
데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
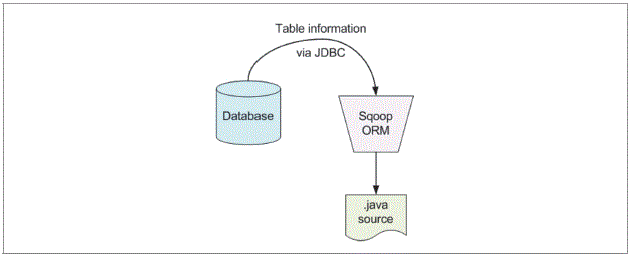
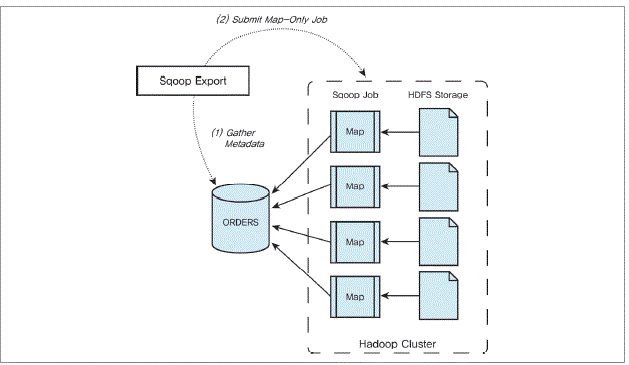
빅데이터 분석시 분산환경(하둡)과 데이터베이스 시스템의 데이터를 연계해 분석할 필요가 있다. 그러기 위해서는 정형 데이터인 데이터베이스 시스템의 데이터와 분산환경(하둡)에 저장된 데이터를 통합해야 한다. 관계형 데이터베이스 상호간에도 데이터를 통합하기 위해서는 벤더에서 제공하는 제품이 필요하다. 하둡과 정형 데이터베이스 시스템 간 통합을 위해서 마찬가지로 상호 연결할 수 있는 브리지가 필요하다. 관계형 데이터베이스 수집에서는 관계형 데이터베이스와 하둡을 연결할 수 있는 프로그램에 대해 알아보자. [그림 Ⅰ-2-4] 브리지의 필요성 하둡과 관계형 데이터베이스와 같은 정형 데이터 저장소간에 데이터를 효과적으로 전달하기 위해 시작된 스쿱(Sqoop)은 2012년 4월 아파치 인큐베이터 프로젝트로 출발해 지금은 아파치의 톱레벨프로젝트가 됐다. 이번 절에서는 Sqoop1.4.5 버전의 설치와 운영에 관해 알아보겠다. (가장 최근 stable 버전은 1.4.5다.) 스쿱(Sqoop)은 하둡과 데이터베이스 간 데이터 이동을 간편하게 하기 위해 개발됐다. 데이터를 분석하면서 하둡에서 데이터베이스의 정보를 가져올 일이 있거나 반대로 하둡의 결과를 데이터베이스로 올릴 때에 사용된다. 스쿱은 어떤 패키지나 프레임워크가 아닌, 하둡에서 제공하는 데이터베이스 연결용 맵 인풋 포맷터를 사용한다. 그것이 바로 DBInputFormater와 DBWritable이다. 이 과정에서 타입의 변환이 일어난다. 다음은 JDBC와 Java 타입을 비교한 것이다. [표Ⅰ-2-4] 데이터 타입 비교 [그림Ⅰ-2-5] 스쿱 아키텍처 [그림 Ⅰ-2-5]와 같이 스쿱은 DBMS 벤더에서 제공하는 JDBC를 사용해 스쿱의 ORM을 거쳐 하둡으로 저장처리 하기 위한 자바(Java) 소스를 생성한다. JDBC로 테이블 정보를 읽어 들인 다음, 맵리듀스에서 사용할 수 있도록 데이터 형 변환용 자바 클래스를 생성한다. 생성한 자바 클래스(위젯)의 예는 다음과 같다. 이 정보를 사용해 스쿱에서 데이터베이스를 읽어올 때, 각 필드의 값을 mapper의 recordreader에 전달하는 데 사용한다. [그림Ⅰ-2-6] 스쿱 잡 리듀스 [그림 Ⅰ-2-6]와 같이 스쿱은 hdfs 저장소에서 스쿱 잡의 맵정보를 통해 하둡클러스터의 메타데이터를 수집하고 맵온리 잡을 이용해 하둡클러스터에 데이터를 저장한다. 스쿱과 연동하기 위해 먼저 관계형 데이터베이스를 설치한다. 관계형 데이터베이스는 오픈소스 데이터베이스인 mysql을 선택했다. mysql을 설치하자. mysql 연동 테스트용 샘플 데이터를 설치한다. 샘플 데이터로는 mysql에서 제공하는 sakila db(사킬라 샘플 데이터베이스는 mysql에서 제공하는 기능 확인을 위해 예제로 제공되는 데이터베이스다)를 사용한다. 내려 받은 다음에 설치한 mysql 데이터베이스로 올린다. 데이터가 준비됐으면, 스쿱에서 사용할 mysql 계정을 생성한다. 본 예제에서는 샘플 데이터베이스의 이름을 hadoop으로 했으며, 접근 계정과 암호를 각각 hadoop과 hadoop00으로 사용했다. mysql 설정이 완료되었으면 스쿱을 설치한다. 