
데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
웹 크롤링에 대한 위키의 정의는 다음과 같다. 웹 크롤러를 이용해 월드 와이드 웹을 탐색해 원하는 정보를 얻어 내거나 기억시킨 동작을 하는 컴퓨터 프로그램이다. 주로 웹 페이지 크롤링을 통해 직접 접근해 정보를 빠르게 수집하거나 자동 이메일 수집 또는 웹 유지관리를 위해 사용되기도 한다. 검색엔진에서는 크롤링을 통해 정보를 찾은 후 색인과정을 통해 데이터를 수집하는 것을 목적으로 한다. 이처럼 웹 크롤링의 의미가 목적에 따라 다중의 의미를 갖기 때문에 웹 크롤링은 목적 지향적 특성에 따라 세분화해 정의를 내려야 할 것이다. 우리는 데이터 수집(데이터 수집의 이해에서 기술한)관점에서 다시 웹 크롤링의 개념을 인지하고 학습해야 할 것이다. [표 Ⅰ-2-5] 크롤러 구현방법 이제 우리가 실습할 크롤러를 선택해 보자. 크롤러중 프레임워크를 제공하는 크롤러를 선택하여 실습하는 것이 크롤링의 개념을 쉽게 이해할 수 있을 것이다. 프레임워크를 제공하고 있는 크롤러중에 최근에 가장 많이 주목 받고 있는 Scrapy를 사용해 이번 실습을 진행해 보도록 하자. [표 Ⅰ-2-6] 크롤러 프레임워크 비교 개발 난이도와 프레임워크가 지원하는 기능 및 성능에 관한 것은 논란의 소지가 있으므로 구글 검색으로 최근 가장 주목 받고 있는 Scrapy를 웹 크롤링에 학습할 크롤러로 선택했다. Scrapy는 웹에 존재하는 정보를 크롤링하기 위한 파이썬 기반의 애플리케이션 프레임워크다. [그림 Ⅰ-2-8] Scrapy 아키텍처 Scrapy의 아키텍처 구조는 수집 주기를 설정하는 스케줄러가 존재하고, 수집할 항목을 정의하는 아이템과 수집 데이터의 저장 형식을 정의하는 파이프라인이 출력을 담당하는 형태다. 스파이를통해 월드와이드웹 정보를 수집하는 형태다. Scrapy는 파이썬이 먼저 설치된 환경에서 설치해야 한다. 파이썬의 패키지 매니저인 PIP을 설치한 후 Scrapy를 설치한다. 주의할 점은 2.7.X.X 버전이 Scrapy에 가장 안정적이므로 가급적 2.7버전을 설치하기를 바란다. 윈도우에 설치할 경우 http://python.org/download/에서 다운로드한다. [그림 Ⅰ-2-9] 파이썬 다운로드 페이지 2.7.XX버전을 다운로드해 windows installer 파일을 받아 실행하면 된다. 파이썬 패키지 인스톨러를 설치하기 위해 easy_install의 홈피에서 setuptools을 다운로드 받는다. easy_install의 설치가 끝나면 pip를 설치한다. 커맨드 창에서 다음과 같이 입력한다. http://slproweb.com/products/Win32OpenSSL.html 에서 win32OpenSSL과 Visual C++ 2008 redistributables을 다운받아 실행한다. 주의할 점은 OpenSSL lite를 받으면 안된다는 것이다. 또한 bin file은 OpenSSL 로컬 폴더에 설치해야 한다. 이후 C:\openssl-win32\bin을 환경변수에 추가한다. 다음으로 필요한 패키지들을 설치해 준다. 필요한 패키지와 다운로드 주소는 다음과 같다. 해당 링크를 다운로드한 후에 윈도우에서 실행한다. 윈도우 설치에서 앞의 모든 과정이 정상적으로 끝났을 경우 커맨드 창에서 다음과 같이 치면 오류 없이 Scrapy가 설치될 것이다. 레드햇 계열 리눅스에서 설치 시 파이썬 2.6.X버전이 기본적으로 설치돼 있으므로 파이썬 버전을 2.7.X.X로 업그레이드할 필요가 있다. 시스템에 필요한 패키지들을 먼저 설치하자 패키지 설치가 끝났으면 파이썬 2.7버전을 받아 설치한다. 만약에 pip가 없다면 파이썬의 패키지를 인스톨하기 위해 pip를 먼저 설치해야 한다. pip 설치 시 유의할 점은 반드시 관리자 계정으로 실행하거나 sudo를 사용해 실행해야 한다는 것이다. 만약에 pip가 없다면 파이썬의 패키지를 인스톨하기 위해 pip를 먼저 설치해야 한다. pip 설치 시 유의할 점은 반드시 관리자 계정으로 실행하거나 sudo를 사용해 실행해야 한다는 것이다. Ubuntu 버전은 패키지에 Scrapy를 지원하므로 다음과 같이 설치하면 완료된다. Scrapy를 설치했으면 어떻게 작동하는지를 살펴보자. Scrapy가 어떻게 구동되는지 작동원리를 알기 위해서는 프레임워크의 아키텍처가 되는 Scrapy 프로젝트의 디렉터리 구조와 핵심이 되는 아이템, 스파이더를 중심으로 살펴볼 필요가 있다. 먼저 웹을 스크랩하기 전에 새로운 프로젝트 하나를 만들어 선택한 디렉터리에 저장되는 코드를 작성한 후 실행해 보도록 하자. startproject 명령어를 실행해 프로젝트를 실행하면, 실행한 디렉터리 하위에 다음과 같은 구조의 디렉터리와 파일이 생성된다. Scrapy의 기본적인 구조를 살펴보았다. Scrapy는 프레임워크이므로 startproject 명령어 구동 시 프로젝트에서 사용할 파일들이 대부분 세팅된다. items.py와 project 메인 디렉터리 하위의 spider 디렉터리에서 스파이더들만 만들어 주면 기본적인 크롤링 기능에 대해 익히는 것은 문제가 없으며, 아이템과 스파이더가 Scrapy의 핵심이라 할 수 있다. 아이템과 스파이더에 대해 알아보자. 아이템은 스크랩한 데이터를 담는 컨테이너다. 아이템의 특징은 웹에서 지정한 형태의 데이터를 필드로 선언해 관리한다. vi 편집기를 사용해 아이템 파일을 수정해 보자. 아이템들이 어떻게 작동하는지 보기 위해 파이썬을 구동해 파이썬의 커맨드 라인에서 다음을 입력한다. Scrapy에서 스파이더 프로그램은 크롤링을 담당하는 핵심 부분이다. 스파이더 프로그램의 구성요소는 무엇인지와 어떻게 구성되는지 알아보자. 스파이더 디렉터리에서 스파이더 프로그램을 작성해 보자. 코드를 실행해 보자. 우리가 만들었던 스파이더는 해당 웹 페이지 전체를 크롤링해 파일로 저장하는 프로그램이었다. Scrapy는 파이썬 언어 기반의 프레임워크이기 때문에 Scrapy 라이브러리로 구성된 모듈을 임포트해 프로그램을 작성하는 기능 외에도 Scrapy 툴 명령어를 지원해 쉽게 프로젝트를 구성할 수 있도록 해준다. 여기서는 Scrapy의 명령어의 종류와 활용 방법에 대해 알아보도록 하자. Scrapy에서 지원하는 명령어 사용법은 다음과 같이 콘솔창에 입력해 명령어를 실행하면 된다. Scrapy에서 사용하는 명령어는 크게 프로젝트 내부에서 해당 프로젝트와 관련돼 사용하는 프로젝트 명령어와 실행(Active)되는 프로젝트와 관련없이 사용할 수 있는 전역 명령어로 나눌 수 있다. - 전역 명령어 - 프로젝트 명령어 새로운 Scrapy의 프로젝트를 생성한다. shell 명령어는 주어진 url 인자 값을 포함해 파이썬 쉘 프롬프트를 구동한다. 그러므로 반드시 인자값에 url 주소가 있어야 한다. url의 인자값은 http의 주소나 html 코드로 작성된 파일이나 모두 사용할 수 있다. 주어진 url 인자값의 페이지 내용을 콘솔창에 출력한다. url은 http 프로토콜을 사용하므로 반드시 http://가 url에 포함돼야 한다. 만약 프로젝트를 만들지 않고 파이썬 내에 독립적으로 스파이더만 만들어 구동 시 사용한다. Scrapy의 버전을 화면에 출력한다. ? v 옵션을 사용하면 파이썬과 twisted 및 플랫폼 정보까지 출력한다. 버전 명령어는 버그 리포트 활용시 유용하다. Scrapy의 다운로더를 사용해 주어진 url 인자값의 url 내용을 다운로드하고, 다운로드한 콘텐츠를 표준 출력으로 기록한다. fetch 명령어는 전역 명령어이지만 프로젝트 내에서도 사용이 가능하다. 프로젝트 외부에서 fetch 명령어를 실행시키면 디폴트 세팅된 Scrapy 다운로더를 사용한다. Fetch 명령이 유용한 것은 --nolog 옵션과 --headers 옵션을 사용하면 fetch하고자 하는 url에 Scrapy 다운로더가 접근하는 것을 분석할 수 있기 때문이다. Scrapy의 세팅 인자별로 값을 출력한다. 만약 프로젝트 내에서 명령어를 수행하면, 프로젝트의 세팅값을 출력하고 프로젝트의 밖에서 명령어를 수행하면 Scrapy의 디폴트 세팅값을 보여준다. setting 명령어는 옵션이 필요하다. setting 값을 얻어오는 --get과 setting 값을 설정해 주는 --set옵션을 주로 사용한다. 프로젝트에서 작성한 스파이더를 사용해 스파이더에서 지정한 웹페이지를 크롤링한다. Scrapy 명령어들 중에서 가장 많이 사용하는 명령어다. crawl 명령어에 파일로 저장하는 옵션이 있기 때문에 간단한 웹크롤링에서는 파일 출력을 담당하는 pipelines.py를 사용하지 않고 crawl 명령어의 옵션으로 크롤링한 데이터를 파일로 저장이 가능하다. 스파이더 간의 관계 확인을 위해 사용한다. 일반적으로 parse와 parse_item 메소드의 관계를 확인할 때 사용하지만, 여러 스파이더가 한 프로젝트에 있을 경우 스파이더 클래스 간의 url 상속관계를 확인할 때도 사용한다. 현재 프로젝트에서 사용가능한 스파이더의 내용을 출력한다. list 명령어는 스파이더 프로그램을 작성한 후 크롤링하기 전에 코드의 오류를 찾기 위해서도 사용된다. setting에 등록된 에디터를 사용해 스파이더 프로그램을 편집할 때 사용한다. 현재 디렉터리에 상관없이 스파이더 이름만 알면, 스파이더 프로그램이 있는 디렉터리의 스파이더 파일을 편집할 수 있다. 프로젝트내의 Scrapy에서 미리 선언된 스파이더 템플릿을 사용해 스파이더 프로그램을 작성한다. 처음 Scrapy를 사용하는 사용자라면 스파이더 프로그램을 이해하는 데 아주 유용하게 사용할 수 있으며, 숙련된 사용자의 경우 스파이더 프로그램을 간편하게 작성할 수 있도록 도와준다. Scrapy 스파이더의 간단한 벤치마크를 테스트한다. Scrapy를 사용해 웹을 크롤링하기 위해 꼭 알아 두어야 할 기능들에 관해 설명한다. 복잡한 크롤링이나 전문적인 크롤링 업체에서 사용하는 기능들은 좀더 익숙해 지면 사용한다고 가정하고 소개한다. 여기서 설명하는 Scrapy의 핵심 기능에 대하여 정확히 학습한다면 파이썬의 Scrapy 프레임워크를 사용하여 일반적인 웹사이트를 크롤링하는데 문제가 없을 것이다. 데이터를 정의하는 아이템클래스와 웹의 규칙에 따라 저장된 페이지에서 어떻게 규칙을 적용해 데이터를 선별하는가 하는 셀렉터를 학습해 보자. 학습에 사용하는 코드들은 테스트 코드들이므로 반드시 실제로 작성해 교재와 같은 결과 값이 본인의 컴퓨터에 출력되도록 해보자. 아이템 클래스는 필드로 구성돼 있다. 필드 오브젝트의 특징만 잘 숙지하면 아이템 선언에 대한 모든 것을 이해할 수 있을 것이다. 아이템을 선언에 대하여 실습해보자. 명령어 라인에서 다음과 같이 입력한다. 선언된 아이템을 적용해 보자 Scrapy에서 셀렉터를 통해 가져온 데이터들은 모두 리스트 형태로 반환된다. Scrapy에서 주로 사용하는 selector는 xml과 html의 xpath 표현식을 가져오는 HtmlXPathSeletor이다. 셀렉터를 사용하기 위해 xpath의 표현식에 대해 주요한 표현식만 간단히 설명하고, 실습을 통해 어떻게 결과값이 추출되는지를 보면 쉽게 이해할 수 있을 것이다. xpath 표현식은 글로벌 DBMS에서도 지원하기 때문에 익혀두면 아주 유용하게 사용할 수 있다. 셀렉터를 실습하기 위해서는 실습을 위한 웹 페이지나 html 코드가 있어야 한다. 따라서 샘플로 html 코드를 만들어 파일로 저장한 후 scrapy shell에서 html 코드를 url로 읽어 실습을 하자. Scrapy를 사용하기 위해 설치와 구성 기본적인 사용법에 대해 살펴보았다. 이제 Scrapy를 통해 웹을 크롤링하는 실습을 해보자. Scrapy는 자체로서 웹 크롤링을 위한 프레임워크이므로 적은 노력(자원과 시간)으로 웹을 크롤링할 수 있다. 또한 크롤링에 필요한 거의 모든 기능을 담고 있다. 실습을 통해 기본적인 크롤링 방법을 살펴보자. 웹 사이트에서 페이지를 스크롤링하기 위해 시나리오를 작성해 실습해보자. 실습을 통해 가져올 웹 사이트의 선정에는 크롤링할 데이터의 실용성과 학습의 효과를 위해 기본적인 크롤링 외에 여러가지 팁들이 표현될 수 있는 사이트를 선정했다. ‘유머 사이트들의 베스트 글만 모아 앱을 통해 분석해 서비스하면 어떨까?’ 하는 생각에서 대표적인 유머 사이트 가운데 하나인 ‘오늘의 유머’의 베스트 글을 서비스하는 것으로 주제를 잡았다. 사이트 탐색을 위해 크롤링할 사이트에 접속해 프로젝트(실습)에 어떻게 적용해야 할지 분석해 보아야 한다(http://todayhumor.co.kr). [그림 Ⅰ-2-10] 오늘의 유머 사이트 분석할 사이트는 주제별 게시판에 게시자가 글을 작성ㆍ저장하고 글이 좋으면 게시글을 읽는 사람이 추천을 누르고 좋지 않으면 반대를 누르는 형태로 돼 있다. 추천이 10 이상이면 ‘베스트’ 게시판에 100 이상이면 ‘베스트 오브 베스트’ 게시판으로 이동하는 것을 알 수 있다. 사이트 탐색을 통해 주제별로 혹은 일정 추천 수 이상이 모인 게시글이 존재하는 게시판으로 분류되는 것을 확인했다. 