
데이터실무
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
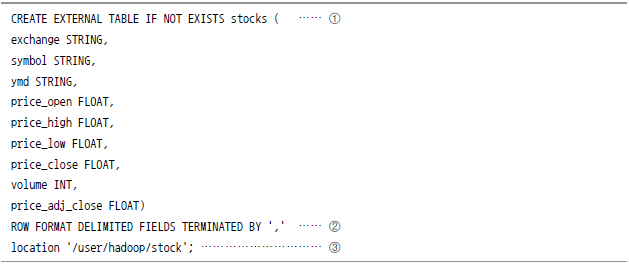
하이브는 하둡에서 맵리듀스를 직접 돌리는 대신, 사용자가 SQL(Simple Query Language)로 쿼리를 작성하면 이것을 자동으로 맵리듀스 작업으로 변경해주는 쿼리 엔진이다. 맵리듀스는 기본적으로 자바 기반의 프레임워크이므로 기존 데이터베이스나 DW를 통해 분석을 하던 개발자가 아닌 사용자들에게는 다소 어렵게 느껴질 수 있다. 하이브는 이것을 극복하도록 개발된 하둡 기반 쿼리엔진이다. 이 엔진을 사용하면 맵리듀스를 작성하지 않고 쿼리 언어만으로 하둡의 비정형 데이터 분석이 가능하다. [그림 Ⅲ-2-4] 데이터 예제 이제 WordCount보다 약간의 요건을 추가해 위 데이터를 바탕으로 ‘18세에서 25세 연령대의 사용자가 가장 많이 방문하는 사이트 5개를 맵리듀스 코드로 작성해 찾으라’는 분석 요청이 들어왔다고 가정해 보자. 아직 맵리듀스에 익숙하지 않다면, 처음부터 쉽게 방법을 찾을 수는 없을 것이다. 일단 데이터가 있으므로 고심 끝에 다음과 같은 로직을 구상할 수 있다. [그림 Ⅲ-2-5] 분석 샘플로직 자 이제 이것에 대해 맵리듀스만 작성하면 된다. 샘플로 작성된 코드는 다음과 같다. [그림 Ⅲ-2-6] 샘플 맵리듀스 논리적으로는 아주 간단한 로직인 것 같으면서도 실제로 구현하려면 위와 같이 많은 코드가 필요하다. 맵리듀스 코드 자체보다도 코드의 복잡성과 양을 보여주는 것이 목적이므로 가독성 있게 코드를 표시하지는 않고 위와 같이 한 화면에 표시했다. 이런 복잡함을 줄이기 위해 사용자별로 하둡 맵리듀스를 자동으로 작성해 주는 고차원 언어를 만들어냈다. 야후(yahoo)는 Pig라는 고차원 언어를 만들어 냈고, 페이스북은 하이브라는 쿼리엔진을 만들어 냈다 아파치 피그는 데이터 처리를 위한 고차원 언어다. 야후에서 개발한 Pig는 야후 데이터 분석의 30%정도를 담당하고 있다. 2007년에 처음 등장한 이후로 꾸준히 업데이트 되고 있으며, 현재는 순수 맵리듀스 대비 약 80% 정도의 성능을 지원한다. 위에서 나왔던 순수 맵리듀스 코드 대비 길이가 1/20 정도로 줄었다. 언어가 아주 직관적이므로 Pig의 문법을 모르는 사람이 보더라도 대강의 내용을 파악할 수 있을 정도다. 코드가 간결하기 때문에 Pig 사용자는 코드 오류보다 알고리즘에 집중할 수 있다. 무엇보다 코드 길이가 짧아서 사용자가 데이터 분석에 집중할 수 있도록 한다. 하이브는 페이스북 주도로 개발된 패키지다. 페이스북 서비스도 초창기에는 아주 간단한 로그 서버 몇 대와 오라클 클러스터를 연결한 구조로 운영됐다. 하지만 점차 로그 양이 늘어나고 처리해야 할 알고리즘과 모델이 늘어나면서 오라클에 들어가는 라이선스 비용이 부담이 됐다. 그래서 페이스북은 오라클에서 하던 배치 작업을 맵리듀스로 수행하기로 결정한다. 결정을 내릴 당시 기본적인 요구 사항은 다음과 같았다고 한다. 즉, 기존에 사용하던 데이터베이스와 아주 유사한 환경의 분석 플랫폼을 원했던 것이다. 이러한 요구 사항을 바탕으로 만들어낸 것이 바로 하이브다. [그림 Ⅲ-2-7] 하이브 내부 구조도 [그림 Ⅲ-2-8] 하이브의 워크플로(Hive Wiki) 하이브의 내부 절차는 아래와 같다. 일반 RDBMS와 비교했을 때 하이브의 단점은 다음과 같다. 이와 같이 RDBMS에 비해 하이브의 단점들이 너무 많아 보인다. 그러나 이와 같은 단점들 중에 몇 가지는 빅데이터를 처리하기 위한 어쩔 수 없는 설계이기도 하다. 이러한 설계가 빅데이터 처리시에 장점으로 작용하기도 한다. RDBMS와 하이브는 데이터를 관리함에 있어서 근본적인 차이가 있다. Schema On WRITE는 데이터를 입력할 때(Write) 테이블의 스키마 형태를 미리 선언하고, 스키마에 맞게 넣으면서 데이터 형태나 컬럼 등을 점검한다. 그러므로 일반적인 RDBMS에서는 테이블 스키마를 선언하기 전까지 데이터를 넣을 수 없다. 물론 파일 형태로 그대로 넣을 수는 있겠지만, 데이터를 제대로 읽을 수 없다. 또한 테이블 스키마가 변경되면, 테이블을 드롭하고 데이터를 리로드해야 한다. Schema On WRITE는 데이터를 읽을 때(Read) 스키마 형태에 맞게 됐는지 확인하고 최대한 유연하게 데이터를 읽어온다. 예를 들어 데이터가 선언된 테이블의 컬럼 수보다 작으면 null로 처리하거나 데이터형을 임의로 바꿔서 처리해 준다. 하이브를 설치하기 위한 선결조건은 아래와 같다. 여러 가지 변형을 통해 다른 시스템에서도 활용할 수 있는 방법도 있지만, 위 사양이 가장 기본조건이다. 보통 하이브를 설치하기 위해서는 하이브 사이트(hive.apache.org)의 다운로드 메뉴에서 패키지를 내려 받아서 설치할 수 있으며, Ambari와 같은 자동 패치키 설치 소프트웨어를 이용할 수도 있다. 여기에서는 가장 기본적인 방법인 직접 다운로드를 받아서 설치하는 방법으로 진행하겠다. 그리고 HIVE_HOME이라는 환경변수에 방금 설치한 하이브의 경로를 사용자의 bash_profile에 입력한다. 만일 하둡이 관련 설정이 없다면, HADOOP_HOME이라는 환경변수를 추가로 입력한다. $HADOOP_HOME이라는 변수가 입력돼 있지 않다면, 하이브가 테스트를 수행할 때 하둡 관련 정보를 찾을 수 없으므로 주의하자. 하이브는 테이블 데이터를 저장하기 위한 별도의 데이터베이스를 사용한다. 디폴트값은 더비(Derby)라는 임베디드 파일형 데이터베이스다. 이 데이터베이스의 경로를 다음과 같이 절대경로(full path)로 바꿔 준다. 그렇지 않을 경우에 하이브 명령어를 수행하는 경로마다 데이터베이스 파일을 생성하고 사용하므로, 만들어 두었던 하이브 테이블이 없어지는 일이 발생한다. 설치가 완료됐으면, 다음과 같이 테스트를 해본다. 하이브 설치 디렉터리로 이동해 bin/hive 명령어로 수행해 본다. 메타데이터가 잘 연결돼 있는지 보기 위해 show tables 명령어가 잘 수행되는지 확인한다. 아직 테이블을 생성한 것이 없기 때문에 테이블은 보이지 않지만 조회는 성공했다. 그리고 하둡과의 연동을 확인하기 위해서 dfs -ls 명령어를 수행한다. 정상적으로 설정돼 있다면, 위와 같이 자신이 갖고 있는 하둡의 파일 리스트가 나온다. 만일 나타나지 않으면, 환경 설정파일에서 HADOOP_HOME 설정이 잘 돼 있는지 확인해 본다. 테이블을 생성하기 위해 하이브의 DDL(Data Definition Language)을 사용해 테이블을 생성하는 실습을 한다. 일반적인 데이터베이스의 DDL과 크게 다르지 않다. 생성된 테이블을 조회하기 위해서는 describe 또는 describe extended로 확인할 수 있다. 이번 실습에서는 나스닥과 뉴욕 증권거래소의 데이터를 사용해 2010년도의 평균 주가 상위 5개업체를 찾는 방법에 대해 실습하겠다. 이 예제에서 사용할 샘플 데이터는 인포침스에서 (www.infochimps.com)에서 제공하는 나스닥(NASDAQ) 거래량 데이터다. 인포침스의 웹사이트에 접근한 다음, resource 탭의 datamarket place를 선택한다. 이어서 search 항목에서 NASDAQ을 입력하면, 필요한 데이터가 검색된다. 해당 페이지를 찾을 수 없을 경우 https://github.com/reillywatson/nasdaq-outliers에서 받으면 된다 [그림 Ⅲ-2-9] 나스닥 거래량 입력 화면 데이터를 다운로드한 후 압축을 푼다. 그 다음 하둡에 user/hadoop/stock이라는 디렉터리를 만든다. 마지막으로 압축을 푼 데이터 중에 NASDAQ_daily로 시작하는 데이터를 하둡으로 올린다. 이번에 사용할 데이터의 구조는 아래와 같다. 이 데이터에 상응하는 하이브 테이블을 생성하기 위해 하이브 스크립트를 작성한다. [그림 Ⅲ-2-10] NASDAQ data 샘플 하이브용 스크립트(stock.hql)를 작성한다. 하이브 스크립트를 완성했으면 커맨드 창에서 hive.cmd를 수행한다. 명령어가 정상적으로 수행됐다면, 하이브에서 테이블이 생성된 것을 describe 명령어로 확인할 수 있다. 하이브 테이블이 잘 생성됐다. 그렇다면 하둡 사용자 화면으로 돌아가서 하이브 작업을 수행해 보자. 여기에서는 애플의 장종가가 50달러를 넘었던 연도를 뽑아보는 것을 예제로 수행해 본다. 전체 쿼리문은 아래와 같다. 하이브는 같은 목적으로 작성한 맵리듀스보다 약 20% 속도가 느리다고 했다. 실제로 그런지 확인을 해 보겠다. 