
데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
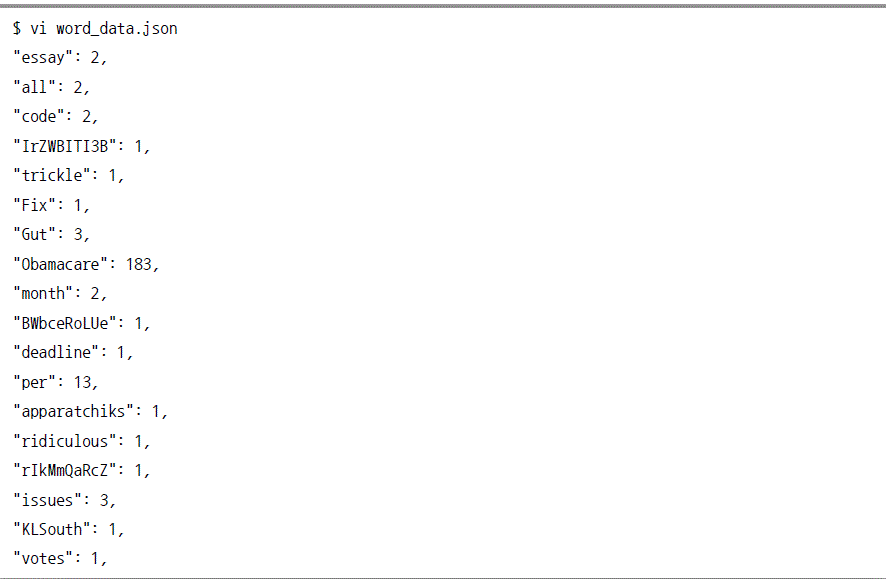
데이터 수집에서 로그 데이터, 관계형 데이터베이스의 데이터, 웹에 존재하는 데이터의 수집방법에 대해 알아보았다. 마지막으로 소셜 네트워크 서비스의 twitter API를 사용해 데이터를 수집하는 방법을 알아 본다. 먼저 이번 단락에서 소개할 내용의 개괄적인 그림은 다음과 같다. [그림 Ⅰ-2-16] 트위터 수집 처리과정 트위터 API를 사용하기 위해서는 트위터 개발자 사이트에 등록하고 접근하기 위한 정보를 생성해야 한다. 트위터 계정이 있다면 별도로 만들 필요는 없다. [그림 Ⅰ-2-17] 트위터 계정 생성 화면 계정을 생성하였다면 트위터 개발자 사이트(https://apps.twitter.com )에 접근해서 API를 사용할 수 있는 정보를 생성한다. [그림 Ⅰ-2-18] 트위터 앱 개발 관리화면 [그림 Ⅰ-2-19] 트위터 앱개발 관리화면 계정을 생성하였다면 트위터 개발자 사이트(https://apps.twitter.com )에 접근해서 API를 사용할 수 있는 정보를 생성한다. [그림 Ⅰ-2-20] 트위터 앱개발 정보 입력화면 [그림 Ⅰ-2-21] 트위터 앱개발 정보 입력화면 입력이 끝났으면 “Create your Twitter application” 버튼을 클릭해 애플리케이션 계정 정보를 발급 받을 수 있는 애플리케이션 관리화면으로 이동한다. 트위터용 Application을 생성했으면, 이 App에 접근할 계정 정보를 생성해준다. 생성정보는 다음과 같이 4종류다. [그림 Ⅰ-2-22] 컨슈머키 확인화면 애플리케이션 정보 화면으로 이동하면 consumer key와 consumer secret key가 발급됐다. 해당정보는 ‘Test OAuth’ 버튼을 클릭하면 확인할 수 있다. 화면의 세 번째 탭인 ‘Keys and Access Tokens’를 클릭해 Access Token과 Access Token secret키를 발급 받으면 트위터 데이터를 수집하기 위한 모든 키 발급이 끝난다. [그림 Ⅰ-2-23] 액세스 토큰 발급화면 Token 관련 키를 생성하기 위해 화면에서 ‘Create my access token’을 클릭한다. 에러 메시지가 없었다면 키가 생성됐을 것이다. 화면 우측 상단의 ‘Test OAuth’ 버튼을 클릭하면 다음 화면이 나타나며 4가지 api 키가 다음과 같이 화면에 출력될 것이다. [그림 Ⅰ-2-24] API 계정정보 확인 화면 트위터 API를 통해 데이터 소스를 가져오는 방법은 여러 가지가 있으나, 여기서는 twitter4j를 사용해 플룸의 소스를 개발하고, 필요한 키워드를 읽어오는 방법을 사용한다. 