
DA 가이드
DA, SQL, DB보안 등 실무자를 위한 위한 DB기술 바이블!
성능 개선 방법론
성능 개선 목표
DBMS 성능 개선을 위해 개선 목표를 설정하는 것은 매우 중요하다. 목적에 따라 목표가 다를 수 있으며, 현재 가용한 비용에 대한 효과를 고려하여 목표를 설정하여야 한다.
처리 능력(Throughput)
처리 능력은 해당 작업을 수행하기 위해서 소요되는 시간으로 수행되는 작업량을 나눔으로써 정의 된다. 만약 수행 작업이 트랜잭션이라면 시스템의 처리 능력은 다음과 같다.
처리능력 = 트랜잭션 수 / 시간
처리 능력은 전체적인 시스템 시각에서 측정되고 평가 된다.
처리 시간(Throughput Time)
처리 시간(Throughput time)은 작업이 완료되는 데 소요되는 시간을 의미한다. 처리 시간은 배 치 프로그램의 성능 목표로 설정한다. 대량 배치 작업의 수행 시간을 단축하기 위해서는 다음과 같 은 작업을 고려한다.
- 병행 처리(Parallel Processing)를 실시한다.
- 인덱스 스캔보다 Full 테이블 스캔으로 처리한다.
- Nest-Loop 조인보다 Hash 조인으로 처리한다.
- 대량 작업을 하기 위한 SORT_AREA, HASH_AREA 의 메모리를 확보한다.
- 병목을 없애기 위해서 작업 계획을 한다.
- 대형 테이블인 경우는 파티션으로 생성한다.
응답 시간(Response Time)
응답 시간은 입력을 위해 사용자가 키를 누른 때부터 시스템이 응답할 때까지 시간이다. 최종 사용 자가 느끼는 시스템의 성능 척도이다. 일반적으로 OLTP 시스템에서 성능 지표가 된다. 응답 시간 을 향상하기 위해서는 다음과 사항을 고려한다.
- 인덱스를 이용하여 액세스 경로를 단축한다.
- 부분 범위 처리를 실시한다.
- Sort-Merge 조인이나 Hash 조인을 사용하지 않고 Nest-Loop 조인으로 처리한다.
- Sort-merge 조인이나 해쉬 조인을 사용하지 않고 Nest-Loop 조인으로 처리한다.
- 잠김(Locking) 발생을 억제한다. 예를 들어 시퀀스(Sequence) 오브젝트 이용한다.
- 하드 파싱을 억제한다.
로드 시간(Load Time)
다음날의 비즈니스를 위해 매일 밤 데이터를 로드하거나 시스템을 재구축하고, 목표 시간 내에 데 이터 마이그레이션을 완료해야 한다. 로드 시간은 이와 같은 정기적이거나 비정기적으로 발생되는 데이터베이스에 데이터를 로드하는 작업 수행 시간을 뜻한다. 로드 시간을 단축하려면 다음과 같 은 사항을 고려한다.
- 로그 파일을 생성하지 않는 다이렉트 로드(Direct Load)를 사용한다.
- 병렬 로드 작업을 실시한다.
- DISK IO 경합이 없도록 작업을 분산한다.
- 인덱스가 많은 테이블인 경우는 인덱스를 삭제하고 데이터 로드 후 인덱스를 생성한다.
- 파티션을 이용하여 작업을 단순화한다.
성능 개선 절차
데이터베이스 성능 튜닝 방법론은 튜닝 작업에 필요한 여러 가지 수행 방법과 이러한 작업들을 효 율적으로 수행하려는 과정에서 필요한 각각의 단계들을 체계적으로 정리하여 표준화한 것으로써 분 석, 이행, 평가 3단계를 거쳐 성능 최적화의 목적을 달성하기 위한 단계별 접근 전략이다.
분석
튜닝 분석 단계에서는 자료 수집과 목표 설정이라는 2단계로 나뉜다.
자료 수집
데이터베이스 모니터링과 데이터베이스 객체 현황 파악 및 물리 설계 요소에 대해 성능과 관련된 지표들을 분석하기 위한 기초 자료를 수집하는 단계이다.
목표 설정
수집된 기초 자료를 통해 데이터 모델 분석, 액세스 패스 분석, 시스템 자원 현황 분석, SQL 성능 분석, SQL 효율 분석 등을 종합하여 성능상에 병목이나 지연 등과 같은 문제 요소 등을 구체적으 로 파악하고 성능 튜닝의 대상이 되는 목표들을 구체화하여 방향을 설정하는 단계이다.
이행
튜닝 이행 단계에서는 성능상의 문제 요소로 파악된 대상에 대해 최적화 방안을 수립하고 적용하는 단계이다.