추천 수 100 이상인 게시글의 제목과 링크 정보만 추출해 데이터를 활용하는 것으로 시나리오를 구성하자. 사이트에 대한 탐색을 통해 가져오고자 하는 데이터가 도출됐다면 어떻게 데이터를 가지고 올지에 대한 구체적 분석이 필요하다. [그림 Ⅰ-2-11] 베스트 오브 베스트 URL 확인 추천 수가 100 이상인 게시글만 모아 둔 게시판에 접근해 URL을 알아낸다. 여기서는 URL이http://todayhumor.co.kr/board/list.php?table=bestofbest다. [그림 Ⅰ-2-12] 베스트 오브 베스트 리스트 제목과 링크가 어떤 패턴으로 돼 있는지 알기 위하여 해당 페이지의 소스를 분석해 본다. 대부분 html이나 xml 형식으로 돼 있는 웹 페이지는 특정 패턴에 따라 작성됐기 때문에 어떤 크롤링 툴을 사용하든지 간에 패턴을 파악하는 것이 가장 중요한 일이다. 굵은 글씨로 표시된 부분 중에 링크(href=”/board/view.php?....)와 제목(“치킨먹고싶은데 용돈 떨어진 사람 있나?”)이 우리가 추출할 데이터다. Scrapy를 사용해 웹을 크롤링해보자. Scrapy가 정상적으로 설치됐으면, 순서대로만 진행하면 된다. 프로젝트를 생성한다. 여기서는 오늘의 유머를 영어로 한 todayhumor라고 프로젝트를 생성하겠다. 생성한 프로젝트로 이동해 어떤 항목들이 있나 살펴보자. 아이템을 설정한다. 아이템은 수집 대상의 항목을 매칭할 대상을 결정하는 것이다. 데이터베이스의 테이블을 만드는 것과 유사하지만, 테이블 생성처럼 어렵지 않다. 다음은 item.py 내용이다. “”은, 파이선은 구문의 내부를 tab으로 구분하기 때문에 구별을 위해서 표시한 내용이다. 이번 실습에서 아이템으로 가져올 데이터 항목이 제목과 url이기 때문에 item.py의 8, 9, 10라인을 지우고 다음과 같이 수정한다. 이제 가장 중요한 데이터를 아이템과 매핑해보자. 직접 스파이더 프로그램을 작성해 결과를 보고 프로그램을 수정하는 방법도 있지만, 그것은 너무나 비효율 적이다. Scrapy에서는 shell 명령어를 이용해 간단히 찾고자 하는 데이터의 html 패턴을 테스트해 볼 수 있다. 정규표현식과, xpath 표현식을 알고 있으면 웹을 크롤링하는 데 많은 도움이 되니 꼭 참고하기 바란다. scrapy shell을 실행해보자. 실습할 url인 http://todayhumor.co.kr.board/list.php?table=bestofbest를 명령어 옵션에 입력한다. html 분석을 위해 필요한 Scrapy의 모듈을 임포트하고 셀렉터 객체를 생성한다. 가져오고자 하는 데이터를 추출하기 위해 html을 분석한다. 쉘에서 지정한 url의 소스를 보고 어떤 패턴으로 데이터가 지정돼 있는지 분석하고 scrapy shell에서 테스트를 수행한다. html 소스를 분석해 보면 트리구조로 되어 있는 것을 볼 수 있다. html 트리에서 우리가 가져오려는 데이터의 중요 노드들은 각각 table→ tr→ td 형태로 구성돼 있는 것을 볼 수 있다. 그런데 table 태그에 class가 명명돼 있으니 class 이름으로 table 태그의 내용을 추출하도록 하자. 다음으로 tr태그를 분석해 내용을 추출하고 다시 td태그를 추출해 보자. 분석한 내용이 맞는지 scrapy shell에서 테스트해 보자. 데이터를 찾았다면 이제 스파이더 프로그램을 작성해 보자 scrapy shell에서 사용했던 코드들을 활용해 프로그램을 작성할 것이므로 프레임워크 특성상 몇 개의 규칙만 정해주면 쉽게 코딩할 수 있다. 작성한 스파이더 프로그램을 테스트 해보자. 먼저 웹을 크롤링 하기 전에 제대로 스파이더 프로그램이 작성되었는지 확인하는 방법은 Scrapy명령어를 통한 코드 검증이다. 웹을 크롤링해 보도록 하자 Scrapy에서 웹을 크롤링하는 명령을 실행한다. 정상적으로 크롤링 되면 화면과 같은 메시지가 출력된다. 크롤링한 데이터를 확인해 보도록 하자. 헤더 부분인 url과 title을 제외하면 20개의 데이터만 가져온 것으로 확인됐다. 그리고 url 데이터는 html 코드에서 외부에서 실행시키는 주소가 생략돼 있음을 알 수 있다. 처음부터 완벽하게 프로그램을 작성하기란 어렵다. 그러므로 프로그램의 구현 목적에 맞게 결과값이 도출 되었는지 확인해 구현 목적을 달성하기 힘든 원인을 찾아 수정해야 할 것이다. 작성한 스파이더 프로그램은 리스트 형태로 된 사이트의 한 페이지만 가져오게 돼 있고, 실습 시나리오에서 url 데이터를 바로 링크가 되도록 하기 위해 가져온 데이터는 불완전한 것을 가져오는 것으로 보인다. 웹은 특성상 한 페이지에 하나의 페이지가 존재하고 다른 정보들은 다시 링크로 연결되는 특징을 가지므로 실습에서 처음 작성한 프로그램은 당연한 결과값이 도출된 것이다. 웹 크롤링은 한 페이지만 크롤링하는 경우는 거의 없다. 물론 탐색을 통해 자동으로 한 페이지만 자동으로 가져오는 경우도 있지만, 그것도 엄밀히 말하면 여러페이지를 가져오는 경우 중, 검색을 통해 결과 페이지가 하나인 경우라 할 수 있을 것이다. 어떻게 웹에서 제공하는 모든 게시물을 가져올 것인지 알아 보기 위해 목적 사이트에 접속해 다시 한 번 사이트의 웹 구조를 살펴보자. [그림 Ⅰ-2-13] 베스트 오브 베스트 리스트 웹 구조 확인 브라우저를 통해 사이트를 분석해 보면 페이지의 숫자가 하나씩 증가함을 볼 수 있다. 시작 url인http://www.todayhumor.co.kr/board/list.php?table=bestofbest에 &page=을 추가해 페이지 번호를 증가시키도록 코드를 작성해 보자. 수정한 프로그램을 실행해 웹 페이지를 스크롤링한다. 스크롤링한 데이터에서 url이 /board/view.php?table=bestofbest&no=194234&s_no=194234&page=1이라는 형태로 추출 되었다. 브라우저에서는 내부의 스크립트를 통해 자동으로 url을 붙여 생성하기 때문에 내부에 저장된 url을 통해서도 링크의 완전한 주소가 만들어진다. 내부 스크립트에서 완전한 url을 만들어 urls 아이템에 저장할 수 있도록 프로그램의 수정이 필요하다. 완전한 url은 가져온 urls 데이터에 “http://todayhumor.co.kr”을 붙이면 해결됨을 알 수 있다. 그러면 urls 아이템에 “http://todayhumor.co.rk” 문자열을 붙일 수 있도록 프로그램 코드를 작성해 보자. 수정한 프로그램을 실행해 웹 페이지를 스크롤링한다. 스크랩된 아이템이 20020개임을 확인할 수 있다. 크롤링한 데이터를 확인한다. 처음 실습한 계획대로 모든 데이터가 정상적으로 출력됨을 알 수 있다. 모든 버그가 디버그 처리되었다. 크롤링한 데이터를 활용하기 위해서 하둡으로 데이터를 저장할 필요가 있다. 실습예제의 데이터를 크롤링과 동시에 어떻게 하둡으로 저장하는지 학습해 보자. 플룸은 소스 타입을 exec 타입으로 지정해 크롤링한 데이터를 실시간으로 저장하도록 구성해 싱크를 hdfs로 지정하도록 워크플로 파일을 작성한다. 웹크롤링의 결과는 크롤링 프로젝트 디렉터리에서 scrapy 명령어를 사용하여 result.csv에 저장한다. 데이터가 잘 처리 되는지 플룸과 하둡에서 확인해 보자. 이상으로 크롤링한 데이터를 하둡으로 저장하는 방법에 대해 알아 보았다. 스쿱과 연결해 하둡의 데이터를 mysql같은 관계형 데이터베이스에 저장할 수도 있고 하둡에서 직접 하이브를 이용해 필요한 데이터를 쿼리할 수 있을 것이다. Scrapy의 기능 중에 직접 DBMS에 크롤링한 데이터를 저장하는 방법에 대해 프레임워크의 기능을 사용해 구현해 보자. 이번에 크롤링할 사이트는 “it-ebooks.info”라는 사이트로 IT 관련 책들을 PDF형식으로 무료로 제공하고 있다. 사이트 분석 및 아이템 정의 등은 첫 번째 실습을 통해 충분히 하였으므로 이번에는 직접 DBMS에 저장하는 방법에 중점을 두어 실습해보자. It-ebooks.info 사이트는 거의 5000종에 가까운 IT 관련 서적들을 PDF 형태로 제공하고 있다. 각 책들의 설명은 it-ebooks.info/book/책번호 형태로 페이지들이 구성돼 있다. 책 번호를 주소창에 입력하고 사이트를 탐색해보면 페이지에 책번호에 해당되는 책의 제목, 페이지, 요약정보, 다운로드, 링크들이 배치돼 있다. 프로젝트의 목적은 사이트에서 서비스하고 있는 모든 책의 제목과 책의 요약정보를 크롤링해 DBMS에 넣고 활용하는 것이다. [그림 Ⅰ-2-14] it-ebooks.info 홈페이지 [그림 Ⅰ-2-15] it-ebooks.info 책의 상세내역 페이지 프로젝트를 생성한다. DBMS로 직접 크롤링한 데이터를 넣기 위해 생성한 프로젝트의 메인폴더에 있는 pipelines.py와 settings.py를 수정해야 한다. settings.py를 다음과 같이 수정한다. items.py를 다음과 같이 수정한다. itbook.py 스파이더 프로그램을 작성한다. mysql DBMS에 4473건의 데이터가 크롤링 돼 저장된 것을 확인할 수 있다. “big data”라는 키워드로 약 26권의 책이 검색됐다. 간단하게 실습 프로그램을 진행해 보았다. 실습한 것처럼 몇 가지 프로그램 규칙과 프로그램 논리만 안다면 페이지를 얼마든지 간단히 크롤링할 수 있다. 크롤링을 통해 수집한 데이터의 활용은 좀더 논의해야겠지만, 수집하는 방법 측면에서는 웹 크롤링에 첫 발을 둔 것으로 볼 수 있다. 첫 번째 수집한 사이트에서는 베스트 오브 베스트의 글과 링크만 수집했지만, 주제별 게시판을 수집해 데이터를 활용할 수도 있을 것이다. 예를들면 음악 게시판의 내용을 수집해 대중 트렌드 분석에 활용할 수도 있고, 종류별 베스트 오브 베스트 게시글을 분석해 사이트의 성향을 분석할 수도 있을듯싶다. 데이터 수집의 첫장에서 언급했듯이 데이터에 대한 인식이 높으면 높을수록 같은 데이터에서도 더 많은 인사이트를 얻을 수 있다. 데이터를 수집하는 방법 중 웹 스크롤링은 강력한 수단이 될 수 있지만, 웹 사이트 담당자에게는 서버에 부하를 줄 수 있고 지적 소유물에 대해 허가를 득하지 않고 가져오는 행위이기 때문에 검토할 사항들이 많이 존재하기 때문에, 반드시 법적 자문을 구하는 것을 권한다.웹 크롤링
데이터 수집 관점에서 웹 크롤링의 개념에 접근해 보면 scrapping과 crawling의 개념을 분리해 생각해 보아야 할 것이다. scrapping은 웹 페이지의 내용 전체를 웹 코드까지 가져오는 것이고 crawling은 scrapping 외에도 웹에서 전달하고자 하는 콘텐츠를 데이터화하는 것까지를 포함한다. 데이터 관점에서 크롤링에 접근하기 위해 일반적으로 언급하는 크롤링이 아니라, 웹에서 콘텐츠를 가져오기 위한 크롤링으로 한정해서 웹 크롤링에 대해 학습하도록 하겠다.
지금도 다양한 목적을 위해 웹 크롤러가 개발되고 있기 때문에 웹 크롤러의 종류를 하나 하나 열거하는 것은 불가능할 것이다. 그래서 크롤러가 어떻게 개발돼 구현됐는지 크게 네 가지 형태로 나누어 비교해 보겠다.
구분
종류
특징
Pure 프로그래밍
C, Java...
프로그램밍 언어로 작성한 간단한 웹 접속용 크롤러
라이브러리
Beautiful soup, lxml, curl…
프로그래밍 언어에서 크롤링을 위해 지원하는 라이브러리들. 주로 html을 파싱하는 기능을 지원한다.
프레임워크
Scrapy, nutch, crawler4j
크롤링의 아키텍처 위에 확장 가능한 기반 코드 제공
업무용패키지
구글, 아마존, 네이버, 다음 같은 곳에서 자체 개발한 엔터프라이즈급 크롤러
특정 목적을 가지고 개발한 패키지 형태의 애플리케이션
프레임워크
기반 언어
구글 검색결과
Scrapy
파이썬
481,000
Nutch
Java
476,000
Crawler4j
Java
20,600
Scrapy 아키텍처
프레임워크라는 말에서 알 수 있듯이, Scrapy는 파이썬 코드에 대해 조금만 알고 있다면 설정을 통해 충분히 웹을 스크랩할 수 있다. 그렇다면 어떻게 작동하는지 Scrapy의 아키텍처를 알아보자.![[그림 Ⅰ-2-8] Scrapy 아키텍처](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_01.gif)
Scrapy 설치
윈도우에서의 Scrapy 설치
파이썬 설치
![[그림 Ⅰ-2-9] 파이썬 다운로드 페이지](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_02.gif)
환경변수를 설정한다. 먼저 환경변수의 경로를 설정 한 후 파이썬 버전을 확인한다.
PIP 설치
https://pypi.python.org/pypi/setuptools 페이지에서 윈도우의 링크를 추적하면
[https://bitbucket.org/pypa/setuptools/raw/bootstrap/ez_setup.py]가 나온다. 링크를 클릭해 ez_setup.py 파일을 다운로드한다. 다운로드 후 윈도우 커맨드 창에서 다음과 같은 명령을 실행한다.

