데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
로그 데이터는 빅데이터 관련 기술의 혜택을 가장 많이 받은 데이터일 것이다. IT 환경에서 가장 많이 발생하는 데이터지만, 데이터 처리 기술이 최근처럼 발달하지 않았던 시기에는 처리 비용에 비해 가치가 낮은 데이터로 여겨졌다. 하지만 지금은 사물인터넷(IoT)의 급부상과 함께 그 효용성이 날로 증가하고 있다. [표Ⅰ-2-1] 로그데이터 수집 시 고려할 사항 대표적인 로그 수집기로서 아파치의 FLUME과 Chukwa, 페이스북에서 스트리밍 데이터를 처리하기 위해 개발된 Scribe를 들 수 있다. 다음표는 로그수집 프로그램의 현황이다. [표Ⅰ-2-2] 주요 로그 수집 프로그램 다음 표는 로그수집 프로그램을 비교하여 요약한 것이다. [표Ⅰ-2-3] 로그 수집 프로그램 비교 살펴본 바와 같이 여러 가지 로그수집을 위한 프로그램들이 존재하고 있다. 이제 로그수집에서 실습할 프로그램으로 가장 장점이 많고 일반적으로 현업에서 많이 사용하고 있는 플룸을 사용해 로그수집 실습을 하겠다. 로그수집 프로그램은 로그 수집방법의 특성을 고려해 프로그램의 설정과정과 기술이 가지고 있는 기능에 대해 실습을 통해 학습하기 바란다. 플룸(flume)은 빅데이터 플랫폼에 로그를 전달하기 위해 개발됐다. 로그를 수집하는 플랫폼으로서 플룸 이전에도 rsyslog와 같은 툴이 있었지만, 플룸은 하둡에 직접 데이터를 저장할 수 있고 여러가지 경로와 장애 대응 기능을 가지고 있어서 대규모의 로그 데이터를 처리하기 매우 편리하다. 플룸은 아파치 톱 레벨 프로젝트로 로그 데이터 수집 시 가장 많이 사용하는 방법이다. 플룸은 [그림Ⅰ-2-1]과 같이 데이터를 받아들이는 소스, 소스와 싱크를 연결하는 채널, 데이터를 처리하는 싱크라는 세 개의 영역으로 구성돼 있다. [그림 Ⅰ-2-1] 플룸에서 데이터 흐름 수집대상(Target) 데이터를 받아 들이는 영역이다. 소스(source)의 종류는 다음과 같다. 데이터를 저장하거나 전달하는 영역이다. 싱크(Sink)의 종류는 다음과 같다. 소스와 싱크와 사이에서 상호 연동 기능을 지원한다. 어떤 채널(channel)을 선택하느냐에 따라 이벤트 전달의 신뢰도가 다음과 같이 영향을 받는다. 플룸 아키텍처는 [그림Ⅰ-2-2]와 같이 컨피그 → 소스 → 채널 → 싱크의 네 가지 모듈로 순차적으로 작동한다. [그림Ⅰ-2-2] 플룸 아키텍처 플룸의 작업 파일을 읽어서 채널, 소스, 싱크를 설정한다. 내부적으로 30초마다 컨피규레이션 파일을 로드하도록 돼 있어서 플룸을 재시작하지 않아도 워크플로를 재설정할 수 있다. 채널은 이벤트의 트랜잭션을 관리하고, 소스에서 보낸 이벤트를 큐(Queue)에 저장한다. 그리고 소스에서 보낸 putlist와 싱크에서 가져간 takelist를 통해 트랜잭션을 관리하도록 돼 있다. 컨피그에서 설정된 체널의 리스트를 가져 온 다음, 채널에 있는 큐에서 메시지를 꺼내 처리한다. 이 때, 채널에서 트랜잭션 처리를 한다 플룸이 작동하도록 하기 위해서 소스, 채널과 싱크를 묶어 하나의 동작으로 만들어야 한다. 에서 사용할 소스ㆍ싱크ㆍ채널을 위와 같이 정의하면, 하나의 워크플로가 작성된다. 플룸을 설치하기 위해서 사이트(flume.apache.org)에 접속해 패키지를 내려 받는다(여기서는 1.5.2버전을 사용한다.) 주의할 것은 파일 이름 중간에 bin이 들어간 버전을 받아야 한다는 점이다. (그렇지 않으면, 빌드를 수행해야 한다.) 내려 받은 다음에 tar 명령어를 사용해 압축을 푼다. 그리고 버전 관리를 쉽게 하기 위해 소프트링크를 생성한다. 수집대상(Target) 데이터를 받아 들이는 영역이다. 소스(source)의 종류는 다음과 같다. FLUME_HOME이라는 환경변수에 방금 설치한 플룸 경로를 입력해 사용자의 bash_profile에 저장한다. 이어서 FLUME_CONF_DIR이라는 변수를 입력한다. 이 환경 변수는 플룸 프로세스가 사용하는 설정 파일을 읽어 들인다. 설치가 완료됐으면 샘플 워크플로를 수행해 정상적으로 작동하는지 확인한다. 