데이터인 인터뷰: 박민숙, 윤현경 교수
“데이터 리터러시와 수치적 리터러시”
 △ 박민숙 교수
△ 박민숙 교수
University of Wisconsin Milwaukee 정보학과 조교수로 근무하고 있다.
주요 연구 분야는 텍스트 마이닝을 이용한 건강정보 행태 분석, 메타데이터, 건강 정보 조직이다. △ 윤현경 교수
△ 윤현경 교수
Arizona State University 수학과 전임강사로 근무하고 있다.
주요 연구 분야는 교사 교육, quantitative reasoning 이다.각종 데이터들이 풍부해지면서 산업, 교육, 의료 등 특정 전문 분야 뿐 아니라 우리 일상생활에 대한 많은 것들이 데이터로 기록되고 있고, 이런 데이터에 기반해 해결책을 찾고 결정을 내리는 일이 흔해졌다. 데이터가 흔해진 만큼, 쏟아지는 데이터 중에서 해결을 원하는 문제에 적합한 데이터를 선택하고, 데이터를 통해 전달하고자 하는 정보를 적정하게 유출하여 합리적인 결정을 내리는 능력이 어느 때 보다 중요해졌다. 이렇게 데이터를 선택하고, 그 품질을 평가하고, 데이터에서 정보를 도출하고, 그 정보가 우리 실생활에 의미하는 바를 이해하고 그 의미를 타인에게 전달하는 일련의 역량을 통틀어 데이터 리터러시라고 한다 (Prado & Marzal, 2013; Wolff et al., 2016).
데이터 리터러시를 소개하는 글의 경우 대체로 데이터 이해 및 평가 능력에 초점을 두고 있어, 데이터 리터러시를 데이터 전문가,데이터 사이언티스트, 혹은 비지니스 애널레릭스와 같은 전문가에게만 요구되는 특수한 능력으로 오해하기 쉽다. 하지만 데이터 리터러시를 정의하는 연구내용을 보면 현실에 대한 적용 능력 역시 데이터 리터러시에 포함되어 있을 뿐만 아니라 적용 능력의 중요성에 대해서도 강조하고 있다. 데이터 리터러시에서의 적용 능력이란, 우리가 실제 생활에서 마주치는 상황에 대해 데이터에서 얻어낸 정보를 적용하고 해결책을 도출해 낼 수 있는 역량을 말한다. 다르게 표현하자면, 데이터를 읽고 해당 데이터가 전달하고자 하는 적합한 정보를 유출하는 능력은 결국 우리가 실제 생활에서 겪고 있는 여러가지 문제를 해결하는데 이용하기 위한 것이라고 보고 있다. 따라서 데이터 자체에 대한 이해 뿐 아니라 이를 실생활에 적용하여 적합한 판단을 할 수 있는 능력을 종합적으로 ‘데이터 리터러시’라고 정의한다.
이 칼럼에서는 데이터 리터러시를 구성하는 두가지 측면, 즉 데이터에 대한 해석과 이를 실생활에 적용하는 능력에 대해 코로나바이러스 관련 데이터를 예로 들어 소개하고자 한다. 코로나바이러스 발생률과 관련된 데이터 표현 (data representations) 중 하나인 그래프를 통해 데이터에서 적합한 정보를 유추하기 위해 필요한 수학적 개념을 바탕으로 도출해낸 정보를 현재 우리 실생활에 어떻게 적용할 수 있는지 설명하고자 한다.
1. 데이터 표현(data representations)의 해석과 수치적 리터러시 (quantitative literacy)
데이터 자체는 사람의 몸무게, 키, 생일 등을 기록한 단순 숫자 혹은 단순 텍스트 등이 나열된 형태로 그 자체로 의미를 갖는 경우는 많지 않다. 이러한 데이터들이 특정한 컨텍스트(context)내에서 재구성되었을 때 사람에게 의미를 갖는 정보가 된다. 예로 아래 그림 3 과 4 를 예제로 보자. 두 개 그림에 있는 숫자는 동일한 숫자들이다. 하지만 그림 3 은 그 자체로는 별다른 의미를 전달하지 않는 단순한 숫자의 나열처럼 보이는데 반해, 그림 4 와 같이 특정 컨텍스트를 부여 받게 되면 데이터가 가지고 있는 의미가 정보이용자에게 전달된다.