Scrapy를 설치하기 위해 필요한 기타 패키지 설치
필요 패키지
다운로드 위치
pywin32
http://sourceforge.net/projects/pywin32/files/pywin32/
twisted
http://twistedmatrix.com/trac/wiki/Downloads
zope.interface
https://pypi.python.org/pypi/zope.interface/4.0.5$downloads
lxml
https://pypi.python.org/pypi/lxml/
pyOpenSSL
https://launchpad.net/pyopenssl/+download
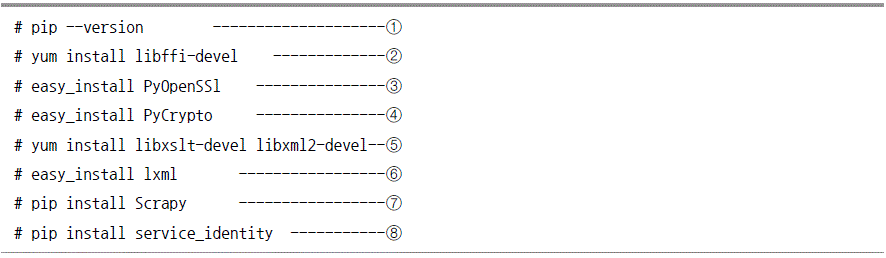
Scrapy 설치 확인
레드햇 계열 리눅스에서의 Scrapy 설치
필요 패키지 설치