- 데이터베이스 파라미터(Parameter) 조정
- 전략적인 저장 기법 적용을 위한 물리 설계 및 디자인 검토
- 비효율적으로 수행되는 SQL 문에 대한 최적화
- 네트워크 부하 등을 고려한 데이터베이스 분산 구조에 대한 최적화
- 적절한 인덱스 구성 및 사용을 위한 인덱스 설계 등의 최적화 작업
평가
튜닝 평가 단계에서는 분석 단계에서 진단을 통해 분류된 문제 요소들에 대해 설정된 개선 목표와 이행단계에서 구체적인 튜닝 작업을 수행한 후의 성과를 비교 측정하는 단계이다. 튜닝 목표와 튜닝성과에 차이가 있다면 그 요소들을 파악한 후 목표와 성과를 합치시키는 과정을 거친다.
성능 개선 접근방법
시스템 성능 문제는 하드웨어(CPU, 메모리, 네트워크 등) 자원 부족, DBMS 설계, SQL 비효율 등의 문제로 발생되는 경우가 대부분이다. 많은 비용을 들여 고성능의 하드웨어 교체 및 증설을 통해 성능상의 문제를 해결하기 이전에 데이터베이스의 성능상 문제점을 파악한 후 문제점의 튜닝을 통한 데이터베이스의 최적화를 우선적으로 고려해야 한다.
![[그림 5-3-1] 성능 저하 요인](https://dataonair.or.kr/publishing/img/dbguide/edu/071107_c_1.gif)
![[그림 5-3-2] 성능 개선 접근 방법](https://dataonair.or.kr/publishing/img/dbguide/edu/071107_c_101.gif)
SQL 성능 분석
SQL이 실행되기 위해서는 실행 가능한 소스코드로 변환되어야 하는데, 이 소스코드를 생성하기 위한 실행 전략을 실행 계획이라 한다. 옵티마이저는 실행 계획을 수립하기 위해 SQL을 관계 대수 형태로 변환하고 개별 연산자의 알고리즘들을 다양한 방법으로 결합해 이들을 트리 형태로 표현한다.
실행 계획이 수립되면 최적화 과정을 거쳐 최적의 실행 계획이 선택되지만 옵티마이저의 지능적 한계로 인해 최종 선택된 실행 계획이 항상 최적의 실행 계획이 아닐 수 있게 된다.
실행 계획 분석이란, 이러한 옵티마이저의 한계를 인식하고 옵티마이저가 최적화된 실행 계획을 수립할 수 있도록 유도하는 데 목적이 있하는 방법은 DBMS별로 약간 차이가 있지만 상용 혹은 DBMS 벤더가 제공하는 SQL 개발 도구를 사용하면 쉽게 실행 계획 보기를 수행할 수 있다.
SQL 트레이스 분석
오라클은 데이터베이스의 인스턴스 또는 세션 단계에서 수행되는 모든 SQL의 통계치 및 대기 이벤트에 대한 정보를 수집해주는 트레이스 기능을 제공하고 있다. 초기 SQL 트레이스 기능은 주로 Instance, Session 수준에서 이루어졌다. 그런데 최근부터는 End to End Application Tracing이 가능하도록 Client Identifier, Service, Module, Action 수준의 트레이스 기능을 추가하였는데, 이로 인해 cross-instance, multi-session, multi-user 수준의 SQL 트레이스가 가능하게 되었다.
다음은 오라클 SQL 트레이스 기능을 요약하여 도식화한 것이다.
![[그림 5-3-3] 오라클 SQL 트레이스 기능](https://dataonair.or.kr/publishing/img/dbguide/edu/071107_c_2.gif)
오라클에서 트레이스 기능이 활성화되면 트레이스 결과 파일은 세션 단위로 지정 디렉토리에 .trc 확장자로 기록된다. 트레이스 파일은 로그와 같이 알기 힘든 약어들이 많이 사용되어 해석이 용이하 지 않다. 그래서 tkprof 유틸리티를 사용해 분석하기 용이한 형태로 변환해 사용한다.
리포트 파일은 여러 개의 세션 트레이스 파일들을 머지하여 하나의 리포트 파일로 생성하며, 헤드 부분, 바디 부분, 써머리 부분의 3부분으로 나눠져 있다.
다음은 헤드 부분에 대한 사례이다.

헤드 부분은 릴리즈 정보, 리포트를 생성한 시간, 저작권 문구, 트레이스 파일명, 리포트 생성 옵션 등의 정보를 포함하고 있다.
다음은 바디 부분에 대한 사례이다.