 △ 그림 3. 미가공 데이터 예제
△ 그림 3. 미가공 데이터 예제
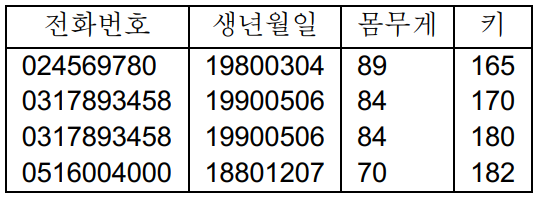 △ 그림 4. 컨텍스트가 부여된 데이터 예제
△ 그림 4. 컨텍스트가 부여된 데이터 예제
특정 데이터를 접했을 때, 그 주어진 데이터와 우리의 기존 지식 및 다른 데이터 들과 함께 제시되면 우리는 그 데이터 속에서 ‘정보’를 얻어낼 수 있다. 예를 들자면, 하나의 엑셀 파일에 수천 명의 키, 몸무게, 생일이 기록되어 있고, 다른 엑셀에는 동일한 사람들과 그 직계가족들이 그 동안 앓았던 각종 병력 (예, 비만, 당뇨, 혈압, 콜레스테롤 등)이 여러 칼럼에 걸쳐 기록되어 있다고 생각해보자. 이 두 가지 데이터들이 합쳐서 ‘환자의 병력’이라는 컨텍스트 안에서 이 데이터를 분석하고 기존의 의학 지식을 이용하면 ‘X 나이의 사람이 키와 몸무게의 비율이 평균 XX 이상인 경우 콜레스테롤이 높아 고지혈증이 될 확률이 XX %다 ’ 라거나 ‘직계가족 중 고혈압 환자가 있을 경우, XX 년생 이상은 고혈압 진단을 받을 필요가 있다’ 라는 정보 (가족력과 고혈압, 나이 및 해당 정보간의 상관관계)와 더불어 이와 관련된 판단 (고혈압 진단의 필요성)을 내릴 수 있다. 이렇게 적정한 데이터를 선택하고 특정한 컨텍스트 내에서 놓일 때 데이터는 이용자에게 데이터가 전달하려는 전반적인 배경을 전달할 수 있게 된다.
그러나 데이터에서 유의미한 정보를 유출하기 위해서는 컨텍스트 뿐 아니라 다른 형태의 리터러시도 요구된다. 그 중 수치적 리터러시 (quantitative literacy) 혹은 산술능력 (numeracy)은 데이터 리터서리를 갖추기 위해 필수적인 기초 리터러시로 꼽힌다 (Shields, 2005; Wolff et al., 2016). 우리가 일상생활에서 접하는 데이터의 경우, 미가공된 데이터를 접하는 경우는 드문 편이며, 데이터를 가공한 형태인 데이터 표현(data representation)으로 접하는 경우가 더 흔하다. 그래프, 테이블, 인포그라픽스 등은 우리가 일상에서 흔히 접할 수 있는 가공된 형태의 데이터 표현 중 하나이다. 이런 데이터 표현은 많은 경우 수학 및 통계 개념 (예, 백분율, 평균 등)을 바탕으로 가공되는 경우가 많기 때문에 정확한 정보를 도출하기 위해서는 데이터 표현을 뒷받침하고 있는 수학 및 통계 개념에 대한 이해가 요구 되기 때문에 수치적 데이터 리터러시를 데이터 리터러시에 수반되는 주요 능력 중 하나로 본다 . 수치적 리터러시란 수학적 구조를 이해하고 경제상황에 대한 결정 등 실생활에 적용시키는 능력 일체를 말하며 (Hallett, 2003; Steen, 1999; Wiest et al., 2007) 수치적 리터러시를 갖춘 사람은 주어진 정보 소스에 수치적 이해력을 적용하여 필요한 상황에 대한 판단을 내릴 수 있다고 본다 (Hallett, 2003).
다소 어렵게 느껴질 수 있는 데이터 리터러시와 데이터 표현, 수치적 리터러시의 관계를 이해하기 위해 아래 두 가지 코로나-19 확진자 수 현황에 대한 그래프를 이용해 보자. 아래 그래프가 전달하고자 하는 정보를 적합하게 유출하기 위해서 수치적 리터러시가 어떻게 적용되는지 예제를 통해 살펴보자. 그림 1 의 그래프는 각각 2020 년 1 월부터 4 월까지 우리나라에서 발생한 코로나-19 확진자 수에 대한 그래프이며, 그림 2 의 그래프1는 미국, 이탈리아 및 한국에서 같은 기간 동안 발생한 코로나-19 확진자 수를 나타내는 그래프이다.