플룸의 소스는 ‘AbstractSource’ 클래스를 상속받고 ‘EventDrivenSource’와 ‘Configurable’을 구현해 작성한다. 그리고 ‘Configure’, ‘start’, ‘stop’ 메소드를 구현(override)하면 된다. 트위터 API에 접속하기 위한 정보나 플룸 셋업에 필요한 정보를 읽어들이는 함수다. 여기서는 API 접속에 필요한 정보를 플룸 작업 정보에서 읽어오게 하였다. 그리고 트위터의 모든 스트림을 읽어오는 대신에 관심 있는 정보(keyword)만을 가지고 오도록 만들었다. 플룸 에이전트가 트위터에 접속하고 스트림을 가져올 수 있도록 twitter4j의 StatusListener를 내부 클래스로 먼저 생성한다. StatusListener는 json형태로 트위터에서 정보를 가지고 온다. StatusListener 클래스를 작성했으면, 이것을 ‘tweeterstream’ 클래스의 ‘addListener’를 사용해 추가한다. 그리고 트위터 접속용으로 생성한 계정정보(consumer, token)를 setOAuthConsumer 메소드와 ‘AccessToken’ 클래스를 사용해 등록한다. 플룸 에이전트를 중지할 때 사용할 메소드를 개발한다. 트위터 스트림을 종료하도록 한다. 다른 일반적인 플룸 잡 컨피그레이션과 같이 데이터 소스와 싱크를 지정해준다. 개발한 플룸소스를 사용하는것이 일반적인 경우와 다를뿐이다. 여기 예제에서는 트위터에서 정보를 읽어들여서 하둡에 저장하도록 설정하였다. 위의 컨피그레이션을 사용해 플룸 잡을 시작한다. 플룸 트위터 소스를 통해서 하둡에 데이터를 수집하기 시작했으면 이젠 하이브에서 간단한 쿼리를 통해서 데이터 분석을 하도록 한다. 데이터 분석을 바로 시작하기 전에 플룹 작업이 쌓은 데이터를 확인한다. ‘hadoop fs ?text /user/flume/tweets/연/월/일/시’ 로 하면 아래와 같은 결과를 확인할 수 있다. ‘twitter4j’에서 생성한 데이터는 위와 같이 제이슨(JSON)형태의 반정형(semi-structured)데이터이다. 이것을 하이브에서 직접 읽어들이기 위해서는 제이슨 데이터를 읽어들이기 위한 설디(SerDe, Serializer/Deserializer)를 만들어야 한다. 설디는 특정 포멧의 데이터를 하이브에서 읽거나 쓸 때 사용하는 데이터 추상화 계층으로서 시리얼라이저는 데이터를 작성할 때, 디시리얼라이저는 데이터를 읽어들일 때 사용한다. 테이블 생성 시 별다른 정보를 입력하지 않으면 ‘LasinessSerde’가 디폴트로 사용된다. 디폴트 설디는 특정 케릭터를 딜리미터로 지정할 수 있으며, 공백기와 콜론 또는 임의의 값을 지정해 컬럼을 구분짓는 값으로 사용할 수 있다. 