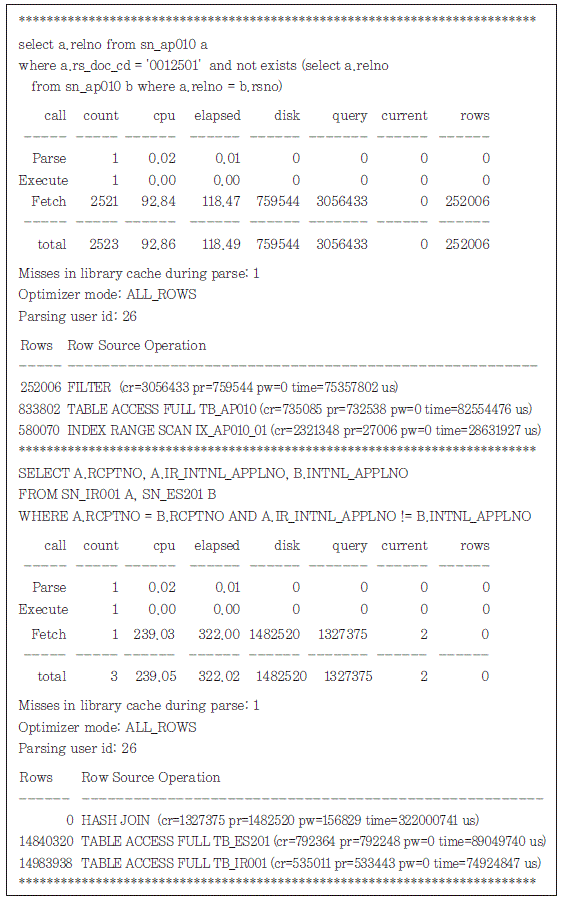
바디 부분은 머지된 모든 트레이스 파일 각각의 실행 통계와 이벤트 관련 정보들을 포함하고 있다.
SQL Statement
수행된 쿼리문 텍스트(Embeded /Static 쿼리문의 경우 포맷이 일부 변경)
Execution statistics
DBMS가 결과 집합을 만들기 위해 내부적으로 Parse, Execute, Fetch 단계에서 수행한 수행 횟 수, cpu 사용시간, 소요시간, 물리적으로 읽은 블록 수(disk), 논리적으로 읽은 블록 수(query+ current), 처리한 로우 건 수 등에 대한 정보들을 포함하고 있다.
Misses in library cache during parse : 1
실행 통계 정보에 표시된 Execute count를 수행하는 동안 하드 파싱이 일어난 횟수를 의미한다. 위 사례에서는 1회의 하드 파싱이 발생하였다.
Execution statistics
옵티마이져 모드는 옵티마이져가 최적화 목표를 어디에 두고 최적화를 수행해야 하는지 최적화 접 근 방법에 대한 선택 옵션으로 first_rows_n, first_rows, all_rows 등의 옵션이 지원된다.
- first_rows_n
최초의 n개 로우를 가장 빠르게 리턴하는 것을 최적화 목표로 하여 최적화를 수행한다. - first_rows
최초의 몇몇 로우들을 가장 빠르게 리턴하기 위한 최적의 플랜을 찾는 것을 최적화 목표로 한다. - all_rows
최적의 throughput을 목표로 최적화를 수행한다.
Parsing user id: 26
SQL을 실행한 사용자의 id를 표시하는 부분으로, id에 대한 명을 확인하려면 dba_users 테이블을 참조하여야 한다.
Execution plan
SQL을 처리하기 위한 실행 계획을 Row Source Operation 단위의 정보와 함께 표시한다.
- Rows : 해당 오퍼레이션 단계에서 리턴된 로우 수
- cr은 consistent reads로 논리적으로 읽은 블록 수를 의미
- pr은 physical reads로 물리적으로 읽은 블록 수를 의미
- pw는 physical writes로 물리적으로 쓴 블록 수를 의미
- time은 micro-sec 단위의 소요 시간을 의미
다음은 써머리 부분에 대한 사례이다.
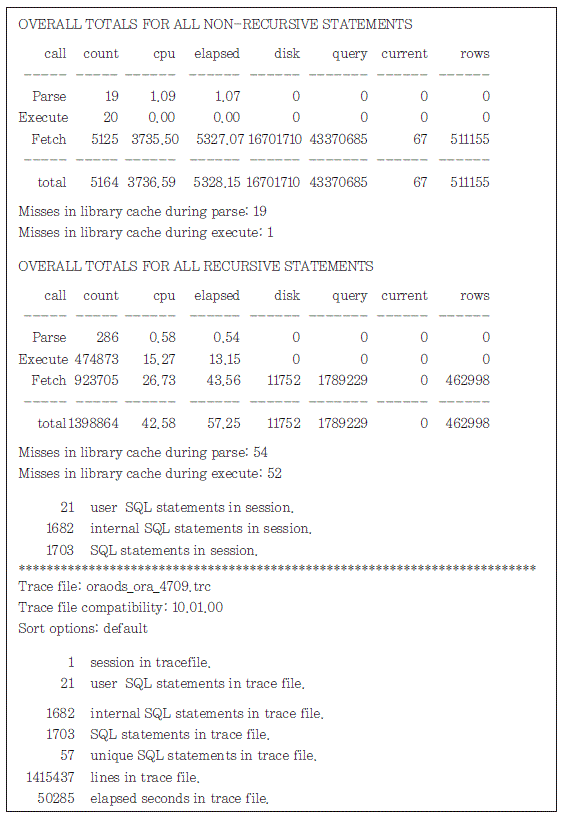
써머리 부분은 Tkprof로 변환한 모든 트레이스 파일에 대한 실행 통계를 누적한 부분으로, 사용 자가 요청한 SQL을 직접적으로 처리하기 위해 수행한 실행 통계는 NON-RECURSIVE에 집계되 고, 추가적으로 수행한 실행 통계는 RECURSIVE에 집계된다.