스쿱은 가장 최근의 안정 버전인 1.4.5를 사용하고, 하둡은 1.0.X대의 버전을 사용할 것이므로 1.0.0이 표시된 것을 내려 받는다. 이어서 심볼릭 링크를 만들어 준다. 설치가 완료 되었으면 사용자의 .bash_profile에 SQOOP_HOME을 추가한다. 하둡 설치 디렉터리를 bin/configure-sqoop 파일 가장 아래쪽에 설정한다. 스쿱에서 생성한 맵리듀스 작업은 데이터베이스에서 데이터를 추출(import)하거나 입력(export)할 때에 jdbc를 사용하도록 돼 있다. 따라서 mysql jdbc driver를 $SQOOP_HOME/lib 아래에 복사해 스쿱이 사용할 수 있도록 한다. [그림 Ⅰ-2-7] mysql 개발자 사이트 하둡의 동작상태를 확인한다. 스쿱과 mysql을 정상적으로 설치하고 하둡이 정상적으로 동작한다면 mysql과 하둡간에 데이터를 주고 받는 것을 실습해 보자. 사킬라 DB의 city 테이블 전체를 스쿱을 사용해 하둡으로 복사해 보자. 인자를 적용해 스쿱의 import 명령을 수행해 보자. 다음은 실행결과 화면이다. map 100%로 나오면 import 작업이 완료된 것이다. 실행결과가 제대로 저장되었는지 하둡을 확인해 보자. 하둡에서 결과값이 어떻게 나오나 확인해보자. mysql에서 쿼리결과만 하둡으로 가져와 보자. 인자를 적용해 스쿱의 import 명령을 수행해 보자. 사킬라 DB의 city 테이블에서 조건에 맞는 데이터 세트를 가져와 하둡의 query_01디렉터리에 저장한다. 다음은 실행결과 화면이다. 데이터베이스 전체를 하둡으로 가져오는 방법을 알아보자. 다음은 실행 화면이다. 하둡에 저장된 파일을 사킬라 DB의 테이블에 스쿱을 사용해 삽입해보자. 하둡의 하이브 테이블과 mysql과 연동하기 위해서는 다음과 같이 명령어를 입력해야 한다. 만약 시스템에 하이브가 설치돼 있고 하이브에 직접 스쿱을 이용해 데이터를 저장하면 하이브의 고수준 쿼리 언어인 HiveQL을 사용할 수 있기 때문에 하둡의 맵리듀스 작업을 거치지 않아도 데이터를 다루는 데 편리하다.관계형 데이터베이스 수집
스쿱 소개
스쿱 소개
- JDBC와 인터페이스
- SQL을 통해 테이블에서 Row 추출
- DB, 테이블, 질의를 인자로 입력
- 데이터베이스의 Row를 기록
- JDBC의 ResultSet를 읽어서 필드로 변환
데이터 타입
JDBC 타입
Java
8,000자까지 고정길이 문자타입
CHAR
String
8,000자까지 고정길이 문자타입
VARCHAR
String
문자열
LONGVARCHAR
String
-10의 38승+1에서 10의 38승 -1 사이의 고정 정밀도 숫자형
NUMERIC
java.math.BigDecimal
-10의 38승+1에서 10의 38승 -1 사이의 고정 정밀도 숫자형
DECIMAL
java.math.BigDecimal
논리형
BIT
boolean
0~255까지의 정수형
TINYNIT
byte
2의 15승에서 2의 15승-1 사이의 정수형
SMALLINT
short
-2의 31에서 2의 31승-1 사이의 정수형
INTEGER
int
-2의 63에서 2의 63승 -1까지의 정수형
BIGINT
long
-3.40E + 38에서 3.40E + 38 사이의 부동 정밀도 숫자
REAL
float
-1.79E + 308에서 1.79E + 308 사이의 부동 정밀도 숫자
FLOAT
double
스쿱 아키텍처