설디를 개발하기 위해서는 설디 클래스(org.apache.hadoop.hive.serde2.SerDe)의 메소드를 구현(implement)하면 한다. 이 추상 클래스에서 ‘initialize’, ‘serialize’, ‘deserialize’ 3개의 함수를 구현하여 제이슨 데이터를 읽어오도록 개발해야 한다. ‘Initialize’ 함수는 테이블에 대한 정보를 읽어온다. 설디는 컬럼의 이름과 타입을 읽어 오며 이 정보를 시리얼라이제이션/디시리얼라이제이션에 사용한다. 역직렬화(Deserialize) 코드에서는 하이브의 ‘ObjectInspector’ 인터페이스가 동작할 수 있도록 이 형식에 맞춰서 객체를 전달한다. 여기서는 제이슨 형태의 데이터가 넘어오고, 이것을 잭슨(Jackson)라이브러리를 통해 파싱한다. 그리고 이 정보를 열(row) 정보에 추가해 하이브에서 row로 인식할 수 있도록 한다. 직렬화(Serialization) 함수는 데이터를 하이브로 넘겨받아 다시 제이슨 형태로 하둡 파일 시스템에 저장한다. 설디 개발이 완료 되었으면, 이제 트위터 분석용 테이블을 생성한다. 먼저 방금 개발한 설디 클래스를 하이브 세션에 ‘ADD JAR’명령어를 추가한 후 아래와 같이 하이브 테이블을 생성한다. 테이블을 생성한 이후 플룸을 통해서 시간대별로 받은 데이터를 하이브의 ‘tweets’ 테이블에 로드한다. 아래 예의 경우 2015년 1월 28일 01시 데이터를 파티션에 추가한 것이다. 파티션을 추가한 경우에 쿼리문에서 ‘where column=파티션’을 수행할 때 하둡의 전체 저장영역을 스캔해 정보를 추출해내는 것이 아니라, 지정한 파티션에서만 데이터를 읽음으로써 작업 시간을 줄여주는 효과가 있다. 테이블을 생성하고 데이터도 정상적으로 로드됐다면 데이터 분석을 해볼 차례다. 먼저 어떤 타임존에서 가장 많은 트위트를 생성하는지 확인해보자. 가장 많은 트위트를 생성한 지역은 미국ㆍ캐나다인 것을 확인할 수 있다. 두 번째로는 사용자가 생성한 트위트 중에서 가장 많은 태그 정보를 확인하도록 한다. 다운 받은 트위트 중에서 가장 많은 태그는 ‘bigdata’와 ‘opendata’인 것을 확인할 수 있었다. 빅데이터 관련 부분에서 최근 가장 주목을 받고 있는 언어가 파이썬이다. 글로벌 사례를 보면 데이터 분석 분야 에서도 R의 사용추세보다 파이썬의 사용추세가 더 가파르게 증가하고 있다. 인터프리터 언어인 파이썬은 구조적으로 이해하기 쉽기 때문에 컴파일 언어보다 프로그램의 생산적인 측면에서 많은 강점을 가지고 있다. 또한 데이터 분석에서 널리 쓰이고 있는 R보다 많은 분석패키지들을 지원하고 있다. 이처럼 파이썬은 빅데이터 분야에서 요구하는 유연한 개발 지원에 적합한 언어의 강점을 모두 가지고 있기 때문에 사용자들을 더 많이 끌어 들이는 것 같다. 이번에는 파이썬을 이용해 트위트를 수집하는 방법과 트위트한 데이터를 어떻게 시각화를 하는지 알아 보자. 