먼저 하둡 맵리듀스를 방금 생성한 테이블 테이터가 있는 하둡의 데이터 디렉터리를 대상으로 해 구동한 다음, 시간을 측정한다. WordCount 예제 프로그램은 하둡에 포함된 hadoop-examples에서 사용하고 시간은 time이라는 명령어를 hadoop 명령어 앞에 넣는다. 먼저 WordCount를 수행해보도록 하겠다. WordCount는 3분 27초 정도가 나왔다. 그러면 이번에 하이브로 동일한 내용의 쿼리를 수행한다. 하이브에서 사용하는 사용자 정의 함수 중에서 explode를 사용해 하나의 라인을 단어(word) 단위로 나누고 이것을 group by로 묶어서 단어의 개수를 새어 본다. 이것을 위한 쿼리문용 파일을 (wordcount.hql) 아래와 같이 작성한다. 파일을 완성했으면, 역시 다음 명령어로 하이브를 통해 WordCount를 수행해 본다. 생각과는 달리 하이브의 결과가 더 빨랐다. 여기서 알 수 있는 것은 적당히 맵리듀스로 로직을 개발한다면 오히려 하이브보다 더 느릴 수 있다는 점이다. 그래서 처음에는 하이브나 Pig 같은 툴로 빠르게 개발해 적용한 다음, 필요 시 맵리듀스를 직접 개발하는 것이 훨씬 효과적이다. 애플의 평균 주가가 50달러가 넘었던 연도를 알아보자. 먼저 다음과 같은 쿼리를 통해 작업을 수행한다. 동일한 내용의 쿼리를 이번에는 다음과 같이 중첩쿼리(Sub Query)로 수행해 본다. 아주 근소하게 중첩쿼리를 쓰지 않는 쪽의 성능이 빨랐다. 필자는 1개의 컴퓨터로 만든 하둡 노드에서 데이터를 처리했으므로 성능 차이를 크게 느끼기 힘들었지만, 대개의 경우 중첩쿼리로 처리하는 경우에 성능이 이 더 좋다. 왜냐하면 중첩쿼리를 사용할 경우 첫 번째 스테이지에서 맵으로만 구성된 작업(map only) 을 수행하고, 리듀스 작업을 수행하지 않기 때문이다. 그만큼 디스크 I/O가 줄어든다. 대개의 경우 데이터베이스는 특정 테이블이나 데이터베이스에 색인(index)을 생성해서 검색 속도를 빠르게 한다. 색인을 사용할 경우 아래와 같은 장점이 있다. 하이브도 자신이 관리하는 테이블에 색인을 생성해서 검색속도를 빠르게 할 수 있다. 아래와 같이 CREATE INDXE라는 명령어를 통해 앞 절에서 생성한 stocks 테이블에 symbol 컬럼을 기준으로 색인을 생성해 보자. WITH DEFERRED REBUILD 옵션을 사용해서 색인 테이블 생성 즉시 색인을 만드는 게 아니라 alter와 같은 명령어로 테이블을 변경할 때 색인을 작성하도록 했다. 위 명령어로 색인을 실제로 생성한다. 이 작업을 수행할 때 혹시 memory overflow error가 발생할 수도 있다. 맵리듀스 작업 시에 많은 메모리를 사용하기 때문에 발생하는 에러다. 하둡으로 돌아가서 태스크 트레커가 생성하는 자식(Child) 프로세스의 메모리 양을 늘려주자. 파일을 수정한 다음 하둡 프로세스를 다시 수행해 줘야 한다. 그렇지 않으면, 변경한 옵션이 반영되지 않는다. 색인(Index)를 다 생성했으면, symbol 컬럼에서 쿼리를 수행할 주식 이름을 뽑아내 별도의 하둡 파일로 저장하자. 아래의 명령어는 생성한 인덱스 중에서 AAPL이라는 이름을 가진 색인정보를 /tmp/index_test_result라는 파일로 저장하는 명령어다. 이 명령어를 잘 수행했으면, 하둡의 /tmp/ 아래에 해당 파일이 생성된 것을 확인할 수 있다. 이제 하이브가 이 색인 파일을 사용해 쿼리를 사용할 수 있도록 다음과 같은 설정한다. 다만 정보는 영속적이지 않으므로 hive 셀 안에서 수행해야 하고 로그아웃 하지 않도록 주의한다. 이것을 막기 위해 이러한 정보들은 사용자의 홈 디렉터리 아래에 .hiverc 파일을 작성해 저장한다 그렇지 않으면 hive 명령어를 내릴 때마다 입력해야 한다. 색인을 사용할 준비가 됐다면, 이제 아래와 같은 쿼리를 한번 수행해 보자. 그리고 색인을 쓰지 않고 쿼리를 수행할 때와 시간을 비교해 보자. 하이브의 색인은 데이터베이스의 색인과는 좀 다르다. 데이터베이스는 자료가 입력될 때마다 색인을 갱신하지만, 하이브는 데이터의 업데이트나 입력과는 전혀 관계없이 alter라는 명령어를 명시적으로 수행하지 않으면 갱신되지 않는다. 그리고 갱신할 경우에도 변경된 부분만 별도로 계산하는 것이 아니라, 테이블이 관리하는 전체 데이터를 갖고 하기 때문에 시간이 오래 걸리고 번거롭다. 이유는 위에서 설명했듯이 Schema On Read 방식으로 구현됐기 때문이다. 일반적으로 DW에서 메인 로그의 특정일별 혹은 시간별 분석을 하는 경우가 많다. 그런데 데이터가 시계열로 쌓이고 특정 일자의 데이터를 찾기 위해서 전체 데이터를 검색해야 한다면 매우 비효율적일 것이다. 데이터 세트를 좀 더 관리가 편리한 조각으로 분리하는 작업으로 파티션 값을 hash해 미리 설정된 버켓에 저장한다. 일반적으로 하나의 파일로 관리가 된다. Bucketing을 하면 Join을 하거나 샘플링 작업을 할 경우 성능향상을 시킬 수 있다. 위와 같은 테이블이 있다고 가정할 때, 기존 RDBMS와 같이 로우를 기준으로 테이블을 관리하면 다음과 같은 형태로 저장된다. 그러나 컬럼 기준으로 테이블을 관리하면 다음과 같은 형태로 저장된다. 저장된 형태를 보면 직관적으로 알 수 있듯이 컬럼 형태로 저장하면, 비슷한 종류끼리(컬럼) 묶이게 되기 때문에 데이터 형식도 일치해서 압축률도 더 올라간다. 또한 일반적인 DW는 테이블의 모든 컬럼을 참고하는 것이 아니라, 특정 컬럼 몇 개만 선택하며, 그 컬럼을 Group by이나 sum 등의 작업을 하기 때문에 데이터 seeking 측면에서도 많은 이점이 있다. 물론 데이터 형식뿐 아니라 쿼리 종류에 따라서 속도, 저장 공간(압축률), 스키마 변경의 용이성이 달라진다. 컬럼 형태로 저장하는 방법은 아래와 같으며 ORC 외에도 Rcfile, Parquet 등의 저장 방법이 있다. [그림 Ⅲ-2-11] Shuffle Join [그림 Ⅲ-2-12] Broadcast Join 사용 방법 [그림 Ⅲ-2-13] Sort-Merge-Bucket Join [표 Ⅲ-2-1] 조인 전략 이 옵션을 설정할 경우 아래와 같은 제한이 생긴다. 하이브는 JDBC를 통해 자바 클라이언트에서 접속할 수 있다. 먼저 하이브 서버를 띄워 둔다. 아래 명령어를 수행하면, 하이브 서버가 수행되고 외부로부터 커넥션을 기다리고 있다. JDBC용 연동 샘플 코드를 깃 허브로부터 내려 받는다. 내려 받은 코드를 이클립스에서 로딩하도록 한다. 이클립스에서 File→ import→ existing Maven 순서로 메뉴를 선택한다. 그리고 다운받은 디렉터리 아래의 pom.xml을 선택한다. 그러면 그림과 같이 메이븐 프로젝트가 로드된다. [그림 Ⅲ-2-14] 프로젝트 로드화면 프로젝트를 로드했으면, pom.xml을 더블클릭하고 dependencies 탭을 선택한다. 여기서 자신의 환경에 맞도록 dependency을 수정한다. 수정방법은 옆의 properties를 선택하고 자신의 환경에 맞는 버전을 입력하면 된다. [그림 Ⅲ-2-15] 의존성 변경화면 의존성을 자신의 버전과 다 일치 시켰으면, 소스 코드 중에서 HiveJdbcClient.java를 선택한 후 소스코드를 열어보자. [그림 Ⅲ-2-16] 사용자 정의 함수의 종류 사용자 정의 함수(UDF)는 위의 그림과 같이 크게 세 가지로 구분된다. 먼저 Standard Function은 floor(), ucase(), concat()와 같이 간단한 작업을 수행하는 사용자 정의 함수다. 이것이 UDF 전체 코드다. UDF는 하이브 클래스 중에서 UDF를 상속한 다음, evalute() 메소드에 원하는 내용만 프로그래밍해 주면 된다. 그리고 @Description는 하이브 안에서 Describe function했을 때 나오는 설명이다. [그림 Ⅲ-2-17] 이클립스 프로젝트 메뉴화면 하이브는 맵리듀스를 기반으로 데이터 처리ㆍ분석을 한다고 소개했다. 그러나 맵리듀스 분산 처리를 쉽게 한다는 측면에서 큰 장점이 있지만, 여러 가지 단점 또한 존재한다. 기본적으로 배치 작업을 목표로 했으므로 빠른 응답속도는 기대할 수 없고, 불필요한 쓰기와 같은 속도 저하 요소들이 있다. [그림 Ⅲ-2-18] 하둡 1.0과 하둡 2.0의 구성요소 또한 하둡 1.0에서 맵리듀스는 유일한 데이터 처리 엔진이었으나, 하둡 2.0에서는 데이터 처리 엔진 중 하나일 뿐이다(클라우데라 하둡은 하둡 2.0과 맵리듀스 1.0을 같이 사용할 수도 있고, Tez 모드가 아닌 순수 맵리듀스를 사용할 수도 있다). Yarn 위에서 스톰이나 Hbase와 같은 하둡에 속해 있지 않던 에코시스템들이 하나로 통합 관리가 가능해졌다. 기존의 맵리듀스는 Tez 엔진 위에서 수행되게 됐다. 