실행 통계 정보는 패턴에 따라 다음과 같은 분석이 가능하다.
| count | 분석 | |
|---|---|---|
| Parse Execute Fetch |
1 1 1 |
.동일 SQL에 조건만 다른 SQL 반복을 사용하거나 Dynamic SQL 형태로 개발된 SQL일 가능성이 높다. .DBMS에 심각한 Parsing 부하를 가중시킬 수 있다. .Trace TKPROF File size가 과대하게 될 수 있다. |
| Parse Execute Fetch |
100 100 100 |
.프로그램 100번 수행 : 프로그램이 여러 번 실행되면 SQL을 파싱하지 않 고 Shared SQL AREA에서 찾아 왔더라도 Parse 횟수가 증가한다. .SQL 100번 수행되었는데, Parse가 100이라는 것은 프로그램이 100번 수행 복 수 행되었다는 것을 의미한다. |
| Parse Execute Fetch |
1 100 100 |
.프로그램 1번 수행 : 애플리케이션이 여러 번 실행되면 SQL을 파싱하지 않고 Shared SQL AREA에서 찾아 왔더라도 Parse 횟수가 증가한다. .SQL 100번 수행되었는데, Parse가 1이라는 것은 PL/SQL 내에서 반복 수행된 SQL이거나 프로그램(Pro*c)에서 Hold Cursor 지정하여 사용했 다는 것을 의미한다. |
| Parse Execute Fetch |
1 1 100 |
.SQL은 1번 수행되었고 패치만 100번 수행했다는 것은 CURSOR로 지정된 SQL이 LOOP 내에서 반복 Fetch 처리를 수행하였다는 것을 의미한다. |
| Parse Execute Fetch |
200 100 10000 |
.Parse count가 Execute count보다 큰 것은 SQL이 파싱만 되고 수행되 지 못한 경우로, 개발 시 오류로 인하여 실행이 취소되거나 시스템 오버헤 드로 인하여 SQL이 실행되지 못한 경우에 발생할 수 있다. .SQL이 100번 수행될 때 패치를 10000번 수행했다는 것은 CURSOR로 지정 된 SQL이 LOOP 내에서 반복 Fetch 처리를 수행하였다는 것을 의미한다. |
| count | rows | 분석 | |
|---|---|---|---|
| Parse Execute Fetch |
2500 2500 0 |
0 9800 0 |
.HOLD_CURSOR를 지정하지 않고 3GL처럼 INSERT, UPDATE, DELETE가 반복 수행되는 구조의 프로그램 |
| Parse Execute Fetch |
1 100 100 |
0 0 200 |
.다중 처리로 수행된 SQL .한 번에 2 Rows가 Fetch 처리 |
| Parse Execute Fetch |
1 1 100 |
0 0 200 |
.다중 처리로 수행된 SQL .한 번에 2 Rows가 Fetch 처리 |
| 구분 | 분석 항목 | 분석 내용 |
|---|---|---|
| 일반 | SQL당 수행 시간 | .total cpu / execute count [0.01초 이내] .total elapsed / execute count [0.03초 이내] |
| Parse Overhead | .parse elapsed / execute elapsed [10% 이내] .Misses in library cache during parse .parse count * 0.01보다 parse cpu time이 크면 Dynamic SQL 이 많이 사용되었거나 라이브러리 캐시가 적게 지정된 경우임 ※ 위의 결과로 Dynamic SQL의 사용 비율을 추정할 수 있음 |
|
| Block I/O 비효율 | .total disk / total rows [1미만의 수치일수록 양호한 상태] .Memory Block Access = total query + total current .Memory Hit Ratio = Memory Block Access / (total disk + Memory Block Access) [90% 이상] .Execute vs. Fetch의 비율 - 처리된 row의 절대량이 많지 않은데, DB Block I/O가 많은 경우는 Optimizing 전략 부재일 가능성이 크고, - 처리된 row의 절대량이 많으면서 DB Block I/O가 많은 경우 DB Block Buffer Hit Ration가 낮으면 DB Block Buffer 크기의 문제일 가능성이 크다고 판단 가능 |