파이썬의 많은 패키지 중에 트위터를 지원하는 패키지를 설치해 트위터의 데이터를 수집해 보자. https://github.com/tweepy/tweepy 에 접속해 tweepy를 내려 받는다. [그림 Ⅰ-2-25] 기트허브 접속화면 Download Zip 버튼을 클릭해 tweepy 를 내려 받은 후 압축을 푼다. 커맨드 창에서 압축을 푼 디렉터리로 이동해 다음 명령을 실행한다. 루트 권한으로 접속해 pip을 실행한다. 트위터에서 단어를 필터링해 트위트되는 내용을 출력하는 프로그램을 구현해 보자. 간단하게 트위터에 접속해 어떻게 작동하는지 살펴보자. 테스트를 실행해 보자. 현재 트위트하고 있는 내용 중 ‘korea’가 들어간 문자로 필터링돼 출력되는 것을 확인할 수 있다. 트위터에 연결해 트위트들을 스트리밍으로 가져오는 테스트는 해보았으니 좀 더 프로그램을 개선해보자. 특정 단어를 검색해 트위트하는 내용을 단어별로 분리해 특정 단어에 대해 어떤 단어가 얼마나 트위트되는지를 구현하는 프로그램을 작성해 보자. Obamacare나 obamacare가 수집되지 않았다. 이번에는 어떤 단어가 많이 추출됐는지를 확인하기 위해서 데이터를 시각화해 보자. Obamacare와 관계된 단어를 분리해 개수를 추출했으므로 얼마나 많은 단어가 나왔는지 워드 클라우드 방법으로 데이터를 시각화해 보자. 수집된 데이터를 R이나 d3.js같은 툴을 사용해 표현할 수 있지만 여기에서는 방법이나 툴의 설명은 필요한 부분만 설명하고 수집된 데이터가 어떻게 활용될 수 있는지에 대한 부분에 집중하기로 한다. 트위트한 데이터를 확인해 보기 위해 로컬 환경에서 구현해 보자. 플랫폼 독립적이다. Visual.html로 파일을 작성하자. 작성한 html을 실행해보자. [그림 Ⅰ-2-26] 데이터 시각화 결과 결과를 보면 Obamacare에 대해 트위트에 올라온 단어들 중 Per라는 단어가 가장 많으며 false, POOR, ill, out등 등 부정적인 단어들도 많이 보인다. 문장의 조어 역할을 하는 단어들을 제외하는 등 좀 더 수정을 할 필요는 있다.오픈 API 수집방법(소셜 데이터 수집)
![[그림 Ⅰ-2-16] 트위터 수집 처리과정](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_01.gif)
트위터 정보생성
트위터 API용 정보생성
![[그림 Ⅰ-2-17] 트위터 계정 생성 화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_02.gif)
![[그림 Ⅰ-2-18] 트위터 앱 개발 관리화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_03.gif)
개발 애플리케이션 생성