자세한 내용은 1장 분산병렬배치처리를 참고하고, 여기에서는 간단한 예제와 함께 Tez의 장점에 대해 설명하겠다. [그림 Ⅲ-2-19] 호튼웍스에서 테스트한 Hive10과 Hive13 벤치마크 Yarn과 Tez가 설치된 환경이라면 Tez를 사용하는 것은 매우 간단하다. 쿼리를 수행하기 전에 혹은 속성값에 아래의 값만 넣어주면 Tez 모드가 적용된다. 또한 기존의 로직들 중에 Map-Reduce-Map-Reduce와 같이 반복적으로 맵리듀스가 사용될 경우에는 불필요한 기록이 발생한다. 하지만 Tez에서는 Map-Reduce-Reduce 모델이 가능해 불필요한 기록을 덜어 준다. Map-Reduce-Reduce를 사용하기 위해서는 다음과 같이 설정해 주면 쿼리에 따라 필요한 경우 사용된다. Tez에서는 SMB joins, SELECT TRANSFORM queries, Index creation, Skew joins 기능을 아직 지원하지 않으므로 이에 해당하는 쿼리를 실행할 때는 set hive.execution.engine=mr; 옵션으로 기존 방식으로 수행해야 한다. 이제 Tez 모드로 다시 실행해 보자. Tez 엔진 사용 옵션 하나를 통해 43초가 걸리던 작업이 20초밖에 안 걸렸다. 아직 Tez에서는 작업 중에 자세한 진행률을 보기는 어렵지만, 확실히 속도가 올라간 것을 확인할 수 있다. 앞서 20초 걸렸던 작업이 이제 9초에 끝났다. 이것이 가능한 이유는 이전 쿼리에서 사용했던 session등을 릴리즈하지 않고 재활용했기 때문이다. 맵리듀스에서는 같은 쿼리를 재실행했더라도 이와 같은 성능 향상을 기대하기 어렵다. 앞서와 동일하게 시간이 많이 단축됐을 뿐 아니라, 로그에서도 차이가 있음을 확인 할 수 있다. 맵리듀스에서는 3단계의 맵리듀스가 순차적으로 수행되는 반면, Tez에서는 전체를 한 번에 병렬로 처리하는 것을 볼 수 있다. 이제 샘플 쿼리를 통해 Tez의 장점을 알아 보자. [그림 Ⅲ-2-20] 맵리듀스와 Tez 처리 비교 맵리듀스는 각각의 매퍼에서 두 개의 테이블을 읽어와 파티션 정렬을 한다. 그러나 Tez 모드에서는 각각의 매퍼에서 테이블을 따로 처리하므로 데이터를 주고받는 양이 훨씬 줄어든다. [그림 Ⅲ-2-21] Shuffle Join Inventory 테이블이 더 크다고 가정할 때, BroadCast 조인과 맵리듀스 단계를 줄이고, 병렬 처리를 통해 HDFS 쓰기를 한 단계 줄여서 훨씬 빠른 결과를 얻을 수 있다. 이로써 MapJoin보다 더 좋은 성능을 얻을 수 있는데, 그 이유는 불필요한 기록뿐 아니라 다중 해싱을 병렬 처리할 수 있고 HashTable이 메모리에 더 컴팩트하게 맞출 수 있기 때문이다. [그림 Ⅲ-2-22] Broadcast Join MR에서는 하나의 매퍼에서 시쿼스하게 처리하는 반면, Tez에서는 여러 개의 매퍼에서 버켓 처리가 가능하며 불필요하게 HDFS에 기록하지 않는다. [그림 Ⅲ-2-23] Dynamically Partitioned Hash Join 맵리듀스 모드에서 Union all 조인의 경우 두 테이블에서 한 번씩 맵리듀스를 수행하고 각 데이터를 HDFS에 저장한다. 그 이후 다시 조인 조건에 해당하는 데이터를 하나의 맵리듀스로 수행하기 때문에 속도가 느리다. 그러나 Tez 모드에서는 두 테이블을 읽으면서 미리 aggregate하기 때문에 중복처리를 줄일 수 있다. [그림 Ⅲ-2-24] Union All 중복 스캔과 처리를 피할 수 있기 때문에 ETL 작업 시 유용하다. [그림 Ⅲ-2-25] Multi-insert Queries하이브
맵리듀스의 대안 하이브와 피그
맵리듀스의 복잡성
맵리듀스를 처음 배울 때, 가장 많이 나오는 예제는 WordCount다. 가장 간단하고 맵리듀스의 작동원리를 가장 잘 표현해줄 수 있는 코드이기 때문이다. 다시 한 번 간단하게 원리를 설명한다. 레코드리더가 매퍼로 데이터를 넘겨주면, 매퍼가 이것을 각 워드 단위로 키(key)와 값(value)으로 나눈다. 이어서 리듀서가 이것을 워드 당 빈도를 세서 워드 당 카운트를 만드는 흐름으로 코드가 작동한다.![[그림 Ⅲ-2-4] 데이터 예제](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_01.png)
![[그림 Ⅲ-2-5] 분석 샘플로직](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_02.png)
![[그림 Ⅲ-2-6] 샘플 맵리듀스](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_03.png)
하지만 힘들게 코드를 만들었는데 갑자기 요구사항이 ‘남성과 여성이 좋아하는 상위 5개의 사이트를 각각 뽑는 맵리듀스를 작성하라’고 바뀌었다고 해보자(데이터 분석이란 항상 그렇다. 일단 한 가지를 보자마자 바로 다른 것을 보고 싶어 한다). 하둡이 비록 기존보다는 훨씬 쉽게 분산 처리와 분석을 할 수 있게 만들어 줬지만, 개발자 중심의 프레임워크이고 개발자들도 맵리듀스라는 개념에 익숙하지 않으면 구현하기 힘들다. 따라서 일반적으로 맵리듀스를 이용해 데이터 분석을 할 때 다음과 같은 문제가 있다.
아파치 피그
Pig를 사용해 앞에서 나왔던 특정 연령별 톱 5 사이트를 구하는 Pig 스크립트는 다음과 같다.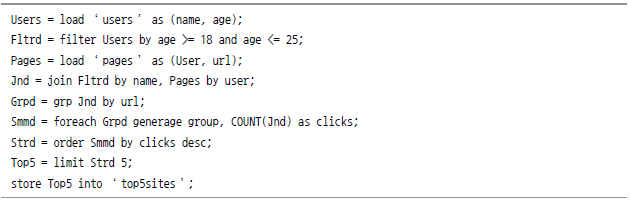
하이브
하이브 소개와 아키텍처
![[그림 Ⅲ-2-7] 하이브 내부 구조도](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_05.png)
![[그림 Ⅲ-2-8] 하이브의 워크플로(Hive Wiki)](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_06.png)
일반 RDBMS와 하이브의 차이점
Schema On WRITE(RDBMS)
물론 이와 같은 것이 기존처럼 작은 데이터일 때는 거의 문제가 되지 않는다. 하지만 처리해야 할 데이터들이 수백 TB라면, 그리고 foreign key가 변경됐다면 어떻게 될까? 수백 TB를 완벽하게 테이블 설계를 할 때까지 미리 넣을 수도 없고 급하게 설계해서 넣었다고 하더라도 다시 수정하려면 문제가 된다. 또한 테이블 설계를 변경하려는데 하필 변경해야 하는 key가 외래키(foreign key)라면 그와 연결되는 테이블은 모두 다시 적재해 줘야 한다. 그런데 위에서 이 데이터가 수백 TB라고 가정했다. 수백 TB를 다시 적재하려면 굉장한 시간과 노력이 들어갈 것이다. 이제 하이브에서는 어떻게 처리하는지 보자(이 처리 방법은 대부분의 SQL-On-Hadoop에서도 비슷하다).
Schema On READ(하이브)
그러므로 하이브에서는 테이블 스키마를 선언하기 전에도 데이터를 HDFS에 넣을 수 있다. 미리 데이터를 넣어 놓고 테이블을 생성ㆍ분석을 하면서 변경하더라도 상대적으로 문제가 되지 않는다. 따라서 데이터 사이즈가 크고 비정형 데이터가 많아서 데이터의 타입이나 컬럼들이 명확하지는 않을때 유연하게 대처하기 위해서 Schema On Read를 사용하게 됐다. 물론 이 방식이 만능은 아니지만, 빅데이터 처리를 할 때 장점이 많아서 대부분의 SQL-On-Hadoop들이 이 방식을 지원한다.
하이브 설치
하이브 패키지 설치
하이브뿐 아니라 대부분의 오픈 소스들의 파일을 다운받을 때 주의할 점은 파일명 중간에 bin이 들어간 버전을 받아야 한다는 것이다. 일반적인 경우 bin이 붙은 파일과 붙지 않은 파일의 차이점은 소스코드 형태의 패키지와 실행 가능한 패키지(압축 파일 이름에 bin이 붙어있음)의 차이다. 오픈소스의 장점이 내부 구조를 파악할 수 있고, 필요 시 소스코드를 수정해 기능을 바꿀 수 있다는 점이다. 그렇기 때문에 오픈소스 프로젝트들은 소스버전과 그 소스를 컴파일한 실행가능 버전 2가지로 배포한다. 또한 사용자 환경에 따라서 참조 라이브러리를 다르게 설정해서 직접 컴파일을 해야 하는 경우가 있는데 이 경우에도 소스 버전이 필요하다.
여기에서는 일반적인 환경에서 테스트하기 위해서 빌드된 버전을(이름에 bin이 포함된) 받도록 한다. 파일을 다운 받은 이후에는 tar 명령어를 사용해 압축을 해지한다. 그리고 버전관리를 용이하게 하기 위해 심볼릭링크를 생성한다. 이는 윈도우에서 ‘바로가기’와 비슷한 역할을 한다.
설치 위치는 실습을 간단하게 하기 위해서 하둡 계정의 홈 디렉터리(/home/hadoop)로 하는데, 실제 업무에서는 다양한 계정의 사람들이 사용하기 위해 /usr/local에 설치하기도 한다. 자동설치의 경우 라이브러리 파일과 실행파일, 환경설정 파일들을 각각 다른 경로에 넣기도 한다.