플룸에서 제공하는 샘플 워크플로 파일은 $FLUME_HOME/conf 디렉터리 아래의 flume-conf.properties.template에 있다. vi 편집기를 사용해 파일을 열어 확인해 보면 다음과 같다. conf/flume-env.sh에서 java 경로를 지정한다. 해당 파일을 복사해 실제 워크플로 파일을 생성한다. 파일이 생성 되었으면 flume-agent를 사용해 실제 워크플로를 수행한다. 위의 인자로 잘 수행되었다면 아래와 같이 단계적으로 증가하는 숫자가 화면에 나타날 것이다. Netcat 서버를 통해 소스에서는 네트워크 서버를 구동하고, 결과는 터미널을 통해 확인하는 실습을 해 본다. Network Stream log의 워크플로 파일을 다음과 같이 작성한다. 워크플로 파일이 완성됐으면 다음 명령어를 사용해 워크플로를 실행한다. 정상적으로 수행됐으면 다음과 같이 화면이 출력되고 스크린의 마지막에 [127.0.0.1:4444]로 이벤트의 발생을 대기하고 있다는 메시지가 출력될 것이다. 정상적으로 대기상태 확인이 되었다면 터미널을 하나 더 열어 텔넷으로 대기상태에 있는 서버를 호출하고 출력을 원하는 스트링을 입력해 보자. 정상적으로 작동됐다면 플룸을 수행한 창에서도 동일하게 [hello this is test]라는 문자열이 출력될 것이다. flume-ng 버전에서는 source 중에 tail이라는 것이 없다. 대신 exec 타입의 소스가 존재하는데 이 타입에서 tail을 통해 데이터를 전송해 보자. secure 파일을 업데이트하기 위해 서버에 반복적으로 ssh를 수행하는 쉘스크립트를 아래와 같이 작성하고 바로 수행한다. 정상적으로 수행됐다면, ssh로 접근하는 호스트의 이름이 계속 출력된다. 플룸 에이전트를 수행한다. 에이전트 수행 전에 /var/log/secure의 퍼미션을 누구나 읽고 쓸 수 있도록 변경한다. (실제 상황에서는 보안상 좋지 않으므로 주의하자.) 정상적으로 수행됐으면 다음과 같이 event body쪽의 시간이 계속 출력되는 것을 확인할 수 있다. 2개의 에이전트를 통해 데이터를 주고 받는 경우를 구성해보자. [그림Ⅰ-2-3] 멀티에이전트 플룸 데이터 흐름 Agent1의 플룸 워크플로 파일을 생성한다. Agent2에서 사용할 플룸 워크플로 파일 생성한다. 2개의 템플릿이 완성됐으면 먼저 avro 서버의 플로우를 갖고 있는 agent2를 수행한 다음, agent1을 수행한다. 먼저 agent2를 실행한다. 터미널을 하나 더 열어 agent1를 실행한다. agent1에서 데이터 소스를 syslog를 지정했으므로 다음 명령어를 수행한다. 정상적으로 세팅돼 있는지 확인하기 위해 agent2를 실행한 화면의 로그를 확인한다. 플룸과 하둡을 연결하기 위해서는 hdfs 싱크를 사용한다. 플룸 워크플로 파일을 열어 설정에 싱크를 다음과 같이 추가한다. 새로운 터미널을 오픈해 플룸을 수행한다. 수행하다 보면 다음과 같은 에러가 발생한다. 에러가 발생하는 이유는 timestamp가 헤더에 없기 때문이다. 에러를 해결하기 위해 플룸의 싱크에 인터셉트를 사용해 timestamp를 추가한다. 새로 작성한 워크플로를 다시 실행한다. 다음과 같이 터미널에 하둡의 파일이 연속해서 특정 디렉터리로 rename이 된다면 정상적으로 작동하는 것이다. 플룸을 통해 로그 수집 실습을 해 보았다. 로그 수집기는 단순히 우리가 인식하는 로그만 수집하는 것이라는 편견만 버리면 다방면으로 활용될 수 있다. 시스템의 내부로 들어 오는 모든 데이터를 로그라 인식한다면, 플룸에서 제공하는 로그 수집 기능들을 이용해 파일 및 DBMS에서 변화하는 데이터를 하둡으로 또는 DBMS로 저장ㆍ처리하는 등 다른 수집방법에서 사용되는 수집기술들 간에 훌륭한 인터페이스 역할을 할 수 있을 것이다.로그 데이터 수집
로그 데이터를 수집해야 할 상황이라면, 수집환경과 수집 데이터를 처리하고자 하는 시스템을 고려해 수집기술을 선택해야 한다. 로그데이터를 수집하기 위한 수집기술 선택 시 고려해야 할 사항은 확장성, 안정성, 유연성, 주기성이다.
