
데이터이야기
DB 노하우, 데이터직무, 다양한 인터뷰를 만나보세요.
구매패턴 기반 구매감소 고객 예측 THE CHALLENGES 프로젝트 시작 시점에 조원들이 브레인스토밍 방식으로 토론해 ‘유통 패러다 임의 급격한 변화 및 유통사들의 대응 방안’을 관심 주제로 선정했다. 주제 관 련 데이터를 입수·탐색하면서 프로젝트 과제를 구체화했다. 고객 만족의 중요 성은 더욱 강조되는 반면, 비정형적·복합적인 고객 행동에 대한 유통업체 대응 은 점점 어려워지고 있다. 이로 인한 구매감소 고객의 지속적인 발생이 유통업 계의 현안이라는 사실에 주목했다. 실례로 국내 및 글로벌 대표 유통 브랜드의 온라인, 온오프 통합 분야에 대한 고객 반응도가 각각 상이하게 나오는 것을 네이버와 구글 트렌드 분석으로 확인했다. 고객은 채널과 무관하게 만족할 수 있는 쇼핑경험을 제공하는 기업에 반응하고, 그 반대의 경우는 외면하게 된다. 고객이 만족할 수 있는 경험가치를 어떻게 제공할 수 있을까 그 해답은 다양 한 고객 니즈와 구매 패턴에 기반한 고객 경험을 제공해야 한다는 사실에서 찾 아볼 수 있다. THE APPROACH 고객 구매패턴 변동을 파악할 수 있는 데이터로 유통업체의 통합 멤버십 고객 정보, 구매 이력 데이터, 비즈니스 도메인 정보로 온/오프라인 유통사업 현안 자료를 수집했다. 네이버·구글 트렌드 분석 데이터도 활용했다. 학술연구 목적 이고 공개된 데이터를 수집하는 경우였지만 불필요한 오해를 방지하기 위해 특정 업체명은 모두 익명 처리했다. 데이터 수집 후 탐색 및 변수화 과정에서 직면한 첫 번째 이슈는 수집된 데이 터의 전처리 문제였다. 통합 멤버십 고객 2만 명이 4개 제휴사와 거래한 2800 만 건의 방대한 구매이력 데이터를 탐색하면서 고객별로 데이터 정리가 쉽지 않았다. 엑셀이나 R에서는 데이터 처리 자체가 불가능했다. SQL로 고객별 월 별 데이터로 1차 가공을 했다. 가공된 데이터를 R로 가져와서 어렵게 탐색을 수행할 수 있었다. 최종 선정된 29개 변수를 적용·분석한 예측모형 수행의 첫 단계는 ‘구매감소 고객을 어떻게 정의할 것인가’였다. 2년간 고객 데이터를 반기별로 4기로 구 분해 1~3기는 데이터 예측 모형, 4기는 평가용으로만 각각 활용하기로 했다. 1기와 4기를 비교해 평균 구매 증감률 대비 하락한 고객을 구매감소 고객으로 정의했다. 3가지 예측모형의 분석결과를 종합적으로 평가해 정확도가 상대적으로 양호 한 rf 모형을 기본 예측모형으로 사용하기로 했다. rf는 물론 logit이나 dt 모형 에서 파악한 인사이트를 종합해 구매감소 고객에 대한 대응방안 수립에 활용 했다. 예측모형에서 파악한 인사이트를 기반으로 구매감소 고객의 구매패턴을 유형 화하고 대응방안을 마련했다. dt의 노드 분류 기준 값이 더 구체적인 유형화의 기준을 제공해 주었다. 고객의 구매패턴을 감소고객 4개, 증가고객 3개를 포함 한 7개 유형으로 구분했다. 유형별 구매패턴에 대한 대응 방안을 수립했다. 각 유형의 구매패턴을 보이는 고객의 미래 구매감소 여부를 예측하고, 대응 조치 를 사전적으로 실행할 수 있는 가이드가 마련됐다. THE OUTCOME 요즘 들어 고객 경험의 가치가 더욱 더 중요해지고 있다. ‘구매패턴에 기반한 구매감소 고객 예측모형’은 시장환경에서 유통업체들이 고객의 구매행동을 더 구체적으로 이해하고 고객의 어려움(Pain Points)에 대해 사전에 대응함으로써 구매감소를 최소화할 수 있다는 점에서 의미를 찾을 수 있다. 이번에 만든 모 형은 다양한 고객의 구매패턴 및 업종별 비즈니스 도메인의 특성을 반영할 수 있는 추가 변수를 개발해 좀 더 정교하고 완성도를 높여갈 계획이다. 특히 급 변하는 유통 환경에서 고객 경험 가치 제고를 더 이상 방치할 수 없음에도 구 체적인 실행 방안의 부재로 어려움을 겪고 있는 중소기업 및 소상공인에게 특 화한 ‘구매패턴 기반 구매감소 고객 예측모형’으로 발전시켜 나갈 계획이다 [유통1기] 구매패턴 기반 구매감소 고객 예측
몇 차례 논의와 수정을 거듭한 후에 ‘구매패턴 기반 구매감소 고객 예측 및 대응방안’을 프로젝트 과제로 선정하는 데 전원 의견 일치를 보았다. 데이 터 수집, 전처리, 변수 선정, 예측분석, 대응방안 수립 등 본격적인 프로젝트에 착수했다. 예상하지 못한 문제에 직면해 상이한 해법으로 갈등을 겪기도 했다. 하지만 과제 선정 과정에서 형성된 조원간 공감과 신뢰를 바탕으로 문제를 하 나씩 풀어나갈 수 있었다. 