메타 데이터용 데이터베이스 설정
먼저 $HIVE_HOME/conf 아래의 hive-default.xml.template 를 hive-site.xml로 이름을 바꿔 저장한 다음, derby database 항목을 찾아 아래와 같이 변경한다.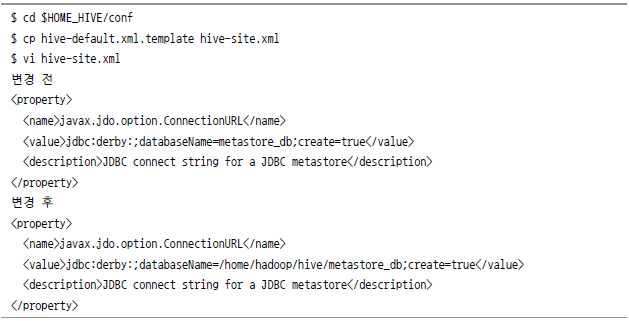
설치 테스트


하이브 실습
DDL 테스트 실습
![// 테이블 생성 hive> CREATE TABLE pokes (foo INT, bar STRING); hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING); hive>describe invites; OK foo int bar string ds string Time taken: 0.152 seconds //테이블 상세 정보 조회(각 컬럼뿐만 아니라 저장 위치나 파티션 정보들을 볼 수 있다.) hive>describe extended invites; OK foo int bar string ds string Detailed Table Information Table(tableName:invites, dbName: default, owner: root, createTime: 1384689115, lastAccessTime: 0, retention: 0, sd: StorageDescriptor(cols: [FieldSchema(name: foo, type: int, comment: null), FieldSchema(name: bar, type: string, comment: null), FieldSchema(name: ds, type: string, comment: null)], location: hdfs://vm2:9000/user/hive/warehouse/invites, inputFormat: org.apache.hadoop.mapred.TextInputFormat, outputFormat: org.apache.hadoop.mapred.TextInputFormat, outputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets: -1, serdeInfo: SerDeInfo(name: null, serializationLib: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters: {serialization.format=1}), bucketCols: [], sortCols:[], parameters: {}), partitionKeys: [FieldSchema(name:ds, type: string, comment: null)], parameters: {transient_lastDdlTime=1384689115}, viewOriginalText:null, viewExpendedText:null, tableType:MANAGED_TABLE) Time taken: 0.063 seconds hive>](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_12.png)
데이터를 활용한 실습
![[그림 Ⅲ-2-9] 나스닥 거래량 입력 화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_13.png)