확장성
수집의 대상이 되는 시스템이 얼마나 늘어날 것인가?
안정성
수집되는 데이터가 손실되지 않고 안정적으로 저장 가능한가?
유연성
다양한 데이터의 형식과 접속 프로토콜을 지원하는가?
주기성
수집 데이터가 실시간으로 반영돼야 하는가 혹은 배치처리를 해도 가능한가?
FLUME
(아파치 톱 레벨 프로젝트)Scribe
(페이스북 오픈소스)Chukwa
(아파치 인큐베이터 프로젝트)
개발 주체
아파치
페이스북
아파치
특징
대용량 로그 데이터를 안정성, 가용성을 바탕으로 효율적으로 수집
수많은 서버로부터 실시간으로 스트리밍 로그 수집
하둡의 서브 프로젝트로 분산서버에서 로그 데이터를 수집ㆍ저장ㆍ분석하기 위한 솔루션
구분
FLUME
Scribe
Chukwa
수집방법
다양한 소스로부터 데이터를 수집해 다양한 방식으로 데이터를 전송할 수 있다.
아키텍처가 단순하고 유연하며, 확장 가능한 데이터 모델을 제공하므로 실시간 분석 애플리케이션을 쉽게 개발할 수 있다.클라이언트 서버의 타입에 상관없이 다양한 방식으로 로그를 읽어 들일 수 있다.
수집된 로그 파일을 hdfs에 저장한다.
처리방법
각종 Source, Sink 등을 제공하므로 쉽게 확장이 가능하다.
단, Apache Thrift는 필수. Thrift 기반 Scribe API를 활용해 확장 가능하다.
hdfs의 장점을 그대로 수용했고, 실시간 분석도 가능하다.
특징
최근 국내의 빅데이터 솔루션에서 수집 부분에 많이 채택되고 있다.
페이스북의 자체 Scaling 작업을 위해 설계돼 현재 매일 수백 억 건의 메시지를 처리하고 있다
지나치게 하둡에 의존적이라는 단점이 있다.
[Note]
여기서 모든 실습은 리눅스 기반으로 한다. 실습 시 사용자를 구분할 필요가 있으므로 $는 일반사용자 계정을 의미하고, #은 관리자 권한으로 실행하는 것을 의미한다. ###은 주석 처리함을 의미한다.
플룸 소개
플룸 아키텍처 소개

소스
싱크
채널
플룸 아키텍처 작동 방식
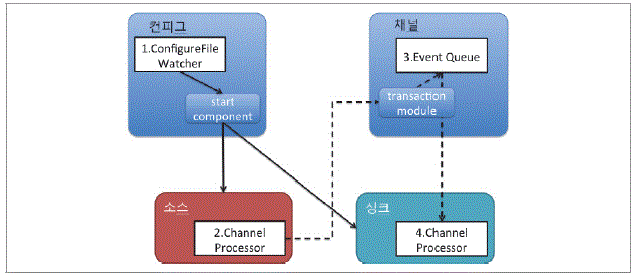
컨피그
소스
채널
싱크
워크플로 작성
워크플로는 플룸이 동작하도록 플룸의 세 가지 요소를 하나의 동작으로 만드는 과정이다. 이렇게 만들어진 워크 플로우는 시스템에서 파일로 관리된다.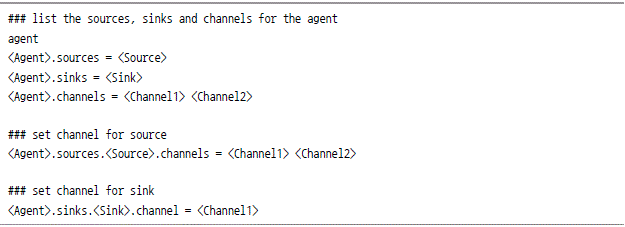
플룸 설치
패키지 설치

소스

워크플로 테스트
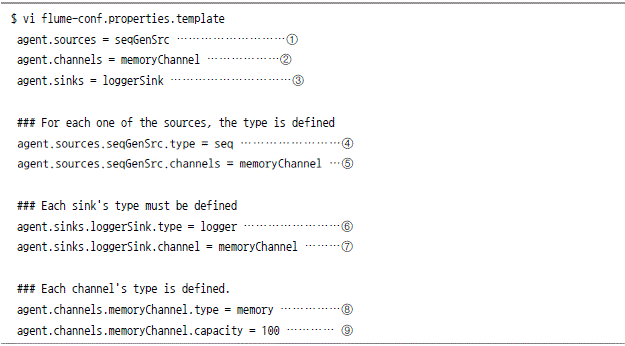
![]()


![2015-01-26 01:36:55,997 INFO source.SequenceGeneratorSource : Sequence generator source starting 2015-01-26 01:36:55,997 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: {headers: { } body: 31 35 30 38 32 15082} 2015-01-26 01:36:55,997 {SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers: { } body: 31 35 30 38 33 