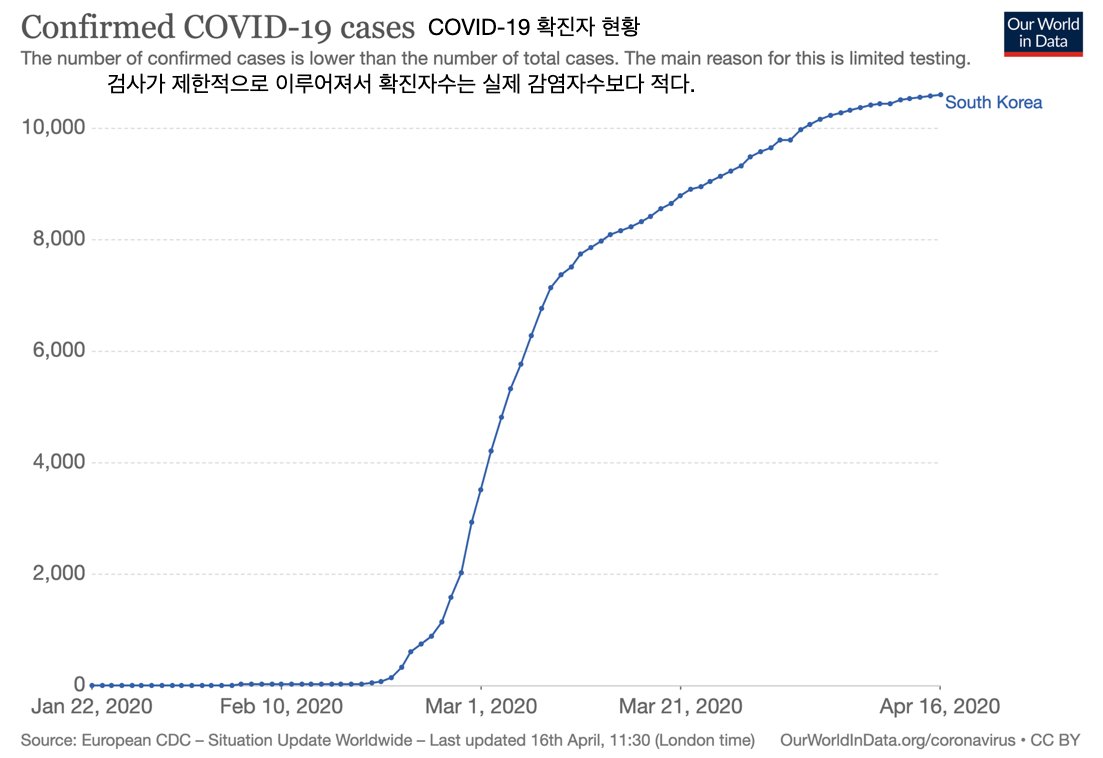 △ 그림 1. 한국의 코로나-19 총 확진자 수 (출처: Our World in Data)
△ 그림 1. 한국의 코로나-19 총 확진자 수 (출처: Our World in Data)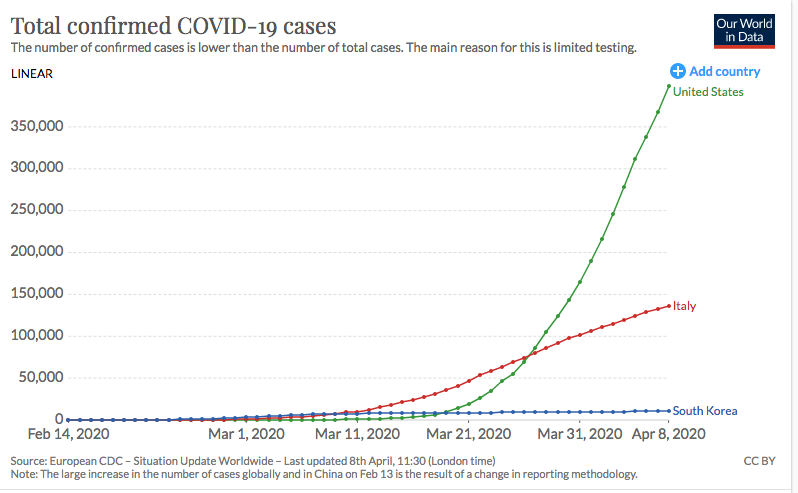 △ 그림 2. 미국, 이탈리아 및 한국 코로나-19 총 확진자 수 (출처: Our World in Data)
△ 그림 2. 미국, 이탈리아 및 한국 코로나-19 총 확진자 수 (출처: Our World in Data)그림 1 과 2 에서 가로축은 날짜를 나타내고, 세로축은 총 확진자 수를 나타낸다. 그래서 그래프의 한 점은 특정 날짜까지 발생한 총 확진자 수의 정보를 가지고 있다. 예를 들어 그림 1 을 보면 2020 년 3 월 1 일까지 한국에서 발생한 총 확진자 수는 약 3,700 명이라는 것을 알 수 있다. 이와 같이 그림 1 과 2 와 같이 그래프로 주어진 정보를 해석할 때에는 가로축과세로축을 모두 사용하여 해석해야 하는데, 그래프의 모양만으로 해석하는 경우가 있다. 가상의 인물인 민수와 영희가 있다고 가정해보자. 수치적 리터러시가 약한 편인 민수는 그래프의 가파른 정도만 보고 그래프를 해석하고, 수치적 리터러시가 높은 영희는 가로축과 세로축의 정보로 그래프를 해석한다고 가정해보자. 민수는 가로축과 세로축의 정보를 가지고 그래프를 해석하기 보다는 기울어진 정도로 그래프를 해석하기 때문에 그림 1 과 2 그래프에서 가파르게 증가한 부분은 확진자 수가 빠르게 증가하는 경우라고 생각하고, 완만하게 증가한 부분은 확진자 수가 천천히 증가한다고 생각하기 쉽다. 따라서, 민수는 그림 1 에서 한국의 총 확진자 수가 그래프가 가파르게 변하다가 다시 완만해지기 때문에 한국에서 코로나바이러스의 상황이 나빠지다가 점차 좋아지는 것으로 해석할 수 있다. 그 후 민수는 그림 2 를 보고 한국의 총 확진자 수 그래프가 계속 완만하기 때문에 한국의 상황은 계속 좋다고 해석할 수 있다. 