|
| Total elapsed / Total cpu |
.100%보다 지나치게 크게 나타나면 Optimizing 전략 부재로 인한 Full Scan 등으로 Disk I/O 병목 현상에 의한 것인 가능성이 큼 | |
| 응용 PGM 문제 Pattern |
fetch rows / fetch count |
.1보다 큰 특정 10의 배수 수치에 가깝게 나타나는 경우 애플리케 이션에 Array Processing이 적용되고 있다고 판단할 수 있으 면 1에 가까운 수치로 나타나는 경우 Array Processing이 적용 되지 않았다고 판단할 수 있음 |
| RECURSIVE CALL OVERHEAD |
.OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS 의 execute count / OVERALL TOTALS FOR ALL NONRECURSIVE STATEMENTS Execute의 비율 .애플리케이션 내에서 DB Function 사용 비율을 판 여부를 조사할 필요가 있음 |
|
| 악성 SQL의 분포 추정 | .TKPROF utility에 의해 처음 생성된 파일의 크기와 Full scan 및 cputime에 의해 추출된 결과 파일의 크기를 비교하여 전체 SQL대비 악성 SQL의 비율을 추정할 수 있음 | |
실행 계획 분석 사례
1) 오라클 실행 계획 분석 사례 1
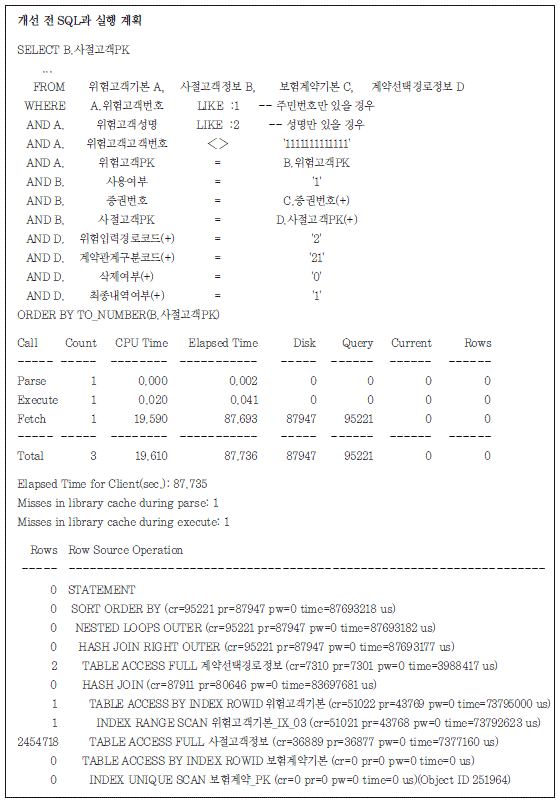
위의 실행 계획을 보면 위험고객기본 테이블과 사절고객정보 테이블이 해쉬 조인으로 수행되고, 그 결과를 가지고 계약선택경로정보 테이블과 RIGHT OUTER 해쉬 조인을 수행하였다. 그리고 다 시 보험계약기본정보 테이블과 Nested-Loop 조인을 수행한 후 그 결과를 가지고 그룹핑을 하였다.
첫 번째 해쉬 조인에서 위험고객기본_IX_03을 RANGE SCAN하여 1건이 추출되었다. 그런데 DISK I/O가 43,769 블록으로 매우 크게 나타나고 있는 것으로 보아 매우 큰 범위를 RANGE SCAN하였다는 것을 알 수 있다. 그리고 1건이 추출되었다는 것은 분포도가 아주 좋은 체크 조건을 가지고 있다는 의미이기도 하다.
SQL을 보면 위험고객기본 테이블에 인덱스를 사용할 수 있는 두 가지 상수 조건이 주어져 있다. 그런데 두 조건 모두 Like 조건으로 비교되었으므로 하나를 사용하면 다른 하나는 체크 조건으로만 사용이 가능하다. 그런데 위 실행 계획에서는 두 조건 중 값이 입력되지 않은 조건을 드라이빙 조건으 로 사용하고 값이 입력된 조건을 체크 조건으로 사용해 위와 같은 비효율이 발생한 것으로 판단된다.
이 비효율을 개선하기 위해서는 이 두 조건을 UNION ALL로 분리하여 값이 입력되는 조건에 따 라 인덱스를 선택적으로 사용할 수 있도록 하여야 한다.
두 번째 비효율은 사절고객정보를 해쉬 조인으로 수행한 부분이다. 해쉬 조인의 경우 먼저 스스로 처리 범위를 줄인 후 조인에 참여하므로 대용량 데이터의 조인 시에는 문제가 되지 않지만 위의 경우 처럼 조인의 대상 집합이 1건인 경우에는 더 많은 비효율이 발생하게 된다.
이 비효율을 개선하기 위해서는 위험고객기본 테이블을 차례로 액세스하면서 그 결과를 가지고 사 절고객정보 테이블을 탐침할 수 있도록 Nested-Loop 조인으로 조인 방식을 변경하여야 한다. 마지막 비효율은 계약선택경로 테이블과의 조인 방식에 대한 부분이다. 계약선택경로 테이블의 경 우 코드성 테이블로 비교적 적은 집합이라 해쉬 조인으로 인한 비효율이 크게 나타나지 않았다. 하지 만 선행 집합이 아주 작은 집합이므로 선행 집합의 결과로 조인을 수행하는 Nested-Loop 조인으로 변경을 해야 한다.