15083 } 2015-01-26 01:36:55,997 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers: {} body: 31 35 30 38 34 15084} 2015-01-26 01:36:55,98 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers: { } body: 31 35 30 38 35 15085 }](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_10.gif)
플룸과 데이터 소스의 연결
Network Stream logging
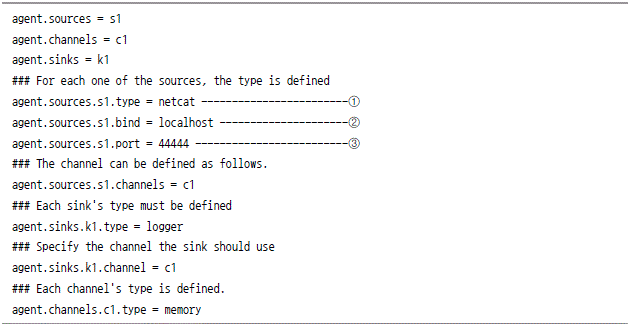

![2015-01-26 01:40:23,620 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:145)] Starting Channel c1 2015-01-26 01:40:23, 622 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:160)] Waiting for channel: c1 to start. Sleeping for 500 ms 2015-01-26 01:40:23, 698 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MoniteredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean. 2015-01-26 01:40:23, 702 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitorCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started 2015-01-26 01:40:24, 123 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:173)] Starting Sink k1 2015-01-26 01:40:24, 124 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Starting Source s1 2015-01-26 01:40:24, 126 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:150)] Source starting 2015-01-26 01:40:24, 141 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:164)] Created serverSocket: sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_13.gif)
![$ telent localhost 44444 Trying::1... telnet: connect to address::1: Connection refused Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. hello this is test OK](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_14.gif)