![[그림 Ⅰ-2-19] 트위터 앱개발 관리화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_04.gif)
![[그림 Ⅰ-2-20] 트위터 앱개발 정보 입력화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_05.gif)
![[그림 Ⅰ-2-21] 트위터 앱개발 정보 입력화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_06.gif)
Application용 계정 정보생성
애플리케이션 관리화면
![[그림 Ⅰ-2-22] 컨슈머키 확인화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_07.gif)
애플리케이션 계정정보 받기
![[그림 Ⅰ-2-23] 액세스 토큰 발급화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_08.gif)
![[그림 Ⅰ-2-24] API 계정정보 확인 화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_09.gif)
트위터 플룸 소스

Configure 메소드 구현

스타트 메소드 구현

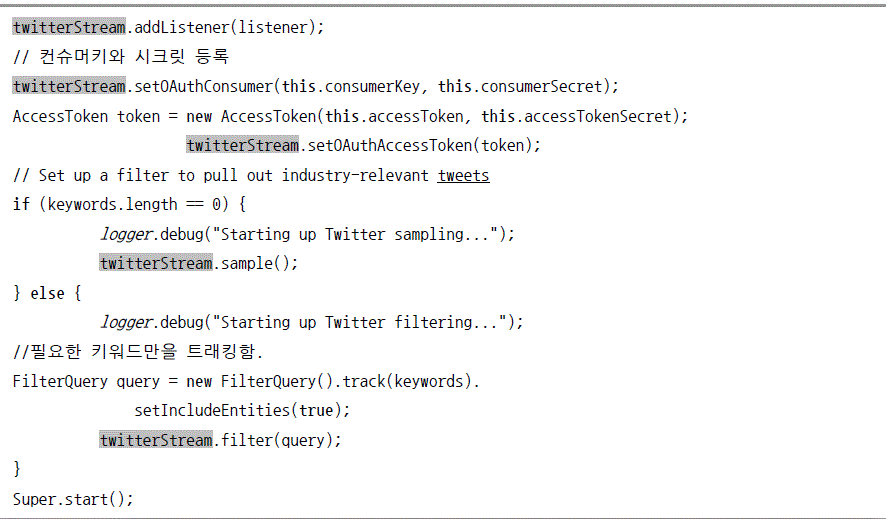
스톱 메소드 구현

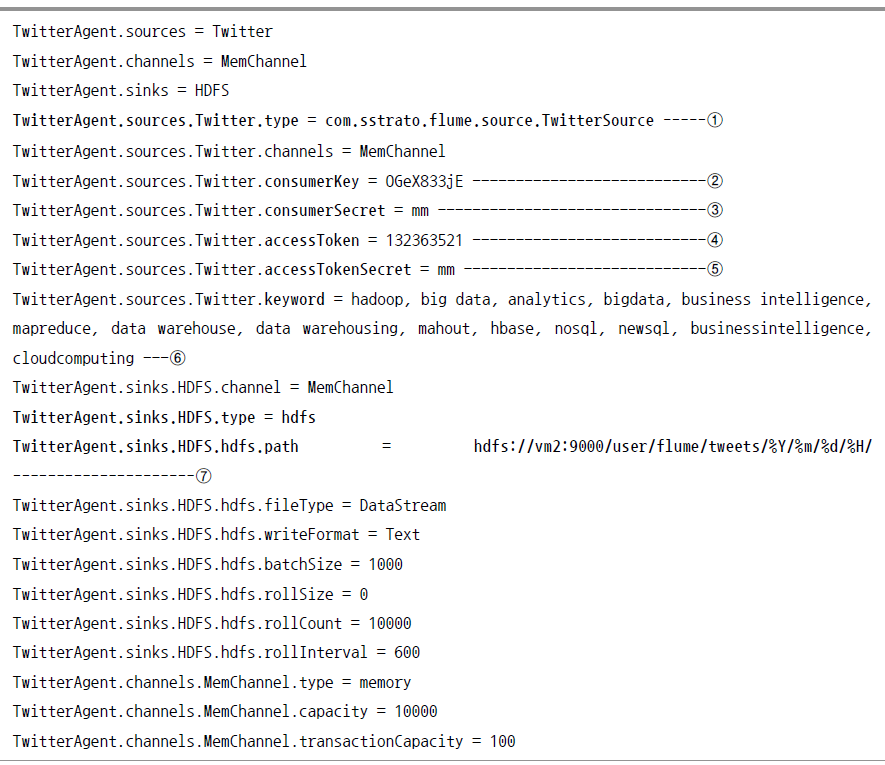
플룸 잡 컨피그레이션
하이브의 트위터 데이터용 설디 구현
![$ hadoop fs -text / user/flume/tweets/2014/04/05/01/00/* { "retweeted_status":{"contributors":null, "text":"$Crowdsourcing = drivers already generate traffic data for your smartphone to suggest alternative routes when a road is clogged. $bigata", "geo":null, "retweeted":false, "in_reply_to_screen_name":null, "truncated":{ "urls":[], "hashtags":[{](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_16.gif)
하이브는 여러 종류의 설디를 내부적으로 갖고 있지만, 아쉽게도 제이슨 형태의 데이터를 처리하는 설디는 없다. 그래서 자체적으로 개발해 주어야 한다. 하이브는 배열(array), 맵(map), 스트럭트(struct)와 같은 복잡한 형태의 데이터도 지원한다.
이중에서 제이슨처럼 키안에 또다른 키/밸류로 중첩돼 있는 데이터 형태의 경우, 스트럭트가 가장 적합한 형태의 데이터 타입이다.