아래의 SQL과 실행 계획은 위와 같은 관점에서 최적화를 수행한 결과이다.
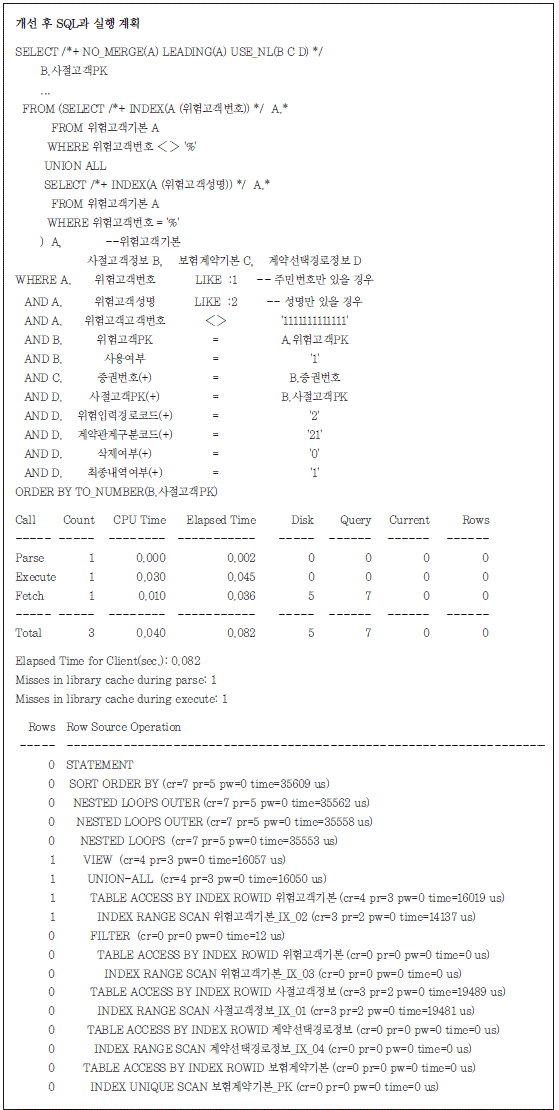
2) 오라클 실행 계획 분석 사례 2
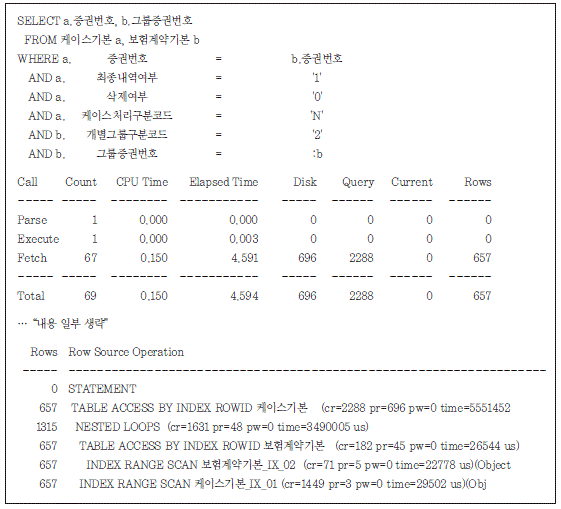
위의 실행 계획을 보면 케이스기본 테이블 액세스에 대부분의 시간이 소요되고 있는 것을 알 수 있다 (주의! 위 사례에서는 오퍼레이션 수준 통계에서 보이는 5.55초, 즉“time=5551452 us”는 쿼리 수행 통계 부분의 4.594초와 불일치하지만 대부분의 소요 시간이 케이스기본 테이블 액세스에서 발생했다 는 사실은 변함없다).
케이스기본 테이블을 657회 탐침하면서 651번의 물리 블록 읽기(pr 696 - pr 45)가 발생하였다는 것은 읽고자 하는 657개의 데이터 로우 각각이 서로 다른 데이터 블록에 저장되어 있다는 의미이다. 이 때문에 처리 시간의 대부분이 651번의 물리 블록 읽기에서 소요되었다. 개선을 위해서는 케이스기본 테이블 로우가 동일한 그룹증권번호로 클러스터링될 수 있도록 테이블 을 정렬하는 것이다.
3) MS-SQL 실행 계획 분석 사례 1 : 스칼라 서브쿼리에서의 비효율

위 실행 계획은 from절에서 테이블 5개를 조인하고 select-list에서 스칼라 서브쿼리 3개를 기술한 SQL의 트레이스 결과다. 오라클에서는 스칼라 서브쿼리가 메인 쿼리의 실행 계획 맨 위에 별도로 표 시되지만 SQL 서버에서는 일반적인 조인 형태로 표현된다.