![[그림 Ⅲ-2-10] NASDAQ data 샘플](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_15.png)

![$ bin/hive -e "describe extended stocks" OK exchange string symbol string ymd string price_open float price_high float price_low float price_close float volume int price_adj_close float Detailed Table Information Table(tableName:stocks, dbName: default, owner: hyejung, createTime: 1379955366, lastAccessTime: 0, retention: 0, sd: StorageDescriptor(cols: [fieldSchema(name: exchange, type: string, commet: null), FieldSchema(name:symbol, type: string, comment: null), FieldSchema(name: ymd, type: string, comment: null), FieldSchema(name: price_open, type: float, comment:null), FieldSchema(name: price_high, type: float, comment: null), FieldSchema(name: price_low, type: floar, comment: null), FieldSchema(name: price_close, type: float, comment: null), FieldSchema(name: volume, type: int, comment: null), FieldSchema(name: price_adj_close, type: float, comment: null)], location: hdfs://localhost:8020/user/hadoop/stock, inputFormat: org.apache.hadoop.mapred.TextInputFormat, outputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed: false, numBuckets: -1, serdeInfo: SerDeInfo(name: null, serializationLib: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, paramaters: {serialization.format=,, field.delim=,}), bucketCols:[], sortCold:[], parameters:{}),partitionKeys: [], parameters: {EXTERNAL=TRUE, transient_lastDdlTime=1379955366}, viewOriginalText:null, viewExpandedText: null, tableType: EXTERNAL_TABLE) Time taken : 0.737 seconds](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_18.png)