파이썬 설치
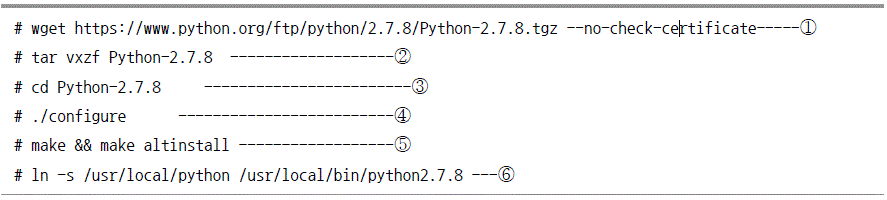
pip 설치

Scrapy 설치
Scrapy설치 확인

Scrapy의 기본 구조와 작동 살펴보기
파이썬의 코드를 설명할 때 이라고 돼 있는 경우 tab키로 분리된 것을 의미한다.
프로젝트 생성
프로젝트의 디렉터리 구조

[Note]
프로젝트를 생성했을 경우 서브 디렉터리에 있는 __init__.py 파일은 파이썬에서 패키지 파일임을 의미하므로 이 파일들은 수정하거나 삭제하지 않아야 한다.
아이템 정의하기

![$ python >>> import scrapy >>> class DmozItem(scrapy.Item): ............title = scrapy.Field()............link = scrapy.Field() .... >>> item = DmozItem() >>>item ["title"] = "Examplt title" >>> item["title"] 'Example title'](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_14.gif)
스파이더 프로그램 만들기
스파이더 프로그램은 다음과 같은 필수 구성요소를 포함해야 한다.

![import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" ### 스파이더의 이름을 선언한다. allowed_domains = ["dmoz.org"] start_urls = [ ### 크롤링할 사이트의 시작 URL을 지정한다. "http:///www.dmoz/org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): ### parse 메소드를 선언한다. filename = response.url.split("/") [-2] --------------- ① with open(filename, 'wb' ) as f : f.write(response.body)](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_16.gif)
샘플 프로그램 작성
이를 좀 더 발전시켜 해당 웹 페이지에서 필요한 데이터만 추출해 csv 형태로 저장하는 프로젝트로 만들어보자. 먼저 프로젝트를 생성하자. 필요한 데이터를 담는 아이템을 만들어 스파이더 프로그램을 작성한 후 csv로 저장되는 크롤링을 구현해 보자. 프로젝트 생성 시 주의할 점은 다른 프로젝트와 중복되지 않도록 해야 한다는 것이다. /home/<user>/<scrapdir> 디렉터리에서 보통 프로젝트를 생성한다. 프로젝트를 생성하면 /home/<user>/<scrapdir> 하위에 프로젝트의 루트 디렉터리 (/home/<user>/<scrapdir>/<projectname>)가 위치하게 된다. 또한 웹 사이트를 분석해 데이터 구조를 분석해 아이템을 작성해야 하고, 링크 구조를 분석해 스파이더 프로그램을 작성해야 한다. 하지만 한 프로젝트의 사이클을 간략히 구현하는 것이 샘플 프로그램의 목적이므로 자세한 설명은 예제 프로그램 작성에서 하기로 하고 여기서는 작동되는 방법만 설명한다.






