM에 RAM을 최소 8GB 이상 배정할 것을 권장). 그러나 여기서는 하둡의 구체적인 설치과정은 생략한다. 아울러 R 또는 RStudio도 이미 설치돼 있다고 가정한다.
이제 RHadoop을 설치하자. RHadoop은 rhdfs, rhbase, rmr2 및 plyrmr로 구성돼 있으며, 될 수 있으면 Linux에서 설치하는 것이 좋다. 그 이유는 하둡 플랫폼이 Linux에서 가장 자연스럽게 설치ㆍ운용되기 때문이다. 이하에서는 Linux 환경을 전제로 하되 일부 MS Windows에서 필요한 사항에 대해 보충 설명하는 방식으로 진행한다.
관련된 R 패키지의 설치
(예: /Library/Frameworks/R.framework/Versions/3.1/Resources/library/functional,)
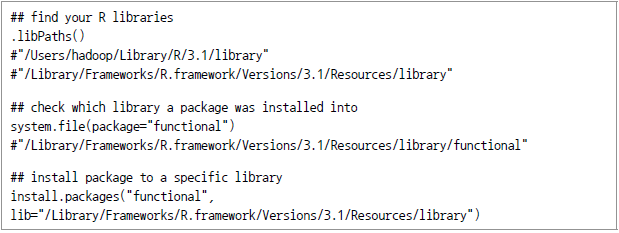
HADOOP_CMD 및 HADOOP_STREAMING과 관련된 환경변수 설정


RHadoop 패키지 설치

하둡 프레임워크 위에서 R 작업
개요
![]()
map과 reduce 인자는 각각 R 코드로 작성된 MapReduce 알고리즘의 두 단계를 의미한다. HDFS와 MapReduce는 모두 key/value pair라는 형태로 운용되기 때문에 MapReduce 단계에서의 입출력 또한 그러한 구조를 따라야 한다. Rmr2 에서는 “keyval” 함수를 제공하는데 여기서는 matrix와 array에서 시작되는 key/value pair를 출력하게 된다.
HDFS 파일에 대해 보자면 rmr2는 “csv”와 “json” 등과 같은 다양한 형태의 파일을 지원하지만, 가장 안전한 방법은 입력파일이 어떤 것이든 본래(“native”)의 포맷인 KVP 형태로 변형시켜 작업하는 것이다. 예컨대 CSV와 같은 경우 key를 갖지 않기 때문에 맵리듀스의 알고리즘을 구현하기 위해서는 별도의 작업이 필요하게 될 것이기 때문이다.
rmr2은 필요 시 언제든지 map 또는 reduce task과정에서 이용할 수 있도록 모든 메모리 상의 데이터를 job 명령과 함께 자동 전송한다.
사실 메모리 상의 데이터와 HDFS 데이터를 연결시켜주는 것은 from.dfs와 to.dfs라는 두 함수인데 이를 이용해 데이터 전송 내지 동기화를 상당부분 커스터마이즈할 수도 있다.
다시 돌아와서 rmr2 패키지의 핵심은 mapreduce()로서 이를 통해 독자적인(custom) 맵리듀스 알고리즘을 구현할 수 있지만, 실제 중요한 것은 map()과 reduce() 함수라고 할 수 있다. 이 두 함수는 모두 R로 구현돼 있으며, Key/Value 형태의 데이터를 입력 받고 출력하는 기능을 한다.
rmr2에는 keyval() 함수가 있어서 출력 key와 value로부터 리스트(list)를 생성시켜 준다. map() 또는 reduce() 함수의 기본 구조는 다음과 같다.
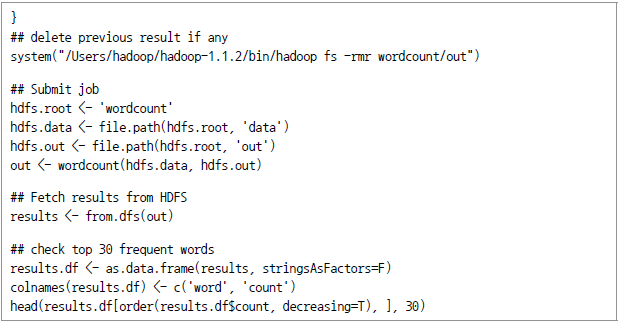
단어빈도 (word count) 예제


rmr2의 장단점
단점으로는 맵리듀스 패러다임에 대한 심도 있는 이해가 필요하다는 것과 코딩 양이 적지 않게 된다는 점을 들 수 있다. 이는 보통 분석 알고리즘에 집중해 코딩에 익숙지 않은 분석가에게는 부담으로 작용할 수도 있다. 따라서 단순한 사례부터 점진적으로 적응하면서 필요한 알고리즘을 커스터마이즈하는 것이 필요하다. 특히 다양한 기계학습 알고리즘에 대해서는 그 알고리즘 자체의 특성에 대한 이해가 충분히 돼야 이를 분해해 map과 reduce로 나누어 수행할 수 있고 그 효과도 볼 수 있을 것이다.