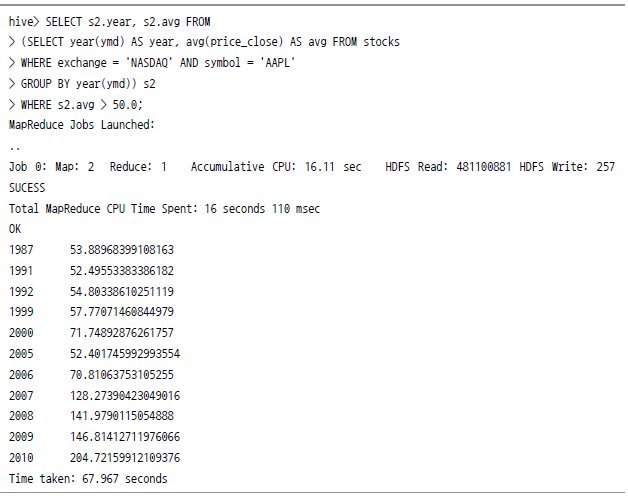
하이브와 맵리듀스 성능 비교
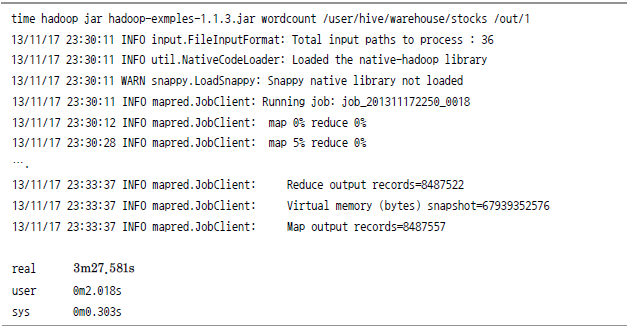