Scrapy 명령어



전역 명령어
startproject

shell

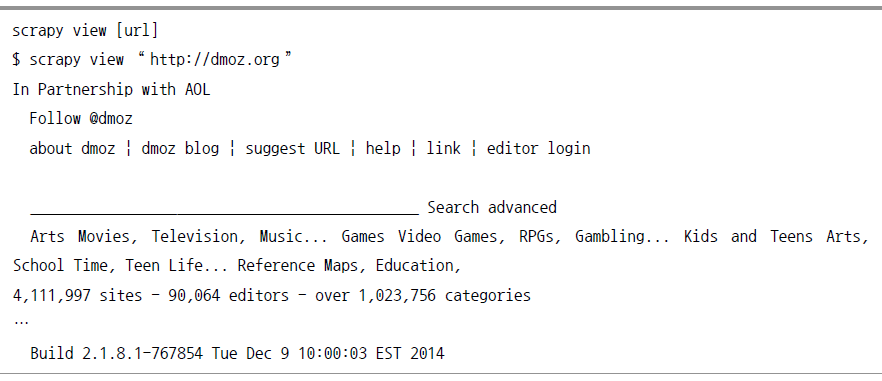
view
runspider

version

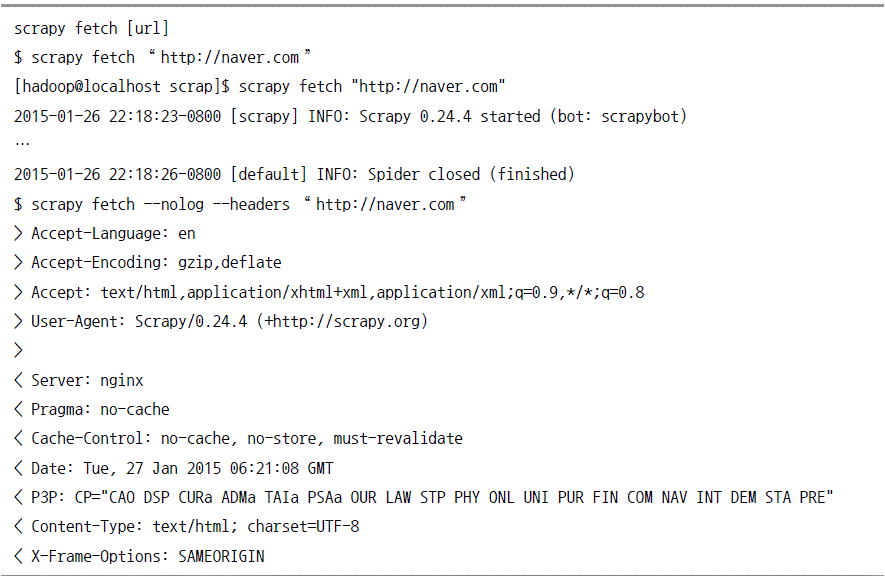
fetch
setting

프로젝트 명령어
crawl

check

list

edit

genspider



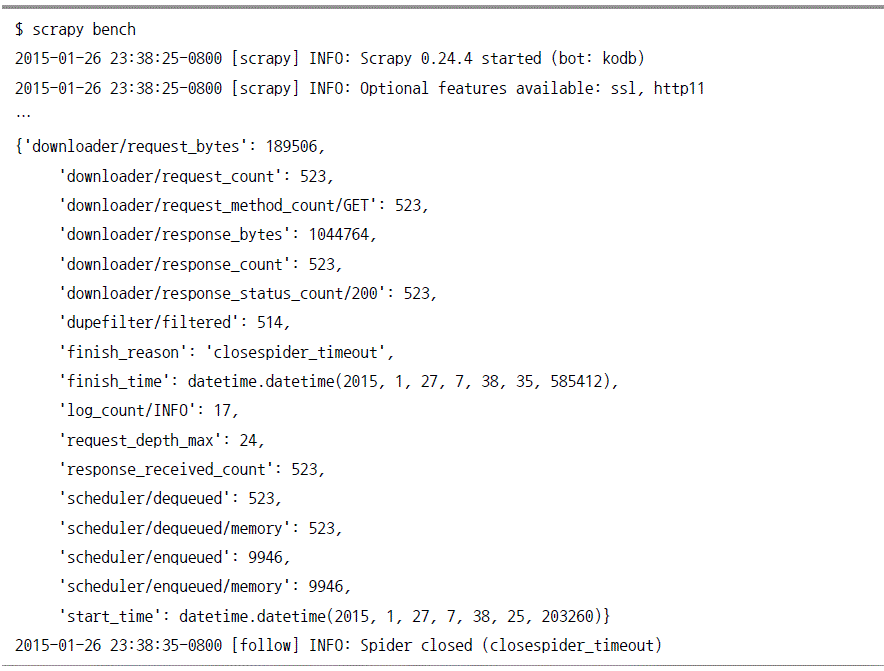
bench
웹 크롤링을 위해 꼭 필요한 Scrapy 기능
아이템 클래스
아이템 필드
아이템 선언

아이템 적용




셀렉터
xpath 표현식의 이해


![[]기호](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_49.gif)
![[]기호](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/123_bigdata_50.gif)