따라서 민수는 그림 1 과 그림 2 의 한국의 총 확진자 수 그래프가 다른 정보를 가지고 있다고 생각할 수 있다. 반면 가로축과 세로축의 정보를 가지고 그래프를 해석하는 영희는 그림 1 의 세로축과 그림 2 의 세로축을 보고 그림 2 의 세로축 숫자가 그림 1 보다 훨씬 크다는 것을 알았다. 영희는 그림 2 에서 한국의 총 확진자 수 그래프의 세로축 숫자를 보고, 한국의 총 확진자 수가 미국이나 이탈리아보다 현저히 적기 때문에 완만하게 보여지지만 그림 2 의 한국 그래프의 확대하면 그림 1 의 그래프와 동일하다고 판단했다. 가파른 정도로만 그래프를 해석한 민수는 그림 1 과 2 에서 한국의 총 확진자 수 그래프가 동일하다는 정보를 파악하지 못했지만, 영희는 그림 1 과 2 의 그래프가 한국의 총 확진자 수에 대해 같은 정보를 전달하고 있다는 것으로 판단했다..
위 예제 그래프에서 볼 수 있는 것처럼 같은 정보를 전달하는 데이터 표현이라 하더라도 시각적으로는 다르게 보일 수 있다. 그래프를 구성하고 있는 수학적 구조를 이해하고 있다면 위의 예제처럼 다르게 보이는 그래프에서 같은 정보를 유추할 수 있다.
2. 실생활에 대한 적용
데이터는 위에서 살펴본 바와 같이 숫자 혹은 텍스트 등으로 구성된 미가공 데이터로 단순한 팩트만을 기록한 내용이거나 혹은 특정한 컨텍스트 안에서 정보를 전달하기 위해 가공된 데이터 표현 등으로 전달된다. 이러한 데이터가 우리에게 중요해진 근본적인 이유는 이러한 일련의 숫자 혹은 그래프 등이 우리가 처한 여러가지 상황에 대해 해결책 혹은 논리적인 결정을 내리는데 도움을 주기 때문이다. 위의 두 그래프의 예제로 돌아가서 보자. 확진자 수 증가세에 대한 정보를 도출한 경우, 우리나라에서 코로나-19 확진자가 급격히 늘어나기 시작한 시점을 이해하고 마스크나 사회적 거리 두기 등 코로나-19 확산 방지를 위해 시행하고 있는 각종 예방책을 어느정도 실천할 것인지에 대한 결정을 내리는데 도움을 줄 수 있다. 또한, 타 국가에서 진행과 비교하여 한국의 코로나-19 확산 상황이 상대적으로 얼마나 심각한지 혹은 안정적인 상황인지를 이해하는데도 도움을 받을 수 있다.