제이슨용 설디 개발
Initialize 함수

역직렬화 함수 개발

직렬화 함수 개발

설디 전체 코드

트위터 테이블 생성

파티션 데이터 추가

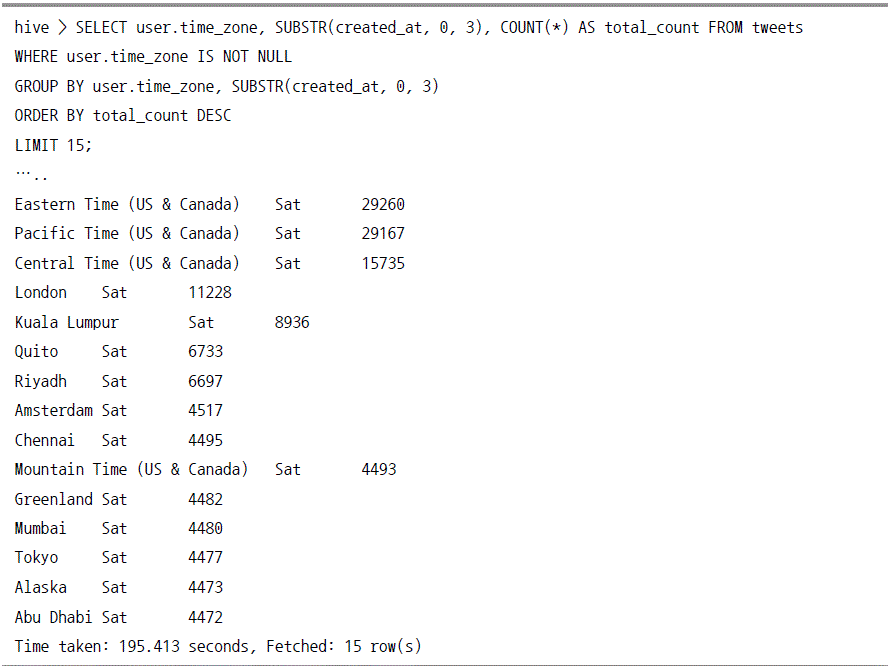
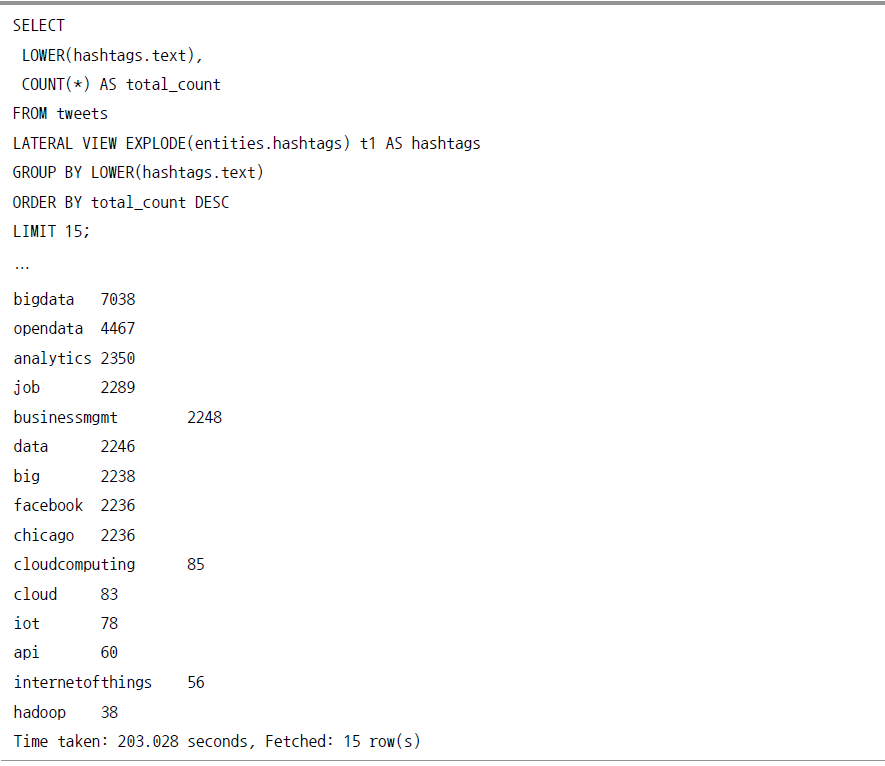
테이블 분석 예제
파이썬을 이용한 트위터 데이터 수집과 시각화
트위터용 파이썬 패키지 설치
윈도우에서 tweepy 설치
![[그림 Ⅰ-2-25] 기트허브 접속화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_25.gif)

리눅스에서 tweepy 설치

트위터 단어 필터링 구현
파이썬 트위터 접속 테스트
twit_test.py 프로그램을 작성하자.![import tweepy -----------------------① consumer_key = 'SRXugVpgEmSxFm0qGDgQz6hHO' ----------------② consumer_skey = 'dkakldlakjdakjadkadieekllkada' access_token = '196044070-G20nm84Vv7S7MuBsOUidVEkupSGgAzV1pxTVan22' access_stoken = 'aldkalakdkfSDEDKI0kelkkafjdlkakdfa' class listener(tweepy.StreamListener): -------------------③ def on_data(self, data): print data return data def on_err(self, status): print status auth = tweepy. OAuthHandler(consumer_key, consumer_skey) -------------- ④ auth.set_access_token(access_token, access_stoken) twitterStreaming = tweepy.Stream(auth, listener()) twitterStreaming.filter(track=("[korea"])](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_28.gif)

트위터에서 단어 필터링 프로그램 구현
![import tweepy ① import json import re import sys ② reload (sys) sys.setdefaultencoding('utf-8') consumer_key = 'SRXugVpgEmSxFm0qGDgQz6hHO' ③ consumer_key = 'dkakldlakjdakjadkadieekllkada' access_token = '196044070-G20nm84Vv7S7MuBsOUidVEkup_SGgAzV1pxTVan22' access_stoken = 'aldkalakdkfsDEDKIOkelkkafjdlkakdfa' def get_api(): api_key = consumer_key access_token_secret = access_stoken auth = tweepy.OAuthHandler(api_key, api_secret) auth.set_access_token(access_token, access_token_secret) return auth class CustomStreamListener(tweepy.StreamListener): ④ def_init_(self, *args, **kwargs): super (CustomStreamListener, self)._init_(*args, **kwargs) self.count = 0 with open ('restrict.word') as f: ⑤ self.common = set(line.strip() for line in f) self.all_words = {} self.pattern = re.compile("[^/w]") ⑥ def on_status(self, status): print 'Got a Tweet' self.count += 1 tweet = status.text tweet = self.pattern.sub('',tweet) words = tweet.split() ⑧ for word in words: if len(word) > 2 and word ! = '' and word not in self.common: if word not in self.all_words: self.all_words[word] = 1 else: self.all_words[word] +=1 if_name_=='_main_': ⑨ 1 = CustomStreamListener() try: auth = get_api() s = "obamacare" ⑩ twitterStreaming.filter(track=[s.decode('utf-8').encode('utf-8')]) except KeyboardInterrupt: print '-----total tweets-----' print 1.count json_data = json.dumps(l.all_words, indent=4) width open('word_data.json', 'w') as f: print >> f, json_data print s](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_30.gif)
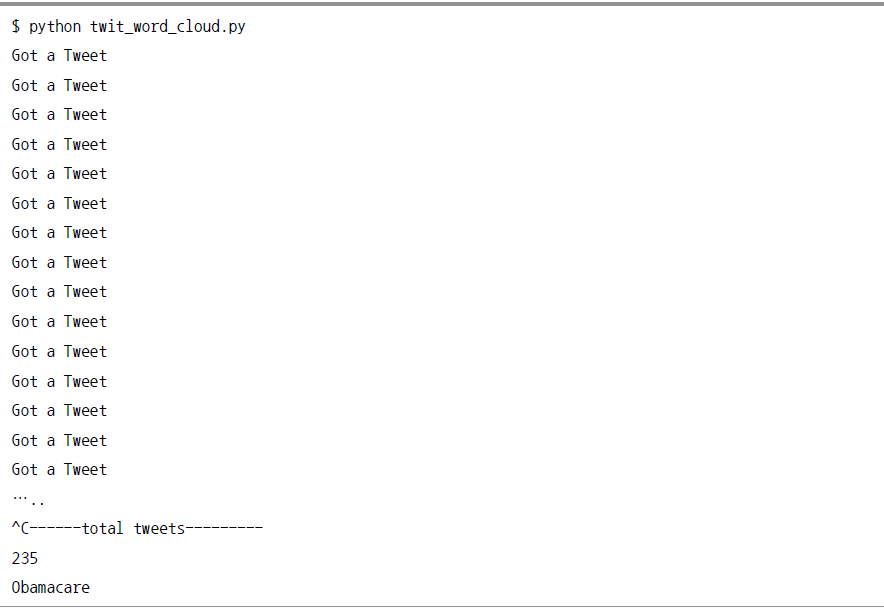
편집기로 어떤 단어들이 수집됐는지 확인하자.