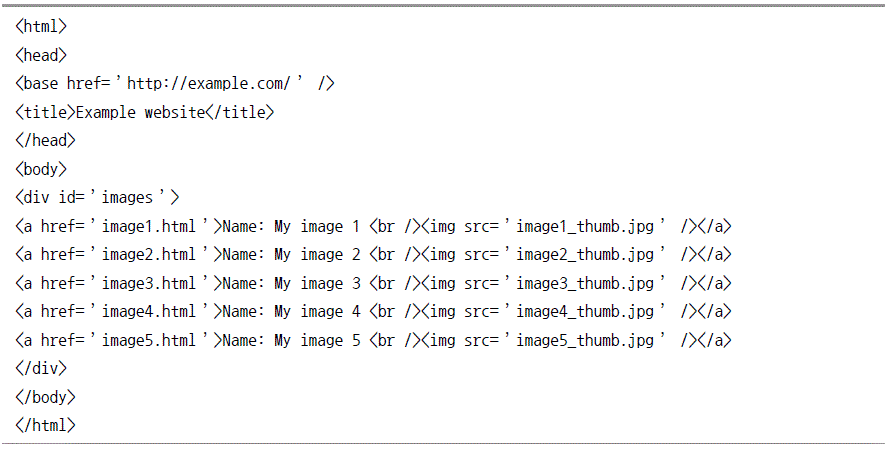
셀렉터 실습


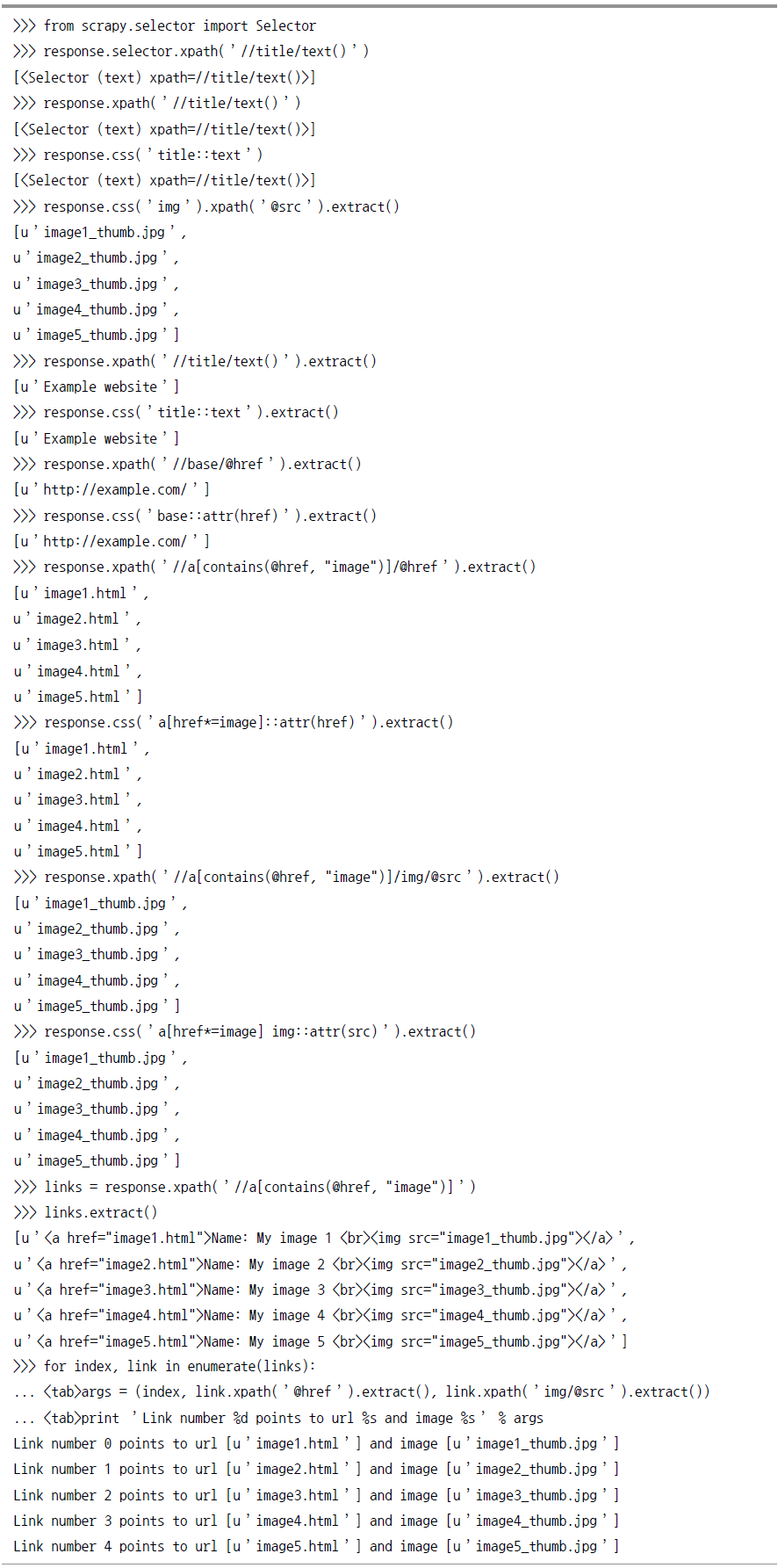
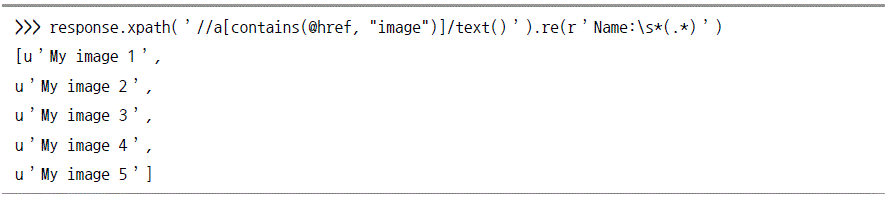
Scrapy 실습
실습 시나리오
크롤링할 사이트 탐색
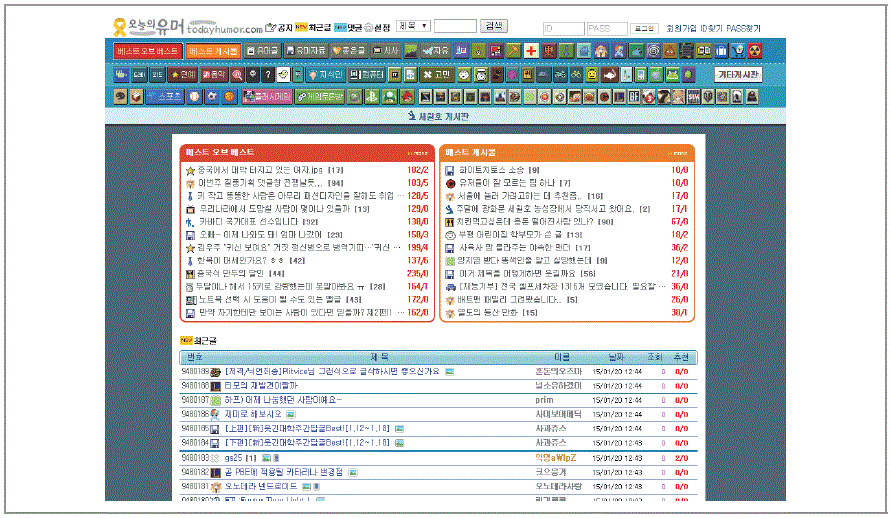
시나리오 설계
사이트 분석
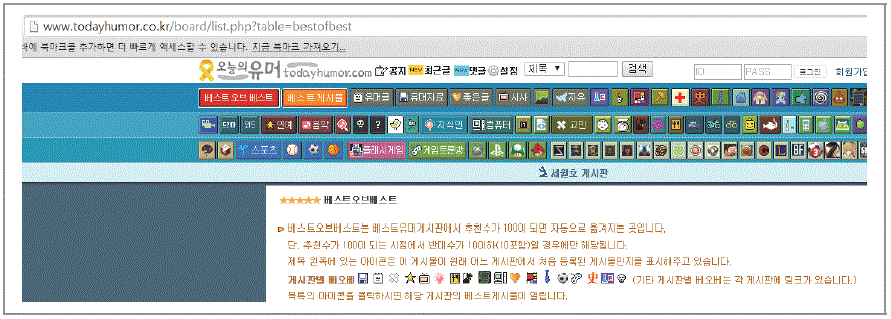
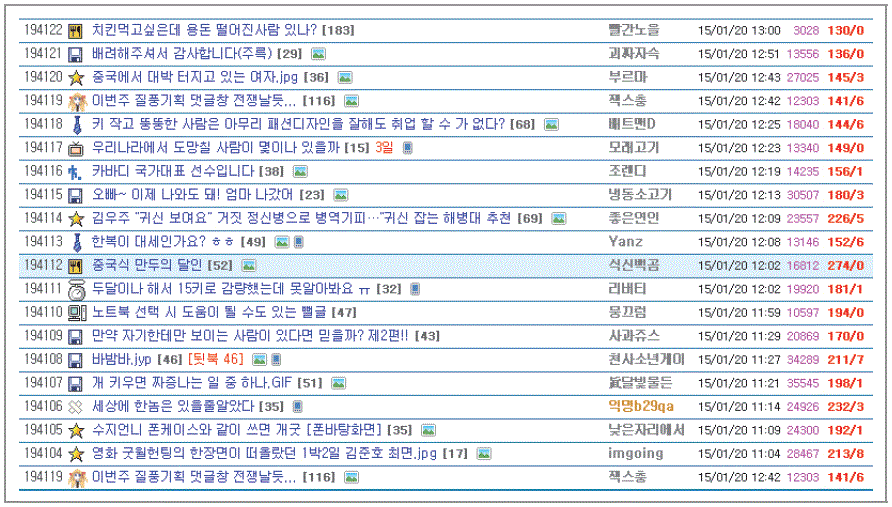

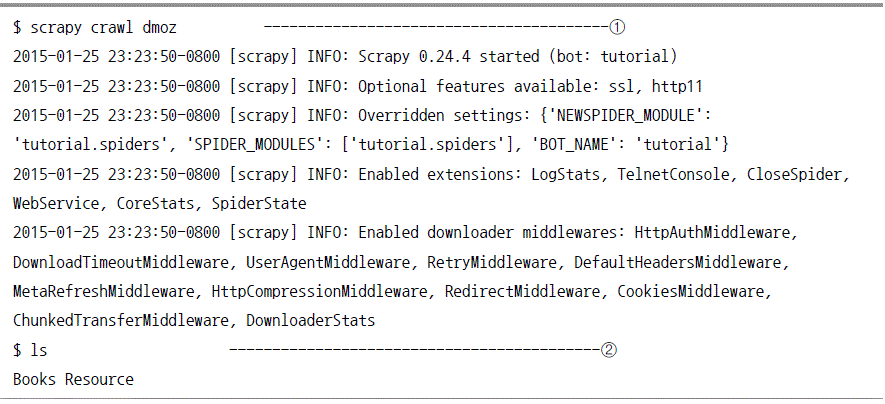
오늘의 유머 웹 크롤링
프로젝트 만들기

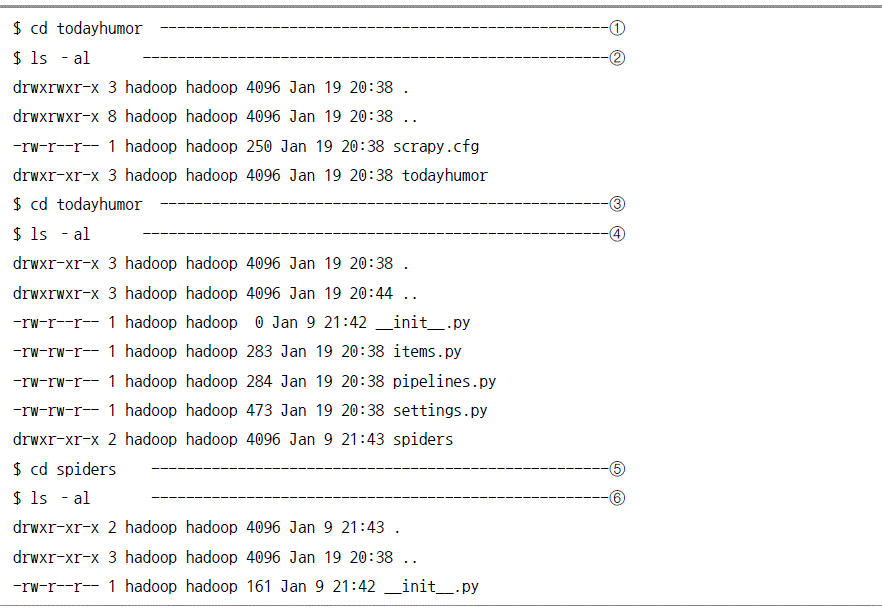
아이템 설정
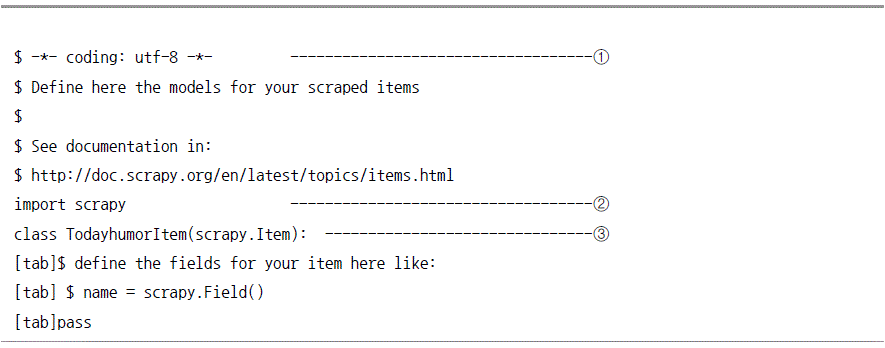
디폴트로 선언된 클래스는 프로젝트 이름에 Item이 붙어 명명된다. 물론 수정도 가능하다.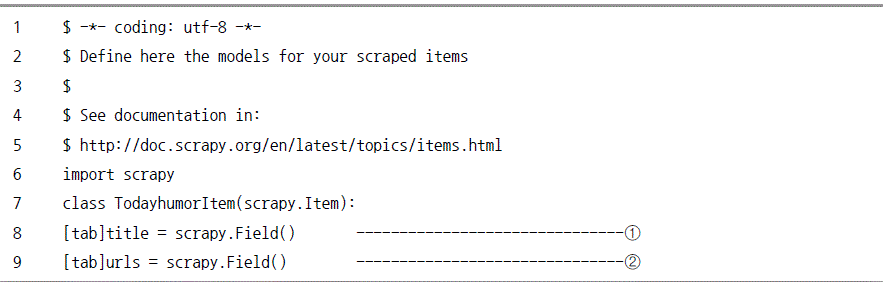
아이템과 데이터 매핑을 위해 shell 명령어 사용