데이터에서 유출한 정보를 실생활에 적용할 수 있는 다른 사례로 또 다른 그래프의 한 형태인 바 차트를 한가지 더 살펴보자. 아래 바 그래프는 COViD-TASER (Creating Opportunities for Visualization of Data: The Application of STEM Education Research) 팀2 에서 개발하여 웹 상(https://www.covidtaser.com/relativerisk)에서 제공하고 있는 데이터 표현의 일부를 캡쳐한 것이다. 이 애플릿은 코로나-19 와 관련된 위험성을 우리가 실생활에서 마주할 수 있는 다른 위험성과 쉽게 비교할 수 있도록 디자인 되었다. 아래 바 차트를 이용하면 백신을 맞았을 때와 맞지 않았을 때 입원하게 될 위험성, 특정 백신을 맞고 그 부작용으로 병원에 입원하게 될 위험성 등을 바 차트의 길이 뿐 아니라 숫자 등을 통해 확인 할 수 있다. 가령 특정 백신의 부작용으로 인한 위험성과 백신 접종 후 코로나-19 에 감염되었을 때를 비교해서 어느 경우가 어느 정도 더 위험한 지에 대한 정보가 확실치 않아 결정을 내리기 어려웠다면 아래와 같은 데이터 표현을 통해 그 위험도를 비교하고 백신 접종 여부에 대한 결정을 내리는데 참고할 수 있다.
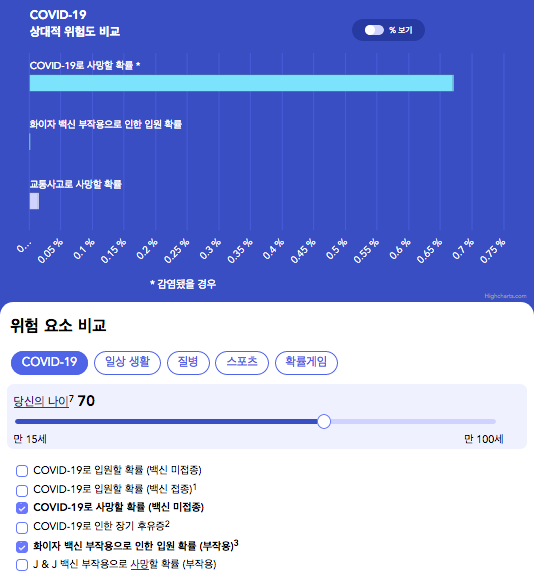 △ 그림 5. Relative Risk Measurement Applet (https://www.covidtaser.com/relativerisk)
△ 그림 5. Relative Risk Measurement Applet (https://www.covidtaser.com/relativerisk)
Relative Risk: (C) 2021 Cameron Byerley, Yoon Hyunkyoung, and COViD-TASER그림 5 의 첫 번째 막대는 70 세 사용자가 백신 미접종시 코로나바이러스에 감염되었을 경우 코로나 바이러스로 입원치료를 받을 확률이 7.52%라는 것을 보여준다. 그림 5 의 두 번째 막대는 70 세 사용자가 백신 접종시, 코로나바이러스로 입원 치료를 받을 확률이 0.45%라는 것을 보여준다. 따라서, 바 막대의 길이와 위험 확률은 70 세 사용자의 경우 백신 미접종시 코로나바이러스에 감염되어 이로 인해 입원치료를 받을 확률이 백신 접종 후 코로나 바이러스로 입원 치료 받을 확률의 약 17 배라는 것을 결론을 낼 수 있게 도와준다. 또한 백신 부작용에 대한 두려움으로 접종을 꺼리고 있을 경우, 70 세 사용자의 경우 특정 백신 부작용으로 입원할 확률은 0.00021%이며, 이는 백신 미접종시 코로나바이러스에 감염되어 입원치료를 받을 확률 (7.52%)이 백신 부작용으로 인해 입원 치료를 받을 확률의 약 35,800 배라는 것을 알 수 있게 해준다. 이렇게 위험 확률을 비교해보는 활동은 사용자들이 상대적으로 어느 선택이 더 위험한지를 판단하여 결정하는 데 도움을 줄 수 있다.