스쿱의 맵 온리 잡 리듀스 처리방법
다음은 스쿱에서 사용하는 DBWritable에 있는 인터페이스다. readFields()와 write() 메소드에서 위에서 생성한 위젯을 사용해 정보를 전달할 수 있다.
스쿱 설치
패키지 설치
관계형 데이터베이스 설치
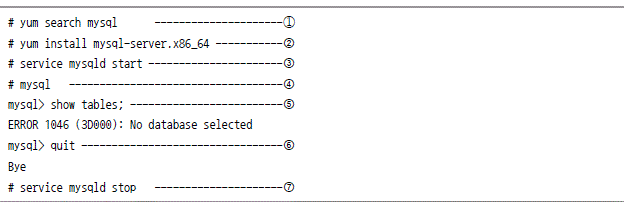

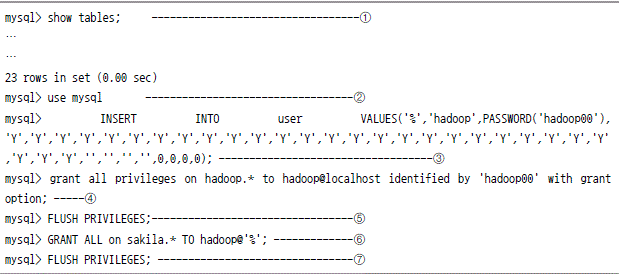
스쿱설치




http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.34.tar.gz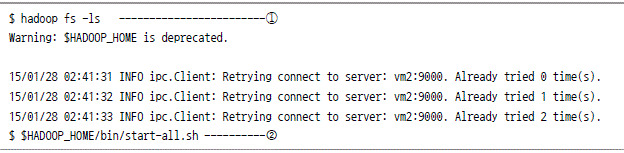
스쿱과 하둡의 연동
mysql에서 하둡으로 데이터 가져오기
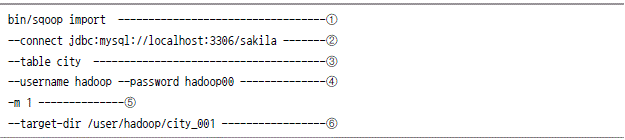



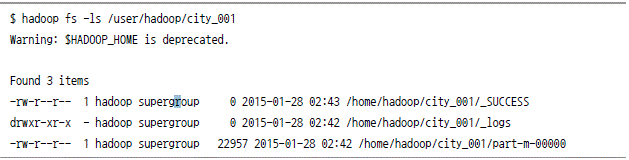
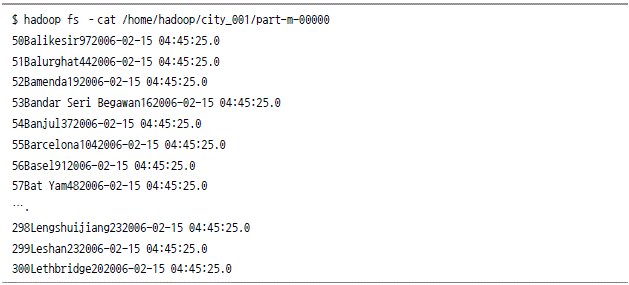


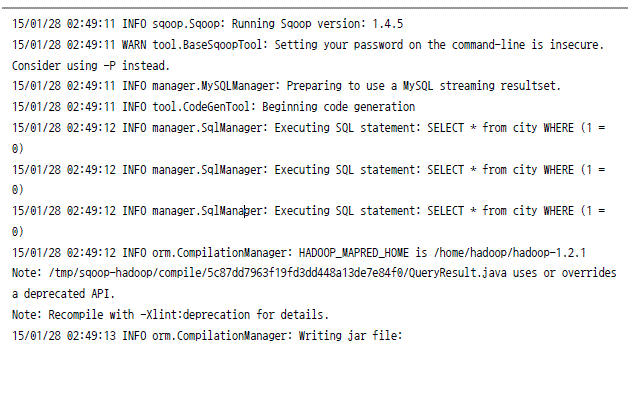
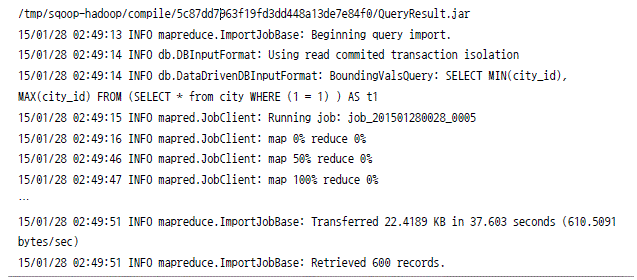

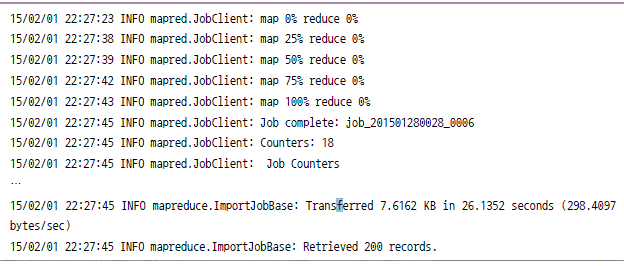
하둡에서 mysql로 데이터 저장하기

하둡의 하이브와 연동
실습을 통해 살펴 보았듯이 스쿱은 DBMS와 하둡 시스템과의 브리지 역할을 한다. 스쿱을 하둡파일 시스템의 관점에서만 보면 단순히 DBMS와 하둡과의 데이터 인터페이스 역할만 한다. 하지만 DBMS의 관점에서 보면 스쿱은 하둡 파일 시스템 외에도 로컬 시스템의 CSV, Avro, Thrift Binary까지 지원하므로 이를 활용하면 데이터 수집 시 훨씬 유연한 아키텍처를 구성할 수 있을 것이다.