스파이더 프로그램 작성


class Todayhumor(CrawlSpider): → class Todayhumor(BaseSpider):
스파이더 프로그램 테스트

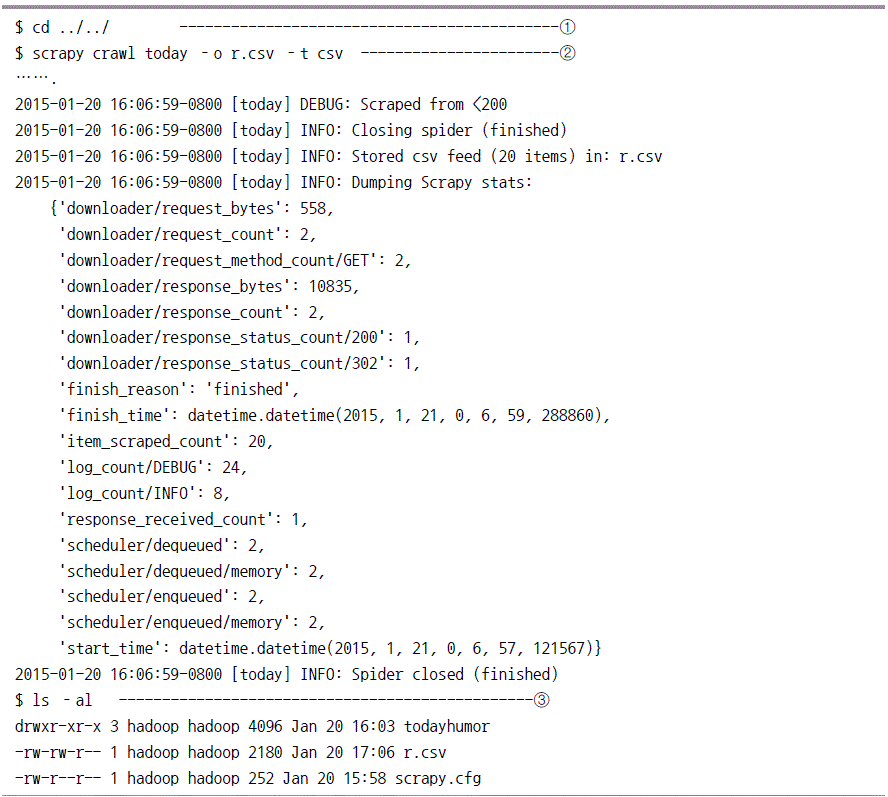



웹 크롤링 프로그램 버그 수정
버그로 정의된 내용을 해결하기 위해 정의된 버그들 상호간에 의존성은 없는지, 그리고 버그 하나하나가 기능요소의 수정인지 아니면 기능요소의 추가인지 결정하고 버그를 해결해야 한다. 실습으로 진행한 프로젝트에서는 두 개의 버그가 발견되었다. 첫 번째는 지정한 한 페이지만 가져오는 것이고, 두 번째는 가져온 url이 불완전하다는 뜻이다. 첫 번째와 두 번째는 서로 독립적으로 상호 의존성을 갖고 있지 않기 때문에 각각 하나씩 수정하면 될 것이다.
첫 번째 버그 해결을 위한 디버그
http://todayhumor.co.rk/board/list.php?table=bestofbest로 접속해 브라우저 화면에서 분석해 보자.

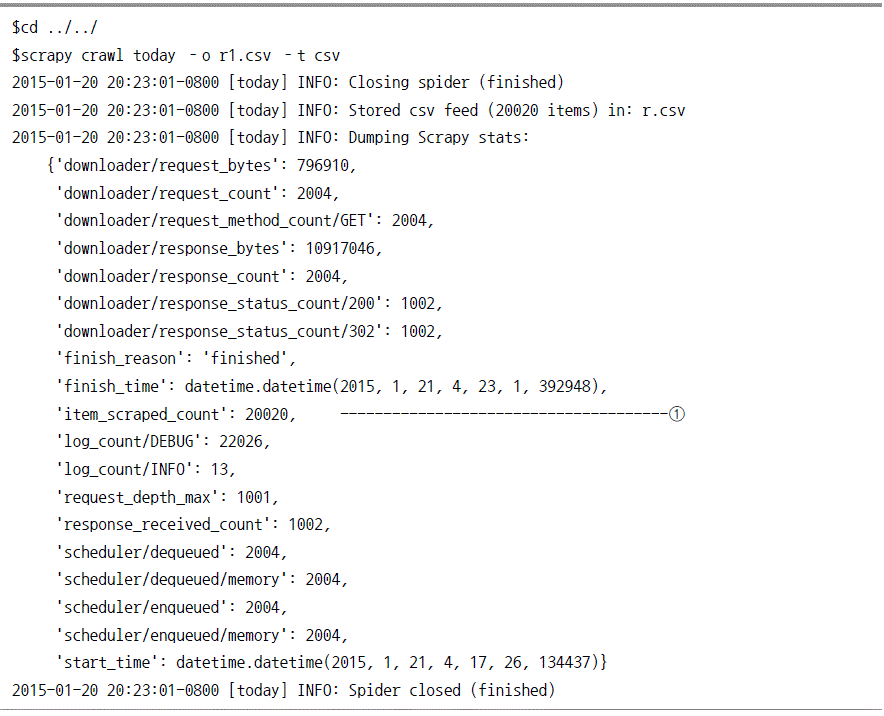
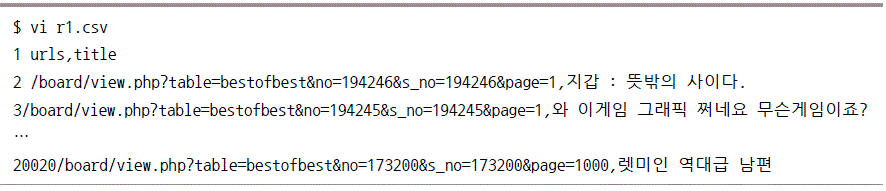
두번째 버그해결을 위한 디버그
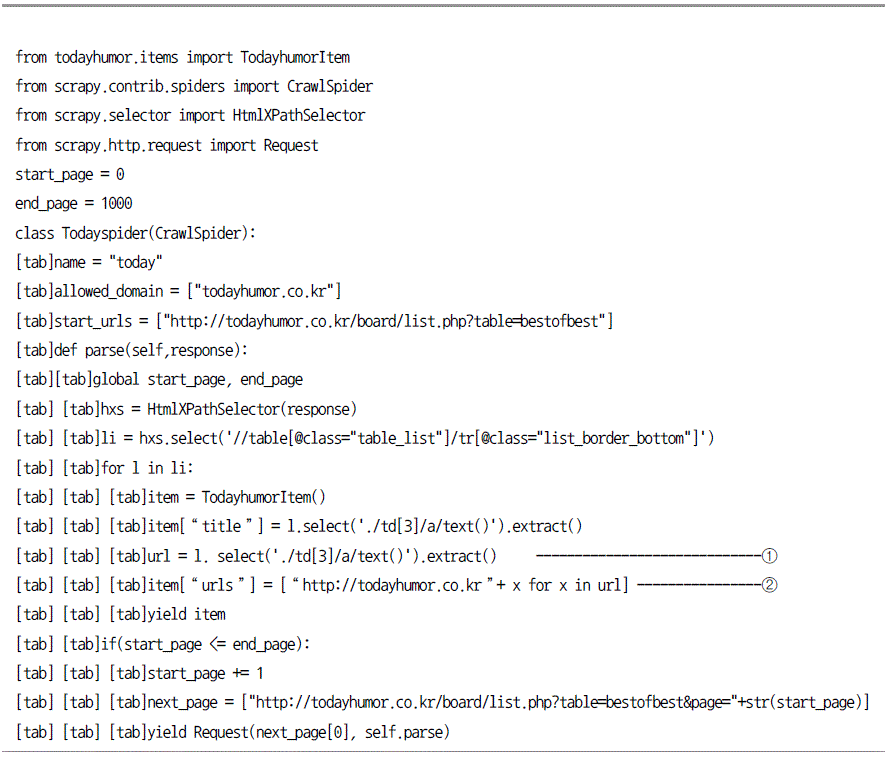