이와 같이 그래프 등 데이터 표현에는 수치적 리터러시를 요구하는 내용이 포함 되어 있으며, 이를정확히 이해하고 정보를 도출하면 우리 실생활에 필요한 결정을 내리는데 도움을 받을 수 있다. 본 칼럼에서는 현재 진행 중인 코로나-19 와 관련된 예제를 통해 데이터 리터러시가 산업 등 일부 전문적 지식을 요구하는 분야 뿐 아니라 우리의 일상생활과도 어떻게 연결되어 있는지 알아보았다. 이러한 데이터 리터러시는 빠르고 정확한 판단이 요구되는 산업, 마케팅 등에서 먼저 중요성이 부각되었으며 현재 데이터를 기반으로 다양한 시설, 기술 등이 다수의 분야에 도입 되면서 기타 여러분야에서도 그 중요성이 대두되고 있다.
데이터 리터러시는 빅데이터가 많은 분야에 적용되면서 특히 그 중요성이 더욱 부각되는 추세이다. 데이터 사이언티스트에게 필수적으로 요구 되는 여러 역량 중 하나가 데이터에서 정보를 유출하고 이를 정확하게 커뮤니케이션 하는 능력이다. 빅데이터 및 데이터 사이언스에 관심을 가진 분이라면 데이터 리터러시의 중요성과 그와 연결된 여러가지 개념에 대해 공부할 기회를 가져 보시길 바란다.
- 참고문헌
- Hallett, D. H. (2003). The role of mathematics courses in the development of quantitative literacy. Quantitative
Literacy: Why Numeracy Matters for School and Cholleges, 91–98.
- Prado, J. C., & Marzal, M. Á. (2013). Incorporating data literacy into information literacy programs: Core
competencies and contents. Libri, 63(2), 123–134.
- Shields, M. (2005). Information literacy, statistical literacy, data literacy. IASSIST Quarterly, 28(2–3), 6–6.
- Steen, L. A. (1999). Numeracy: The new literacy for a data-drenched society. Educational Leadership, 57, 8–13.
- Wiest, L. R., Higgins, H. J., & Frost, J. H. (2007). Quantitative literacy for social justice. Equity & Excellence in
Education, 40(1), 47–55.
- Wolff, A., Gooch, D., Montaner, J. J. C., Rashid, U., & Kortuem, G. (2016). Creating an understanding of data
literacy for a data-driven society. The Journal of Community Informatics, 12(3).
- Yoon, H., Byerley, C.O., Joshua, S., Moore, K., Park, M., Musgrave, S., Valaas, L., & Drimalla, J. (2021).
United States and South Korean citizens’ interpretation and assessment of COVID-19 quantitative data.
The Journal of Mathematical Behavior. 62, 100865. doi: 10.1016/j.jmathb.2021.100865
- 저자 약력
- 박민숙은 University of Wisconsin Milwaukee 정보학과 조교수로 근무하고 있다. 주요 연구 분야는텍스트 마이닝을 이용한 건강정보 행태 분석, 메타데이터, 건강 정보 조직이다. 윤현경은 Arizona State University 수학과 전임강사로 근무하고 있다. 주요 연구 분야는 교사 교육, quantitative reasoning 이다.
- * 위의 두 저자는 COViD-TASER 연구팀 소속으로, 본 칼럼은 COViD-TASER 연구팀에서 코로나-19 감염증에 대한 quantitative data representation 에 대한 연구에 사용되었던 예제 및 연구 산출물을 포함하고 있다.
- COViD-TASER 연구팀은 National Science Foundation RAPID grant (DUE- 2032688) 연구지원금을 기반으로 미디어에서 접하게 되는 코로나-19 관련 수치적 데이터 표현(quantitative data representations) 에 대한 일반시민들의 이해도를 연구하고, 이를 바탕으로 새로운 수치적 데이터 표현을 개발하고 있다. COViD-TASER 팀은 University of Georgia 소속의 Cameron Byerley, Ph.d., (PI), Arizona State University 소속의 윤현경 Ph.d. (co-PI), Surani Joshua Ph.d., University of Wisconsin Milwaukee 소속의 박민숙 Ph.d., University of Georgia 교수 Kevin Moore Ph.d., 유석진 Ph.d., Laura Valaas, M.D., James Drimalla, 공미나, Anne Waswa, Ximeng Huang, Dru Horne, Heather Lavender, Alexandra Yon 으로 구성되어 있다.
출처 : 한국데이터산업진흥원
제공 : 데이터 온에어 https://dataonair.or.kr/