트레이스 파일의 상단에는 테이블별 스캔 수와 페이지 읽기 수가 표시되는데, 위 트레이스 파일에서 는 mBarItm 테이블의 페이지 읽기 수가 매우 큰 것을 알 수 있다. 트레이스 파일의 아래에서 6번째 줄을 보면 IX_mBarItm_01 인덱스를 Index Scan 방식으로 액세스해 0건을 출력했다. 이 부분에 별 다른 비효율이 없어 보이지만 SQL 서버에서 Index Scan 연산은 해당 인덱스를 처음부터 끝까지 스캔 하는 것을 의미하므로 인덱스를 전체 스캔해 결과가 0건이라는 의미이다.
Nested Loop 조인 시 Inner 집합의 조인 속성에 인덱스가 없으면 Outer 집합에서 출력된 건 수만 큼 반복해서 Inner 집합을 전체 스캔해야 하기 때문에 많은 비효율이 발생한다. 그런데 다행히 outer 집합에서 1건이 출력되었으므로 IX_mBarItm_01 인덱스를 1번만 전체 스캔하였다.
비효율을 개선하려면 스칼라 서브쿼리에서 IX_mBarItm_01 인덱스를 Index Seek(* 오라클의 index range scan 또는 index unique scan과 같음) 방식으로 액세스하도록 SQL을 개선해야 한다.
다음은 mBarItm에 생성된 인덱스 정보이다.
reate index IX_mBarItm_01 on mBarItm (bar_code);
create index IX_mBarItm_02 on mBarItm (bar_no);
개선 전 SQL에서 메인 쿼리가 먼저 수행되면 메인 쿼리의 m.lot_no는 상수가 되기 때문에 스칼라 서 브쿼리는 where bar_code like [상수값]||’%’형태의 검색 조건으로 대체되므로 인덱스 IX_mBarItm_01을 사용해 수행되어야 한다. 그런데 우리가 원하는 방식으로 실행되지 않았다.
옵티마이저가 우리가 원하는 액세스 패스를 가지도록 유도하기 위해 논리적으로 동일한 결과를 가지는 m.lot_no is not null이라는 dummy 조건을 추가하였다. 개선 후 실행 계획에서 옵티마이저가 인덱스 IX_mBarItm_01을 사용하여 정상적으로 액세스하고 있는 것을 확인할 수 있다.

4) MS-SQL 실행 계획 분석 사례 2 : OR 조건에 의한 비효율

위 SQL의 트레이스 결과를 분석해 보면 IX_mShipMst_01 인덱스에서 454건을 추출하여 mBarHis 테이블과 Nested Loops 방식으로 454회 탐침을 시도하였으나 결과는 1건만 추출되었다는 사실을 알 수 있다.
탐침을 시도한 횟수가 454회인데 결과 건수가 1이라는 것은 테이블 액세스에서 453건이 제거된다는 의미이며, Inner 집합을 탐침할 때 처리 범위를 결정하는 데 참여하지 못하고 있는 아주 변별력이 좋은 조건이 있다는 의미이다.
실제로 mBarHis 테이블의 2개 칼럼에 똑똑한 변수 값이 각각 제공되었지만 or 조건에 의해 각 칼럼 에 생성된 인덱스를 사용하지 못했다. 문제의 or 조건 대신 union 연산자로 실행 계획을 분리하여 비 효율을 제거할 수 있다.
개선 후 SQL을 보면 union으로 분리된 각각의 SQL이 IX_mBarHis_01 인덱스와 IX_mBarHis_02 인덱스를 효율적으로 사용했음을 알 수 있다. union all 대신 union을 사용함으로써 Sort(DISTINCT …) 연산이 발생한 것이 불만이기는 하지만 이 사례에서는 중복 건이 존재하므로 불가피한 선택이었다.

성능 개선 도구
DBMS에서는 성능 개선이나 모니터링을 하기 위한 기능을 제공하고 있다. 각 기능은 차이가 있 다. 기본적으로 서버 상태, 트레이스(Trace), 딕셔너리(Dictionary) 정보, 실행 계획을 제공하고 있 다. 여기에 소개하는 오라클, UDB, SQL 서버 외의 DBMS에서도 유사한 기능을 제공한다.
Oracle
StatsPack/AWR
8i부터 사용하던 Statspack, 10g 이후 사용하게 된 AWR(Automatic Workload Repository)은 오라클이 제공하는 표준 성능 관리 도구다(그 이전에는 utlbstat/utlestat 스크립트를 이용해 비 슷한 리포트를 뽑아볼 수 있었다). 이들 도구가 제공하는 기능을 간단히 요약하면 오라클이 내부적으로 누적 관리하는 다양한 동적 성능 뷰를 주기적으로 특정 리파지토리에 별도 저장했다가 사용자가 원하는 시점에 특정 기간 동 안의 성능 분석 리포트를 출력해 봄으로써 데이터베이스 전반의 건강 상태를 체크할 수 있게 해 주 는 것이다.