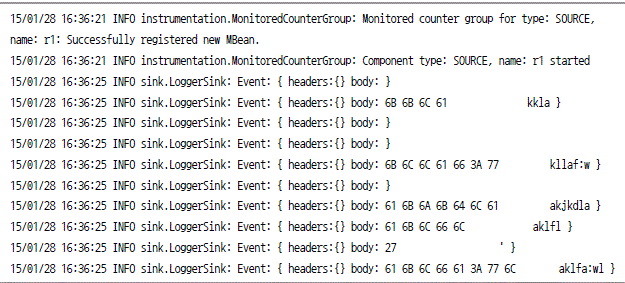
![2015-01-26 01:41:42, 159 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume. sink.LoggerSink.process(LoggerSink.java:70)] Event: {headers: { } body: 68 65 6C 6C 6F 20 74 68 69 73 20 69 73 20 74 65 hello this is test }](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_15.gif)
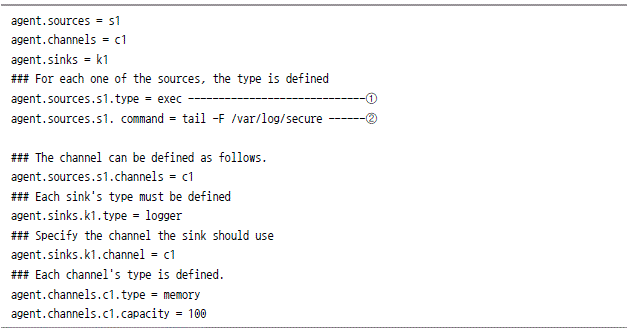
테일 실습
![$ while [ 1 -le 2 ] ; do ssh server name hostname ; done server server server server](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_17.gif)

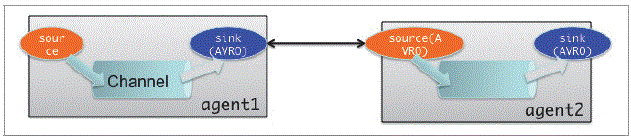
Multi-agent



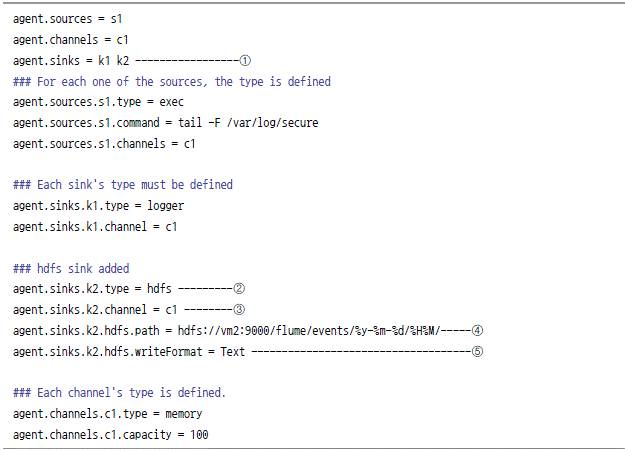
![]()
![13/11/24 19:04:32 INFO source.AvroSource: Avro source s2 started. 13/11/24 19:05:47 INFO ipc.NettyServer: [id: 0x18987a33, /127.0.0.1:44657 => /127.0.0.1:44657 => /127.0.0.1:10000] BOUND: /127.0.0.1:1000013/11/24 19:05:47 INFO ipc.NettyServer: [id: 0x18987a33, /127.0.0.1:44657 => /127.0.0.1:10000] CONNECTED: /127.0.0.1:44657 13/11/24 19:06:14 INFO sink.LoggerSink: Event: { headers: {Serverity=1, Facility=4} body: 20 68 65 6C 6C 6F 20 76 69 61 20 73 79 73 6C 6F hello via syslo } 13/11/24 19:06:29 INFO sink.LoggerSink: Event: { headers: {Serverity=1, Facility=4} body: 20 68 65 6C 6C 6F 20 76 69 61 20 73 79 73 6C 6F hello via syslo }](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/121_bigdata_26.gif)
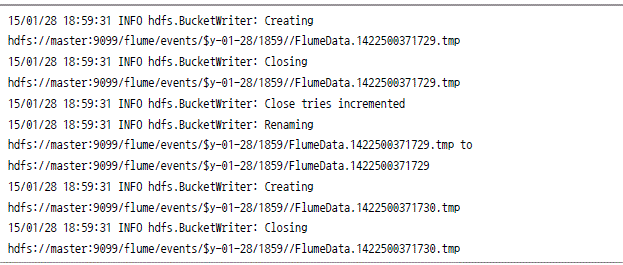
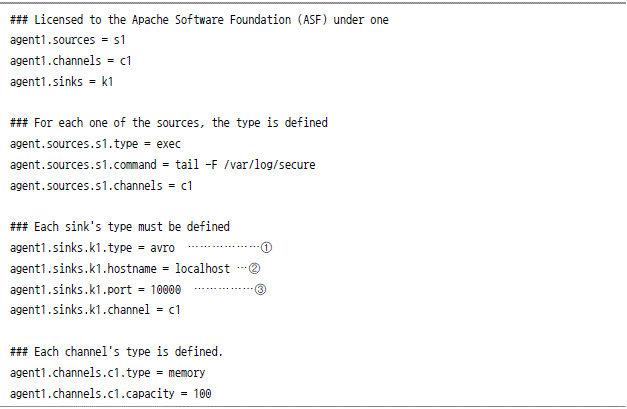
플룸과 하둡의 연결


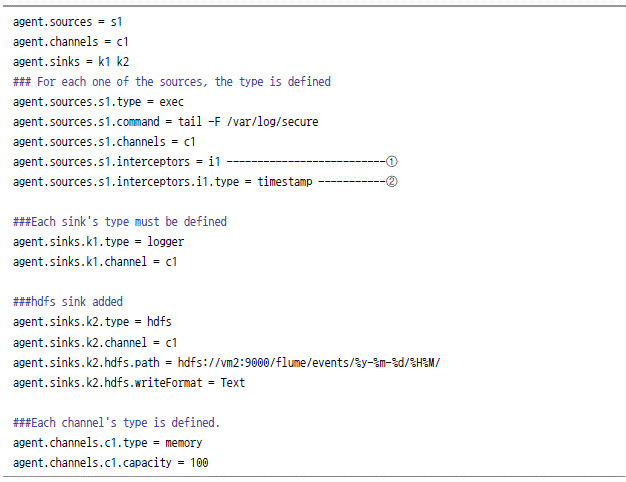
![]()