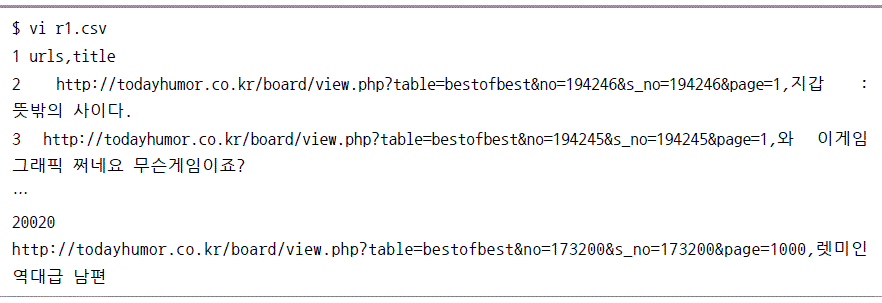
크롤링 데이터를 하둡으로 저장
아키텍처 구성흐름은 다음과 같다.
플룸 설정
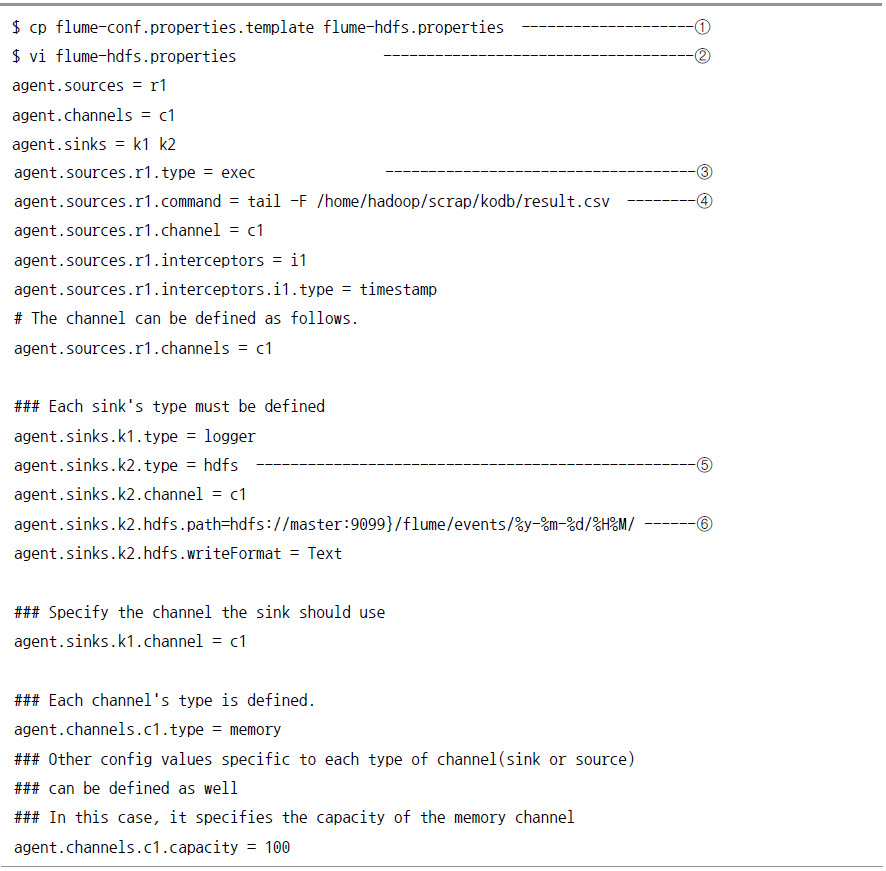
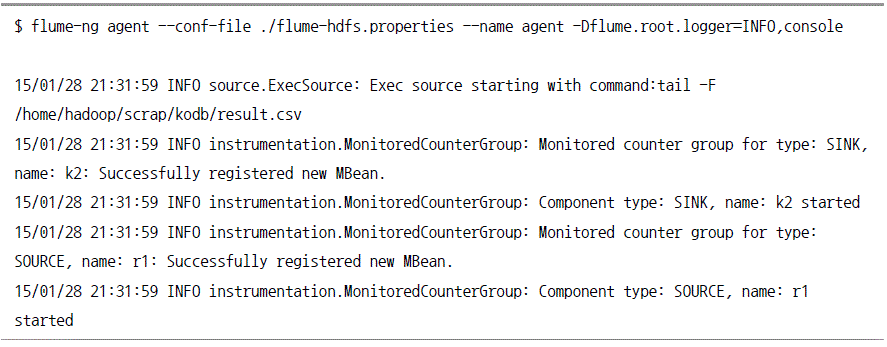
웹 크롤링

플룸 및 하둡확인

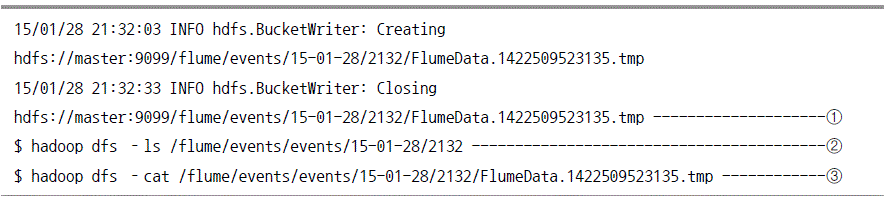
관계형 데이터베이스로 크롤링 데이터 저장 실습
시나리오
mysql 테이블 생성

파이썬 mysql db연결용 패키지 인스톨

Scrapy 프로젝트 생성 및 설정

pipelines.py를 다음과 같이 수정한다.



크롤링 실행

mysql 데이터 확인

책의 요약 내용에 big data로 관련된 책은 어떤 책이 있는지 검색해 보자.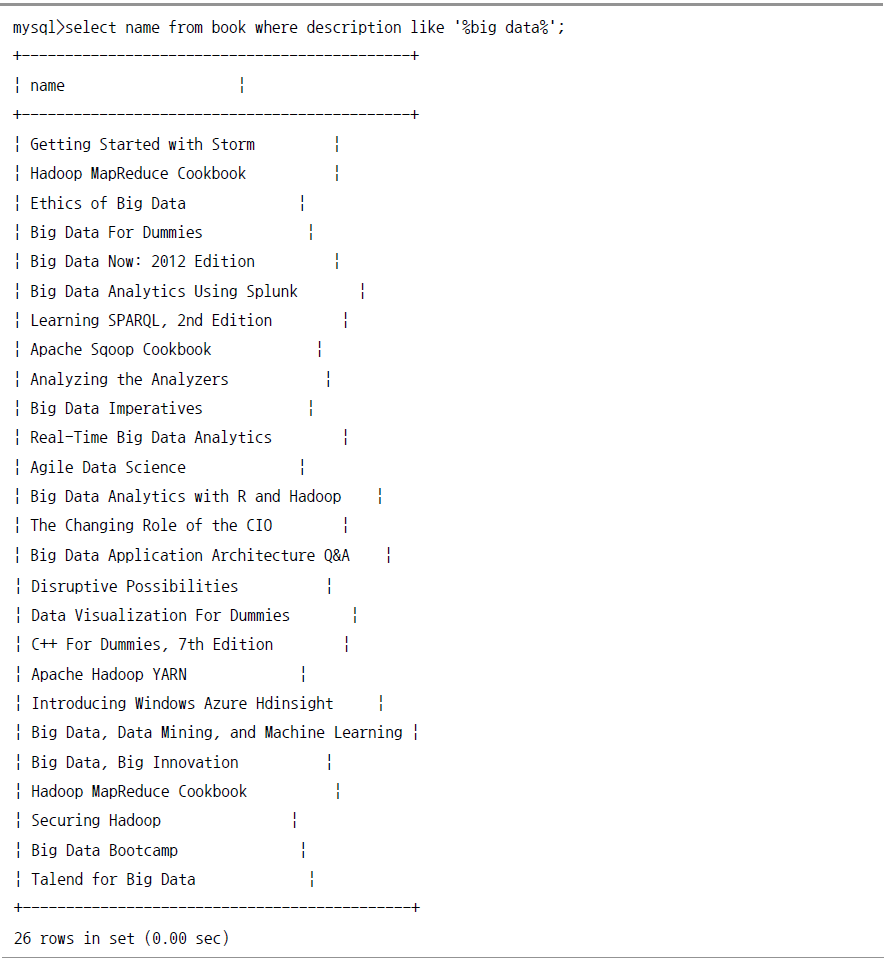
Scrapy에서 어떻게 DBMS로 직접 데이터를 저장하는지를 테스트 해보았다. 단순히 데이터를 직접 DBMS에 넣는 것 이상의 의미를 갖는다. 물론 DBMS를 통한 분석을 제공하는 기능뿐만 아니라 하둡환경에서는 하이브의 메타스토어 기능을 설정해 mysql에 저장된 데이터를 직접 하둡의 파일시스템과 연동할 수 있다.
웹 스크롤링 실습과 시사점