부하 프로파일, 인스턴스 효율성, 공유 풀 통계, Top 5 대기 이벤트 발생 현황 등을 일목요연하게 보여줄 뿐만 아니라 분석 항목별 상세 분석 자료를 제공함으로써 데이터베이스 성능 병목 현상이 발생하는 주원인을 쉽게 찾을 수 있게 해 준다. Statspack과 AWR은 거의 비슷한 내용을 담고 있 으며, 다른 점이 있다면 정보를 수집하는 방식에 있다. Statspack은 SQL을 이용해 데이터 사전 을 조회하는 방식인데 반해, AWR은 SGA를 DMA(Direct Memory Access) 방식으로 직접 액세 스하므로 좀 더 빠르게 정보를 수집한다. 상대적으로 부하가 적으므로 이전보다 더 많은 정보를 수 집하고 제공할 수 있게 된 것이다.
SQL 트레이스
SQL 트레이스는 데이터베이스의 인스턴스 또는 세션 단계에서 수행되는 모든 수행 SQL의 통계 치 및 대기 이벤트에 대한 정보를 수집해 주는 기능을 제공한다. 주요 수집 정보로는 파스(Parse), 실행(Execute), 패치(Fetch) 시의 CPU 사용시간, 수행(Elapsed) 시간(대기 시간 포함), 메모리 블록 I/O 횟수 및 디스크 블록 I/O 횟수 등이 있다. 또 선택적으로 대기 이벤트에 대한 정보도 같 이 수집하게 할 수 있다. TKPROF를 이용하면 수집된 정보를 가공하여 분석하기 용이한 레포팅 기능을 제공한다. SQL 트레이스를 통해 응답 시간 또는 처리 시간을 줄일 수 있는 대상 SQL을 식 별할 수 있고, 수집 기간 동안 수행된 모든 SQL에 대한 정보를 담고 있기 때문에 인덱스 설계 시 에 직접적인 자료로 활용된다.
IBM UDB
스냅샷 모니터
DB2의 운영, 성능, 애플리케이션에 대한 정보를 수집할 때 사용할 수 있는 모니터링 방법이며, 스 냅샷이나 이벤트 모니터를 사용하고 특정 시점에서의 데이터베이스 활동에 관한 정보를 제공하며, DB2 활동 상태에 대한 정보이다. 스냅샷을 취했을 때 사용자에게 반환되는 정보 양은 사용하는 모니터 스위치에 의해 결정된다. 이 스위치들은 인스턴스 또는 인용 프로그램 레벨에서 설정할 수 있다. 이 데이터는 DB2가 수행될 때 유지되고, 성능과 문제 해결을 위한 중요한 정보로 제공된다.
이벤트 모니터
이벤트 모니터링은 DB2 이벤트의 특정 사건 발생을 기록한다. 교착 상태, 연결, SQL 문장들을 포 함한 일시적인 이벤트 정보를 수집할 수 있다. 스냅샷 모니터링이 스냅샷을 취할 때 데이터베이스 활동의 상태를 기록하는 반면, 이벤트 모니터는 이벤트나 전이가 발생할 때 데이터베이스 활동을 기록한다. 이벤트 모니터는 SQL DDL을 사용하여 생성된다.
SQL 모니터링
SQL이 어떻게 수행되는지를 알기 위해서는 액세스 플랜을 분석한다. 실행 계획 기능은 SQL 문장 을 해석하기 위해 어떻게 DB2가 데이터를 액세스하는지에 대한 정보를 제공한다. 다.
NT 성능 모니터링
운영체제의 특정 구성 요소에서 사용하는 리소스 및 프로그램에서 사용하는 리소스에 대한 자세한 데이터를 제공하며, 성능 모니터링을 통해 CPU, 메모리, 디스크 등에 대한 다양한 정보를 얻을 수 있다. 상태를 실시간으로 모니터링할 수도 있으며 그 내역을 파일로 저장하여 엑셀 등에서 다양한 방법으로 분석할 수도 있다. 물론 원하는 시간 동안 자료를 수집하도록 스케줄링도 가능하다.
SQL 프로파일러
SQL 서버 인스턴스의 이벤트에 대한 데이터를 캡처하고 파일 또는 테이블에 저장하여 분석할 수 있는 기능을 제공한다. 수집된 트레이스를 분석하여 주요 액세스 경로를 파악할 수 있으며 인덱스 설계 시에 기초 자료가 된다. SQL 프로파일러를 사용해 SQL 서버 인스턴스의 성능을 모니터링하 고, 트랜잭션 SQL문과 저장 프로시저를 디버그하며, 실행 속도가 느린 쿼리를 확인할 수 있으며, 운영 시스템에서 이벤트를 캡처하고 테스트 시스템에서 그 이벤트를 재생하여 SQL 서버의 문제 를 해결할 수 있다. 또한 SQL 서버 인스턴스에서 발생하는 동작을 감시하고 검토할 수 있다.