데이터 시각화
“https://github.com/jasondavies/d3-cloud” 사이트에 접속해 d3.js를 다운로드한다. 자바스크립트 기반이기에 html 코드를 작성해 테스트해보자.
![<!DOCTYPE html> <meta charset="utf-8"> <body> <script src="../lib/d3/d3.js"></script> <script src="../d3.layout.cloud.js"></script> <script> var fill = d3.scale.category20(); mydata = d3.json("word_data.json", function(error, json){ if(error) return console.warn(error); data = json; d3.layout.cloud().size([300, 300]).words(mydata.map(function(d){ return {text : d[0], size: d[1]}; })) .padding(5) .rotate(function(){ return ~~(Math.random()*2)*90; }) .font("Impact") .fontSize(function(d){return d.size;}) .on("end", draw) .start(); function draw(words){ d3.select("body").append("svg") .attr("width", 300) .attr("height", 300) .append("g") .attr("transform", "translate(150, 150)") .selectAll("text") .data(words) .enter().append("text") .style("font-size", function(d) {return d.size + "px";}) .style("font-family", "Impact") .style("fill", function(d, i) {return fill(i);}) .attr("text-anchor", "middle") .attr("transform", function(d){ return "translate"(" + [d.x, d.y] + ")rotate("+d.rotate +")"; }) .text(function(d){return d.text;})'' } } </script>](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_34.gif)
![[그림 Ⅰ-2-26] 데이터 시각화 결과](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/124_bigdata_35.gif)
데이터 수집을 실무적인 관점에서 귀납적으로 접근해 프로그램의 설치→ 프로그램의 기능실습→ 프로그램 응용 순서대로 각 수집기술의 기본적인 활용방법에 대해 학습했다. 수집방법별로 어떤 것은 설치 및 기능이 주를 이루는 기술도 있었고, 어떤 것은 기술 활용이 주를 이루는 것도 있었다. 본장의 서두에도 기술했듯이 수집기술들은 계속 발전하고 기능 또한 추가되고 있어 기술들에 대해 부단한 학습을 해야 ‘데이터 수집’이라는 목적을 달성하기 위한 유연한 아키텍처를 구성할 수 있다. 데이터를 수집하다 보면 데이터를 내부 시스템으로 획득까지의 순간이 가장 어렵다. 일단 내부로 데이터를 획득하면 그 형태에 상관없이 데이터 활용을 위한 다양한 형태로 변형은 우리가 학습한 내용만 가지고도 충분히 구현이 가능하다. 1장 데이터 수집의 이해와 2장 데이터 수집실무는 서로 별개의 장이 아니라 ‘데이터 수집’ 목적을 이루기 위한 이론과 기능이라는 두 개의 날개로 생각하고 ‘데이터 수집’을 이해하기 바란다. 마지막으로 ‘데이터 수집’ 단원에서 다룬 내용은 다른 단원과 완전히 독립적인 것도 있고 서로 의존관계에 있는 것도 있기 때문에 다른 단원의 학습 또한 데이터 수집의 관점에서 꼭 필요하니 열심히 학습할 것을 당부한다.