데이터 수집
데이터 탐색 및 변수화
두 번째 이슈는 업체별로 상품 분류 기준이 상이한 문제였다. 상품별로 고 객 구매 패턴을 분석하지 못할 수도 있겠다는 불안감이 밀려왔다. 의미 있는 데이터 해석의 전제 조건인 표준화한 상품 분류 기준을 작성했다. 관련 데이 터를 새로운 기준에 맞춰 다시 분류할 필요가 있었다. 변성원 조원의 헌신적인 노력으로 상품 유형별·수준별로 표준화한 상품 분류기준을 완성하면서 문제 해결의 실마리를 찾을 수 있었다. 결국 상이한 4개 제휴사 상품 분류기준을 14 개 카테고리, 3개 레벨로 표준화할 수 있었다.
세 번째 이슈는 구매패턴의 변동요인을 반영할 수 있는 변수를 도출하는 문제였다. 고객별 구매변동 패턴을 반영하는 구매변동 및 증감지수를 산출하 면서 분석의 기초가 되는 45개의 변수를 얻을 수 있었다. 데이터 탐색 및 변수 화 작업의 마지막 이슈는 변수의 적합성 검증이었다. rf의 importance 기능 을 활용해 변수의 중요성을 확인하고, 45개 변수 중 정확도와 불순도 개선 기 여도 측면에서 중요한 32개의 변수를 추려냈다. 변수의 분산 값이 0에 가까운 의미 없는 변수 3개를 추가로 제외한 후에 29개의 변수를 최종 선정했다. 최종 선정된 변수 29개는 구매감소 고객 여부를 대변하는 반응변수 1개와 설명변수 28개다. 설명변수는 고객속성 변수 6개, 구매증감 변수 11개, 구매변동 변수 11개로 구성됐다. 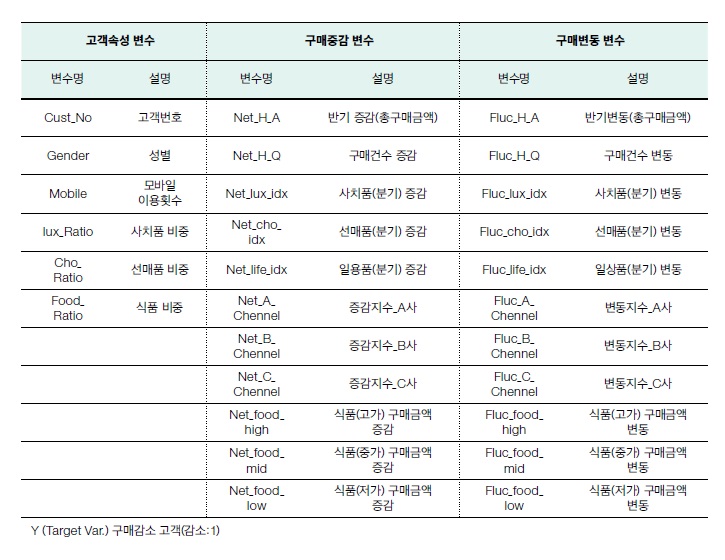
예측모형 구축
두 번째 단계는 예측모형 수행 방법이었다. 기본적으로 1기와 4기를 비교 해 구매감소한 고객의 1~3기 기간 중 구매패턴을 기계학습으로 훈련시켜 4기 대한 예측모형을 생성하는 방식이었다. 예측모형 평가를 위해 전체 데이터 를 7:3으로 랜덤 샘플링해 트레인 데이터와 테스트 데이터로 분리했다. 트레인 데이터를 적용해 생성된 예측모형을 테스트 데이터로 검증했다.