![[root@vm2 hive]# time hive -f wordcount.q WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files. Logging initialized using configuration in jar: file:/usr/local/hive-0.8.1/lib/hive-common-0.8.1.jar!/hive-log4j.properties Hive history file=/tmp/root/hive_job_log_root_201311172342_1640623017.txt OK exchange 72 stock_price_adj_close 72 stock_price_close 72 stock_price_high 72 stock_price_low 72 stock_price_open 72 stock_symbol 72 stock_volume 72 Time taken: 201.353 seconds](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_22.png)
중첩쿼리 실습

색인을 사용한 하이브 가속화

![]()
이 옵션은 하둡의 mapred-site.xml에서 mapred.child.java.opts 옵션을 찾은 다음, 1024m로 수정해 줘야 한다.





하지만 위의 예에서와 같이 미리 한 번 만들어 놓으면, 속도가 빨라지는 것은 사실이므로 동일 테이블에서 특정 컬럼이나 데이터를 기준으로 쿼리를 반복적으로 수행할 경우에는 색인을 생성해 놓고 작업을 수행하는 것도 고려해 볼 일이다.
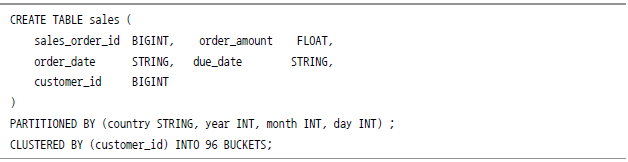
파티셔닝
이러한 요건을 해결하기 위해서 파티셔닝(Partitioning)이라는 개념이 나왔다. 데이터마다 날짜 표시를 해놓고 원하는 시간대가 아닌 데이터는 분석 대상에서 아예 제외시키는 방법이다. RDBMS에도 있는 기능이지만 하이브에서는 더 직관적으로 돼 있다.
하이브는 HDFS를 Read해서 분석을 하는데, 이때 테이블마다 디렉터리가 할당됐으므로 쉽게 읽어올 수 있다. 하지만 파티셔닝은 이 디렉터리 안에 추가로 원하는 컬럼 값의 디렉터리를 만드는 것이다(이 경우에는 날짜 값). 그렇게 되면, 모든 데이터를 읽어와서 날짜 컬럼을 비교ㆍ분석할 필요 없이 디렉터리 이름만 비교해 원하는 데이터만 추려 내면 훨씬 간단해진다. 이것이 파티셔닝의 기본 원리다. 예제를 보도록 하자.




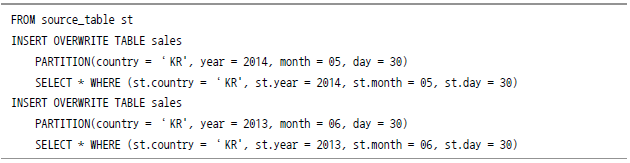


Bucketing

Store

No
Status
City
Name
S1
20
London
Smith
S2
10
Paris
Jones
S3
30
Paris
Blake
S4
20
London
Clark
S5
30
Athens
Adams
![]()


Join
![[그림 Ⅲ-2-11] Shuffle Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_46.png)
![[그림 Ⅲ-2-12] Broadcast Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_47.png)

하둡은 기본적으로 하드디스크를 사용하므로 Seek(데이터 탐색)를 위해 디스크의 헤더가 움직이면서 해당 위치를 찾게 된다. 그러므로 이 시간을 줄이면, 훨씬 빠르게 처리가 가능하다. 아래와 같이 데이터가 일정 규칙에 의해서 정렬됐으면, Seek Time을 줄일 수 있다. 또한 Bucket을 이용해서 좀 더 효율적으로 데이터 처리가 가능하다.
![[그림 Ⅲ-2-13] Sort-Merge-Bucket Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_49.png)
Type
Approach
Pros
Cons
Shuffle Join
맵리듀스를 이용해 Key를 기준으로 shuffle해 Join side를 기준으로 조인
어떤 형태의 데이터 크기와 구성에서도 작동함
가장 많은 자원을 사용하며 가장 느린 조인 방식
Broadcast Join
작은 테이블을 모든 노드의 메모리에 올리고 매퍼는 큰 테이블을 읽어서 조인
가장 큰 테이블에서 굉장히 빠른 단일 스캔
작은 테이블이 메모리에 들어갈 정도로 작아야 함
Sort-Merge-B ucket Join
Sort로 인접된 Key를 이용해 매퍼에서 효과적인 조인
어떤 크기의 테이블에서도 굉장히 빠름
사전에 자료가 정렬되고 bucketing 돼 있어야 함
Configuration


태스크 자체의 실행시간보다 JVM의 생성 및 초기화가 더 오래 걸릴 때가 있다. 이것을 위해 설정하는 옵션이며, 자바 가상 머신 재사용이 예약된 태스크 슬롯을 잡이 완료할 때까지 점유하고 있다.


JDBC드라이버를 통한 하이브 연동


![[그림 Ⅲ-2-14] 프로젝트 로드화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_56.png)
![[그림 Ⅲ-2-15] 의존성 변경화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_57.png)
![public static void main(String[] args) throws SQLException { try{Class.forName(driverName);} catch(ClassNotFoundException e) { e.printStackTrace(); System.exit(1); } //192.168.10.5 대신에 자신의 하이브 서버 IP를 입력한다. Connection con = DriverManager.getConnection("jdbc:hive//192.168.10.5:1000/default", "", ""); Statement stmt = con.createStatement(); String tableName = "testHiveDriverTable"; stmt.executeQuery("drop table " + tableName); //key, value 컬럼으로 이뤄진 테이블을 생성한다. 그리고 구분자는 탭으로 나뉜다. ResultSet res = stmt.executeQuery("create table" + tableName + "(key int, value string)" + "ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'"); //show tables String sql = "show tables'" + tableName + "'"; System.out.println("Running: " +sql); res = stmt.executeQuery(sql); if (res.next()){System.out.println(res.getString(1));} //describe table sql = "describe" + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()){System.out.println(res.getString(1) + "\t" + res.getString(2));} //데이터를 하이브 테이블로 입력한다. //파일의 경로는 이 클라이언트 예제를 수행하는 로컴 컴퓨터의 경로다. // /home/hadoop/a.txt는 탭으로 구분되는 파일을 아무것이나 미리 생성해 둔다.](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_58.png)

사용자 정의 함수 예제
![[그림 Ⅲ-2-16] 사용자 정의 함수의 종류](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_60.png)
UDAF는 하나 이상의 로우나 컬럼으로부터 데이터를 가져와 계산을 수행하는 함수다. abs(), sum()과 같은 함수가 여기에 속한다. UDAF는 중에 Generic UDAF가 있는데, 이것은 UDAF보다 좀 더 일반적으로 작업을 수행할 수 있도록 복잡한 인터페이스를 상속받아 구현하도록 돼 있다. 마지막으로 UDTF는 사용자 정의 테이블 생성 함수로써 앞서 예제에서 사용한 explode가 여기에 속한다.
이번 예제에서는 UDAF를 제작하는 방법에 대해 설명한다. 앞서 다운 받은 코드에서 Fullname.java를 선택한다. 이 루틴은 aapl이나 AAPL을 APPLE로 변환해 출력하는 코드다.
코드를 완성했으면 jar 파일 형태로 배포(export)한다. 이클립스에서 프로젝트를 선택한 다음, 오른쪽 마우스를 클릭하면 그림과 같이 메뉴가 나온다. 여기서 export를 메뉴로 jar 파일을 생성한다. 그리고 하이브 창에서 이 jar 파일을 로드하고 사용자 정의 함수를 fullname으로 입력한다.![[그림 Ⅲ-2-17] 이클립스 프로젝트 메뉴화면](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_62.png)

Apache Tez
Tez 소개
그래서 하둡 2.0으로 넘어오면서 이러한 단점을 개선하기 위해 여러 가지 변화가 생겼다. 하둡2.0에는 1장 분산병렬배치처리에서 다뤘던 Yarn이 맵리듀스에서 하던 리소스 관리를 한다. 기존 맵리듀스를 확장ㆍ발전시켜서 데이터 처리ㆍ분석을 하는 새로운 모듈이 이번에 다룰 Tez다.![[그림 Ⅲ-2-18] 하둡 1.0과 하둡 2.0의 구성요소](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_64.png)
![[그림 Ⅲ-2-19] 호튼웍스에서 테스트한 Hive10과 Hive13 벤치마크](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_65.png)
Tez 실습


이전에 생성했던 stocks 테이블을 조회하되, 먼저 맵리듀스 모드로 수행한 다음, 이후에 Tez 모드로 수행해 작동과 성능 차이를 테스트해 보자.


이어서 위에서 수행했던 쿼리를 바로 다시 실행해 보자.
아래 쿼리로 맵리듀스와 Tez의 차이점을 더 확인해 보자.

맵리듀스

Tez
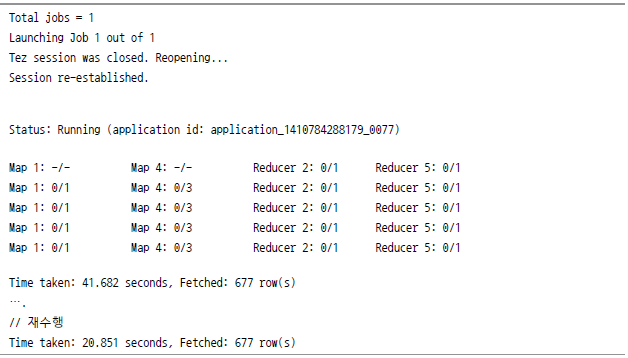
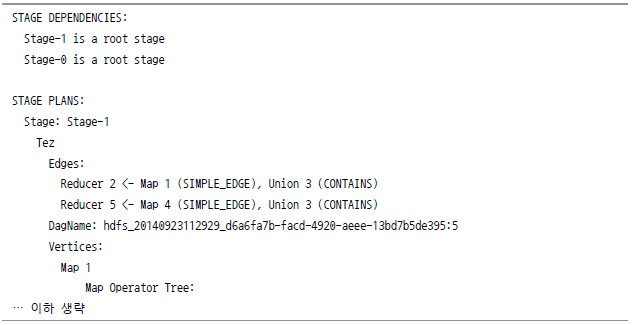
내부 처리에 대한 자세한 Plain은 explain 명령을 통해 다음과 같이 확인할 수 있다.
맵리듀스

Tez
Tez의 장점
대표적인 장점

![[그림 Ⅲ-2-20] 맵리듀스와 Tez 처리 비교](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_79.png)
Shuffle Join

![[그림 Ⅲ-2-21] Shuffle Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_81.png)
BroadCast Join

![[그림 Ⅲ-2-22] Broadcast Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_83.png)
Dynamically Partitioned Hash Join

![[그림 Ⅲ-2-23] Dynamically Partitioned Hash Join](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_85.png)
Union all

![[그림 Ⅲ-2-24] Union All](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_87.png)
Multi-insert queries

![[그림 Ⅲ-2-25] Multi-insert Queries](https://dataonair.or.kr/publishing/img/dbguide/bigdata_technology/322_bigdata_89.png)