세 번째 단계로 분석할 예측모형을 선정했다. 분류분석의 대표적인 모형 인 랜덤포레스트(Random Forest), 로지스틱 회귀분석(Logistic Regression), 디 시전 트리(Decision Tree)를 선택했다. 랜덤포레스트로 예측모형을 수행한 결 과, 예측 정확도는 상대적으로 양호한 78.05%로 나왔다. rf 일차 수행 시 중요 파라미터인 ntree(나무의 수)와 ntry(노드 분류기준으로 고려할 변수의 개수)는 각각 디폴트 값으로 500과 5가 적용됐다.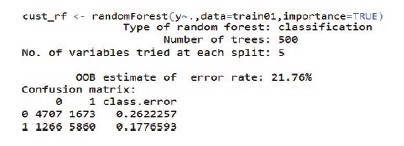
ntree와 mtry가 각각 디폴트값으로 500과 5로 수행된 것에 대한 적합 성을 검증했다. ntree는 500까지는 미세하게 에러가 축소되고 있었다. mtry 는 5일 때 에러가 최소화되는 것을 확인함으로써 예측모형 수행 결과를 신뢰 할 수 있었다. 로지스틱 회귀분석(Logistic Regression) 모형 수행 과정에서, 일 차적으로 28개 설명변수 모두를 트레인 데이터에 적용한 logit 모델을 step function에 적용했다. AIC(Akaike Information Criterion) 값이 최저 수준인 12,758일 때의 16개 변수를 얻을 수 있었다. Summary를 통해 베타 계수 값 을 확인하는 과정에서 16개 변수의 예측 기여도를 파 악하고 인사이트를 발굴할 수 있었다.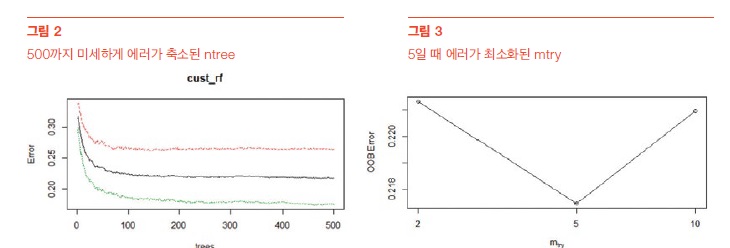
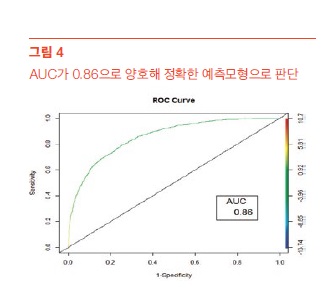
생성된 logit 모형에 테스트 데이터를 적용해 예 측점수를 산출했다. ROC Curve를 사용하기 위해 예 측점수와 테스트 데이터의 실제 y값으로 prediction 객체를 만들었다. 이를 performance() 함수에 넘겨 tpr(구매 감소하지 않는 고객을 구매 감소하지 않았다고 예측) 및 fpr(구매 감소하는 고객을 감소하지 않았다고 예측)을 구 했다. tpr과 fpr을 각각 X, Y축으로 하는 ROC Curve 를 이용해 성능을 최대화하는 Cutoff value 0.04를 선택했다. ROC Curve 아래 면적을 의미하는 AUC가 0.86으로 양호해 예측모형은 정확하다고 판단 할 수 있었다.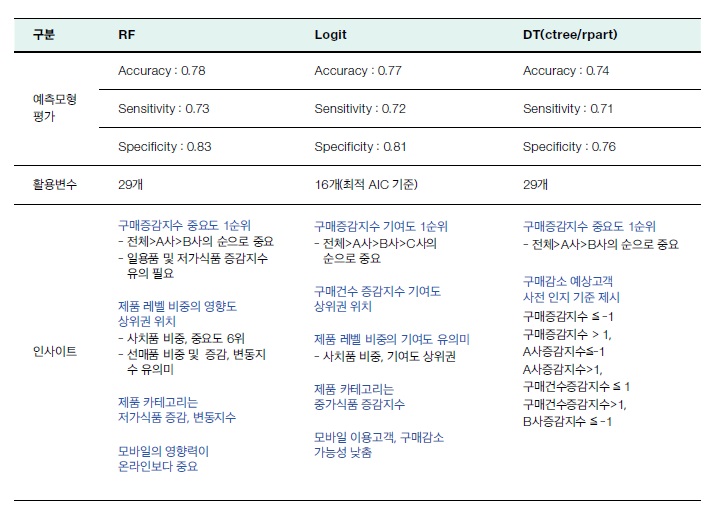

Cutoff value 0.04를 기준으로, 예측 값을 0과 1로 분류해 주고 실제 y값 과 같이 confusionMatrix를 수행한 결과 예측모형의 정확도 76.99%를 구할 수 있었다. 디시전 트리 모형은 예측 정확도가 74%로 조금 떨어졌다. 하지만 구매감소 고객 예측에 적용되는 핵심 변수의 기준 값을 구체적으로 제시해 준 다는 측면에서 유용하게 활용했다.
예측모형 평가 및 인사이트 도출
구매패턴 유형별 구매감소 고객 대응방안